Recognition: unknown
Walking Through Uncertainty: An Empirical Study of Uncertainty Estimation for Audio-Aware Large Language Models
Pith reviewed 2026-05-07 14:24 UTC · model grok-4.3
The pith
Semantic-level and verification-based uncertainty methods outperform token-level baselines for audio-aware LLMs on general reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish through systematic experiments that semantic-level and verification-based uncertainty estimation methods consistently outperform token-level baselines on general audio reasoning benchmarks for audio-aware large language models, whereas on trustworthiness-oriented benchmarks such as hallucination detection and unanswerable question answering the relative effectiveness of the methods is more dependent on the model and the specific benchmark.
What carries the argument
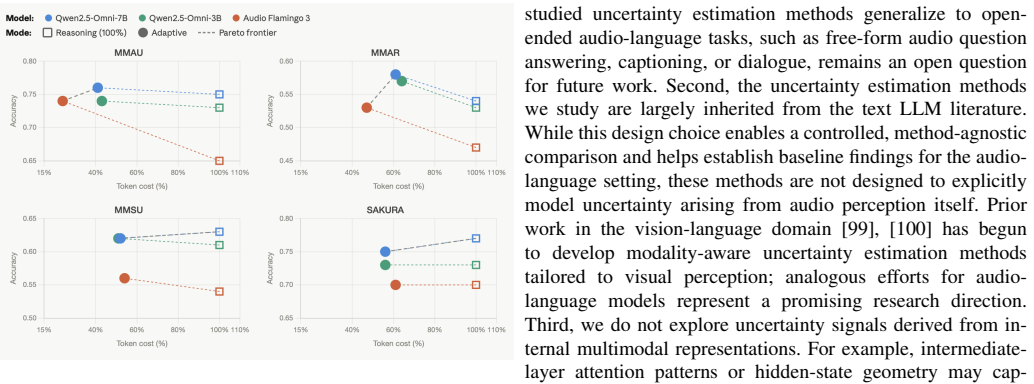
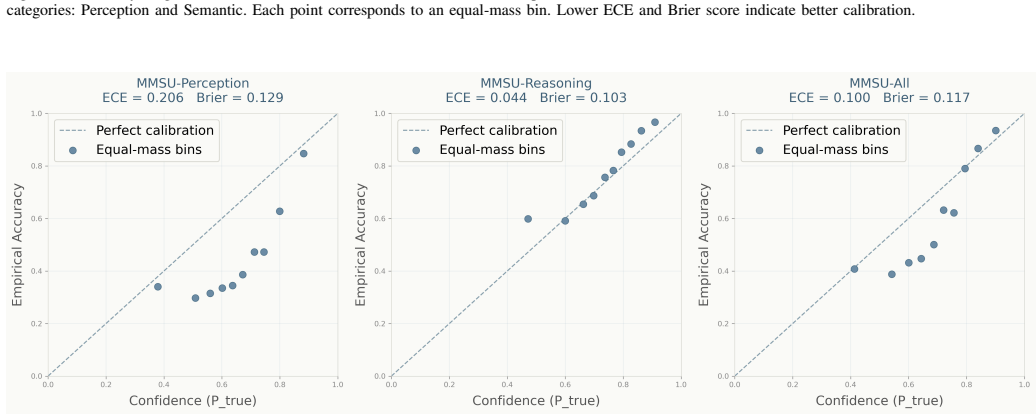
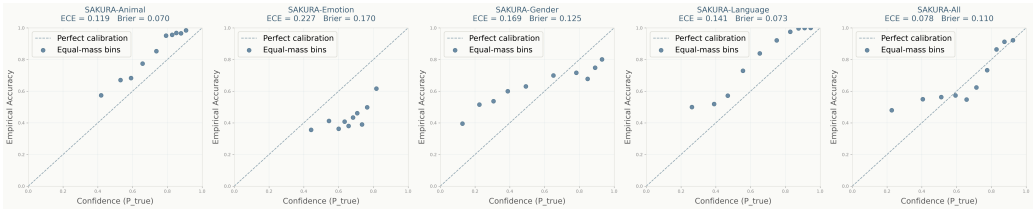
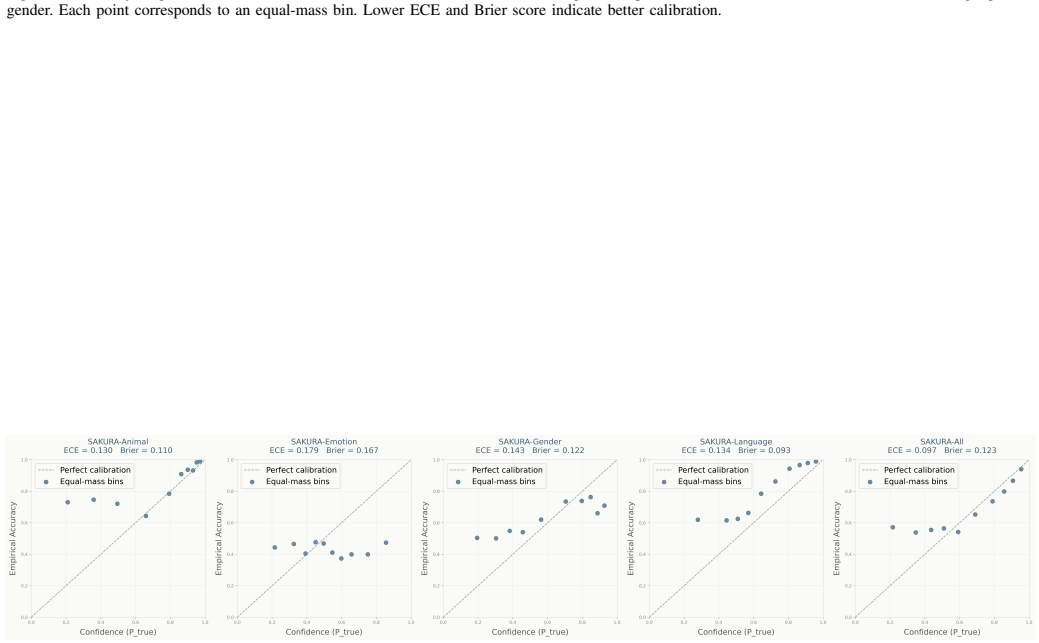
Empirical benchmarking of five uncertainty estimation methods (predictive entropy, length-normalized entropy, semantic entropy, discrete semantic entropy, and P(True)) applied to multiple audio-aware LLMs across audio-conditioned generation tasks.
Load-bearing premise
The assumption that the chosen models, benchmarks, and audio-conditioned generation settings adequately represent the perceptual ambiguity and cross-modal grounding challenges without introducing implementation-specific biases.
What would settle it
An experiment on new audio datasets or additional ALLMs in which token-level entropy methods achieve higher calibration or better hallucination detection accuracy than semantic-level methods on general reasoning tasks would falsify the main result.
Figures





read the original abstract
Recent audio-aware large language models (ALLMs) have demonstrated strong capabilities across diverse audio understanding and reasoning tasks, but they still frequently produce hallucinated or overly confident outputs. While uncertainty estimation has been extensively studied in text-only LLMs, it remains largely unexplored for ALLMs, where audio-conditioned generation introduces additional challenges such as perceptual ambiguity and cross-modal grounding. In this work, we present the first systematic empirical study of uncertainty estimation in ALLMs. We benchmark five representative methods, including predictive entropy, length-normalized entropy, semantic entropy, discrete semantic entropy, and P(True), across multiple models and diverse evaluation settings spanning general audio understanding, reasoning, hallucination detection, and unanswerable question answering. Our results reveal two key findings. First, semantic-level and verification-based methods consistently outperform token-level baselines on general audio reasoning benchmarks. Second, on trustworthiness-oriented benchmarks, the relative effectiveness of uncertainty methods becomes notably more model- and benchmark-dependent, indicating that conclusions drawn from general reasoning settings do not straightforwardly transfer to hallucination and unanswerable-question scenarios. We further explore uncertainty-based adaptive inference as a potential downstream application. We hope this study provides a foundation for future research on reliable, uncertainty-aware audio-language systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic empirical study of uncertainty estimation for audio-aware large language models (ALLMs). It benchmarks five methods (predictive entropy, length-normalized entropy, semantic entropy, discrete semantic entropy, and P(True)) across multiple models on tasks spanning general audio understanding and reasoning, hallucination detection, and unanswerable question answering. The two main findings are that semantic-level and verification-based methods consistently outperform token-level baselines on general audio reasoning benchmarks, while relative effectiveness becomes more model- and benchmark-dependent on trustworthiness-oriented tasks; the work also explores uncertainty-based adaptive inference.
Significance. If the results hold under appropriate controls, this establishes a valuable baseline for uncertainty quantification in multimodal audio-language models and shows that text-LLM findings do not transfer directly due to perceptual ambiguity and cross-modal issues. It provides a foundation for reliable ALLM systems and adaptive inference, with credit for the broad multi-model, multi-task design.
major comments (1)
- [§4 (Experimental Evaluation)] §4 (Experimental Evaluation): The central claim that semantic-level and verification-based methods outperform baselines specifically due to better handling of perceptual ambiguity and cross-modal grounding requires that benchmarks systematically vary audio clarity, noise, or modality conflict while holding text prompts fixed. No such ablations or controls on audio degradation are described, so the comparison may not isolate ALLM-specific challenges from general LLM uncertainty.
minor comments (2)
- [Results] The results lack reported error bars, variance across runs, or statistical significance tests, which would strengthen verification of the consistency claims.
- [§3 (Methods)] Implementation details for audio conditioning (e.g., feature extraction, fusion mechanism) and exact benchmark compositions could be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address the major comment below and commit to revisions that better align our claims with the experimental evidence while preserving the value of the empirical benchmarking study.
read point-by-point responses
-
Referee: [§4 (Experimental Evaluation)] §4 (Experimental Evaluation): The central claim that semantic-level and verification-based methods outperform baselines specifically due to better handling of perceptual ambiguity and cross-modal grounding requires that benchmarks systematically vary audio clarity, noise, or modality conflict while holding text prompts fixed. No such ablations or controls on audio degradation are described, so the comparison may not isolate ALLM-specific challenges from general LLM uncertainty.
Authors: We agree that a strong causal attribution of the observed outperformance to better handling of perceptual ambiguity and cross-modal grounding would require controlled ablations that systematically vary audio clarity, noise, or modality conflicts while holding text prompts fixed. Our study is an empirical benchmarking effort on existing audio reasoning, hallucination, and unanswerable-question datasets, which do contain real-world audio with varying perceptual quality; however, we did not introduce explicit degradation controls or modality-conflict conditions. Consequently, we cannot fully isolate ALLM-specific factors from general LLM uncertainty behaviors. In the revised manuscript we will (i) moderate the language in the abstract, introduction, and conclusion to describe the results as consistent outperformance of semantic-level and verification-based methods on audio-conditioned tasks without claiming this is 'specifically due to' perceptual or cross-modal mechanisms, and (ii) add an explicit limitations paragraph noting the absence of such controls and recommending them for future work. This constitutes a partial revision focused on textual clarification rather than new experiments. revision: partial
Circularity Check
No circularity: empirical benchmarking without derivations or self-referential predictions
full rationale
The paper is a purely empirical study that benchmarks five uncertainty estimation methods (predictive entropy, length-normalized entropy, semantic entropy, discrete semantic entropy, P(True)) on external audio reasoning and trustworthiness benchmarks across multiple ALLMs. No mathematical derivations, first-principles results, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described structure. All claims rest on direct experimental comparisons to prior text-LLM methods and standard benchmarks, with no load-bearing steps that reduce to the paper's own inputs by construction. This matches the default case of an observational evaluation whose conclusions are falsifiable against independent data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty estimation techniques developed for text-only LLMs remain meaningful when applied to audio-conditioned generation
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Listen, think, and understand,
Y . Gong, H. Luo, A. H. Liu, L. Karlinsky, and J. R. Glass, “Listen, think, and understand,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[3]
Joint audio and speech understanding,
Y . Gong, A. H. Liu, H. Luo, L. Karlinsky, and J. Glass, “Joint audio and speech understanding,” in2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[4]
Blsp: Bootstrapping language-speech pre-training via behavior alignment of continuation writing,
C. Wang, M. Liao, Z. Huang, J. Lu, J. Wu, Y . Liu, C. Zong, and J. Zhang, “Blsp: Bootstrapping language-speech pre-training via behavior alignment of continuation writing,”arXiv preprint arXiv:2309.00916, 2023
-
[5]
Audiochatllama: Towards general-purpose speech abilities for llms,
Y . Fathullah, C. Wu, E. Lakomkin, K. Li, J. Jia, Y . Shangguan, J. Mahadeokar, O. Kalinli, C. Fuegen, and M. Seltzer, “Audiochatllama: Towards general-purpose speech abilities for llms,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers)...
2024
-
[6]
Speech-copilot: Leveraging large language models for speech process- ing via task decomposition, modularization, and program generation,
C.-Y . Kuan, C.-K. Yang, W.-P. Huang, K.-H. Lu, and H.-y. Lee, “Speech-copilot: Leveraging large language models for speech process- ing via task decomposition, modularization, and program generation,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 1060–1067
2024
-
[7]
Speechprompt: Prompting speech language models for speech processing tasks,
K.-W. Chang, H. Wu, Y .-K. Wang, Y .-K. Wu, H. Shen, W.-C. Tseng, I.-t. Kang, S.-W. Li, and H.-y. Lee, “Speechprompt: Prompting speech language models for speech processing tasks,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
2024
-
[8]
Blsp-emo: Towards empathetic large speech-language models,
C. Wang, M. Liao, Z. Huang, J. Wu, C. Zong, and J. Zhang, “Blsp-emo: Towards empathetic large speech-language models,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 19 186–19 199
2024
-
[9]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
S. Ghosh, A. Goel, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valleet al., “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[10]
A. H. Liu, A. Ehrenberg, A. Lo, C. Denoix, C. Barreau, G. Lample, J.-M. Delignon, K. R. Chandu, P. von Platen, P. R. Muddireddyet al., “V oxtral,”arXiv preprint arXiv:2507.13264, 2025
-
[11]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2. 5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Building a taiwanese mandarin spoken language model: A first attempt,
C.-K. Yang, Y .-K. Fu, C.-A. Li, Y .-C. Lin, Y .-X. Lin, W.-C. Chen, H. L. Chung, C.-Y . Kuan, W.-P. Huang, K.-H. Luet al., “Building a taiwanese mandarin spoken language model: A first attempt,”arXiv preprint arXiv:2411.07111, 2024
-
[13]
Teaching audio-aware large language mod- els what does not hear: Mitigating hallucinations through synthesized negative samples,
C.-Y . Kuan and H.-y. Lee, “Teaching audio-aware large language mod- els what does not hear: Mitigating hallucinations through synthesized negative samples,” inProc. Interspeech 2025, 2025, pp. 2073–2077
2025
-
[14]
From alignment to advancement: Bootstrapping audio-language alignment with synthetic data,
——, “From alignment to advancement: Bootstrapping audio-language alignment with synthetic data,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 4604–4619, 2025
2025
-
[15]
Recent advances in discrete speech tokens: A review,
Y . Guo, Z. Li, H. Wang, B. Li, C. Shao, H. Zhang, C. Du, X. Chen, S. Liu, and K. Yu, “Recent advances in discrete speech tokens: A review,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
2025
-
[16]
Towards audio language modeling–an overview,
H. Wu, X. Chen, Y .-C. Lin, K.-w. Chang, H.-L. Chung, A. H. Liu, and H.-y. Lee, “Towards audio language modeling–an overview,”arXiv preprint arXiv:2402.13236, 2024
-
[17]
Discrete audio tokens: More than a survey!arXiv preprint arXiv:2506.10274, 2025
P. Mousavi, G. Maimon, A. Moumen, D. Petermann, J. Shi, H. Wu, H. Yang, A. Kuznetsova, A. Ploujnikov, R. Marxeret al., “Discrete audio tokens: More than a survey!”arXiv preprint arXiv:2506.10274, 2025
-
[18]
Recent advances in speech language models: A survey,
W. Cui, D. Yu, X. Jiao, Z. Meng, G. Zhang, Q. Wang, S. Y . Guo, and I. King, “Recent advances in speech language models: A survey,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 13 943– 13 970
2025
-
[19]
A survey on speech large language models for understanding,
J. Peng, Y . Wang, B. Li, Y . Guo, H. Wang, Y . Fang, Y . Xi, H. Li, X. Li, K. Zhanget al., “A survey on speech large language models for understanding,”IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[20]
Wavchat: A survey of spoken dialogue models
S. Ji, Y . Chen, M. Fang, J. Zuo, J. Lu, H. Wang, Z. Jiang, L. Zhou, S. Liu, X. Chenget al., “Wavchat: A survey of spoken dialogue models,”arXiv preprint arXiv:2411.13577, 2024
-
[21]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chenet al., “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras,”arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
On the landscape of spoken language models: A comprehensive survey,
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H.-y. Lee, K. Livescu, and S. Watanabe, “On the landscape of spoken language models: A comprehensive survey,”Transactions on Machine Learning Research, 2025
2025
-
[24]
Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities,
S. Ghosh, Z. Kong, S. Kumar, S. Sakshi, J. Kim, W. Ping, R. Valle, D. Manocha, and B. Catanzaro, “Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities,” inF orty-second International Conference on Machine Learning, 2024
2024
-
[25]
Tico: Time-controllable training for spoken dialogue models,
K.-W. Chang, W.-C. Chen, E.-P. Hu, H.-y. Lee, and J. Glass, “Tico: Time-controllable training for spoken dialogue models,”arXiv preprint arXiv:2603.22267, 2026
work page internal anchor Pith review arXiv 2026
-
[26]
Mmau: A massive multi- task audio understanding and reasoning benchmark,
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “Mmau: A massive multi- task audio understanding and reasoning benchmark,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,
Z. Ma, Y . Ma, Y . Zhu, C. Yang, Y .-W. Chao, R. Xuet al., “Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,”arXiv preprint arXiv:2505.13032, 2025
-
[28]
S. Kumar, ˇS. Sedl ´aˇcek, V . Lokegaonkar, F. L´opez, W. Yu, N. Anand, H. Ryu, L. Chen, M. Pli ˇcka, M. Hlav ´aˇceket al., “Mmau-pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence,”arXiv preprint arXiv:2508.13992, 2025
-
[29]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,
D. Wang, J. Wu, J. Li, D. Yang, X. Chen, T. Zhang, and H. Meng, “Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,”arXiv preprint arXiv:2506.04779, 2025
-
[30]
Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information,
C.-K. Yanget al., “Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information,” in Interspeech 2025, 2025
2025
-
[31]
Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,
C.-Y . Kuan, W.-P. Huang, and H.-y. Lee, “Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,” inInterspeech 2025, 2025
2025
-
[32]
Can large audio-language models truly hear? tackling hallucinations with multi-task assessment and stepwise audio reasoning,
C.-Y . Kuan and H.-y. Lee, “Can large audio-language models truly hear? tackling hallucinations with multi-task assessment and stepwise audio reasoning,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[33]
Dynamic-superb: Towards a dynamic, collaborative, and compre- hensive instruction-tuning benchmark for speech,
C.-y. Huang, K.-H. Lu, S.-H. Wang, C.-Y . Hsiao, C.-Y . Kuanet al., “Dynamic-superb: Towards a dynamic, collaborative, and compre- hensive instruction-tuning benchmark for speech,” inICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 136–12 140
2024
-
[34]
Dynamic- superb phase-2: A collaboratively expanding benchmark for measuring the capabilities of spoken language models with 180 tasks,
C.-y. Huang, W.-C. Chen, S.-w. Yang, A. T. Liuet al., “Dynamic- superb phase-2: A collaboratively expanding benchmark for measuring the capabilities of spoken language models with 180 tasks,” inThe Thir- teenth International Conference on Learning Representations, 2025
2025
-
[35]
Listen and speak fairly: a study on semantic gender bias in speech integrated large language models,
Y .-C. Lin, T.-Q. Lin, C.-K. Yang, K.-H. Lu, W.-C. Chen, C.-Y . Kuan, and H.-y. Lee, “Listen and speak fairly: a study on semantic gender bias in speech integrated large language models,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 439–446
2024
-
[36]
Spoken stereoset: on evaluating social bias toward speaker in speech large language models,
Y .-C. Lin, W.-C. Chen, and H.-y. Lee, “Spoken stereoset: on evaluating social bias toward speaker in speech large language models,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 871–878
2024
-
[37]
Av-superb: A multi- task evaluation benchmark for audio-visual representation models,
Y . Tseng, L. Berry, Y .-T. Chen, I.-H. Chiu, H.-H. Lin, M. Liu, P. Peng, Y .-J. Shih, H.-Y . Wang, H. Wuet al., “Av-superb: A multi- task evaluation benchmark for audio-visual representation models,” in ICASSP 2024-2024 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2024, pp. 6890–6894
2024
-
[38]
Beyond single-audio: Advancing multi-audio processing in audio large language models,
Y . Chen, X. Yue, X. Gao, C. Zhang, L. F. D’Haro, R. T. Tan, and H. Li, “Beyond single-audio: Advancing multi-audio processing in audio large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 10 917–10 930
2024
-
[39]
P. He, Z. Wen, Y . Wang, Y . Wang, X. Liu, J. Huang, Z. Lei, Z. Gu, X. Jin, J. Yanget al., “Audiomarathon: A comprehensive benchmark for long-context audio understanding and efficiency in audio llms,” arXiv preprint arXiv:2510.07293, 2025
-
[40]
Speech-ifeval: Evaluating instruction-following and quantifying catastrophic forgetting in speech- aware language models,
K.-H. Lu, C.-Y . Kuan, and H.-y. Lee, “Speech-ifeval: Evaluating instruction-following and quantifying catastrophic forgetting in speech- aware language models,” inProc. Interspeech 2025, 2025, pp. 2078– 2082
2025
-
[41]
Y . Tseng, T. Parcollet, R. van Dalen, S. Zhang, and S. Bhattacharya, “Evaluation of llms in speech is often flawed: Test set contamination in large language models for speech recognition,”arXiv preprint arXiv:2505.22251, 2025
-
[42]
S.-w. Yang, M. Tu, A. T. Liu, X. Qu, H.-y. Lee, L. Lu, Y . Wang, and Y . Wu, “Paras2s: Benchmarking and aligning spoken language models for paralinguistic-aware speech-to-speech interaction,”arXiv preprint arXiv:2511.08723, 2025
-
[43]
Mos-bias: From hidden gen- der bias to gender-aware speech quality assessment,
W. Ren, Y .-C. Lin, W.-C. Huang, E. Cooper, R. E. Zezario, H.- M. Wang, H.-y. Lee, and Y . Tsao, “Mos-bias: From hidden gen- der bias to gender-aware speech quality assessment,”arXiv preprint arXiv:2603.10723, 2026
-
[44]
Aqua-bench: Beyond finding answers to knowing when there are none in audio question answering,
C.-Y . Kuan and H.-y. Lee, “Aqua-bench: Beyond finding answers to knowing when there are none in audio question answering,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026, pp. 1–5
2026
-
[45]
Aqascore: Evaluating seman- tic alignment in text-to-audio generation via audio question answering,
C.-Y . Kuan, K.-W. Chang, and H.-y. Lee, “Aqascore: Evaluating seman- tic alignment in text-to-audio generation via audio question answering,” arXiv preprint arXiv:2601.14728, 2026
-
[46]
Causal tracing of audio-text fusion in large audio language models,
W.-C. Chen, C.-y. Huang, and H.-y. Lee, “Causal tracing of audio-text fusion in large audio language models,”arXiv preprint arXiv:2603.13768, 2026
-
[47]
Membership inference attacks against large audio language models,
J.-K. Dong, Y .-X. Lin, and H.-Y . Lee, “Membership inference attacks against large audio language models,”arXiv preprint arXiv:2603.28378, 2026
-
[48]
Echomind: An interrelated multi-level benchmark for evaluating empathetic speech language models,
L. Zhou, L. Yu, Y . Lyu, Y . Lin, Z. Zhao, J. Ao, Y . Zhang, B. Wang, and H. Li, “Echomind: An interrelated multi-level benchmark for evaluating empathetic speech language models,”arXiv preprint arXiv:2510.22758, 2025
-
[49]
How contrastive decoding enhances large audio language models?
T.-Q. Lin, W.-P. Huang, Y .-C. Lin, and H.-y. Lee, “How contrastive decoding enhances large audio language models?”arXiv preprint arXiv:2603.09232, 2026
-
[50]
K.-W. Chang, Y .-C. Lin, H.-C. Chou, W. Ren, Y .-H. Huang, Y .-S. Tsai, C.-C. Chen, Y . Tsao, Y .-F. Liao, S. Narayananet al., “Taigis- peech: A low-resource real-world speech intent dataset and prelim- inary results with scalable data mining in-the-wild,”arXiv preprint arXiv:2603.21478, 2026
-
[51]
VIBE: Voice-Induced open-ended Bias Evaluation for Large Audio-Language Models via Real-World Speech
Y .-C. Lin, Y . Hirota, S.-F. Huang, and H.-y. Lee, “Vibe: V oice-induced open-ended bias evaluation for large audio-language models via real- world speech,”arXiv preprint arXiv:2604.17248, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Game-time: Evaluating temporal dynamics in spoken language models,
K.-W. Chang, E.-P. Hu, C.-Y . Kuan, W. Ren, W.-C. Chen, G.-T. Lin, Y . Tsao, S.-H. Sun, H.-y. Lee, and J. Glass, “Game-time: Evaluating temporal dynamics in spoken language models,” inICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026, pp. 1–5
2026
-
[53]
Y . Chen, W. Zhu, X. Chen, Z. Wang, X. Li, P. Qiu, H. Wang, X. Dong, Y . Xiong, A. Schneideret al., “Aha: Aligning large audio-language models for reasoning hallucinations via counterfactual hard negatives,” arXiv preprint arXiv:2512.24052, 2025
-
[54]
HalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
F. Zhao, Y . Chen, W. Lu, D. Zhang, X. Yue, and J. Wei, “Halluaudio: A comprehensive benchmark for hallucination detection in large audio- language models,”arXiv preprint arXiv:2604.19300, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Audiotrust: Benchmarking the multifaceted trustworthiness of audio large language models,
K. Li, C. Shen, Y . Liu, J. Han, K. Zheng, X. Zou, L. Z. Wang, S. Zhang, X. Du, H. Luoet al., “Audiotrust: Benchmarking the multifaceted trustworthiness of audio large language models,”arXiv preprint arXiv:2505.16211, 2025
-
[56]
H. He, X. Du, R. Sun, Z. Dai, Y . Xiao, M. Yang, J. Zhou, X. Li, Z. Liu, Z. Lianget al., “Measuring audio’s impact on correctness: Audio- contribution-aware post-training of large audio language models,”arXiv preprint arXiv:2509.21060, 2025
-
[57]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,”arXiv preprint arXiv:1610.02136, 2016
work page internal anchor Pith review arXiv 2016
-
[58]
Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,
Y . Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. Dillon, B. Lakshminarayanan, and J. Snoek, “Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[59]
Calibration of pre-trained transformers,
S. Desai and G. Durrett, “Calibration of pre-trained transformers,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 295–302
2020
-
[60]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Younget al., “Scaling language models: Methods, analysis & insights from training gopher,”arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review arXiv 2021
-
[61]
How can we know when language models know? on the calibration of language models for ques- tion answering,
Z. Jiang, J. Araki, H. Ding, and G. Neubig, “How can we know when language models know? on the calibration of language models for ques- tion answering,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 962–977, 2021
2021
-
[62]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnsonet al., “Language models (mostly) know what they know,”arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[63]
Reducing conversational agents’ overconfidence through linguistic calibration,
S. J. Mielke, A. Szlam, E. Dinan, and Y .-L. Boureau, “Reducing conversational agents’ overconfidence through linguistic calibration,” Transactions of the Association for Computational Linguistics, vol. 10, pp. 857–872, 2022
2022
-
[64]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,
A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro, A. Gupta, A. Garriga-Alonsoet al., “Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,”Transactions on machine learning research, 2023
2023
-
[65]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[66]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhnet al., “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, pp. 625–630, 2024
2024
-
[67]
Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities,
A. Nikitin, J. Kossen, Y . Gal, and P. Marttinen, “Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities,”Advances in Neural Information Processing Systems, vol. 37, pp. 8901–8929, 2024
2024
-
[68]
Beyond semantic entropy: Boosting llm uncertainty quantification with pairwise semantic similarity,
D. Nguyen, A. Payani, and B. Mirzasoleiman, “Beyond semantic entropy: Boosting llm uncertainty quantification with pairwise semantic similarity,” inFindings of the Association for Computational Linguis- tics: ACL 2025, 2025, pp. 4530–4540
2025
-
[69]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[70]
On the calibration of large language models and alignment,
C. Zhu, B. Xu, Q. Wang, Y . Zhang, and Z. Mao, “On the calibration of large language models and alignment,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 9778–9795
2023
-
[71]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inInternational conference on machine learning. PMLR, 2017, pp. 1321–1330
2017
-
[72]
Teaching models to express their uncertainty in words
S. Lin, J. Hilton, and O. Evans, “Teaching models to express their uncertainty in words,”arXiv preprint arXiv:2205.14334, 2022
-
[73]
Do large language models know what they don’t know?
Z. Yin, Q. Sun, Q. Guo, J. Wu, X. Qiu, and X.-J. Huang, “Do large language models know what they don’t know?” inFindings of the association for Computational Linguistics: ACL 2023, 2023, pp. 8653– 8665
2023
-
[74]
Uncertainty quantification of large language models through multi- dimensional responses,
T. Chen, X. Liu, L. Da, J. Chen, V . Papalexakis, and H. Wei, “Uncertainty quantification of large language models through multi- dimensional responses,”arXiv preprint arXiv:2502.16820, 2025
-
[75]
A survey of uncertainty estimation in llms: Theory meets practice,
H.-Y . Huang, Y . Yang, Z. Zhang, S. Lee, and Y . Wu, “A survey of uncertainty estimation in llms: Theory meets practice,”arXiv preprint arXiv:2410.15326, 2024
-
[76]
Uncertainty in natural language processing: Sources, quantification, and applications,
M. Hu, Z. Zhang, S. Zhao, M. Huang, and B. Wu, “Uncertainty in natural language processing: Sources, quantification, and applications,” arXiv preprint arXiv:2306.04459, 2023
-
[77]
A survey of uncertainty estimation methods on large language models,
Z. Xia, J. Xu, Y . Zhang, and H. Liu, “A survey of uncertainty estimation methods on large language models,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 21 381–21 396
2025
-
[78]
Rethinking Uncertainty Estimation in LLMs: A Principled Single-Sequence Measure
L. Aichberger, K. Schweighofer, and S. Hochreiter, “Rethinking un- certainty estimation in natural language generation,”arXiv preprint arXiv:2412.15176, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
M. Chen, G. Chen, W. Wang, and Y . Yang, “Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization,” arXiv preprint arXiv:2505.12346, 2025
-
[80]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
L. Chen, M. Zaharia, and J. Zou, “Frugalgpt: How to use large language models while reducing cost and improving performance,” arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.