Recognition: unknown
Local Linearity of LLMs Enables Activation Steering via Model-Based Linear Optimal Control
Pith reviewed 2026-05-10 02:28 UTC · model grok-4.3
The pith
Local linearity of LLM layers allows closed-loop linear quadratic regulator control for activation steering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
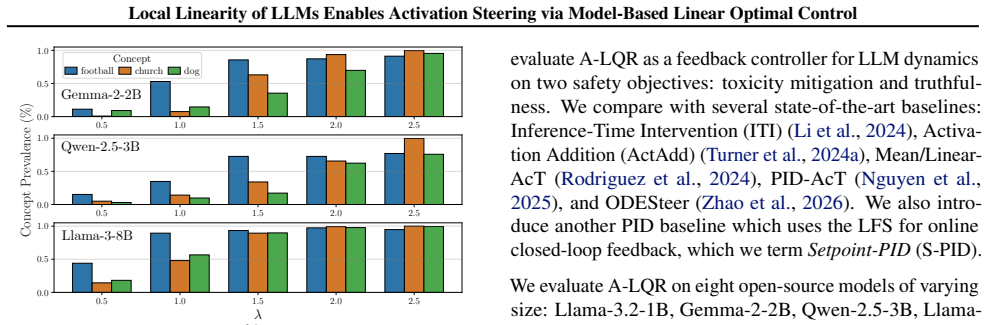
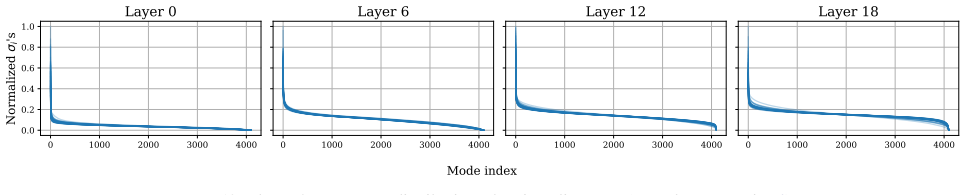
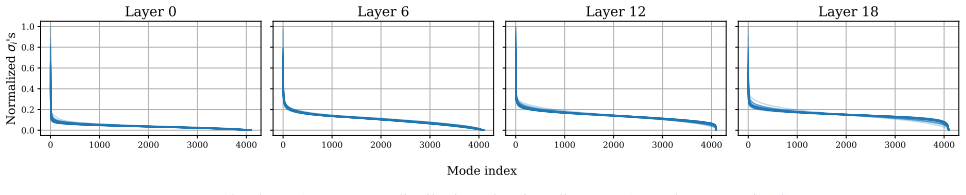
Despite the nonlinear structure of transformer blocks, layer-wise dynamics across multiple LLM architectures and scales are well-approximated by locally-linear models. Exploiting this property, we model LLM inference as a linear time-varying dynamical system and adapt the classical linear quadratic regulator to compute feedback controllers using layer-wise Jacobians, steering activations toward desired semantic setpoints in closed-loop with minimal computational overhead and no offline training. We also derive theoretical bounds on setpoint tracking error.
What carries the argument
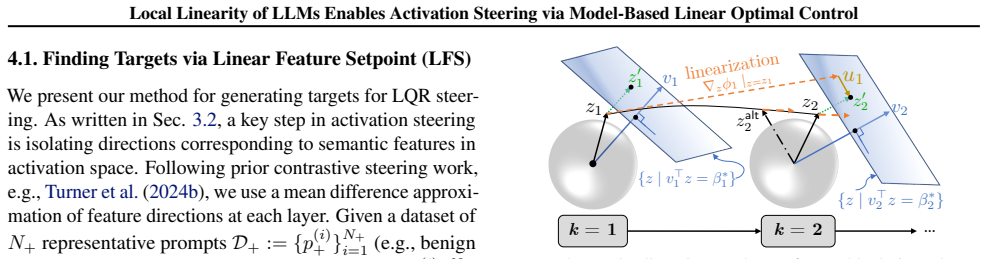
The locally-linear approximation of layer-wise dynamics, which enables adapting the linear quadratic regulator to provide Jacobian-based feedback controllers for closed-loop activation steering.
If this is right
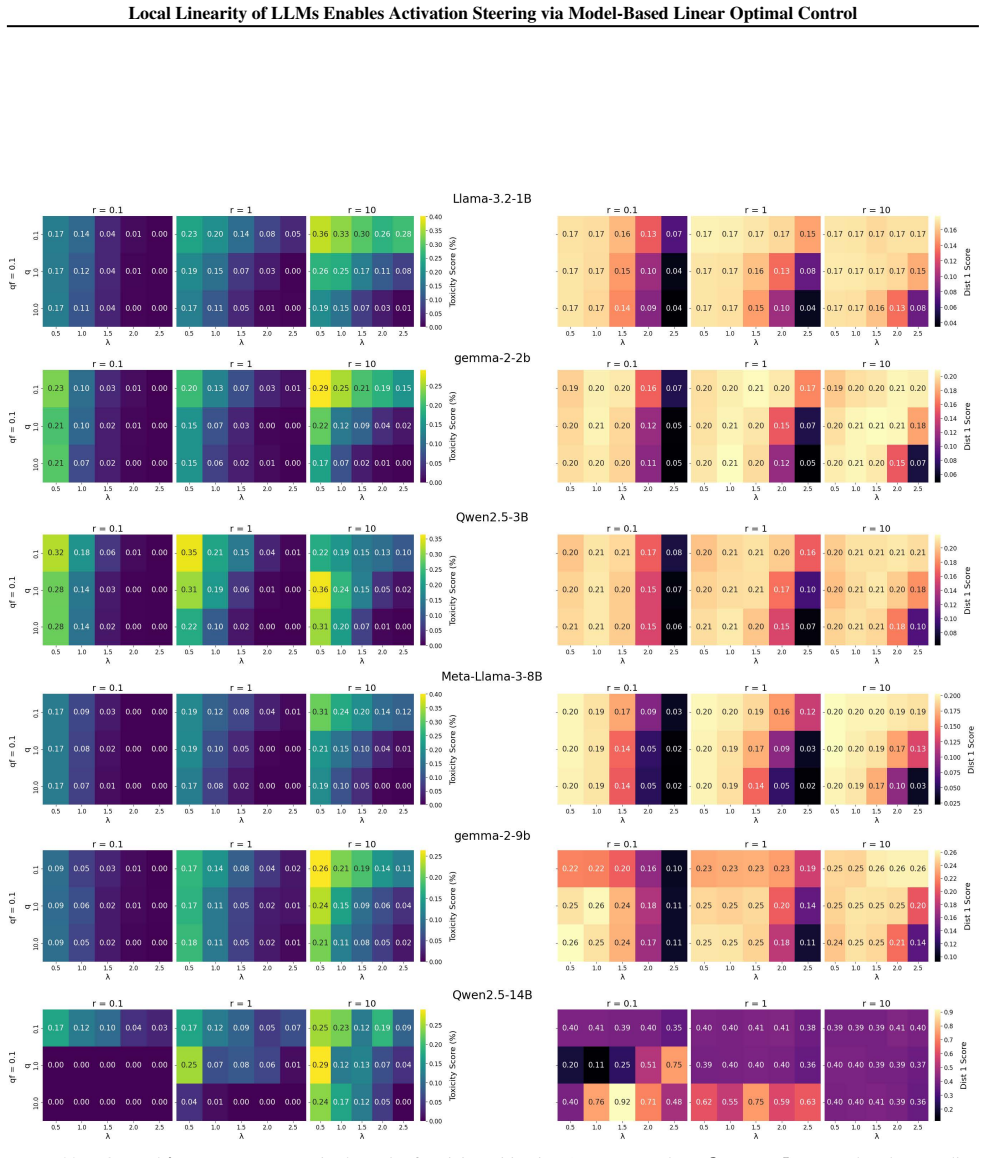
- Steering achieves robust, fine-grained behavior control across models, scales, and tasks.
- Surpasses baseline methods in modulating toxicity, truthfulness, refusal, and arbitrary concepts.
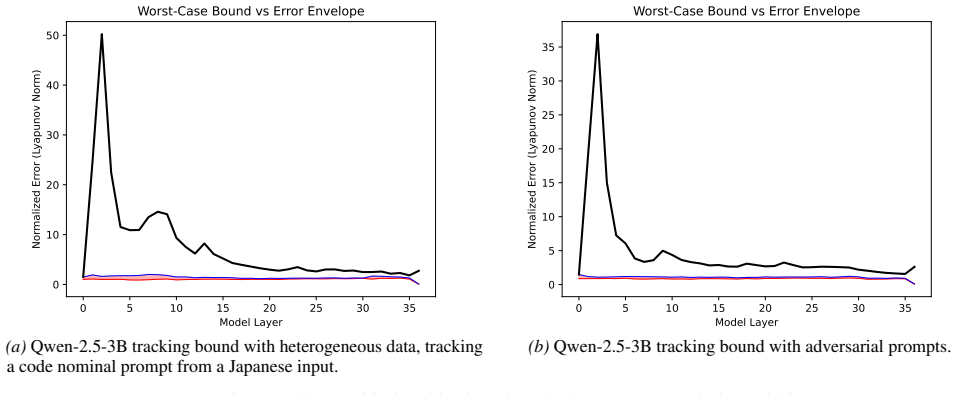
- Provides formal performance guarantees via derived bounds on setpoint tracking error.
- Operates with minimal computational overhead and requires no offline training.
Where Pith is reading between the lines
- If local linearity holds more generally, other classical control techniques such as model predictive control could be adapted for LLM internals.
- The method suggests activation steering can be reframed as an online control problem rather than a static intervention.
- Success here raises the possibility of designing or fine-tuning models to preserve or strengthen layer-wise linearity for easier control.
Load-bearing premise
Layer-wise dynamics remain sufficiently linear over the full generation trajectory for the LQR feedback to keep tracking errors low and stable.
What would settle it
If the Jacobian-based LQR controller produces higher activation deviation from semantic setpoints than open-loop baselines on a held-out model scale or task, the local linearity is not sufficient for reliable control.
Figures












read the original abstract
Inference-time LLM alignment methods, particularly activation steering, offer an alternative to fine-tuning by directly modifying activations during generation. Existing methods, however, often rely on non-anticipative interventions that ignore how perturbations propagate through transformer layers and lack online error feedback, resulting in suboptimal, open-loop control. To address this, we show empirically that, despite the nonlinear structure of transformer blocks, layer-wise dynamics across multiple LLM architectures and scales are well-approximated by locally-linear models. Exploiting this property, we model LLM inference as a linear time-varying dynamical system and adapt the classical linear quadratic regulator to compute feedback controllers using layer-wise Jacobians, steering activations toward desired semantic setpoints in closed-loop with minimal computational overhead and no offline training. We also derive theoretical bounds on setpoint tracking error, enabling formal guarantees on steering performance. Using a novel adaptive semantic feature setpoint signal, our method yields robust, fine-grained behavior control across models, scales, and tasks, including state-of-the-art modulation of toxicity, truthfulness, refusal, and arbitrary concepts, surpassing baseline steering methods. Our code is available at: https://github.com/trustworthyrobotics/lqr-activation-steering
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that despite the nonlinear structure of transformer blocks, layer-wise dynamics in LLMs are well-approximated by locally linear models across architectures and scales; it models inference as a linear time-varying system, adapts classical LQR to compute Jacobian-based feedback controllers for closed-loop steering of activations to adaptive semantic setpoints, derives theoretical bounds on tracking error, and reports superior empirical performance on toxicity, truthfulness, refusal, and concept modulation tasks with no offline training.
Significance. If the local-linearity assumption holds over full trajectories, the work supplies a control-theoretic framework for activation steering that combines empirical validation, formal error bounds, and reproducible code; this could advance inference-time alignment by replacing heuristic open-loop interventions with stable, low-overhead feedback control and quantifiable guarantees.
major comments (2)
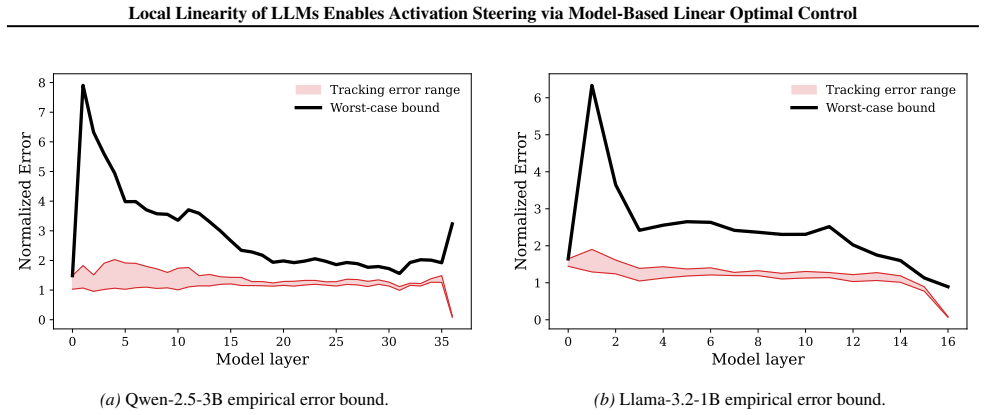
- [§3] §3 (empirical linearity checks): the reported approximation quality and Jacobian-based residuals are shown at selected points or short horizons, but the manuscript does not quantify how these residuals evolve or remain bounded over complete generation trajectories; this directly affects whether the LQR closed-loop eigenvalues stay stable and whether the derived tracking-error bounds remain tight, as required by the central claim.
- [§4.2] §4.2 (LQR formulation and error bounds): the tracking-error bounds are stated to scale with the linearization residual, yet the experiments do not report a direct comparison between predicted bound values and observed setpoint errors across models or tasks; without this calibration the formal guarantees' practical relevance is difficult to assess.
minor comments (2)
- [§4] The choice and sensitivity analysis of the LQR weighting matrices Q and R (free parameters) are not detailed; a brief ablation or default-setting justification would clarify reproducibility.
- [§5] Figure captions and the adaptive semantic-feature setpoint definition would benefit from an explicit equation or pseudocode block to make the online adaptation rule unambiguous.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified important opportunities to strengthen the empirical support for our local-linearity claims and the practical calibration of our theoretical bounds. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (empirical linearity checks): the reported approximation quality and Jacobian-based residuals are shown at selected points or short horizons, but the manuscript does not quantify how these residuals evolve or remain bounded over complete generation trajectories; this directly affects whether the LQR closed-loop eigenvalues stay stable and whether the derived tracking-error bounds remain tight, as required by the central claim.
Authors: We agree that explicit quantification of residual evolution over full trajectories is needed to rigorously support stability of the closed-loop eigenvalues and tightness of the tracking bounds. Our current experiments evaluate residuals at representative points and short segments during generation, which is consistent with the local-linearity hypothesis but does not fully address long-horizon behavior. In the revised manuscript we will add new figures and tables showing the evolution of Jacobian-based residuals (||f(x) - Ax - b||) over complete generation sequences for the toxicity, truthfulness, refusal, and concept-modulation tasks across the evaluated models. We will also report whether residuals remain bounded and discuss any implications for eigenvalue stability within the LQR design. revision: yes
-
Referee: [§4.2] §4.2 (LQR formulation and error bounds): the tracking-error bounds are stated to scale with the linearization residual, yet the experiments do not report a direct comparison between predicted bound values and observed setpoint errors across models or tasks; without this calibration the formal guarantees' practical relevance is difficult to assess.
Authors: We appreciate this observation. The derived bounds explicitly depend on the linearization residual, and a side-by-side comparison with observed errors would better demonstrate the tightness and practical utility of the guarantees. In the revision we will include a new table (or supplementary figure) that computes the theoretical tracking-error bounds from the measured residuals for each model and task, then directly compares these predicted values against the empirical setpoint tracking errors reported in our experiments. This calibration will be accompanied by discussion of any observed discrepancies and their relation to the local-linearity assumption. revision: yes
Circularity Check
No significant circularity: empirical linearity check + standard LQR + derived bounds remain independent of fitted inputs
full rationale
The derivation begins with an empirical claim that layer-wise transformer dynamics are locally linear (validated across models and scales), models inference as an LTV system, applies the classical LQR controller using computed Jacobians, and derives tracking-error bounds that explicitly depend on the linearization residual. None of these steps reduce by construction to quantities fitted inside the same experiment; the LQR formulation and error bounds are taken from external control theory, the linearity is presented as an empirical observation rather than a definitional assumption, and no self-citation chain is invoked to justify uniqueness or the ansatz. The central performance claims are therefore supported by external mathematics and separate empirical measurements rather than tautological renaming or self-referential fitting.
Axiom & Free-Parameter Ledger
free parameters (1)
- LQR state and control weighting matrices Q and R
axioms (1)
- domain assumption Layer-wise LLM dynamics admit a locally linear approximation whose Jacobians can be used for control
Reference graph
Works this paper leans on
-
[1]
Webb, Stefan and Rainforth, Tom and Teh, Yee Whye and Kumar, M. Pawan , year=. A Statistical Approach to Assessing Neural Network Robustness , url=. doi:10.48550/arXiv.1811.07209 , abstractNote=
-
[2]
Wu, Gabriel and Hilton, Jacob , year=. Estimating the Probabilities of Rare Outputs in Language Models , url=. doi:10.48550/arXiv.2410.13211 , abstractNote=
-
[3]
s-nlp/roberta\_toxicity\_classifier Model
Roberta. s-nlp/roberta\_toxicity\_classifier Model. 2026
2026
-
[4]
A Koopman framework for rare event simulation in stochastic differential equations , url=
Zhang, Benjamin and Sahai, Tuhin and Marzouk, Youssef , year=. A Koopman framework for rare event simulation in stochastic differential equations , url=. doi:10.48550/arXiv.2101.07330 , abstractNote=
-
[5]
IEEE Robotics and Automation Letters , volume=
Planning with learned dynamics: Probabilistic guarantees on safety and reachability via lipschitz constants , author=. IEEE Robotics and Automation Letters , volume=. 2021 , publisher=
2021
-
[6]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[7]
Jailbroken: How Does LLM Safety Training Fail?
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , year=. Jailbroken: How Does LLM Safety Training Fail? , url=. doi:10.48550/arXiv.2307.02483 , abstractNote=
work page internal anchor Pith review doi:10.48550/arxiv.2307.02483
-
[8]
Machine Learning: Science and Technology , author=
Neural scaling laws from large- N field theory: solvable model beyond the ridgeless limit , volume=. Machine Learning: Science and Technology , author=. 2025 , month=jun, pages=. doi:10.1088/2632-2153/adc872 , abstractNote=
-
[9]
Rigorous agent evaluation: An adversarial approach to uncover catastrophic failures,
Uesato, Jonathan and Kumar, Ananya and Szepesvari, Csaba and Erez, Tom and Ruderman, Avraham and Anderson, Keith and Krishmamurthy and Dvijotham and Heess, Nicolas and Kohli, Pushmeet , year=. Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures , url=. doi:10.48550/arXiv.1812.01647 , abstractNote=
-
[10]
Efficient Sampling Methods of, by, and for Stochastic Dynamical Systems , rights=
Zhang, Benjamin Jiahong , year=. Efficient Sampling Methods of, by, and for Stochastic Dynamical Systems , rights=
-
[11]
Journal of Statistical Physics , author=
Simulating Rare Events in Dynamical Processes , volume=. Journal of Statistical Physics , author=. 2011 , month=nov, pages=. doi:10.1007/s10955-011-0350-4 , abstractNote=
-
[12]
and Chen, Mo and Tomlin, Claire J
Fisac, Jaime F. and Chen, Mo and Tomlin, Claire J. and Sastry, S. Shankar , year=. Reach-avoid problems with time-varying dynamics, targets and constraints , ISBN=. doi:10.1145/2728606.2728612 , booktitle=
-
[13]
Variational approach to rare event simulation using least-squares regression , url=
Hartmann, Carsten and Kebiri, Omar and Neureither, Lara and Richter, Lorenz , year=. Variational approach to rare event simulation using least-squares regression , url=. doi:10.48550/arXiv.1901.09195 , abstractNote=
-
[14]
Journal of the Franklin Institute , author=
An approximate method of stochastic terminal control for nonlinear dynamical systems , volume=. Journal of the Franklin Institute , author=. 1970 , month=mar, pages=. doi:10.1016/0016-0032(70)90286-3 , abstractNote=
-
[15]
Silva, Samuel Henrique and Najafirad, Peyman , year=. Opportunities and Challenges in Deep Learning Adversarial Robustness: A Survey , url=. doi:10.48550/arXiv.2007.00753 , abstractNote=
-
[16]
Kruse, Liam A. and Schlichting, Marc R. and Kochenderfer, Mykel J. , year=. Scalable Importance Sampling in High Dimensions with Low-Rank Mixture Proposals , url=. doi:10.48550/arXiv.2505.13335 , abstractNote=
-
[17]
Chaos: An Interdisciplinary Journal of Nonlinear Science , author=
Rare Event Sampling Methods , volume=. Chaos: An Interdisciplinary Journal of Nonlinear Science , author=. 2019 , month=aug, pages=. doi:10.1063/1.5120509 , number=
-
[18]
Bengtsson, Thomas and Bickel, Peter and Li, Bo , year=. Curse-of-dimensionality revisited: Collapse of the particle filter in very large scale systems , url=. doi:10.48550/arXiv.0805.3034 , abstractNote=
-
[19]
Quantifying uncertainty, variability and likelihood for ordinary differential equation models , volume=. BMC Systems Biology , author=. 2010 , month=dec, pages=. doi:10.1186/1752-0509-4-144 , number=
-
[20]
Computational Doob h-transforms for Online Filtering of Discretely Observed Diffusions , url=
Chopin, Nicolas , year=. Computational Doob h-transforms for Online Filtering of Discretely Observed Diffusions , url=
-
[21]
2019 , url =
Simon Särkkä and Arno Solin , title =. 2019 , url =
2019
-
[22]
Tomasetto, Matteo and Manzoni, Andrea and Braghin, Francesco , year=. Real-time optimal control of high-dimensional parametrized systems by deep learning-based reduced order models , url=. doi:10.48550/arXiv.2409.05709 , abstractNote=
-
[23]
IEEE Robotics and Automation Letters , author=
Biased-MPPI: Informing Sampling-Based Model Predictive Control by Fusing Ancillary Controllers , volume=. IEEE Robotics and Automation Letters , author=. 2024 , month=jun, pages=. doi:10.1109/LRA.2024.3397083 , abstractNote=
-
[24]
arXiv preprint arXiv:2301.06227 , year=
Wu, Guangyu and Lindquist, Anders , year=. General Distribution Steering: A Sub-Optimal Solution by Convex Optimization , url=. doi:10.48550/arXiv.2301.06227 , abstractNote=
-
[25]
Pilipovsky, Joshua and Sivaramakrishnan, Vignesh and Oishi, Meeko M. K. and Tsiotras, Panagiotis , year=. Probabilistic Verification of ReLU Neural Networks via Characteristic Functions , url=. doi:10.48550/arXiv.2212.01544 , abstractNote=
-
[26]
Rapakoulias, George and Tsiotras, Panagiotis , year=. Discrete-Time Maximum Likelihood Neural Distribution Steering , rights=. doi:10.1109/CDC56724.2024.10885992 , booktitle=
-
[27]
arXiv preprint arXiv:2405.15454 , year=
Cheng, Emily and Alonso, Carmen Amo , year=. Linearly Controlled Language Generation with Performative Guarantees , url=. doi:10.48550/arXiv.2405.15454 , abstractNote=
-
[28]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander , year=. Steering Llama 2 via Contrastive Activation Addition , url=. doi:10.18653/v1/2024.acl-long.828 , booktitle=
-
[29]
Amatucci, Lorenzo and Sousa-Pinto, João and Turrisi, Giulio and Orban, Dominique and Barasuol, Victor and Semini, Claudio , year=. Primal-Dual iLQR for GPU-Accelerated Learning and Control in Legged Robots , url=. doi:10.48550/arXiv.2506.07823 , abstractNote=
-
[30]
Mechanistic interpretability for steering vision-language-action models , url=
Häon, Bear and Stocking, Kaylene and Chuang, Ian and Tomlin, Claire , year=. Mechanistic interpretability for steering vision-language-action models , url=. doi:10.48550/arXiv.2509.00328 , abstractNote=
-
[31]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , year=. Refusal in Language Models Is Mediated by a Single Direction , url=. doi:10.48550/arXiv.2406.11717 , abstractNote=
work page internal anchor Pith review doi:10.48550/arxiv.2406.11717
-
[32]
Preemptive Detection and Steering of LLM Misalignment via Latent Reachability , url=
Karnik, Sathwik and Bansal, Somil , year=. Preemptive Detection and Steering of LLM Misalignment via Latent Reachability , url=. doi:10.48550/arXiv.2509.21528 , abstractNote=
-
[33]
2013 IEEE International Conference on Robotics and Automation , author=
Optimal sampling-based planning for linear-quadratic kinodynamic systems , ISSN=. 2013 IEEE International Conference on Robotics and Automation , author=. 2013 , month=may, pages=. doi:10.1109/ICRA.2013.6630907 , abstractNote=
-
[34]
Nguyen, Dung V. and Vu, Hieu M. and Pham, Nhi Y. and Zhang, Lei and Nguyen, Tan M. , year=. Activation Steering with a Feedback Controller , url=. doi:10.48550/arXiv.2510.04309 , abstractNote=
-
[35]
arXiv preprint arXiv:2407.15549 , year=
Sheshadri, Abhay and Ewart, Aidan and Guo, Phillip and Lynch, Aengus and Wu, Cindy and Hebbar, Vivek and Sleight, Henry and Stickland, Asa Cooper and Perez, Ethan and Hadfield-Menell, Dylan and Casper, Stephen , year=. Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs , url=. doi:10.48550/arXiv.2407.15549 , abstractNote=
-
[36]
Monnier, John D. and Jain, Prachet and Gutierrez, Mayra and Han, Chi and Hezi, Sara and Kalluri, Shashank and Kabaria, Hirsh and Kompas, Brennan and Harikumar, Vaishnavi and Skifstad, Julian and Peri, Janani and Hernandez, Emmanuel and Bhaskarapanthula, Ramya and Cutler, James , year=. Prospects for using drones to test formation-flying CubeSat concepts, ...
-
[37]
Explaining and Harnessing Adversarial Examples
Goodfellow, Ian J. and Shlens, Jonathon and Szegedy, Christian , year=. Explaining and Harnessing Adversarial Examples , url=. doi:10.48550/arXiv.1412.6572 , abstractNote=
work page internal anchor Pith review doi:10.48550/arxiv.1412.6572
-
[38]
Propagation of Uncertainty with the Koopman Operator , url=
Servadio, Simone and Lavezzi, Giovanni and Hofmann, Christian and Wu, Di and Linares, Richard , year=. Propagation of Uncertainty with the Koopman Operator , url=. doi:10.48550/arXiv.2407.20170 , abstractNote=
-
[39]
arXiv preprint arXiv:2410.23054 (2024)
Rodriguez, Pau and Blaas, Arno and Klein, Michal and Zappella, Luca and Apostoloff, Nicholas and Cuturi, Marco and Suau, Xavier , year=. Controlling Language and Diffusion Models by Transporting Activations , url=. doi:10.48550/arXiv.2410.23054 , abstractNote=
-
[40]
European Symposium on Programming , pages=
Neural network verification is a programming language challenge , author=. European Symposium on Programming , pages=. 2025 , organization=
2025
-
[41]
Steering Language Models With Activation Engineering
Turner, Alexander Matt and Thiergart, Lisa and Leech, Gavin and Udell, David and Vazquez, Juan J. and Mini, Ulisse and MacDiarmid, Monte , year=. Steering Language Models With Activation Engineering , url=. doi:10.48550/arXiv.2308.10248 , abstractNote=
work page internal anchor Pith review doi:10.48550/arxiv.2308.10248
-
[42]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , shorttitle =
Li, Kenneth and Patel, Oam and Viégas, Fernanda and Pfister, Hanspeter and Wattenberg, Martin , year=. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url=. doi:10.48550/arXiv.2306.03341 , abstractNote=
-
[43]
A language model's guide through latent space
Rütte, Dimitri von and Anagnostidis, Sotiris and Bachmann, Gregor and Hofmann, Thomas , year=. A Language Model’s Guide Through Latent Space , url=. doi:10.48550/arXiv.2402.14433 , abstractNote=
-
[44]
and Bewley, Tom and Mishra, Saumitra and Veloso, Manuela , title =
Hedström, Anna and Amoukou, Salim I. and Bewley, Tom and Mishra, Saumitra and Veloso, Manuela , title =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , address =
2025
-
[45]
arXiv preprint arXiv:2510.26243 (2025) 8
Vu, Hieu M. and Nguyen, Tan M. , year=. Angular Steering: Behavior Control via Rotation in Activation Space , url=. doi:10.48550/arXiv.2510.26243 , abstractNote=
-
[46]
Geiger, Atticus and Wu, Zhengxuan and Potts, Christopher and Icard, Thomas and Goodman, Noah D. , year=. Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , url=. doi:10.48550/arXiv.2303.02536 , abstractNote=
-
[47]
Safe Large-Scale Robust Nonlinear MPC in Milliseconds via Reachability-Constrained System Level Synthesis on the GPU , author=. arXiv preprint arXiv:2604.07644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Abdelzaher and Yejin Choi and Manling Li and Huajie Shao , booktitle=
Hongjue Zhao and Haosen Sun and Jiangtao Kong and Xiaochang Li and Qineng Wang and Liwei Jiang and Qi Zhu and Tarek F. Abdelzaher and Yejin Choi and Manling Li and Huajie Shao , booktitle=. 2026 , url=
2026
-
[49]
arXiv preprint arXiv:2301.13729 , year=
Low-rank LQR Optimal Control Design over Wireless Communication Networks , author=. arXiv preprint arXiv:2301.13729 , year=
-
[50]
Safety Beyond the Training Data: Robust Out-of-Distribution MPC via Conformalized System Level Synthesis , author=. arXiv preprint arXiv:2602.12047 , year=
-
[51]
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and Grosse, Roger and McCandlish, Sam and Kaplan, Jared and Amodei, Dario and Wattenberg, Martin and Olah, Christopher , year=. Toy Models of Superposition , url=. do...
work page internal anchor Pith review doi:10.48550/arxiv.2209.10652
-
[52]
doi:10.48550/arXiv.2410.02707 , abstract =
Orgad, Hadas and Toker, Michael and Gekhman, Zorik and Reichart, Roi and Szpektor, Idan and Kotek, Hadas and Belinkov, Yonatan , year=. LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , url=. doi:10.48550/arXiv.2410.02707 , abstractNote=
-
[53]
and Vrabie, Draguna L
Lewis, Frank L. and Vrabie, Draguna L. and Syrmos, Vassilis L. , title =
-
[54]
thought” of LLM by finding the “circuit
Gemma Team , year=. Gemma , url=. doi:10.34740/KAGGLE/M/3301 , publisher=
-
[55]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[56]
Realtoxicityprompts: Evaluating neural toxic degenera- tion in language models
Realtoxicityprompts: Evaluating neural toxic degeneration in language models , author=. arXiv preprint arXiv:2009.11462 , year=
-
[57]
Aligning Large Language Models with Representation Editing: A Control Perspective , url=
Kong, Lingkai and Wang, Haorui and Mu, Wenhao and Du, Yuanqi and Zhuang, Yuchen and Zhou, Yifei and Song, Yue and Zhang, Rongzhi and Wang, Kai and Zhang, Chao , year=. Aligning Large Language Models with Representation Editing: A Control Perspective , url=. doi:10.48550/arXiv.2406.05954 , abstractNote=
-
[58]
arXiv preprint arXiv:2308.05374 , year=
Trustworthy llms: a survey and guideline for evaluating large language models' alignment , author=. arXiv preprint arXiv:2308.05374 , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Jailbroken: How does llm safety training fail? , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[61]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[62]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[63]
arXiv preprint arXiv:2402.01694 , year=
Args: Alignment as reward-guided search , author=. arXiv preprint arXiv:2402.01694 , year=
-
[64]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review arXiv
-
[65]
Meng, K., Bau, D., Andonian, A., and Belinkov, Y
The unlocking spell on base llms: Rethinking alignment via in-context learning , author=. arXiv preprint arXiv:2312.01552 , year=
-
[66]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Statistical safety and robustness guarantees for feedback motion planning of unknown underactuated stochastic systems , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[67]
Mechanistic Interpretability for
Leonard Bereska and Stratis Gavves , journal=. Mechanistic Interpretability for. 2024 , url=
2024
-
[68]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review arXiv
-
[69]
arXiv preprint arXiv:2305.18449 , year=
Taming ai bots: Controllability of neural states in large language models , author=. arXiv preprint arXiv:2305.18449 , year=
-
[70]
2012 , publisher=
Optimal control , author=. 2012 , publisher=
2012
-
[71]
Yulin Luo, Ruichuan An, Bocheng Zou, Yiming Tang, Jiaming Liu, and Shanghang Zhang
Prompt engineering through the lens of optimal control , author=. arXiv preprint arXiv:2310.14201 , year=
-
[72]
Contributions to the theory of optimal control , author=. Bol. soc. mat. mexicana , volume=
-
[73]
arXiv preprint arXiv:2310.04444 , year=
What's the magic word? a control theory of llm prompting , author=. arXiv preprint arXiv:2310.04444 , year=
-
[74]
Advances in Neural Information Processing Systems , volume=
Analysing the generalisation and reliability of steering vectors , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
Dong Shu, Xuansheng Wu, Haiyan Zhao, Daking Rai, Ziyu Yao, Ninghao Liu, and Mengnan Du
Multi-property steering of large language models with dynamic activation composition , author=. arXiv preprint arXiv:2406.17563 , year=
-
[76]
arXiv preprint arXiv:2408.15625 , year=
Cbf-llm: Safe control for llm alignment , author=. arXiv preprint arXiv:2408.15625 , year=
-
[77]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[78]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation , author=. arXiv preprint arXiv:2401.08417 , year=
-
[80]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Preference ranking optimization for human alignment , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.