Recognition: unknown
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
Pith reviewed 2026-05-10 05:02 UTC · model grok-4.3
The pith
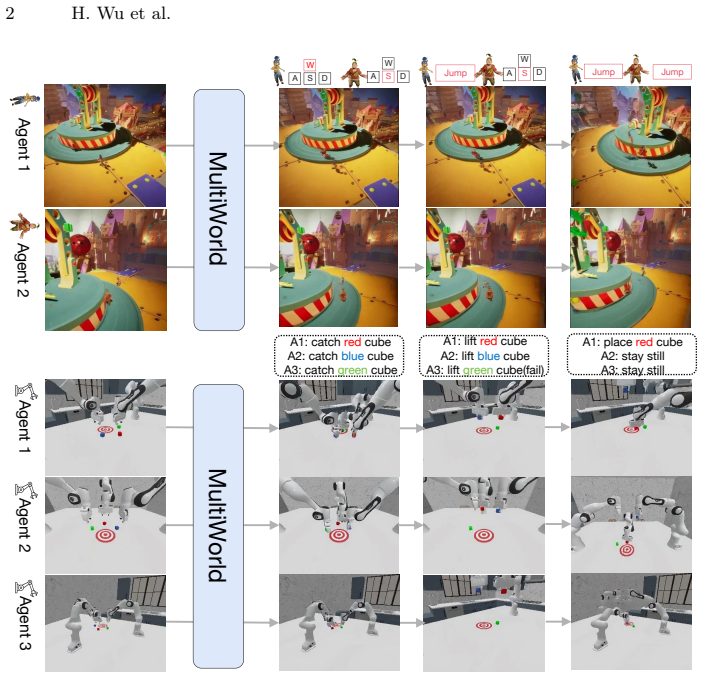
MultiWorld is a unified framework that adds dedicated modules to video world models so they can control multiple agents while keeping observations consistent across different views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MultiWorld is a unified framework for multi-agent multi-view world modeling that enables accurate control of multiple agents while maintaining multi-view consistency. It introduces the Multi-Agent Condition Module to achieve precise multi-agent controllability and the Global State Encoder to ensure coherent observations across different views. The framework supports flexible scaling of agent and view counts and synthesizes different views in parallel for high efficiency, outperforming baselines in video fidelity, action-following ability, and multi-view consistency on multi-player game environments and multi-robot manipulation tasks.
What carries the argument
The Multi-Agent Condition Module, which injects separate action signals for each agent into the video generator, together with the Global State Encoder, which extracts and broadcasts shared environmental information to keep every view aligned.
If this is right
- Precise following of each agent’s actions in the predicted video frames
- No visible contradictions between images generated for different camera angles
- Ability to add or remove agents and views at inference time without retraining
- Higher measured video quality and action adherence than single-agent baselines on the same tasks
- Parallel synthesis of all views reduces the time needed to produce a full multi-view prediction
Where Pith is reading between the lines
- The same conditioning and encoding pattern could be tested on real driving footage containing several vehicles observed by multiple roadside cameras.
- Combining the model with multi-agent reinforcement learning would let planners use the generated videos as fast forward simulations of team behavior.
- The parallel view generation might support online video prediction for robotic teams that must react to teammates they cannot see directly.
- Extending the global encoder to handle partial or occluded views could improve robustness when some cameras are blocked.
Load-bearing premise
That inserting the Multi-Agent Condition Module and Global State Encoder into standard video generation networks will produce better controllability and consistency without hidden losses in training stability or ability to generalize to new scenes.
What would settle it
Generate videos for two agents that take conflicting actions while viewed from two cameras; the claim is refuted if the output frames show mismatched object positions or states across the two views or if the agents ignore their individual action inputs.
Figures









read the original abstract
Video world models have achieved remarkable success in simulating environmental dynamics in response to actions by users or agents. They are modeled as action-conditioned video generation models that take historical frames and current actions as input to predict future frames. Yet, most existing approaches are limited to single-agent scenarios and fail to capture the complex interactions inherent in real-world multi-agent systems. We present \textbf{MultiWorld}, a unified framework for multi-agent multi-view world modeling that enables accurate control of multiple agents while maintaining multi-view consistency. We introduce the Multi-Agent Condition Module to achieve precise multi-agent controllability, and the Global State Encoder to ensure coherent observations across different views. MultiWorld supports flexible scaling of agent and view counts, and synthesizes different views in parallel for high efficiency. Experiments on multi-player game environments and multi-robot manipulation tasks demonstrate that MultiWorld outperforms baselines in video fidelity, action-following ability, and multi-view consistency. Project page: https://multi-world.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiWorld, a unified framework for multi-agent multi-view video world modeling. It extends action-conditioned video generation by adding a Multi-Agent Condition Module for precise control of multiple agents and a Global State Encoder to maintain coherent multi-view observations. The framework supports flexible scaling of agent and view counts with parallel view synthesis for efficiency. Experiments on multi-player game environments and multi-robot manipulation tasks are described, with claims of outperformance over baselines in video fidelity, action-following ability, and multi-view consistency.
Significance. If the empirical results hold, the work would extend video world models to handle multi-agent interactions and multi-view consistency, filling a gap in single-agent focused approaches. The design emphasis on scalability and parallel synthesis offers practical advantages for complex environments like robotics and gaming simulations.
major comments (1)
- Abstract: The abstract states that MultiWorld 'outperforms baselines in video fidelity, action-following ability, and multi-view consistency' but supplies no quantitative metrics, baseline descriptions, ablation studies, or error analysis. This prevents verification of the central empirical claims from the available text.
minor comments (1)
- Abstract: The high-level description of the Multi-Agent Condition Module and Global State Encoder would benefit from more detail on their integration into existing video generation architectures to clarify the technical novelty.
Simulated Author's Rebuttal
We thank the referee for their valuable comments and the opportunity to improve the manuscript. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: The abstract states that MultiWorld 'outperforms baselines in video fidelity, action-following ability, and multi-view consistency' but supplies no quantitative metrics, baseline descriptions, ablation studies, or error analysis. This prevents verification of the central empirical claims from the available text.
Authors: We agree that the abstract would benefit from including key quantitative results to substantiate the performance claims. The full manuscript provides these details in the Experiments section, including specific metrics for video fidelity, action-following accuracy, and multi-view consistency, along with baseline comparisons and ablation studies. We will revise the abstract to incorporate representative quantitative improvements and baseline references so that the central claims can be verified directly from the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an architectural framework for multi-agent multi-view video generation by describing two new modules (Multi-Agent Condition Module and Global State Encoder) plus parallel synthesis for scaling. No equations, derivations, fitted parameters, or predictions are presented that reduce by construction to the inputs or to self-citations. The central claims rest on experimental comparisons in game and robotics environments rather than any self-referential reduction of outputs to fitted quantities or prior author results. This is a standard model-design paper whose evaluation is externally falsifiable.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Multi-Agent Condition Module
no independent evidence
-
Global State Encoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems37, 58757–58791 (2024) 4
Alonso,E.,Jelley,A.,Micheli,V.,Kanervisto,A.,Storkey,A.J.,Pearce,T.,Fleuret, F.: Diffusion for world modeling: Visual details matter in atari. Advances in Neural Information Processing Systems37, 58757–58791 (2024) 4
2024
-
[2]
Advances in Neural Information Processing Systems35, 24639–24654 (2022) 9, 2
Baker, B., Akkaya, I., Zhokov, P., Huizinga, J., Tang, J., Ecoffet, A., Houghton, B., Sampedro, R., Clune, J.: Video pretraining (vpt): Learning to act by watching unlabeled online videos. Advances in Neural Information Processing Systems35, 24639–24654 (2022) 9, 2
2022
-
[3]
Ball, P.J., Bauer, J., Belletti, F., Brownfield, B., Ephrat, A., Fruchter, S., Gupta, A., Holsheimer, K., Holynski, A., Hron, J., Kaplanis, C., Limont, M., McGill, M., Oliveira, Y., Parker-Holder, J., Perbet, F., Scully, G., Shar, J., Spencer, S., Tov, O., Villegas, R., Wang, E., Yung, J., Baetu, C., Berbel, J., Bridson, D., Bruce, J., Buttimore, G., Chak...
2025
-
[4]
In: Forty-first International Conference on Machine Learning (2024) 4
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: Forty-first International Conference on Machine Learning (2024) 4
2024
-
[5]
arXiv preprint arXiv:2508.18797 (2025) 4
Chai, Q., Zheng, Z., Ren, J., Ye, D., Lin, Z., Wang, H.: Causalmace: Causal- ity empowered multi-agents in minecraft cooperative tasks. arXiv preprint arXiv:2508.18797 (2025) 4
-
[6]
arXiv preprint arXiv:2509.22642 , year=
Chi, X., Jia, P., Fan, C.K., Ju, X., Mi, W., Zhang, K., Qin, Z., Tian, W., Ge, K., Li, H., Qian, Z., Chen, A., Zhou, Q., Jia, Y., Liu, J., Dai, Y., Wuwu, Q., Bai, C., Wang, Y.K., Li, Y., Chen, L., Bao, Y., Jiang, Z., Zhu, J., Tang, K., An, R., Luo, Y., Feng, Q., Zhou, S., min Chan, C., Hou, C., Xue, W., Han, S., Guo, Y., Zhang, S., Tang, J.: Wow: Towards ...
-
[7]
Decart, Julian, Q., Quinn, M., Spruce, C., Xinlei, C., Robert, W.: Oasis: A universe in a transformer (2024),https://oasis-model.github.io/4
2024
-
[8]
Worldscore: A unified evaluation benchmark for world generation, 2025
Duan, H., Yu, H.X., Chen, S., Fei-Fei, L., Wu, J.: Worldscore: A unified evaluation benchmark for world generation. arXiv preprint arXiv:2504.00983 (2025) 2
-
[9]
Euler, L.: Institutionum calculi integralis, vol. 4. impensis Academiae imperialis scientiarum (1845) 3
-
[10]
Feng, R., Zhang, H., Yang, Z., Xiao, J., Shu, Z., Liu, Z., Zheng, A., Huang, Y., Liu, Y., Zhang, H.: The matrix: Infinite-horizon world generation with real-time moving control. arXiv preprint arXiv:2412.03568 (2024) 4
-
[11]
Multi-agent embodied ai: Advances and future directions.arXiv preprint arXiv:2505.05108,
Feng, Z., Xue, R., Yuan, L., Yu, Y., Ding, N., Liu, M., Gao, B., Sun, J., Zheng, X., Wang, G.: Multi-agent embodied ai: Advances and future directions. arXiv preprint arXiv:2505.05108 (2025) 4
-
[12]
Mineworld: a real-time and open-source interactive world model on minecraft,
Guo, J., Ye, Y., He, T., Wu, H., Jiang, Y., Pearce, T., Bian, J.: Mineworld: a real-time and open-source interactive world model on minecraft. arXiv preprint arXiv:2504.08388 (2025) 4 MultiWorld 17
-
[13]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[14]
Advances in Neural Information Processing Systems (NeurIPS)33, 6840–6851 (2020) 4
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems (NeurIPS)33, 6840–6851 (2020) 4
2020
- [15]
-
[16]
Huang, X.: Towards video world models (2025),https://www.xunhuang.me/ blogs/world_model.html4
2025
-
[17]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv: 2506.08009 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[18]
Jiang, Z., Liu, K., Qin, Y., Tian, S., Zheng, Y., Zhou, M., Yu, C., Li, H., Zhao, D.: World4rl: Diffusion world models for policy refinement with reinforcement learning for robotic manipulation. arXiv preprint arXiv:2509.19080 (2025) 4
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
In: The Eleventh International Conference on Learning Rep- resentations (2023) 4, 6
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Rep- resentations (2023) 4, 6
2023
-
[21]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Liu, R., Wu, H., Zheng, Z., Wei, C., He, Y., Pi, R., Chen, Q.: Videodpo: Omni- preference alignment for video diffusion generation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 8009–8019 (2025) 4
2025
-
[22]
In: The Eleventh International Conference on Learning Representations (2023) 6
Liu, X., Gong, C., et al.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023) 6
2023
-
[23]
Long, Q., Li, Z., Gong, R., Wu, Y.N., Terzopoulos, D., Gao, X.: Teamcraft: A benchmark for multi-modal multi-agent systems in minecraft. arXiv preprint arXiv:2412.05255 (2024) 4
-
[24]
arXiv preprint arXiv:2509.13903 (2025) 4
Lykov, A., Sam, J., Nguyen, H.K., Kozlovskiy, V., Mahmoud, Y., Serpiva, V., Cabrera, M.A., Konenkov, M., Tsetserukou, D.: Physicalagent: Towards general cognitive robotics with foundation world models. arXiv preprint arXiv:2509.13903 (2025) 4
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lyu, J., Li, Z., Shi, X., Xu, C., Wang, Y., Wang, H.: Dywa: Dynamics-adaptive world action model for generalizable non-prehensile manipulation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11058–11068 (2025) 4
2025
-
[26]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Mao, X., Lin, S., Li, Z., Li, C., Peng, W., He, T., Pang, J., Chi, M., Qiao, Y., Zhang, K.: Yume: An interactive world generation model. arXiv preprint arXiv:2507.17744 (2025) 1
-
[27]
World Simulation with Video Foundation Models for Physical AI
NVIDIA, :, Ali, A., Bai, J., Bala, M., Balaji, Y., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y.W., Chattopadhyay, P., Chen, M., Chen, Y., Chen, Y., Cheng, S., Cui, Y., Diamond, J., Ding, Y., Fan, J., Fan, L., Feng, L., Ferroni, F., Fidler, S., Fu, X., Gao, R., Ge, Y., Gu, J., Gupta, A., Gururani, S., Hanafi, I.E., Hassani, A., Hao, Z., Huffm...
work page internal anchor Pith review arXiv 2025
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
URL: https://deepmind
Parker-Holder, J., Ball, P., Bruce, J., Dasagi, V., Holsheimer, K., Kaplanis, C., Moufarek, A., Scully, G., Shar, J., Shi, J., et al.: Genie 2: A large-scale foundation world model. URL: https://deepmind. google/discover/blog/genie-2-a-large-scale- foundation-world-model (2024) 4
2024
-
[30]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 4
2023
-
[31]
arXiv preprint arXiv:2503.16408 (2025)
Qin, Y., Kang, L., Song, X., Yin, Z., Liu, X., Liu, X., Zhang, R., Bai, L.: Robo- factory: Exploring embodied agent collaboration with compositional constraints. arXiv preprint arXiv:2503.16408 (2025) 3, 4, 1
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (2022) 4
2022
-
[33]
Gaia-2: A controllable multi-view generative world model for autonomous driving,
Russell, L., Hu, A., Bertoni, L., Fedoseev, G., Shotton, J., Arani, E., Corrado, G.: Gaia-2: A controllable multi-view generative world model for autonomous driving. arXiv preprint arXiv:2503.20523 (2025) 4
-
[34]
Solaris: Building a multiplayer video world model in minecraft.arXiv preprint arXiv:2602.22208, 2026
Savva, G., Michel, O., Lu, D., Waiwitlikhit, S., Meehan, T., Mishra, D., Poddar, S., Lu, J., Xie, S.: Solaris: Building a multiplayer video world model in minecraft. arXiv preprint arXiv:2602.22208 (2026) 2, 4
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shin, S., Kim, J., Halilaj, E., Black, M.J.: Wham: Reconstructing world-grounded humans with accurate 3d motion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2070–2080 (2024) 4
2070
- [36]
-
[37]
arXiv preprint arXiv: 2508.09822 (2025) 4
Song, Z., Qin, S., Chen, T., Lin, L., Wang, G.: Physical autoregressive model for robotic manipulation without action pretraining. arXiv preprint arXiv: 2508.09822 (2025) 4
-
[38]
Neurocomputing568, 127063 (2024) 6
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024) 6
2024
-
[39]
Hunyuan-gamecraft-2: Instruction-following interactive game world model,
Tang, J., Liu, J., Li, J., Wu, L., Yang, H., Zhao, P., Gong, S., Yuan, X., Shao, S., Lu, Q.: Hunyuan-gamecraft-2: Instruction-following interactive game world model. arXiv preprint arXiv:2511.23429 (2025) 4
-
[40]
team, E.: Introducing multiverse: The first ai multiplayer world model (2025), https://enigma.inc/blog4
2025
-
[41]
Advancing open-source world models,
Team, R., Gao, Z., Wang, Q., Zeng, Y., Zhu, J., Cheng, K.L., Li, Y., Wang, H., Xu, Y., Ma, S., et al.: Advancing open-source world models. arXiv preprint arXiv:2601.20540 (2026) 1, 4
-
[42]
Advances in neural information processing systems34, 16558–16569 (2021) 2 MultiWorld 19
Teed, Z., Deng, J.: Droid-slam: Deep visual slam for monocular, stereo, and rgb- d cameras. Advances in neural information processing systems34, 16558–16569 (2021) 2 MultiWorld 19
2021
-
[43]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018) 9
work page internal anchor Pith review arXiv 2018
-
[44]
Diffusion models are real-time game engines
Valevski, D., Leviathan, Y., Arar, M., Fruchter, S.: Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837 (2024) 4
-
[45]
Advances in Neural Information Pro- cessing Systems (NeurIPS)30(2017) 6
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in Neural Information Pro- cessing Systems (NeurIPS)30(2017) 6
2017
-
[46]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 4, 9, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
arXiv preprint arXiv: 2509.12437 (2025) 4
Wang, D., Sun, Z., Li, Z., Wang, C., Peng, Y., Ye, H., Zarrouki, B., Li, W., Pic- cinini, M., Xie, L., Betz, J.: Enhancing physical consistency in lightweight world models. arXiv preprint arXiv: 2509.12437 (2025) 4
-
[48]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025) 7, 12
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025) 7, 12
2025
-
[49]
Wang, J., Ma, A., Cao, K., Zheng, J., Zhang, Z., Feng, J., Liu, S., Ma, Y., Cheng, B., Leng, D., et al.: Wisa: World simulator assistant for physics-aware text-to-video generation. arXiv preprint arXiv:2503.08153 (2025) 4
-
[50]
Wang, X., Zhu, Z., Huang, G., Wang, B., Chen, X., Lu, J.: Worlddreamer: Towards general world models for video generation via predicting masked tokens. arXiv preprint arXiv:2401.09985 (2024) 1
-
[51]
IEEE transactions on image processing 13(4), 600–612 (2004) 9
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004) 9
2004
-
[52]
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Wu, H., Wu, D., He, T., Guo, J., Ye, Y., Duan, Y., Bian, J.: Geometry forcing: Mar- rying video diffusion and 3d representation for consistent world modeling. arXiv preprint arXiv:2507.07982 (2025) 4, 9, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Wu, R., He, X., Cheng, M., Yang, T., Zhang, Y., Kang, Z., Cai, X., Wei, X., Guo, C., Li, C., et al.: Infinite-world: Scaling interactive world models to 1000- frame horizons via pose-free hierarchical memory. arXiv preprint arXiv:2602.02393 (2026) 4
-
[54]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
Wu, T., Yang, S., Po, R., Xu, Y., Liu, Z., Lin, D., Wetzstein, G.: Video world models with long-term spatial memory. arXiv preprint arXiv:2506.05284 (2025) 1
-
[55]
arXiv preprint arXiv:2602.07854 (2026) 4
Xiang, C., Liu, J., Zhang, J., Yang, X., Fang, Z., Wang, S., Wang, Z., Zou, Y., Su, H., Zhu, J.: Geometry-aware rotary position embedding for consistent video world model. arXiv preprint arXiv:2602.07854 (2026) 4
-
[56]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Xiao, Z., Lan, Y., Zhou, Y., Ouyang, W., Yang, S., Zeng, Y., Pan, X.: Worldmem: Long-term consistent world simulation with memory. arXiv preprint arXiv:2504.12369 (2025) 4
-
[57]
arXiv preprint arXiv:2601.15281 (2026) 1
Yang, Y., Lv, Z., Pan, T., Wang, H., Yang, B., Yin, H., Li, C., Liu, Z., Si, C.: Stableworld: Towards stable and consistent long interactive video generation. arXiv preprint arXiv:2601.15281 (2026) 1
-
[58]
arXiv preprint arXiv: 2512.12751 (2025) 4
Yang, Z., Liu, Z., Lu, Y., Hou, L., Miao, C., Peng, S., Feng, B., Bai, X., Zhao, H.: Geniedrive: Towards physics-aware driving world model with 4d occupancy guided video generation. arXiv preprint arXiv: 2512.12751 (2025) 4
-
[59]
arXiv preprint arXiv: 2412.08410 (2024) 4 20 H
Yang, Z., Guo, X., Ding, C., Wang, C., Wu, W.: Physical informed driving world model. arXiv preprint arXiv: 2412.08410 (2024) 4 20 H. Wu et al
-
[60]
arXiv preprint arXiv:2503.14070 (2025) 4
Ye, Y., Guo, J., Wu, H., He, T., Pearce, T., Rashid, T., Hofmann, K., Bian, J.: Fast autoregressive video generation with diagonal decoding. arXiv preprint arXiv:2503.14070 (2025) 4
- [61]
-
[62]
Yu, J., Bai, J., Qin, Y., Liu, Q., Wang, X., Wan, P., Zhang, D., Liu, X.: Context as memory: Scene-consistent interactive long video generation with memory retrieval. arXiv preprint arXiv: 2506.03141 (2025) 4
-
[63]
A survey of interactive generative video.arXiv preprint arXiv:2504.21853, 2025
Yu, J., Qin, Y., Che, H., Liu, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Chen, H., Liu, X.: A survey of interactive generative video. arXiv preprint arXiv:2504.21853 (2025) 4
-
[64]
Yu, J., Qin, Y., Wang, X., Wan, P., Zhang, D., Liu, X.: Gamefactory: Creating new games with generative interactive videos (2025) 4
2025
-
[65]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[66]
Yuan, S., Yin, Y., Li, Z., Huang, X., Yang, X., Yuan, L.: Helios: Real real-time long video generation model. arXiv preprint arXiv: 2603.04379 (2026) 4
-
[67]
Zhang, H., Wang, Z., Lyu, Q., Zhang, Z., Chen, S., Shu, T., Du, Y., Gan, C.: Combo: Compositional world models for embodied multi-agent cooperation. arXiv preprint arXiv:2404.10775 (2024) 2, 4, 12, 13
-
[68]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 9
2018
-
[69]
Empowering Multi-Robot Cooperation via Sequential World Models
Zhao, Z., Guo, H., Chen, S., Xu, K., Jiang, B., Zhu, Y., Zhao, D.: Em- powering multi-robot cooperation via sequential world models. arXiv preprint arXiv:2509.13095 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Tesseract: Learning 4d embodied world models, 2025
Zhen, H., Sun, Q., Zhang, H., Li, J., Zhou, S., Du, Y., Gan, C.: Tesseract: learning 4d embodied world models. arXiv preprint arXiv:2504.20995 (2025) 4
-
[71]
Flare: Robot learning with implicit world modeling, 2025
Zheng, R., Wang, J., Reed, S., Bjorck, J., Fang, Y., Hu, F., Jang, J., Kundalia, K., Lin, Z., Magne, L., et al.: Flare: Robot learning with implicit world modeling. arXiv preprint arXiv:2505.15659 (2025) 4
-
[72]
arXiv preprint arXiv: 2507.00603 (2025) 4
Zheng, Y., Yang, P., Xing, Z., Zhang, Q., Zheng, Y., Gao, Y., Li, P., Zhang, T., Xia, Z., Jia, P., Zhao, D.: World4drive: End-to-end autonomous driving via intention- aware physical latent world model. arXiv preprint arXiv: 2507.00603 (2025) 4
-
[73]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Zhu, F., Wu, H., Guo, S., Liu, Y., Cheang, C., Kong, T.: Irasim: A fine-grained world model for robot manipulation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 9834–9844 (2025) 4
2025
-
[74]
Wmpo: World model-based policy optimization for vision-language-action models, 2025
Zhu, F., Yan, Z., Hong, Z., Shou, Q., Ma, X., Guo, S.: Wmpo: World model- based policy optimization for vision-language-action models. arXiv preprint arXiv: 2511.09515 (2025) 4
-
[75]
Zhu, H., Zhao, M., He, G., Su, H., Li, C., Zhu, J.: Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video genera- tion. arXiv preprint arXiv: 2602.02214 (2026) 4 MultiWorld 1 Appendix forMultiWorld: Scalable Multi-Agent Multi-View Video World Models A Dataset Construction Video Game Dataset.We collec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.