Recognition: unknown
Audio-DeepThinker: Progressive Reasoning-Aware Reinforcement Learning for High-Quality Chain-of-Thought Emergence in Audio Language Models
Pith reviewed 2026-05-10 03:37 UTC · model grok-4.3
The pith
A progressive two-stage reinforcement learning approach enables high-quality chain-of-thought reasoning to emerge in audio language models without supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
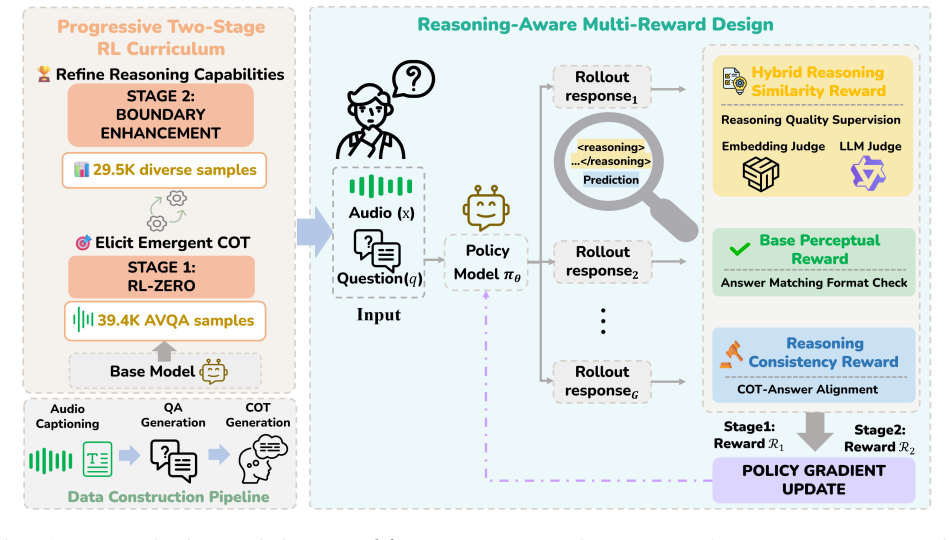
The central discovery is that instruction-tuned audio language models with no initial chain-of-thought capability can develop high-quality reasoning chains through a two-stage RL process: the first stage uses a hybrid reward of LLM logical evaluation plus embedding similarity on foundational audio QA tasks to build basic patterns, while the second stage uses only LLM rewards on difficult boundary cases to promote diversity, ultimately producing models that set new state-of-the-art scores on audio reasoning benchmarks.
What carries the argument
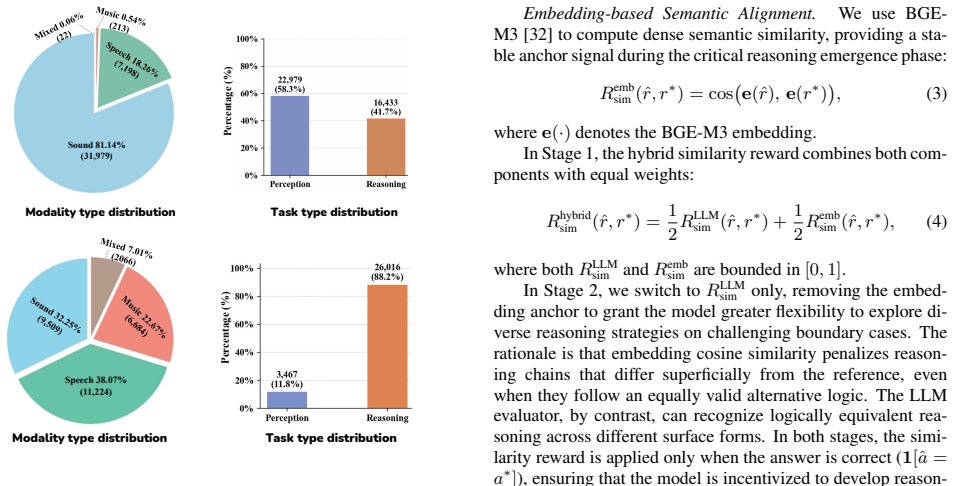
The hybrid reasoning similarity reward that combines an LLM evaluator checking logical path alignment, key step coverage, and analytical depth with an embedding similarity measure to enforce alignment with reference reasoning chains.
If this is right
- Audio-DeepThinker reaches 74.0% on MMAR, 78.5% on MMAU-test-mini, and 77.26% on MMSU.
- It secures first place in the Interspeech 2026 Audio Reasoning Challenge in the single model track.
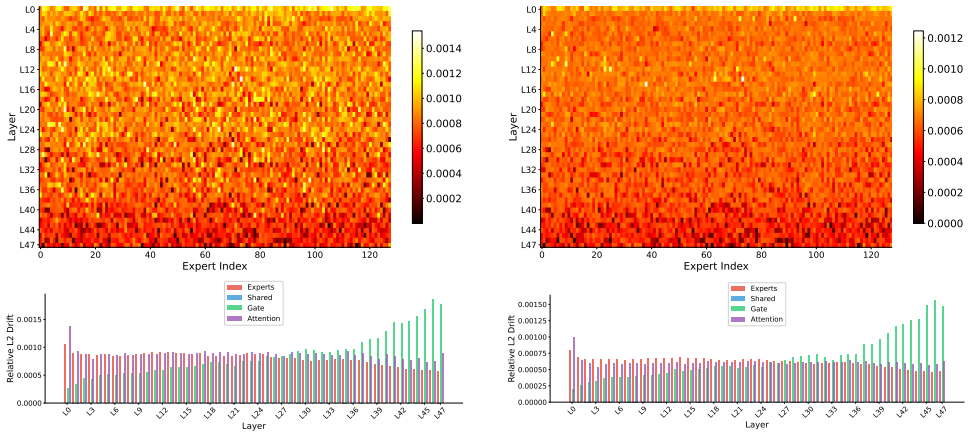
- RL training reshapes the gating mechanisms in upper layers of the mixture-of-experts architecture.
- Reasoning tokens form progressively in the upper transformer layers as training advances.
- Explicit chain-of-thought emerges from pure RL without any prior supervised reasoning training.
Where Pith is reading between the lines
- Similar progressive curricula might enable reasoning emergence in other sensory modalities such as vision or robotics where grounding is key.
- The observed changes in model internals suggest that future work could monitor layer activations to detect when reasoning capabilities stabilize.
- If the hybrid reward generalizes, it could be adapted to reduce dependence on large annotated datasets for training reasoning in language models overall.
- Testing the method on non-audio tasks would help determine whether the gains stem from the reward design or the specific challenges of audio data.
Load-bearing premise
The hybrid reward must supply an unbiased measure of reasoning quality that encourages genuine acoustic grounding instead of rewarding imitation of reference chains or superficial logical structure.
What would settle it
Running the same training but replacing the hybrid reward with a simple accuracy-based reward and checking if the resulting models still produce reasoning chains with comparable logical depth, semantic alignment, and benchmark performance.
Figures




read the original abstract
Large Audio-Language Models (LALMs) have made significant progress in audio understanding, yet they primarily operate as perception-and-answer systems without explicit reasoning processes. Existing methods for enhancing audio reasoning rely either on supervised chain-of-thought (CoT) fine-tuning, which is limited by training data quality, or on reinforcement learning (RL) with coarse rewards that do not directly evaluate reasoning quality. As a result, the generated reasoning chains often appear well-structured yet lack specific acoustic grounding. We propose Audio-DeepThinker, a framework built on two core ideas. First, we introduce a hybrid reasoning similarity reward that directly supervises the quality of generated reasoning chains by combining an LLM evaluator assessing logical path alignment, key step coverage, and analytical depth with an embedding similarity component enforcing semantic alignment with reference reasoning chains. Second, we propose a progressive two-stage curriculum that enables high-quality CoT reasoning to emerge through pure RL exploration, without any supervised reasoning fine-tuning, from an instruction-tuned model that possesses no prior chain-of-thought capability. Stage 1 trains on foundational audio QA with the hybrid reward to foster basic reasoning patterns, while Stage 2 shifts to acoustically challenging boundary cases with an LLM-only reward for greater reasoning diversity. Audio-DeepThinker achieves state-of-the-art results on MMAR (74.0%), MMAU-test-mini (78.5%), and MMSU (77.26%), winning 1st Place in the Interspeech 2026 Audio Reasoning Challenge (Single Model Track). Interpretability analyses further reveal that RL training primarily reshapes upper-layer MoE gating mechanisms and that reasoning tokens crystallize progressively in the upper transformer layers, offering mechanistic insights into how audio reasoning emerges through exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Audio-DeepThinker, a two-stage progressive RL framework for inducing high-quality chain-of-thought reasoning in audio language models starting from an instruction-tuned base without prior CoT capability. Stage 1 employs a hybrid reward (LLM evaluator for logical alignment, key-step coverage, and depth plus embedding similarity to reference reasoning chains) on foundational audio QA tasks; Stage 2 switches to an LLM-only reward on acoustically challenging cases. The paper reports SOTA results on MMAR (74.0%), MMAU-test-mini (78.5%), and MMSU (77.26%), first place in the Interspeech 2026 Audio Reasoning Challenge (Single Model Track), and mechanistic findings that RL reshapes upper-layer MoE gating while reasoning tokens crystallize progressively in upper transformer layers.
Significance. If substantiated, the work would advance audio-language modeling by showing that grounded CoT reasoning can emerge via RL exploration rather than supervised fine-tuning, reducing dependence on curated reasoning datasets. The two-stage curriculum design offers a practical way to bootstrap basic then diverse reasoning patterns, and the mechanistic analyses on gating and layer-wise token crystallization provide useful interpretability insights for future LALM architectures. The reported benchmark wins, if verified with proper controls, would demonstrate strong empirical utility.
major comments (3)
- [Abstract] Abstract: The hybrid reasoning similarity reward combines an LLM evaluator with an embedding similarity term 'enforcing semantic alignment with reference reasoning chains.' This term supplies a direct supervised signal from reference material, which appears to contradict the central claim of emergence 'through pure RL exploration, without any supervised reasoning fine-tuning.' The manuscript must demonstrate (via divergence metrics, ablations removing the similarity component, or qualitative examples) that post-training CoT chains are not simply mimicking references while still achieving acoustic grounding.
- [Abstract] Abstract: The SOTA performance claims (MMAR 74.0%, MMAU-test-mini 78.5%, MMSU 77.26%) and Interspeech 2026 first-place result are presented without baseline comparisons, ablation results, number of evaluation runs, or statistical tests. Because these numbers are load-bearing for the contribution, the paper requires tables or sections showing prior methods, the isolated effect of the hybrid reward versus LLM-only, and the curriculum stages.
- [Abstract] Abstract (Interpretability analyses): The statements that 'RL training primarily reshapes upper-layer MoE gating mechanisms' and that 'reasoning tokens crystallize progressively in the upper transformer layers' are offered without reference to specific figures, quantitative metrics (e.g., gating entropy changes, token activation thresholds), or experimental protocols. These mechanistic claims are central to explaining emergence and need detailed, reproducible exposition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for clarification and strengthening of our claims. We address each major comment point by point below, providing honest responses and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The hybrid reasoning similarity reward combines an LLM evaluator with an embedding similarity term 'enforcing semantic alignment with reference reasoning chains.' This term supplies a direct supervised signal from reference material, which appears to contradict the central claim of emergence 'through pure RL exploration, without any supervised reasoning fine-tuning.' The manuscript must demonstrate (via divergence metrics, ablations removing the similarity component, or qualitative examples) that post-training CoT chains are not simply mimicking references while still achieving acoustic grounding.
Authors: We appreciate the referee highlighting this potential ambiguity. The phrase 'without any supervised reasoning fine-tuning' specifically denotes the lack of supervised fine-tuning (SFT) on chain-of-thought data; our method starts from an instruction-tuned model with no prior CoT capability and optimizes exclusively via RL policy gradients. The embedding similarity term forms part of the hybrid reward to encourage coherent reasoning patterns during exploration, but does not involve direct imitation or SFT. To substantiate that generated CoT chains achieve genuine acoustic grounding rather than reference mimicry, we will add ablations removing the similarity component, quantitative divergence metrics (e.g., embedding distances and semantic overlap scores) between generated and reference chains, and qualitative examples in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The SOTA performance claims (MMAR 74.0%, MMAU-test-mini 78.5%, MMSU 77.26%) and Interspeech 2026 first-place result are presented without baseline comparisons, ablation results, number of evaluation runs, or statistical tests. Because these numbers are load-bearing for the contribution, the paper requires tables or sections showing prior methods, the isolated effect of the hybrid reward versus LLM-only, and the curriculum stages.
Authors: We agree that the reported performance figures require supporting evidence and controls to substantiate the SOTA claims. In the revised version, we will add a comprehensive results table with comparisons to prior methods, ablation studies isolating the hybrid reward versus LLM-only reward and the effects of each curriculum stage, and report metrics averaged across multiple evaluation runs with appropriate statistical tests (e.g., standard deviations and significance levels). revision: yes
-
Referee: [Abstract] Abstract (Interpretability analyses): The statements that 'RL training primarily reshapes upper-layer MoE gating mechanisms' and that 'reasoning tokens crystallize progressively in the upper transformer layers' are offered without reference to specific figures, quantitative metrics (e.g., gating entropy changes, token activation thresholds), or experimental protocols. These mechanistic claims are central to explaining emergence and need detailed, reproducible exposition.
Authors: We acknowledge that the interpretability section requires greater detail and reproducibility. In the revision, we will expand this analysis with explicit references to the corresponding figures, quantitative metrics including pre- and post-RL changes in MoE gating entropy and reasoning token activation thresholds, and a full description of the experimental protocols, layer-wise analysis methods, and visualization procedures. revision: yes
Circularity Check
Hybrid reward incorporates reference embedding similarity, reducing 'pure RL emergence' claim to supervised alignment with references
specific steps
-
fitted input called prediction
[Abstract]
"we introduce a hybrid reasoning similarity reward that directly supervises the quality of generated reasoning chains by combining an LLM evaluator assessing logical path alignment, key step coverage, and analytical depth with an embedding similarity component enforcing semantic alignment with reference reasoning chains. ... enables high-quality CoT reasoning to emerge through pure RL exploration, without any supervised reasoning fine-tuning, from an instruction-tuned model that possesses no prior chain-of-thought capability. Stage 1 trains on foundational audio QA with the hybrid reward to fos"
The embedding similarity term directly uses reference reasoning chains as the target for semantic alignment in the reward function. Although the paper asserts 'pure RL exploration' and 'without any supervised reasoning fine-tuning,' the generated chains are trained to minimize deviation from those references. This reduces the claimed emergence to optimization against the reference inputs by construction, rather than independent discovery of acoustic-grounded reasoning.
full rationale
The paper's core claim is that high-quality CoT emerges via pure RL exploration from an instruction-tuned base model with no supervised reasoning fine-tuning. However, the Stage 1 hybrid reward explicitly includes an embedding similarity term that enforces semantic alignment to reference reasoning chains. This makes the training signal dependent on the same reference material used to define 'high-quality' reasoning, so the output chains are optimized toward reference patterns by construction. Stage 2's LLM-only reward inherits any patterns shaped in Stage 1. This matches the 'fitted input called prediction' pattern: the reward is constructed using references, then the emergent reasoning is presented as independent discovery. No self-citations, uniqueness theorems, or ansatz smuggling appear in the provided text; the circularity is isolated to the reward design vs. emergence claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent progress in large language models has demonstrated that reinforcement learning (RL) can unlock sophisticated rea- soning capabilities through pure exploration, as exemplified by DeepSeek-R1 [ 1] and OpenAI o1 [ 2]. These successes have inspired growing interest in extending RL-based reasoning to multimodal domains [ 3, 4, 5]. In the aud...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Significant progress has been made in audio understanding through large- scale pre-training
Related Work Large Audio-Language Models (LALMs). Significant progress has been made in audio understanding through large- scale pre-training. SALMONN [ 7] proposed a generic hearing framework for LLMs. Audio Flamingo [ 17] introduced few- shot capabilities and dialogue abilities, while Qwen2-Audio- Instruct [ 6] pushed the performance of open-source model...
-
[3]
think out loud
Method We present Audio-DeepThinker, a framework that enables chain-of-thought reasoning capabilities to emerge in Large Audio-Language Models through reinforcement learning, with- out any supervised reasoning data. Our approach builds on a key insight: just as DeepSeek-R1 [ 1] demonstrated that reason- ing can emerge naturally through RL exploration in t...
-
[4]
Experimental Setup Model
Experiments 4.1. Experimental Setup Model. We adopt Qwen3-Omni-30B-A3B-Instruct [ 5] as our base model, which employs a mixture-of-experts (MoE) archi- tecture with 30B total parameters and 3B active parameters per token. The model contains 48 transformer layers with 128 ex- perts per layer. Notably, the model lacks inherent CoT reason- ing capability pri...
2026
-
[5]
Analysis To gain deeper insights into how CoT reasoning capabilities are acquired through RL training, we conduct comprehensive in- terpretability analyses. We systematically compare the internal representations across the progressive training pipeline (Base → Stage 1 → Stage 2) at multiple levels of granularity: repre- sentation drift across layers, MoE ...
2000
-
[6]
Conclusion We present Audio-DeepThinker, a progressive two-stage RL framework that enables high-quality CoT reasoning to emerge in LALMs through pure RL exploration, without supervised reasoning fine-tuning. Our hybrid reasoning similarity reward provides fine-grained supervision over reasoning quality, while the progressive curriculum first establishes foun...
2026
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Y ang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, S. Wang, S. Wu et al., “Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning,” arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
A. Jaech, L. Adams, M. Brundage et al., “Openai o1 system card,” arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
W. Huang, B. Jia, Z. Zhai, S. Cao, Z. Y e, F. Zhao, Z. Xu, Y . Hu, and S. Lin, “Vision-r1: Incentivizing reasoning ca- pability in multimodal large language models,” arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Visual-rft: Visual reinforcement fine-tuning,
Z. Liu, Z. Sun, Y . Zang, X. Dong, Y . Cao, H. Duan, D. Lin, and J. Wang, “Visual-rft: Visual reinforcement fine-tuning,” in Pro- ceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2034–2044
2025
-
[11]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhu et al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Y . Chu, J. Xu, Q. Y ang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin et al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
SALMONN: towards generic hearing abilities for large language models,
C. Tang, W. Y u, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: towards generic hearing abilities for large language models,” in The Twelfth International Conference on Learning Representations, ICLR 2024 , 2024
2024
-
[14]
Step-audio 2 technical report, 2025
B. Wu, C. Y an, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Y u, H. Zhang, J. Li et al. , “Step-audio 2 technical report,” arXiv preprint arXiv:2507.16632, 2025
-
[15]
Audio flamingo 2: An audio- language model with long-audio understanding and expert reason- ing abilities,
S. Ghosh, Z. Kong, S. Kumar, S. Sakshi, J. Kim, W. Ping, R. V alle, D. Manocha, and B. Catanzaro, “Audio flamingo 2: An audio- language model with long-audio understanding and expert reason- ing abilities,” in International Conference on Machine Learning . PMLR, 2025, pp. 19 358–19 405
2025
-
[16]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.- H. H. Y ang, R. Duraiswami, D. Manocha, R. V alle et al., “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,” arXiv preprint arXiv:2507.08128, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering,
G. Li, J. Liu, H. Dinkel, Y . Niu, J. Zhang, and J. Luan, “Reinforce- ment learning outperforms supervised fine-tuning: A case study on audio question answering,” arXiv preprint arXiv:2503.11197 , 2025
-
[18]
Omni-r1: Do you really need audio to fine-tune your audio llm?arXiv preprint arXiv:2505.09439, 2025
A. Rouditchenko, S. Bhati, E. Araujo, S. Thomas, H. Kuehne, R. Feris, and J. Glass, “Omni-r1: Do you really need audio to fine- tune your audio llm?” arXiv preprint arXiv:2505.09439, 2025
-
[19]
H. He, X. Du, R. Sun, Z. Dai, Y . Xiao, M. Y ang, J. Zhou, X. Li, Z. Liu, Z. Liang et al. , “Measuring audio’s impact on correct- ness: Audio-contribution-aware post-training of large audio lan- guage models,” arXiv preprint arXiv:2509.21060, 2025
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P . Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of math- ematical reasoning in open language models,” arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Audio-thinker: Guiding audio language model when and how to think via reinforcement learning,
S. Wu, C. Li, W. Wang, H. Zhang, H. Wang, M. Y u, and D. Y u, “Audio-thinker: Guiding audio language model when and how to think via reinforcement learning,” arXiv preprint arXiv:2508.08039, 2025
-
[22]
J. Fan, R. Ren, J. Li, R. Pandey, P . G. Shivakumar, I. Bulyko, A. Gandhe, G. Liu, and Y . Gu, “Incentivizing consistent, effec- tive and scalable reasoning capability in audio llms via reasoning process rewards,” arXiv preprint arXiv:2510.20867, 2025
-
[23]
Audio flamingo: a novel audio language model with few- shot learning and dialogue abilities,
Z. Kong, A. Goel, R. Badlani, W. Ping, R. V alle, and B. Catan- zaro, “Audio flamingo: a novel audio language model with few- shot learning and dialogue abilities,” inProceedings of the 41st In- ternational Conference on Machine Learning , 2024, pp. 25 125– 25 148
2024
-
[24]
A. Hurst, A. Lerer, A. P . Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford et al. , “GPT-4o system card,” arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Our vision for building a universal AI assis- tant,
D. Hassabis, “Our vision for building a universal AI assis- tant,” 2025. [Online]. Available: https://blog.google/technology/ google-deepmind/gemini-universal-ai-assistant/
2025
-
[26]
Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
Y . Li, J. Liu, T. Zhang, S. Chen, T. Li, Z. Li, L. Liu, L. Ming, G. Dong, D. Pan et al. , “Baichuan-omni-1.5 technical report,” arXiv preprint arXiv:2501.15368, 2025
-
[27]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,” arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Audio- reasoner: Improving reasoning capability in large audio language models,
X. Zhifei, M. Lin, Z. Liu, P . Wu, S. Y an, and C. Miao, “Audio- reasoner: Improving reasoning capability in large audio language models,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Nov. 2025, pp. 23 829– 23 851
2025
-
[29]
Ke-omni- r: Achieving advanced audio reasoning with a concise 50-words think process,
S. Zhao, T. Guo, C. Wen, B. Xiang, W. Zou, and X. Li, “Ke-omni- r: Achieving advanced audio reasoning with a concise 50-words think process,” https://github.com/shuaijiang/Ke-Omni-R, 2025
2025
-
[30]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
S.-Y . Liu, X. Dong, X. Lu, S. Diao, P . Belcak, M. Liu, M.-H. Chen, H. Yin, Y .-C. F. Wang, K.-T. Cheng et al. , “Gdpo: Group reward-decoupled normalization policy optimization for multi- reward rl optimization,” arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review arXiv 2026
-
[31]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P . Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE inter- national conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780
2017
-
[32]
Evalu- ation of algorithms using games: The case of music tagging,
E. Law, K. West, M. Mandel, M. Bay, and J. S. Downie, “Evalu- ation of algorithms using games: The case of music tagging,” in 10th International Society for Music Information Retrieval Con- ference, ISMIR 2009, 2009, pp. 387–392
2009
-
[33]
A. Y ang, A. Li, B. Y ang, B. Zhang, B. Hui, B. Zheng, B. Y u, C. Gao, C. Huang, C. Lv et al., “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Avqa: A dataset for audio-visual question answering,
C. Li, M. Zhao, Q. She et al. , “Avqa: A dataset for audio-visual question answering,” in Proceedings of the 30th ACM Interna- tional Conference on Multimedia , 2022, pp. 2785–2795
2022
-
[35]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan et al. , “Deepseek-v3 technical re- port,” arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Mustango: Toward controllable text-to-music gen- eration,
J. Melechovsky, Z. Guo, D. Ghosal, N. Majumder, D. Herremans, and S. Poria, “Mustango: Toward controllable text-to-music gen- eration,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies (V olume 1: Long Papers) , 2024, pp. 8286–8309
2024
-
[37]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,” Language resources and evaluation, vol. 42, no. 4, pp. 335–359, 2008
2008
-
[38]
Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,
J. Chen, S. Xiao, P . Zhang, K. Luo, D. Lian, and Z. Liu, “Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,” arXiv e- prints, pp. arXiv–2402, 2024
2024
-
[39]
T. M. Cover, Elements of information theory . John Wiley & Sons, 1999
1999
-
[40]
Swift:a scalable lightweight infrastructure for fine-tuning,
Y . Zhao, J. Huang, J. Hu, X. Wang, Y . Mao, D. Zhang, Z. Jiang, Z. Wu, B. Ai, A. Wang, W. Zhou, and Y . Chen, “Swift:a scalable lightweight infrastructure for fine-tuning,” 2024
2024
-
[41]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P . LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parame- ter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[42]
MMAR: A challenging bench- mark for deep reasoning in speech, audio, music, and their mix,
Z. Ma, Y . Ma, Y . Zhu, C. Y ang, Y .-W. Chao, R. Xu, W. Chen, Y . Chen, Z. Chen, J. Cong et al., “MMAR: A challenging bench- mark for deep reasoning in speech, audio, music, and their mix,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[43]
Z. Ma, R. Xu, Y . Ma, C.-H. H. Y ang, B. Li, J. Kim, J. Xu, J. Li, C. Busso, K. Y u et al. , “The interspeech 2026 audio reasoning challenge: Evaluating reasoning process quality for audio reason- ing models and agents,” arXiv preprint arXiv:2602.14224, 2026
-
[44]
Mmau: A massive multi-task audio understand- ing benchmark,
S. Sakshi et al., “Mmau: A massive multi-task audio understand- ing benchmark,” in Conference on Neural Information Processing Systems, 2024
2024
-
[45]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabil- ities,” arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang et al. , “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
W. Wang, C. Li, L. Zhang, Y . Zhao, Y . Zou, H. Li, M. Cui, H. Zhang, K. Wei, L. Xu et al. , “Covo-audio technical report,” arXiv preprint arXiv:2602.09823, 2026
-
[48]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space,
M. Geva, A. Caciularu, K. Wang, and Y . Goldberg, “Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space,” in Proceedings of the 2022 conference on empirical methods in natural language processing , 2022, pp. 30– 45. A. Prompt Templates This appendix provides the detailed prompt templates used in our framework. A....
2022
-
[49]
If audio Description is completely unrelated to the question and answer → output only "None"
-
[50]
{answer}
Otherwise, write 200-600 word reasoning that: - Identifies key audio evidence - Explains how it points to "{answer}" - Rules out other options - Sounds like analysis, not pre-knowledge
-
[51]
NO meta-commentary, NO repetition
-
[52]
Start immediately with your analysis Analysis: A.2. Reasoning Similarity Evaluation Prompt The following prompt is used by the LLM evaluator (Qwen3-235B-A22B-Instruct) to assess the similarity between generated reasoning and the reference CoT: Reasoning Similarity Evaluation Prompt You are an expert in evaluating reasoning similarity. Compare the followin...
-
[53]
Do they follow similar logical paths?
-
[54]
Do they cover the same key steps?
-
[55]
Are the reasoning strategies aligned?
-
[56]
U nas ju ˙z trzyna ´scie, ale... wybieramy jego spokojn ˛ a, a dzisiaj...,
Is the depth of analysis comparable? Reference Reasoning (Ground Truth): {gt_think} Generated Reasoning: {pred_think} Output ONLY a number between 0.0 and 1.0. No explanation. A.3. Model System Prompts The following system prompts are used for the Qwen3-Omni-30B-A3B-Instruct and Qwen3-Omni-30B-A3B-Thinking models during evaluation: Qwen3-Omni-Instruct Sys...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.