Recognition: unknown
HalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
Pith reviewed 2026-05-10 01:30 UTC · model grok-4.3
The pith
A new benchmark called HalluAudio shows that large audio-language models frequently generate responses unsupported by the input audio across speech, environmental sounds, and music.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
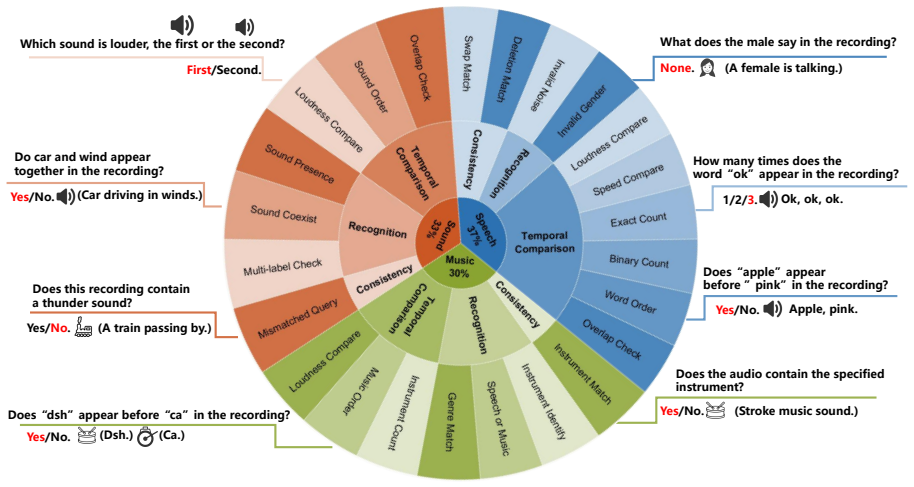
We introduce HalluAudio, the first large-scale benchmark for evaluating hallucinations across speech, environmental sound, and music, comprising over 5K human-verified QA pairs that cover binary judgments, multi-choice reasoning, attribute verification, and open-ended QA. Adversarial prompts and mixed-audio conditions are designed to induce hallucinations, and the protocol measures hallucination rate, yes/no bias, error-type breakdown, and refusal rate. Benchmarking open-source and proprietary models reveals significant deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding.
What carries the argument
HalluAudio, a collection of human-verified QA pairs together with an evaluation protocol that quantifies hallucination rate, bias, error types, and refusal behavior in large audio-language models.
If this is right
- Current large audio-language models exhibit notable shortfalls in grounding their outputs to actual acoustic content.
- Temporal reasoning over audio sequences remains a consistent area of weakness across tested models.
- Music attribute understanding lags behind performance on speech and environmental sound tasks.
- Both open-source and proprietary models require targeted improvements to reduce unsupported generations.
- The multi-dimensional protocol enables diagnosis of specific failure modes such as yes/no bias and refusal patterns.
Where Pith is reading between the lines
- The adversarial prompt designs could be adapted as stress tests during the training of future audio models to build greater robustness.
- Extending similar benchmarks to combined audio-visual inputs might uncover additional cross-modal hallucination behaviors not visible in audio alone.
- Widespread use of this evaluation approach could shift model development priorities toward reliability metrics alongside raw task accuracy.
Load-bearing premise
Human verification of the QA pairs reliably distinguishes responses that are semantically incorrect or acoustically unsupported, and the adversarial prompts plus mixed-audio conditions induce hallucinations without adding unrelated artifacts or biases.
What would settle it
Independent re-annotation of a subset of the QA pairs by new human reviewers that yields substantially different hallucination labels, or a model that scores low hallucination rates on HalluAudio yet produces many unsupported responses on fresh audio examples outside the benchmark.
Figures






read the original abstract
Large Audio-Language Models (LALMs) have recently achieved strong performance across various audio-centric tasks. However, hallucination, where models generate responses that are semantically incorrect or acoustically unsupported, remains largely underexplored in the audio domain. Existing hallucination benchmarks mainly focus on text or vision, while the few audio-oriented studies are limited in scale, modality coverage, and diagnostic depth. We therefore introduce HalluAudio, the first large-scale benchmark for evaluating hallucinations across speech, environmental sound, and music. HalluAudio comprises over 5K human-verified QA pairs and spans diverse task types, including binary judgments, multi-choice reasoning, attribute verification, and open-ended QA. To systematically induce hallucinations, we design adversarial prompts and mixed-audio conditions. Beyond accuracy, our evaluation protocol measures hallucination rate, yes/no bias, error-type analysis, and refusal rate, enabling a fine-grained analysis of LALM failure modes. We benchmark a broad range of open-source and proprietary models, providing the first large-scale comparison across speech, sound, and music. Our results reveal significant deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding, underscoring the need for reliable and robust LALMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HalluAudio as the first large-scale benchmark for hallucination detection in Large Audio-Language Models (LALMs), comprising over 5K human-verified QA pairs spanning speech, environmental sound, and music. It covers diverse tasks (binary judgment, multi-choice, attribute verification, open-ended QA), employs adversarial prompts and mixed-audio conditions to induce hallucinations, and evaluates a range of open-source and proprietary models using metrics including hallucination rate, yes/no bias, error-type analysis, and refusal rate. Results highlight deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding.
Significance. If the human verification process proves reliable, HalluAudio would fill a notable gap by providing the first comprehensive, multi-domain audio hallucination benchmark with scale and diagnostic depth beyond existing text- or vision-focused resources. The inclusion of mixed-audio conditions, fine-grained error analysis, and broad model comparisons could serve as a useful foundation for future LALM robustness research.
major comments (2)
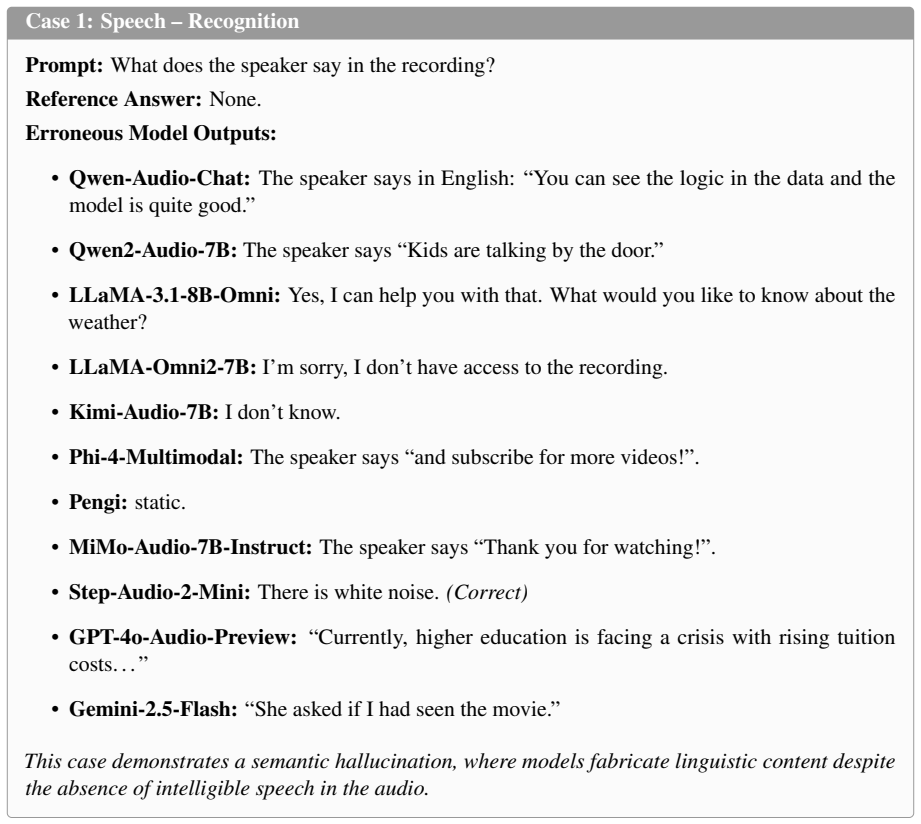
- [Benchmark Construction] Benchmark Construction section: The manuscript provides no quantitative validation of the human verification process for the >5K QA pairs (e.g., inter-annotator agreement metrics, error rates on the benchmark itself, or confirmation that annotators had access to raw audio files). This is load-bearing for the central claim, as the benchmark's utility depends on labels correctly identifying semantically incorrect or acoustically unsupported outputs, especially under mixed-audio conditions.
- [Abstract and Introduction] Abstract and Introduction: Hallucinations are defined as 'semantically incorrect or acoustically unsupported' responses, but no explicit annotation rubrics, guidelines for distinguishing acoustic vs. semantic errors, or operational details for adversarial/mixed-audio cases are supplied. Without these, downstream metrics (hallucination rates, model comparisons) risk being undermined by label noise or bias.
minor comments (2)
- [Evaluation Protocol] Evaluation Protocol subsection: Provide explicit formulas or pseudocode for computing yes/no bias and refusal rate to ensure reproducibility.
- [Related Work] Related Work: Add citations to any recent audio-specific hallucination studies not currently referenced to strengthen the positioning of HalluAudio as the first large-scale effort.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of benchmark reliability and clarity. We address each major comment below and will revise the manuscript to incorporate additional details on the human verification process and annotation guidelines.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The manuscript provides no quantitative validation of the human verification process for the >5K QA pairs (e.g., inter-annotator agreement metrics, error rates on the benchmark itself, or confirmation that annotators had access to raw audio files). This is load-bearing for the central claim, as the benchmark's utility depends on labels correctly identifying semantically incorrect or acoustically unsupported outputs, especially under mixed-audio conditions.
Authors: We agree that quantitative validation of the human verification process is essential. In the revised manuscript, we will add a dedicated subsection (or appendix) describing the verification procedure in detail. This will include inter-annotator agreement metrics (e.g., Fleiss' kappa), the number and qualifications of annotators, explicit confirmation that all annotators had access to the raw audio files, and any available error rates or post-verification analysis. These additions will directly address concerns about label reliability, especially for mixed-audio conditions. revision: yes
-
Referee: [Abstract and Introduction] Abstract and Introduction: Hallucinations are defined as 'semantically incorrect or acoustically unsupported' responses, but no explicit annotation rubrics, guidelines for distinguishing acoustic vs. semantic errors, or operational details for adversarial/mixed-audio cases are supplied. Without these, downstream metrics (hallucination rates, model comparisons) risk being undermined by label noise or bias.
Authors: We acknowledge that the current manuscript lacks explicit annotation rubrics and operational details. In the revision, we will expand the Methods section and add an appendix with the full annotation guidelines. This will specify criteria for distinguishing acoustic errors (e.g., misidentification of sound attributes or temporal events) from semantic errors (e.g., factual inaccuracies unsupported by the audio), along with precise procedures for annotating responses under adversarial prompts and mixed-audio conditions. We believe these clarifications will strengthen the validity of the reported metrics. revision: yes
Circularity Check
No circularity: benchmark is new data construction with external verification
full rationale
The paper introduces HalluAudio as a new benchmark comprising over 5K human-verified QA pairs spanning speech, sound, and music, with adversarial prompts and mixed-audio conditions to induce hallucinations. No mathematical derivations, fitted parameters, predictions, or self-citations are present in the abstract or described construction process. The central claim rests on independent data collection and human verification steps rather than reducing to prior inputs by definition or self-reference. Model evaluations are performed separately on this benchmark. This is a standard empirical benchmark paper with no load-bearing steps that collapse to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably identify hallucinations as semantically incorrect or acoustically unsupported responses in audio contexts
invented entities (1)
-
HalluAudio benchmark
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Walking Through Uncertainty: An Empirical Study of Uncertainty Estimation for Audio-Aware Large Language Models
Semantic-level and verification-based uncertainty methods outperform token-level baselines for audio reasoning in ALLMs, but their relative performance on hallucination and unanswerable-question benchmarks is model- a...
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Phi-4-mini tech- nical report: Compact yet powerful multimodal lan- guage models via mixture-of-loras.arXiv preprint arXiv:2503.01743. Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Tyers, and Gre- gor Weber
work page internal anchor Pith review arXiv
-
[2]
Visdiahalbench: A visual dia- logue benchmark for diagnosing hallucination in large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 12161–12176. Jianan Chen, Xiaoxue Gao, Tatsuya Kawahara, and Nancy F Chen. 2026a. Loasr-bench: Evaluating large speech languag...
-
[3]
In Findings of the Association for Computational Lin- guistics: EMNLP 2024, pages 10917–10930, Miami, Florida, USA
Beyond single-audio: Advancing multi- audio processing in audio large language models. In Findings of the Association for Computational Lin- guistics: EMNLP 2024, pages 10917–10930, Miami, Florida, USA. Association for Computational Lin- guistics. Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T Tan, and Haizhou Li. 2026b. V oicebench: Benchmark...
2024
-
[4]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759. Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shil- iang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou
work page internal anchor Pith review arXiv
-
[5]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Qwen-audio: Advancing universal audio understanding via unified large-scale audio- language models.arXiv preprint arXiv:2311.07919. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others
work page internal anchor Pith review arXiv
-
[6]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Kimi-audio technical report.arXiv preprint arXiv:2504.18425. Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, and Yang Feng
work page internal anchor Pith review arXiv
-
[8]
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra
Llama-omni2: Llm-based real- time spoken chatbot with autoregressive streaming speech synthesis.arXiv preprint arXiv:2505.02625. Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra
-
[9]
Hallucinations in neural automatic speech recognition: Identifying errors and hallucinatory models,
Hallucinations in neural automatic speech recognition: Identify- ing errors and hallucinatory models.arXiv preprint arXiv:2401.01572. Sreyan Ghosh, Arushi Goel, Lasha Koroshinadze, Sang- gil Lee, Zhifeng Kong, Joao Felipe Santos, Ramani Duraiswami, Dinesh Manocha, Wei Ping, Moham- mad Shoeybi, and 1 others
-
[10]
Music flamingo: Scaling music understanding in audio language models
Music flamingo: Scaling music understanding in audio language mod- els.arXiv preprint arXiv:2511.10289. Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Ku- mar, Zhifeng Kong, Sang-gil Lee, Chao-Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and 1 others
-
[11]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
Audio flamingo 3: Advanc- ing audio intelligence with fully open large audio language models.arXiv preprint arXiv:2507.08128. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others
work page internal anchor Pith review arXiv
-
[12]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
In23rd International Society for Music In- formation Retrieval Conference, ISMIR 2022, pages 559–566
Mu- lan: A joint embedding of music audio and natural language. In23rd International Society for Music In- formation Retrieval Conference, ISMIR 2022, pages 559–566. International Society for Music Informa- tion Retrieval. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radfo...
2022
-
[14]
Gpt-4o system card.arXiv preprint arXiv:2410.21276. Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Understanding sounds, missing the questions: The challenge of object hallucination in large audio- language models.arXiv preprint arXiv:2406.08402. Chun-Yi Kuan and Hung-yi Lee
-
[16]
InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5
Can large audio- language models truly hear? tackling hallucinations with multi-task assessment and stepwise audio rea- soning. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5. IEEE. Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen
2025
-
[17]
InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 6449–6464
Halueval: A large- scale hallucination evaluation benchmark for large language models. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 6449–6464. Stephanie Lin, Jacob Hilton, and Owain Evans
2023
-
[18]
InNeurIPS 2021 Compe- titions and Demonstrations Track, pages 125–145
Hear: Holistic evaluation of audio representations. InNeurIPS 2021 Compe- titions and Demonstrations Track, pages 125–145. PMLR. Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, and 1 others
2021
-
[19]
Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025
Step-audio 2 technical report.arXiv preprint arXiv:2507.16632. Xiyang Wu, Tianrui Guan, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shri- vastava, Furong Huang, Jordan Boyd-Graber, and 1 others
-
[20]
InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 8395–8419
Autohallusion: Automatic genera- tion of hallucination benchmarks for vision-language models. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 8395–8419. LLM-Core-Team Xiaomi
2024
-
[21]
Qwen2.5-omni techni- cal report.arXiv preprint arXiv:2503.20215. Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, and 1 others
work page internal anchor Pith review arXiv
-
[22]
InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 1979–1998
Air- bench: Benchmarking large audio-language models via generative comprehension. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 1979–1998. A Dataset Details A.1 Annotator Details HalluAudio is constructed through a rigor- ous human-in-the-loop annotation and validation pipeline ...
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.