Recognition: unknown
An AI Agent Execution Environment to Safeguard User Data
Pith reviewed 2026-05-10 02:11 UTC · model grok-4.3
The pith
GAAP guarantees AI agents disclose private user data only per user permissions, even if the agent or model is attacked.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GAAP provides a deterministic guarantee of confidentiality for private user data by collecting user permission specifications via dynamic directed prompts and enforcing them on all agent disclosures through augmented information flow control. The augmentation uses novel persistent data stores and annotations to track how private data flows across execution steps in a single task and over multiple tasks separated in time. This approach works without trusting the agent with private data and without requiring the AI model or user prompts to be free of attacks such as prompt injection.
What carries the argument
Augmented information flow control using persistent data stores and annotations that track private data flows within tasks and across time-separated tasks.
If this is right
- Agents can safely access and operate on private data for tasks such as financial advice while keeping all disclosures under user control.
- Disclosures to the AI model and its provider become subject to the same permission rules as other parties.
- Prompt injection and other attacks that previously caused data leaks in other systems are blocked.
- Agent utility remains largely unchanged because enforcement adds no significant overhead.
- Tracking spans both single-task steps and multi-task sequences separated in time.
Where Pith is reading between the lines
- The persistent tracking mechanism could be applied to non-AI agent systems that run over long periods and cross task boundaries.
- If permission prompts prove incomplete in practice, the approach would need additional user interfaces or defaults to maintain coverage.
- The deterministic enforcement suggests a path for reducing reliance on model providers for data privacy in agent workflows.
Load-bearing premise
Dynamic user prompts can elicit complete and accurate permission specifications while the tracking mechanism captures every relevant data flow without omissions during realistic agent runs.
What would settle it
A test case in which an agent execution produces an unauthorized disclosure to an unpermitted party because either the prompt failed to capture a needed permission or the persistent store missed a data flow path.
Figures





read the original abstract
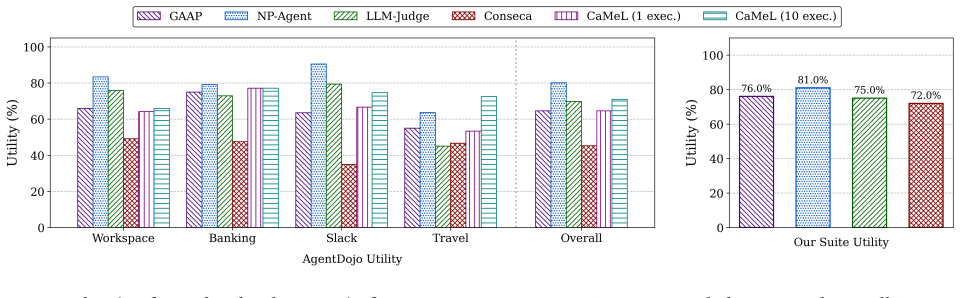
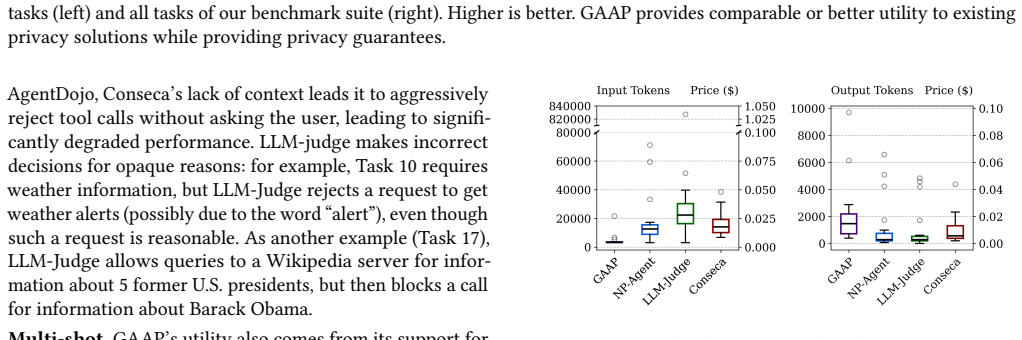
AI agents promise to serve as general-purpose personal assistants for their users, which requires them to have access to private user data (e.g., personal and financial information). This poses a serious risk to security and privacy. Adversaries may attack the AI model (e.g., via prompt injection) to exfiltrate user data. Furthermore, sharing private data with an AI agent requires users to trust a potentially unscrupulous or compromised AI model provider with their private data. This paper presents GAAP (Guaranteed Accounting for Agent Privacy), an execution environment for AI agents that guarantees confidentiality for private user data. Through dynamic and directed user prompts, GAAP collects permission specifications from users describing how their private data may be shared, and GAAP enforces that the agent's disclosures of private user data, including disclosures to the AI model and its provider, comply with these specifications. Crucially, GAAP provides this guarantee deterministically, without trusting the agent with private user data, and without requiring any AI model or the user prompt to be free of attacks. GAAP enforces the user's permission specification by tracking how the AI agent accesses and uses private user data. It augments Information Flow Control with novel persistent data stores and annotations that enable it to track the flow of private information both across execution steps within a single task, and also over multiple tasks separated in time. Our evaluation confirms that GAAP blocks all data disclosure attacks, including those that make other state-of-the-art systems disclose private user data to untrusted parties, without a significant impact on agent utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GAAP (Guaranteed Accounting for Agent Privacy), an execution environment for AI agents that collects dynamic user permission specifications via directed prompts and enforces them using augmented Information Flow Control (IFC) with novel persistent data stores and annotations. This allows tracking private data flows across execution steps and multiple tasks over time, providing a deterministic confidentiality guarantee without trusting the AI agent, model, or prompt to be attack-free. The evaluation is said to show that it blocks all tested data disclosure attacks, including those affecting other systems, with no significant utility loss.
Significance. If the tracking mechanism proves complete for realistic agent executions and the evaluation is robust, this work could significantly advance privacy-preserving AI agents by offering a system-level guarantee against data exfiltration via prompt injection or provider compromise. The use of persistent stores for cross-task tracking is a creative extension of IFC and merits attention if substantiated. However, the current lack of detailed evidence for the tracking completeness and evaluation weakens its immediate impact.
major comments (2)
- [Evaluation] The abstract claims that the evaluation 'confirms that GAAP blocks all data disclosure attacks... without a significant impact on agent utility,' but no details are provided on the attack models, metrics, baselines, experimental controls, or specific scenarios tested (e.g., implicit flows or multi-task interactions). This leaves the central empirical support for the deterministic guarantee unverifiable and requires substantial expansion.
- [Design of augmented IFC and persistent stores] The description of how annotations and persistent stores track flows 'both across execution steps within a single task, and also over multiple tasks separated in time' does not address potential evasion via implicit information flows, model-generated encodings, external API side effects, or agent loops. Since the guarantee is deterministic and rests on complete tracking, this omission is load-bearing and needs explicit mechanisms or proofs of coverage.
minor comments (1)
- [Abstract] The abstract is well-written but could benefit from a brief mention of the core technical innovation (persistent stores) to better highlight novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the potential significance of GAAP if the tracking completeness and evaluation can be substantiated. We address the major comments point by point below, agreeing where expansion is needed and providing clarifications on the design.
read point-by-point responses
-
Referee: [Evaluation] The abstract claims that the evaluation 'confirms that GAAP blocks all data disclosure attacks... without a significant impact on agent utility,' but no details are provided on the attack models, metrics, baselines, experimental controls, or specific scenarios tested (e.g., implicit flows or multi-task interactions). This leaves the central empirical support for the deterministic guarantee unverifiable and requires substantial expansion.
Authors: We agree that the abstract is high-level and that the evaluation details should be more prominent to support verifiability. The full manuscript includes an evaluation section describing the attack models (prompt injection, provider compromise, and data exfiltration attempts), metrics (disclosure blocking rate and utility via task completion accuracy), baselines (comparisons to non-persistent IFC systems), and controls. To address this, we will substantially expand the evaluation section with explicit descriptions of all tested scenarios, including implicit flows and multi-task interactions, additional tables summarizing results, and details on experimental setups. revision: yes
-
Referee: [Design of augmented IFC and persistent stores] The description of how annotations and persistent stores track flows 'both across execution steps within a single task, and also over multiple tasks separated in time' does not address potential evasion via implicit information flows, model-generated encodings, external API side effects, or agent loops. Since the guarantee is deterministic and rests on complete tracking, this omission is load-bearing and needs explicit mechanisms or proofs of coverage.
Authors: The augmented IFC mechanism propagates labels on all data accesses via the persistent stores, which capture implicit flows through dependency tracking on every operation (including model outputs and API interactions). Model-generated encodings are addressed by tainting all outputs based on prior input labels; external API side effects are intercepted and labeled by the sandboxed execution environment; and agent loops are handled through persistent cross-task annotations that survive time separation. We will revise the design section to add an explicit subsection discussing these evasion vectors and the coverage mechanisms. A formal proof of completeness against every conceivable evasion is not feasible within the paper's scope (as it would require exhaustive modeling of all agent behaviors), but we will strengthen the informal arguments and limitations discussion. revision: partial
Circularity Check
No circularity: GAAP is a constructive system design with external inputs
full rationale
The paper describes a system (GAAP) whose confidentiality guarantee is constructed from two external mechanisms: (1) dynamic user prompts that supply permission specifications and (2) augmented information-flow control plus persistent stores that track data flows. The abstract states that GAAP 'enforces that the agent's disclosures... comply with these specifications' and 'provides this guarantee deterministically, without trusting the agent with private user data.' No equations, fitted parameters, or self-citations are invoked to derive the guarantee from itself. The evaluation is presented as empirical confirmation that the implementation blocks attacks, not as a statistical prediction derived from the same data used to define the mechanism. The core claim therefore remains independent of its own outputs and does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Users can provide accurate and complete permission specifications through dynamic directed prompts
- domain assumption Information flow control can be augmented with persistent stores and annotations to track data across execution steps and separate tasks
invented entities (1)
-
GAAP execution environment with persistent data stores and annotations
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Engineering Robustness into Personal Agents with the AI Workflow Store
AI agents should shift from on-the-fly plan synthesis to invoking pre-engineered, tested, and reusable workflows stored in an AI Workflow Store to gain reliability and security.
-
Engineering Robustness into Personal Agents with the AI Workflow Store
AI agents require pre-engineered reusable workflows stored in a central repository rather than generating plans on the fly to achieve production-grade reliability and security.
Reference graph
Works this paper leans on
-
[1]
Alibaba Cloud Community. 2026. Alibaba’s Qwen App Advances Agentic AI Strategy by Turning Core Ecosystem Services into Exe- cutable AI Capabilities.https://www.alibabacloud.com/blog/alibaba% E2%80%99s-qwen-app-advances-agentic-ai-strategy-by-turning- core-ecosystem-services-into-executable-ai-capabilities_602801
2026
- [2]
-
[3]
Anthropic. 2024. Model Context Protocol: A Standard for Tool Use in AI Systems.Technical Report(2024)
2024
-
[4]
Apple Security Engineering and Architecture. 2024. Private Cloud Compute: A new frontier for AI privacy in the cloud. Apple Security Re- search Blog.https://security.apple.com/blog/private-cloud-compute/ Accessed: 2026-04-14
2024
- [5]
-
[6]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2025. StruQ: defending against prompt injection with structured queries. InProceedings of the 34th USENIX Conference on Security Symposium (Seattle, WA, USA)(SEC ’25). USENIX Association, USA, Article 123, 18 pages
2025
-
[7]
Zhaorun Chen, Mintong Kang, and Bo Li. 2025. ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning. InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerr...
2025
-
[8]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li
- [9]
-
[10]
Sahana Chennabasappa, Cyrus Nikolaidis, Daniel Song, David Molnar, Stephanie Ding, Shengye Wan, Spencer Whitman, Lauren Deason, Nicholas Doucette, Abraham Montilla, Alekhya Gampa, Beto de Paola, Dominik Gabi, James Crnkovich, Jean-Christophe Testud, Kat He, Rashnil Chaturvedi, Wu Zhou, and Joshua Saxe. 2025. LlamaFirewall: An open source guardrail system ...
-
[11]
NVIDIA Corporation. 2025. NeMo Guardrails | NVIDIA Developer. https://developer.nvidia.com/nemo-guardrails
2025
- [12]
-
[13]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, An- dreas Terzis, and Florian Tramèr. 2025. Defeating Prompt Injections by Design. (2025). arXiv:2503.18813 [cs.CR]https://arxiv.org/abs/2503. 18813
work page internal anchor Pith review arXiv 2025
-
[14]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer- Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dy- namic Environment to Evaluate Prompt Injection Attacks and De- fenses for LLM Agents. (2024). arXiv:2406.13352 [cs.CR]https: //arxiv.org/abs/2406.13352
work page internal anchor Pith review arXiv 2024
- [15]
-
[16]
DonutShinobu. [n. d.].Claude Code — Leaked Source (2026-03-31).https: //github.com/DonutShinobu/claude-code-forkGitHub repository
2026
-
[17]
Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N
William Enck, Peter Gilbert, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N. Sheth. 2010. TaintDroid: An Information-Flow Tracking System for Realtime Privacy Monitoring on Smartphones. InOSDI. USENIX Association
2010
-
[18]
Kassem Fawaz, Ren Yi, Octavian Suciu, Rishabh Khandelwal, Hamza Harkous, Nina Taft, and Marco Gruteser. 2026. Text-Based Personas for Simulating User Privacy Decisions. (2026). arXiv:2603.19791 [cs.CR] https://arxiv.org/abs/2603.19791
work page internal anchor Pith review arXiv 2026
-
[19]
2024.Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Igor Fedorov, Kate Plawiak, Lemeng Wu, Tarek Elgamal, Naveen Suda, Eric Smith, Hongyuan Zhan, Jianfeng Chi, Yuriy Hulovatyy, Kimish Patel, Zechun Liu, Changsheng Zhao, Yangyang Shi, Tijmen Blankevoort, Mahesh Pasupuleti, Bilge Soran, Zacharie Delpierre Coudert, Rachad Alao, Raghuraman Krishnamoorthi, and Vikas Chandra. 2024.Llama Guard 3-1B-INT4: Compact ...
2024
- [20]
-
[21]
Kai Greshake et al. 2023. More than you’ve asked for: A comprehen- sive analysis of prompt injection vulnerabilities in LLM-integrated applications.arXiv preprint arXiv:2302.12173(2023)
work page internal anchor Pith review arXiv 2023
-
[22]
Friederike Groschupp, Daniele Lain, Aritra Dhar, Lara Magdalena Lazier, and Srdjan Čapkun. 2025. Can LLMs Make (Personalized) Access Control Decisions? (2025). arXiv:2511.20284 [cs.CR]https: //arxiv.org/abs/2511.20284
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
2026.Practical Security Guidance for Sandboxing Agen- tic Workflows and Managing Execution Risk
Rich Harang. 2026.Practical Security Guidance for Sandboxing Agen- tic Workflows and Managing Execution Risk. NVIDIA Technical Blog.https://developer.nvidia.com/blog/practical-security-guidance- for-sandboxing-agentic-workflows-and-managing-execution-risk/
2026
-
[24]
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. 2024. Defending Against Indirect Prompt Injection Attacks With Spotlighting.arXiv(2024). arXiv:2403.14720 https://api.semanticscholar.org/CorpusID:268667111
work page internal anchor Pith review arXiv 2024
-
[25]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations.arXiv(2023). arXiv:2312.06674 [cs.CL]https://arxiv.org/abs/2312.06674
work page internal anchor Pith review arXiv 2023
-
[26]
Dennis Jacob, Emad Alghamdi, Zhanhao Hu, Basel Alomair, and David Wagner. 2025. Better Privilege Separation for Agents by Restricting Data Types. (2025). arXiv:2509.25926 [cs.CR]https://arxiv.org/abs/ 2509.25926
work page internal anchor Pith review arXiv 2025
-
[27]
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. 2023. Baseline Defenses for Ad- versarial Attacks Against Aligned Language Models.arXiv(2023). arXiv:2309.00614 [cs.LG]https://arxiv.org/abs/2309.00614
work page internal anchor Pith review arXiv 2023
-
[28]
Mintong Kang, Zhaorun Chen, and Bo Li. 2025. C-SafeGen: Certi- fied Safe LLM Generation with Claim-Based Streaming Guardrails. InNeurIPS. NeurIPS.https://neurips.cc/virtual/2025/loc/san-diego/ 14 poster/116139
2025
-
[29]
Darya Kaviani, Alp Eren Ozdarendeli, Jinhao Zhu, Yu Ding, and Raluca Ada Popa. 2026. Opal: Private Memory for Personal AI. (2026). arXiv:2604.02522 [cs.CR]https://arxiv.org/abs/2604.02522
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Aashish Kolluri, Rishi Sharma, Manuel Costa, Boris Köpf, Tobias Nießen, Mark Russinovich, Shruti Tople, and Santiago Zanella- Beguelin. 2026. Optimizing Agent Planning for Security and Autonomy. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=g0aVCDY3gS
2026
-
[31]
Pandya, Ashish Hooda, Xiaohan Fu, and Earlence Fernandes
Andrey Labunets, Nishit V. Pandya, Ashish Hooda, Xiaohan Fu, and Earlence Fernandes. 2025. Fun-tuning: Characterizing the Vulner- ability of Proprietary LLMs to Optimization-based Prompt Injec- tion Attacks via the Fine-Tuning Interface. InS&P. IEEE.https: //arxiv.org/abs/2501.09798
- [32]
-
[33]
Hao Li, Xiaogeng Liu, Ning Zhang, and Chaowei Xiao. 2025. PIGuard: Prompt Injection Guardrail via Mitigating Overdefense for Free. In ACL. Association for Computational Linguistics.https://aclanthology. org/2025.acl-long.1468.pdf
2025
- [34]
- [35]
-
[36]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2023. AgentBench: Evaluating LLMs as Agents.arXiv preprint arXiv: 2308.03688(2023)
work page internal anchor Pith review arXiv 2023
-
[37]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. InUSENIX Security. USENIX.https://www.usenix.org/ conference/usenixsecurity24/presentation/liu-yupei
2024
-
[38]
Jon Martindale. 2026. Meta Security Researcher’s AI Agent Acci- dentally Deleted Her Emails.https://www.pcmag.com/news/meta- security-researchers-openclaw-ai-agent-accidentally-deleted-her- emails
2026
- [39]
-
[40]
Meta. [n. d.]. Pyre: A performant type checker for Python.https://pyre- check.org/. Accessed: 2026-03-27
2026
-
[41]
Cade Metz and Kevin Roose. 2026. The Rise of AI Agents: How They Are Changing the Way We Work.https: //www.nytimes.com/2026/03/19/technology/ai-agents-uses.html? unlocked_article_code=1.VlA.Teax.ZjL3TEp0tNp7&smid=url-share. Accessed: 2026-03-25
2026
-
[42]
2026.Manipulat- ing AI Memory for Profit: The Rise of AI Recommendation Poison- ing.https://www.microsoft.com/en-us/security/blog/2026/02/10/ai- recommendation-poisoning/
Microsoft Defender Security Research Team. 2026.Manipulat- ing AI Memory for Profit: The Rise of AI Recommendation Poison- ing.https://www.microsoft.com/en-us/security/blog/2026/02/10/ai- recommendation-poisoning/
2026
-
[43]
Madison Mills. 2026. Anthropic leaked 500,000 lines of its own source code.https://www.axios.com/2026/03/31/anthropic-leaked-source- code-ai
2026
-
[44]
Model Context Protocol. [n. d.].Building a Server: Weather API Helper Functions. Anthropic.https://modelcontextprotocol.io/docs/develop/ build-server#weather-api-helper-functions-2
-
[45]
2026.Model Context Protocol Servers.https: //github.com/modelcontextprotocol/servers/tree/main/srcGitHub repository
Model Context Protocol. 2026.Model Context Protocol Servers.https: //github.com/modelcontextprotocol/servers/tree/main/srcGitHub repository
2026
-
[46]
Andrew C. Myers. 1999. JFlow: Practical Mostly-Static Information Flow Control. InPOPL. ACM
1999
-
[47]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, et al
-
[48]
WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332(2021)
work page internal anchor Pith review arXiv 2021
-
[49]
Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V. Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaud- hari, Ilia Shumailov, Abhradeep Thakurta, Kai Yuanqing Xiao, An- dreas Terzis, and Florian Tramèr. 2025. The Attacker Moves Sec- ond: Stronger Adaptive Attacks Bypass Defenses Against Llm Jail- breaks and Prompt Injecti...
-
[50]
OpenAI. 2023. ChatGPT Plugins.OpenAI Blog(2023)
2023
-
[51]
2025.Guardrails — OpenAI Agents SDK Documentation
OpenAI. 2025.Guardrails — OpenAI Agents SDK Documentation. Ope- nAI.https://openai.github.io/openai-agents-python/guardrails/
2025
-
[52]
OWASP. 2024. OWASP Top 10 for LLM Applications 2025.https:// genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/
2024
-
[53]
Nils Palumbo, Sarthak Choudhary, Jihye Choi, Prasad Chalasani, and Somesh Jha. 2026. Policy Compiler for Secure Agentic Systems. (2026). arXiv:2602.16708 [cs.CR]https://arxiv.org/abs/2602.16708
work page internal anchor Pith review arXiv 2026
- [54]
-
[55]
Ethan Perez et al. 2022. Red Teaming Language Models with Language Models.arXiv preprint arXiv:2202.03286(2022)
work page Pith review arXiv 2022
-
[56]
2026.IronCurtain: A Personal AI Assistant Built Secure from the Ground Up
Niels Provos. 2026.IronCurtain: A Personal AI Assistant Built Secure from the Ground Up. Niels Provos Blog.https://www.provos.org/p/ ironcurtain-secure-personal-assistant/
2026
-
[57]
PulseMCP. 2026. PulseMCP: Model Context Protocol Community Resource.https://www.pulsemcp.com/
2026
-
[58]
Rudra-ravi. [n. d.]. wikipedia-mcp.https://github.com/Rudra-ravi/ wikipedia-mcp. GitHub repository, Accessed: 2026-03-28
2026
-
[59]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools.arXiv preprint arXiv:2302.04761(2023)
work page internal anchor Pith review arXiv 2023
- [60]
-
[61]
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, Basel Alomair, Xuandong Zhao, William Yang Wang, Neil Gong, Wenbo Guo, and Dawn Song. 2025. PromptArmor: Simple yet Effective Prompt Injection Defenses. (2025). arXiv:2507.15219 [cs.CR]https://arxiv.org/ abs/2507.15219
-
[62]
Shoaib Ahmed Siddiqui, Radhika Gaonkar, Boris Köpf, David Krueger, Andrew Paverd, Ahmed Salem, Shruti Tople, Lukas Wutschitz, Menglin Xia, and Santiago Zanella-Béguelin. 2026. Permissive Information-Flow Analysis for Large Language Models. (2026). arXiv:2410.03055 [cs.LG]https://arxiv.org/abs/2410.03055
-
[63]
SQLite Development Team. [n. d.]. SQLite.https://sqlite.org/. Accessed: 2026-03-27
2026
- [64]
- [65]
- [66]
- [67]
-
[68]
Kenton Varda and Sunil Pai. 2025. Code Mode: The Better Way to Use MCP.https://blog.cloudflare.com/code-mode/
2025
-
[69]
2026.Sandboxing AI agents, 100x faster
Kenton Varda, Sunil Pai, and Ketan Gupta. 2026.Sandboxing AI agents, 100x faster. The Cloudflare Blog.https://blog.cloudflare.com/dynamic- workers/
2026
-
[70]
VitalDB. [n. d.].medcalc: Medical Calculator in Python.https://github. com/vitaldb/medcalcGitHub repository
-
[71]
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. 2024. The Instruction Hierarchy: Training LLMs to Pri- oritize Privileged Instructions.arXiv(2024). arXiv:2404.13208 [cs.CR] https://arxiv.org/abs/2404.13208
work page internal anchor Pith review arXiv 2024
-
[72]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. 2025. AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents. (2025). arXiv:2503.18666 [cs.AI]https://arxiv.org/abs/2503.18666
work page internal anchor Pith review arXiv 2025
-
[73]
Zi Wang et al. 2024. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments.arXiv preprint arXiv:2404.07972(2024)
work page internal anchor Pith review arXiv 2024
-
[74]
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, and Eugene Siow. 2025. MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers.arXiv preprint arXiv:2508.20453(2025)
-
[75]
2024.Delimiters won’t save you from prompt injection
Simon Willison. 2024.Delimiters won’t save you from prompt injection. https://simonwillison.net/2023/May/11/delimiters-wont-save-you
2024
-
[76]
2024.The Dual LLM pattern for building AI assistants that can resist prompt injection.https://simonwillison.net/2023/Apr/ 25/dual-llm-pattern/
Simon Willison. 2024.The Dual LLM pattern for building AI assistants that can resist prompt injection.https://simonwillison.net/2023/Apr/ 25/dual-llm-pattern/
2024
-
[77]
2024.You can’t solve AI security problems with more AI.https://simonwillison.net/2022/Sep/17/prompt-injection-more-ai/
Simon Willison. 2024.You can’t solve AI security problems with more AI.https://simonwillison.net/2022/Sep/17/prompt-injection-more-ai/
2024
- [78]
-
[79]
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. 2025. IsolateGPT: An Execution Isolation Ar- chitecture for LLM-Based Agentic Systems. InProceedings of the 32nd Network and Distributed System Security Symposium (NDSS).https://www.ndss-symposium.org/ndss-paper/isolategpt-an- execution-isolation-architecture-for-llm-based-agentic-systems/
2025
-
[80]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. 2024. TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks....
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.