Recognition: unknown
Memorize When Needed: Decoupled Memory Control for Spatially Consistent Long-Horizon Video Generation
Pith reviewed 2026-05-10 04:46 UTC · model grok-4.3
The pith
Decoupling a lightweight memory branch from the generator with camera-aware gating maintains spatial consistency in long-horizon video while preserving novel scene creation and cutting training costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
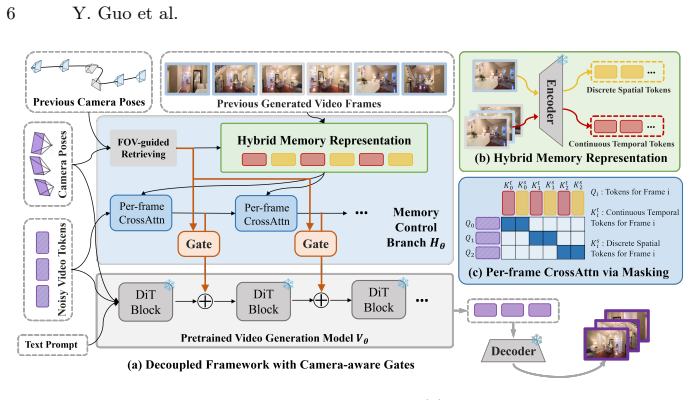
We introduce a decoupled framework that separates memory conditioning from generation by employing a lightweight independent memory branch to learn precise spatial consistency from historical observations via a hybrid memory representation and per-frame cross-attention, then use a camera-aware gating mechanism to mediate interaction so that memory conditioning occurs only when meaningful historical references exist, thereby enhancing spatial consistency during scene revisits without diminishing the generative capacity for novel regions while reducing training costs.
What carries the argument
The camera-aware gating mechanism that controls when the independent memory branch supplies historical spatial cues to the generative model based on whether relevant past observations exist for the current camera pose.
If this is right
- Training costs drop substantially because the memory branch is trained independently and the generator receives targeted conditioning.
- Spatial consistency improves during scene revisits without forcing the entire model to memorize all prior frames.
- Generative capacity for unexplored regions remains intact because memory influence is gated and does not dominate the output.
- The approach achieves state-of-the-art visual quality and consistency while requiring less annotated data than entangled baselines.
- Per-frame cross-attention ensures each generated frame receives only the most spatially relevant historical cues.
Where Pith is reading between the lines
- The design suggests memory separation could be applied to other autoregressive or diffusion video models to handle longer contexts without proportional increases in compute.
- Gating based on camera overlap might generalize to additional control signals such as object motion or lighting to further stabilize extended generations.
- Independent scaling of the memory branch could support even longer horizons in applications like robotics simulation or virtual production where 3D consistency matters.
- Testing the gating on real-world erratic camera paths would reveal whether the current relevance criterion generalizes beyond synthetic trajectories.
Load-bearing premise
A lightweight separate memory branch plus camera-aware gating can supply precisely the right historical spatial information without introducing new inconsistencies or reducing the generator's ability to create novel content.
What would settle it
Train both the decoupled model and an entangled baseline on the same limited dataset, then evaluate on a test set with repeated camera paths through complex scenes; if the decoupled version scores higher on spatial consistency metrics while matching or exceeding diversity of new scene elements, the central claim is supported.
Figures


read the original abstract
Spatially consistent long-horizon video generation aims to maintain temporal and spatial consistency along predefined camera trajectories. Existing methods mostly entangle memory modeling with video generation, leading to inconsistent content during scene revisits and diminished generative capacity when exploring novel regions, even trained on extensive annotated data. To address these limitations, we propose a decoupled framework that separates memory conditioning from generation. Our approach significantly reduces training costs while simultaneously enhancing spatial consistency and preserving the generative capacity for novel scene exploration. Specifically, we employ a lightweight, independent memory branch to learn precise spatial consistency from historical observation. We first introduce a hybrid memory representation to capture complementary temporal and spatial cues from generated frames, then leverage a per-frame cross-attention mechanism to ensure each frame is conditioned exclusively on the most spatially relevant historical information, which is injected into the generative model to ensure spatial consistency. When generating new scenes, a camera-aware gating mechanism is proposed to mediate the interaction between memory and generation modules, enabling memory conditioning only when meaningful historical references exist. Compared with the existing method, our method is highly data-efficient, yet the experiments demonstrate that our approach achieves state-of-the-art performance in terms of both visual quality and spatial consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a decoupled framework for spatially consistent long-horizon video generation that separates memory conditioning from the generative model. It introduces a lightweight independent memory branch using a hybrid memory representation to capture temporal and spatial cues from generated frames, a per-frame cross-attention mechanism to condition each frame only on the most relevant historical information, and a camera-aware gating mechanism to apply memory conditioning selectively when meaningful historical references exist. The authors claim this reduces training costs, enhances spatial consistency during scene revisits, preserves generative capacity for novel regions, and achieves SOTA performance in visual quality and spatial consistency while being highly data-efficient.
Significance. If the experimental claims hold, the decoupled memory control could meaningfully advance long-horizon video synthesis by mitigating entanglement between memory and generation, enabling more efficient training and better handling of both revisited and novel scenes. The camera-aware gating and hybrid representation address a practical limitation in existing methods, with potential impact on applications requiring trajectory-consistent video such as simulation and robotics.
major comments (2)
- Abstract: The assertions that the method 'significantly reduces training costs', is 'highly data-efficient', and 'achieves state-of-the-art performance in terms of both visual quality and spatial consistency' are not supported by any quantitative metrics, baseline comparisons, ablation studies, or error analysis. This absence is load-bearing because the central contribution and significance rest on these empirical claims, which cannot be evaluated from the manuscript text.
- Abstract: The camera-aware gating mechanism is described only at a high level without specification of the gating criterion, threshold, or robustness analysis across trajectory lengths and scene complexities. This leaves unaddressed the risk that imperfect gating decisions could reintroduce spatial inconsistencies or constrain novel content generation, directly impacting the weakest assumption underlying the decoupled framework.
minor comments (1)
- Abstract: Terms such as 'hybrid memory representation' and 'per-frame cross-attention mechanism' are introduced without inline definitions or references to later sections, reducing clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Abstract: The assertions that the method 'significantly reduces training costs', is 'highly data-efficient', and 'achieves state-of-the-art performance in terms of both visual quality and spatial consistency' are not supported by any quantitative metrics, baseline comparisons, ablation studies, or error analysis. This absence is load-bearing because the central contribution and significance rest on these empirical claims, which cannot be evaluated from the manuscript text.
Authors: We agree that the abstract would be strengthened by explicit references to supporting evidence. The manuscript body (Section 4) contains the relevant quantitative results, including baseline comparisons on visual quality and spatial consistency metrics, training cost measurements for the decoupled branch, data-efficiency ablations on reduced training sets, and error analysis. We have revised the abstract to cite these specific experimental outcomes and sections so that the claims are directly traceable to the reported evidence. revision: yes
-
Referee: Abstract: The camera-aware gating mechanism is described only at a high level without specification of the gating criterion, threshold, or robustness analysis across trajectory lengths and scene complexities. This leaves unaddressed the risk that imperfect gating decisions could reintroduce spatial inconsistencies or constrain novel content generation, directly impacting the weakest assumption underlying the decoupled framework.
Authors: We acknowledge that the abstract presents the gating at a high level. Section 3.4 of the manuscript specifies the gating criterion (camera-pose overlap computed from rotation and translation similarity) and the activation threshold. We have added a dedicated robustness study in the revised experiments section that evaluates gating decisions across trajectory lengths up to 120 frames and varying scene complexities, confirming that imperfect gating does not reintroduce inconsistencies or limit novel content. We will incorporate a concise statement of the criterion and threshold into the abstract and move the robustness results into the main text. revision: yes
Circularity Check
No circularity: architecture description contains no derivations, equations, or self-referential reductions.
full rationale
The paper presents a decoupled memory framework for video generation as an empirical architecture choice (lightweight independent memory branch, hybrid representation, per-frame cross-attention, camera-aware gating) without any mathematical derivation chain, first-principles results, or predictions that reduce to fitted inputs by construction. No equations are shown in the provided text, no parameters are fitted to subsets then renamed as predictions, and no load-bearing self-citations or uniqueness theorems are invoked. The central claims rest on experimental validation of the proposed components rather than definitional equivalence or self-referential justification, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A generative video model can be externally conditioned on a separate memory module without degrading its capacity for novel content.
invented entities (2)
-
hybrid memory representation
no independent evidence
-
camera-aware gating mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bahmani, S., Skorokhodov, I., Qian, G., Siarohin, A., Menapace, W., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Ac3d: Analyzing and improving 3d camera con- trol in video diffusion transformers. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22875–22889 (2025)
2025
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bar, A., Zhou, G., Tran, D., Darrell, T., LeCun, Y.: Navigation world models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15791–15801 (2025)
2025
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review arXiv 2023
-
[4]
In: Forty-first International Conference on Machine Learning (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[5]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Cao, C., Zhou, J., Li, S., Liang, J., Yu, C., Wang, F., Xue, X., Fu, Y.: Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video gen- eration. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–12 (2025)
2025
-
[6]
Advances in Neural Information Processing Systems37, 24081–24125 (2024)
Chen, B., Martí Monsó, D., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Information Processing Systems37, 24081–24125 (2024)
2024
-
[7]
SkyReels-V2: Infinite-length Film Generative Model
Chen, G., Lin, D., Yang, J., Lin, C., Zhu, J., Fan, M., Zhang, H., Chen, S., Chen, Z., Ma, C., et al.: Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074 (2025)
work page internal anchor Pith review arXiv 2025
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion mod- els. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7310–7320 (2024)
2024
-
[9]
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
-
[10]
Decart, E.: Oasis: A universe in a transformer.https://oasis-model.github.io/ (2024)
2024
-
[11]
Deepmind, G.: Veo3 video model (2025),https://deepmind.google/models/veo/
2025
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Duan, H., Yu, H.X., Chen, S., Fei-Fei, L., Wu, J.: Worldscore: A unified evaluation benchmark for world generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27713–27724 (2025)
2025
-
[13]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025)
work page internal anchor Pith review arXiv 2025
-
[14]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023) 16 Y. Guo et al
work page internal anchor Pith review arXiv 2023
-
[15]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
work page internal anchor Pith review arXiv 2024
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
He, H., Yang, C., Lin, S., Xu, Y., Wei, M., Gui, L., Zhao, Q., Wetzstein, G., Jiang, L., Li, H.: Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13416–13426 (2025)
2025
-
[17]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
He, X., Peng, C., Liu, Z., Wang, B., Zhang, Y., Cui, Q., Kang, F., Jiang, B., An, M., Ren, Y., et al.: Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Henschel, R., Khachatryan, L., Poghosyan, H., Hayrapetyan, D., Tadevosyan, V., Wang, Z., Navasardyan, S., Shi, H.: Streamingt2v: Consistent, dynamic, and ex- tendable long video generation from text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2568–2577 (2025)
2025
-
[19]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[20]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Hong, Y., Mei, Y., Ge, C., Xu, Y., Zhou, Y., Bi, S., Hold-Geoffroy, Y., Roberts, M., Fisher, M., Shechtman, E., et al.: Relic: Interactive video world model with long-horizon memory. arXiv preprint arXiv:2512.04040 (2025)
-
[21]
Huang, J., Hu, X., Han, B., Shi, S., Tian, Z., He, T., Jiang, L.: Memory forc- ing: Spatio-temporal memory for consistent scene generation on minecraft. arXiv preprint arXiv:2510.03198 (2025)
-
[22]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review arXiv 2025
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[24]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ke, J., Wang, Q., Wang, Y., Milanfar, P., Yang, F.: Musiq: Multi-scale image quality transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5148–5157 (2021)
2021
-
[25]
Advances in Neural Information Processing Systems37, 89834–89868 (2024)
Kim, J., Kang, J., Choi, J., Han, B.: Fifo-diffusion: Generating infinite videos from text without training. Advances in Neural Information Processing Systems37, 89834–89868 (2024)
2024
-
[26]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Kuaishou: Kling video model (2024),https://klingai.com/global/
2024
-
[28]
Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition,
Li, J., Tang, J., Xu, Z., Wu, L., Zhou, Y., Shao, S., Yu, T., Cao, Z., Lu, Q.: Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition. arXiv preprint arXiv:2506.172012(3), 6 (2025)
-
[29]
Cameras as relative positional encoding, 2025
Li, R., Yi, B., Liu, J., Gao, H., Ma, Y., Kanazawa, A.: Cameras as relative posi- tional encoding. arXiv preprint arXiv:2507.10496 (2025)
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, R., Torr, P., Vedaldi, A., Jakab, T.: Vmem: Consistent interactive video scene generation with surfel-indexed view memory. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25690–25699 (2025)
2025
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Zhu, Z.L., Han, L.H., Hou, Q., Guo, C.L., Cheng, M.M.: Amt: All-pairs multi-field transforms for efficient frame interpolation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9801– 9810 (2023) Memorize When Needed 17
2023
-
[32]
Advances in Neural Information Processing Systems37, 131434–131455 (2024)
Lu, Y., Liang, Y., Zhu, L., Yang, Y.: Freelong: Training-free long video generation with spectralblend temporal attention. Advances in Neural Information Processing Systems37, 131434–131455 (2024)
2024
-
[33]
Minimax: Hailuo video model (2024),https://hailuoai.video
2024
-
[34]
Gta: A geometry-aware attention mechanism for multi-view transformers, 2024
Miyato, T., Jaeger, B., Welling, M., Geiger, A.: Gta: A geometry-aware attention mechanism for multi-view transformers. arXiv preprint arXiv:2310.10375 (2023)
-
[35]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6121–6132 (2025)
2025
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[38]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[39]
History-guided video diffusion.arXiv preprint arXiv:2502.06764,
Song, K., Chen, B., Simchowitz, M., Du, Y., Tedrake, R., Sitzmann, V.: History- guided video diffusion. arXiv preprint arXiv:2502.06764 (2025)
-
[40]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[41]
Sun, W., Chen, S., Liu, F., Chen, Z., Duan, Y., Zhang, J., Wang, Y.: Dimensionx: Create any 3d and 4d scenes from a single image with controllable video diffusion. arXiv preprint arXiv:2411.04928 (2024)
-
[42]
arXiv preprint arXiv:2506.18901 (2025)
Sun, W., Wei, F., Zhao, J., Chen, X., Chen, Z., Zhang, H., Zhang, J., Lu, Y.: From virtual games to real-world play. arXiv preprint arXiv:2506.18901 (2025)
-
[43]
Worldplay: Towards long-term geometric consistency for real-time interactive world modeling,
Sun, W., Zhang, H., Wang, H., Wu, J., Wang, Z., Wang, Z., Wang, Y., Zhang, J., Wang, T., Guo, C.: Worldplay: Towards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614 (2025)
-
[44]
Team, H., Wang, Z., Liu, Y., Wu, J., Gu, Z., Wang, H., Zuo, X., Huang, T., Li, W., Zhang, S., et al.: Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels. arXiv preprint arXiv:2507.21809 (2025)
-
[45]
In: European conference on computer vision
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: European conference on computer vision. pp. 402–419. Springer (2020)
2020
-
[46]
MAGI-1: Autoregressive Video Generation at Scale
Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W., Luo, W., et al.: Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211 (2025)
work page internal anchor Pith review arXiv 2025
-
[47]
Diffusion models are real-time game engines
Valevski, D., Leviathan, Y., Arar, M., Fruchter, S.: Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837 (2024)
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[50]
Video models are zero-shot learners and reasoners
Wiedemer, T., Li, Y., Vicol, P., Gu, S.S., Matarese, N., Swersky, K., Kim, B., Jaini, P., Geirhos, R.: Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328 (2025) 18 Y. Guo et al
work page internal anchor Pith review arXiv 2025
-
[51]
arXiv preprint arXiv:2502.01776 , year =
Xi, H., Yang, S., Zhao, Y., Xu, C., Li, M., Li, X., Lin, Y., Cai, H., Zhang, J., Li, D., et al.: Sparse videogen: Accelerating video diffusion transformers with spatial- temporal sparsity. arXiv preprint arXiv:2502.01776 (2025)
-
[52]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Xiao, Z., Lan, Y., Zhou, Y., Ouyang, W., Yang, S., Zeng, Y., Pan, X.: Worldmem: Long-term consistent world simulation with memory. arXiv preprint arXiv:2504.12369 (2025)
-
[53]
Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
-
[54]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review arXiv 2024
-
[55]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Yu, J., Bai, J., Qin, Y., Liu, Q., Wang, X., Wan, P., Zhang, D., Liu, X.: Context as memory: Scene-consistent interactive long video generation with memory retrieval. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–11 (2025)
2025
-
[56]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yu, J., Qin, Y., Wang, X., Wan, P., Zhang, D., Liu, X.: Gamefactory: Creating new games with generative interactive videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11590–11599 (2025)
2025
-
[57]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yu, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 100–111 (2025)
2025
-
[58]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review arXiv 2024
- [59]
-
[60]
Zhao, M., He, G., Chen, Y., Zhu, H., Li, C., Zhu, J.: Riflex: A free lunch for length extrapolation in video diffusion transformers. arXiv preprint arXiv:2502.15894 (2025)
-
[61]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhou,J.,Gao,H.,Voleti,V.,Vasishta,A.,Yao,C.H.,Boss,M.,Torr,P.,Rupprecht, C., Jampani, V.: Stable virtual camera: Generative view synthesis with diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12405–12414 (2025)
2025
-
[62]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learning view synthesis using multiplane images. ACM Trans. Graph. (Proc. SIG- GRAPH)37(2018),https://arxiv.org/abs/1805.09817 Memorize When Needed 19 - Appendix - In this appendix, we provide the following materials: –Section A: The camera-aware gating algorithm (referring to ...
work page internal anchor Pith review arXiv 2018
-
[63]
(historical frames=1) to generate 61 frames under its iterative inference paradigm. The memory FLOPs refer to the extra cost arising from its memory mechanism, which retains more historical frames(=4) and reduces the number Memorize When Needed 21 of newly generated frames per iteration, thus increasing the total number of iterations required. For WorldPl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.