Recognition: unknown
Generalization at the Edge of Stability
Pith reviewed 2026-05-10 02:33 UTC · model grok-4.3
The pith
A sharpness dimension derived from the full Hessian spectrum bounds generalization when training at the edge of stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing stochastic optimizers as random dynamical systems that converge to a fractal attractor set with smaller intrinsic dimension, the authors introduce the sharpness dimension inspired by Lyapunov dimension theory. They prove a generalization bound in terms of this dimension, showing that generalization in the chaotic regime depends on the complete Hessian spectrum and the structure of its partial determinants in a way that cannot be captured by the trace or spectral norm alone. Experiments on MLPs and transformers support the bound and illuminate grokking.
What carries the argument
The sharpness dimension, the intrinsic dimension of the fractal attractor in the random dynamical system model of the optimizer, computed from the partial determinants of the Hessian spectrum.
If this is right
- Generalization bounds in chaotic regimes must incorporate the full Hessian spectrum and partial determinant structure.
- Training at the edge of stability reduces the effective sharpness dimension and thereby tightens the generalization bound.
- Grokking arises as a transition that lowers the sharpness dimension over the course of training.
- Bounds that rely solely on the trace or largest eigenvalue of the Hessian are incomplete for large learning rates.
Where Pith is reading between the lines
- Optimizers might be designed to steer the partial Hessian determinants toward smaller sharpness dimension values.
- The same random dynamical system lens could be applied to analyze generalization in other iterative learning algorithms.
- Tracking partial Hessian determinants during training could become a practical predictor of final generalization.
Load-bearing premise
Stochastic optimizers operating at the edge of stability can be represented as random dynamical systems that converge to a fractal attractor set whose intrinsic dimension is captured by the Hessian spectrum.
What would settle it
Computing the sharpness dimension from the Hessian spectrum for a set of models trained at the edge of stability and finding that the observed generalization error does not track the predicted bound would falsify the claim.
Figures




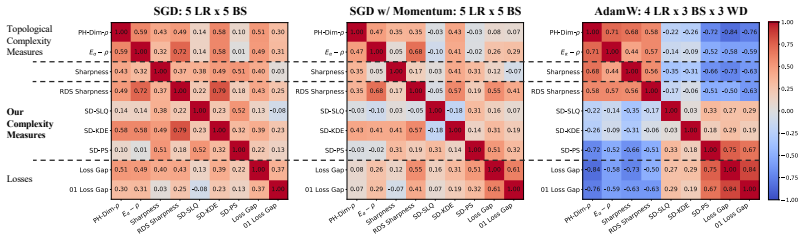



read the original abstract
Training modern neural networks often relies on large learning rates, operating at the edge of stability, where the optimization dynamics exhibit oscillatory and chaotic behavior. Empirically, this regime often yields improved generalization performance, yet the underlying mechanism remains poorly understood. In this work, we represent stochastic optimizers as random dynamical systems, which often converge to a fractal attractor set (rather than a point) with a smaller intrinsic dimension. Building on this connection and inspired by Lyapunov dimension theory, we introduce a novel notion of dimension, coined the `sharpness dimension', and prove a generalization bound based on this dimension. Our results show that generalization in the chaotic regime depends on the complete Hessian spectrum and the structure of its partial determinants, highlighting a complexity that cannot be captured by the trace or spectral norm considered in prior work. Experiments across various MLPs and transformers validate our theory while also providing new insights into the recently observed phenomenon of grokking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to model stochastic optimizers at the edge of stability as random dynamical systems that converge to fractal attractors of reduced intrinsic dimension. It introduces a 'sharpness dimension' constructed from the full Hessian spectrum and its partial determinants, proves a generalization bound based on this dimension, and shows through experiments on MLPs and transformers that generalization in the chaotic regime depends on this measure rather than trace or spectral norm, while also providing insights into grokking.
Significance. If the central results hold, the work provides a novel dynamical-systems perspective on generalization that incorporates the entire Hessian structure, going beyond prior sharpness measures. The experimental validation across architectures and the link to Lyapunov dimension theory are strengths that could explain empirical benefits of the edge-of-stability regime.
major comments (2)
- [Theoretical framework and main theorem] The proof of the generalization bound assumes convergence of SGD dynamics at the edge of stability to a fractal attractor whose intrinsic dimension equals the proposed sharpness dimension, but no lemma or theorem establishes existence, uniqueness, or dimension reduction for the specific random dynamical system considered.
- [Definition of sharpness dimension (around Eq. (5))] The sharpness dimension is defined via partial determinants of the Hessian spectrum; the manuscript does not verify that this construction satisfies monotonicity or countable stability, properties required for it to function as a dimension in the subsequent bound.
minor comments (2)
- [Abstract and Experiments] The abstract refers to 'various MLPs and transformers' without listing the exact architectures, depths, or hyperparameter ranges used in the experiments; these details should appear in the experimental section for reproducibility.
- [Notation and definitions] Notation for the partial determinants in the sharpness dimension could be clarified with a small worked example on a low-dimensional Hessian.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive assessment of the work's significance. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Theoretical framework and main theorem] The proof of the generalization bound assumes convergence of SGD dynamics at the edge of stability to a fractal attractor whose intrinsic dimension equals the proposed sharpness dimension, but no lemma or theorem establishes existence, uniqueness, or dimension reduction for the specific random dynamical system considered.
Authors: We agree that the manuscript does not contain a dedicated lemma establishing existence, uniqueness, or dimension reduction for the specific random dynamical system modeling SGD at the edge of stability. The framework relies on this convergence as a modeling assumption, supported by empirical observations and connections to prior analyses of chaotic optimization dynamics. In the revision, we will explicitly flag this assumption in the theoretical framework section and add a new subsection with supporting numerical evidence from Lyapunov exponent computations and attractor dimension estimates on the considered models. We do not claim a full existence proof, which lies beyond the current scope. revision: partial
-
Referee: [Definition of sharpness dimension (around Eq. (5))] The sharpness dimension is defined via partial determinants of the Hessian spectrum; the manuscript does not verify that this construction satisfies monotonicity or countable stability, properties required for it to function as a dimension in the subsequent bound.
Authors: The sharpness dimension is constructed to parallel the Lyapunov dimension from dynamical systems theory, which satisfies monotonicity and countable stability. We will add a short proposition in the revised manuscript that directly verifies these properties for our definition by leveraging the ordering of Hessian eigenvalues and the multiplicative structure of the partial determinants. This verification follows standard arguments for spectrum-based dimensions and will be included prior to the generalization bound. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper models stochastic optimizers as random dynamical systems converging to fractal attractors, introduces the sharpness dimension (inspired by Lyapunov dimension theory and constructed from the full Hessian spectrum and partial determinants), and derives a generalization bound from this dimension. The abstract and description provide no quoted equations or steps showing self-definition (e.g., sharpness dimension defined in terms of the bound), fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central claim to a tautology. The modeling assumption and subsequent mathematical derivation appear independent of the target generalization result, with no evidence of the patterns that would trigger a positive circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic optimizers at the edge of stability converge to a fractal attractor set with smaller intrinsic dimension.
invented entities (1)
-
sharpness dimension
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Perturbation Dose Responses in Recursive LLM Loops: Raw Switching, Stochastic Floors, and Persistent Escape under Append, Replace, and Dialog Updates
In 30-step recursive LLM loops, append-mode persistent escape from source basins reaches 50% near 400 tokens under full history but plateaus below 50% under tail-clip memory policy, while replace-mode switching largel...
Reference graph
Works this paper leans on
-
[1]
T., Suarez, F., and Zhang, Y
Ahn, K., Bubeck, S., Chewi, S., Lee, Y. T., Suarez, F., and Zhang, Y. (2023a). Learning threshold neurons via edge of stability. Advances in Neural Information Processing Systems , 36:19540--19569
- [2]
-
[3]
Ahn, K., Zhang, J., and Sra, S. (2022). Understanding the unstable convergence of gradient descent. In International conference on machine learning . PMLR
2022
-
[4]
Andreeva, R., Dupuis, B., Sarkar, R., Birdal, T., and Simsekli, U. (2024). Topological generalization bounds for discrete-time stochastic optimization algorithms. Advances in Neural Information Processing Systems , 37
2024
-
[5]
Andreyev, A. and Beneventano, P. (2024). Edge of stochastic stability: Revisiting the edge of stability for sgd. arXiv preprint arXiv:2412.20553
-
[6]
Arnold, L. (2006). Random dynamical systems. In Dynamical Systems: Lectures Given at the 2nd Session of the Centro Internazionale Matematico Estivo (CIME) held in Montecatini Terme, Italy, June 13--22, 1994 . Springer
2006
-
[7]
Arora, S., Li, Z., and Panigrahi, A. (2022). Understanding gradient descent on the edge of stability in deep learning. In International Conference on Machine Learning , pages 948--1024. PMLR
2022
-
[8]
J., and Simsekli, U
Birdal, T., Lou, A., Guibas, L. J., and Simsekli, U. (2021). Intrinsic dimension, persistent homology and generalization in neural networks. Advances in Neural Information Processing Systems , 34:6776--6789
2021
-
[9]
Bogachev, V. (2007). Measure theory . Springer
2007
-
[10]
Cai, Y., Huang, H., Wen, H., Liu, D., Ma, Y., and Lyu, K. (2026). Does LLM pre-training typically occur at the edge of stability? In Workshop on Scientific Methods for Understanding Deep Learning
2026
-
[11]
A., Gurbuzbalaban, M., Simsekli, U., and Zhu, L
Camuto, A., Deligiannidis, G., Erdogdu, M. A., Gurbuzbalaban, M., Simsekli, U., and Zhu, L. (2021). Fractal structure and generalization properties of stochastic optimization algorithms. Advances in neural information processing systems , 34:18774--18788
2021
-
[12]
Chaudhari, P., Choromanska, A., Soatto, S., LeCun, Y., Baldassi, C., Borgs, C., Chayes, J., Sagun, L., and Zecchina, R. (2019). Entropy-sgd: Biasing gradient descent into wide valleys. Journal of Statistical Mechanics: Theory and Experiment , 2019(12):124018
2019
-
[13]
and Engel, M
Chemnitz, D. and Engel, M. (2025). Characterizing dynamical stability of stochastic gradient descent in overparameterized learning. Journal of Machine Learning Research , 26(134):1--46
2025
-
[14]
and Bruna, J
Chen, L. and Bruna, J. (2023). Beyond the edge of stability via two-step gradient updates. In International Conference on Machine Learning , pages 4330--4391. PMLR
2023
- [15]
-
[16]
Cohen, J. M., Kaur, S., Li, Y., Kolter, J. Z., and Talwalkar, A. (2021). Gradient descent on neural networks typically occurs at the edge of stability. arXiv preprint arXiv:2103.00065
-
[17]
Crauel, H., Debussche, A., and Flandoli, F. (1997). Random attractors. Journal of Dynamics and Differential Equations , 9(2):307--341
1997
-
[18]
and Flandoli, F
Crauel, H. and Flandoli, F. (1994). Attractors for random dynamical systems. Probability Theory and Related Fields , 100(3):365--393
1994
- [19]
-
[20]
Ding, L., Drusvyatskiy, D., Fazel, M., and Harchaoui, Z. (2024). Flat minima generalize for low-rank matrix recovery. Information and Inference: A Journal of the IMA
2024
-
[21]
Dinh, L., Pascanu, R., Bengio, S., and Bengio, Y. (2017). Sharp minima can generalize for deep nets. In International Conference on Machine Learning , pages 1019--1028. PMLR
2017
-
[22]
Dupuis, B., Deligiannidis, G., and Simsekli, U. (2023). Generalization bounds using data-dependent fractal dimensions. In International conference on machine learning , pages 8922--8968. PMLR
2023
-
[23]
Dupuis, B., Viallard, P., Deligiannidis, G., and Simsekli, U. (2024). Uniform generalization bounds on data-dependent hypothesis sets via PAC -bayesian theory on random sets. Journal of Machine Learning Research , 25(409)
2024
-
[24]
and Simon, K
Feng, D.-J. and Simon, K. (2022). Dimension estimates for iterated function systems and repellers. part ii. Ergodic Theory and Dynamical Systems , 42(11):3357--3392
2022
- [25]
-
[26]
J., Greenberg, S., Kale, S., Luo, H., Mohri, M., and Sridharan, K
Foster, D. J., Greenberg, S., Kale, S., Luo, H., Mohri, M., and Sridharan, K. (2019). Hypothesis set stability and generalization. Advances in Neural Information Processing Systems , 32
2019
-
[27]
Gatmiry, K., Li, Z., Ma, T., Reddi, S., Jegelka, S., and Chuang, C.-Y. (2023). What is the inductive bias of flatness regularization? a study of deep matrix factorization models. Advances in Neural Information Processing Systems , 36:28040--28052
2023
-
[28]
Ghorbani, B., Krishnan, S., and Xiao, Y. (2019). An investigation into neural net optimization via hessian eigenvalue density. In International Conference on Machine Learning , pages 2232--2241. PMLR
2019
-
[29]
Ghosh, A., Cong, B., Yokota, R., Ravishankar, S., Wang, R., Tao, M., Khan, M. E., and M \"o llenhoff, T. (2025). Variational learning finds flatter solutions at the edge of stability. arXiv preprint arXiv:2506.12903
-
[30]
Golub, G. H. and Welsch, J. H. (1969). Calculation of gauss quadrature rules. Mathematics of computation , 23
1969
- [31]
-
[32]
Halko, N., Martinsson, P.-G., and Tropp, J. A. (2011). Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM review , 53(2):217--288
2011
-
[33]
and Schmidhuber, J
Hochreiter, S. and Schmidhuber, J. (1994). Simplifying neural nets by discovering flat minima. Advances in neural information processing systems , 7
1994
-
[34]
Hodgkinson, L., Simsekli, U., Khanna, R., and Mahoney, M. (2022). Generalization bounds using lower tail exponents in stochastic optimizers. In International Conference on Machine Learning , pages 8774--8795. PMLR
2022
-
[35]
Hunt, B. R. (1996). Maximum local lyapunov dimension bounds the box dimension of chaotic attractors. Nonlinearity , 9(4):845
1996
-
[36]
Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., and Wilson, A. G. (2018). Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407
work page Pith review arXiv 2018
- [37]
- [38]
-
[39]
Jiang, Y., Neyshabur, B., Mobahi, H., Krishnan, D., and Bengio, S. (2019b). Fantastic Generalization Measures and Where to Find Them . ICLR 2020
2020
-
[40]
Kaddour, J., Liu, L., Silva, R., and Kusner, M. J. (2022). When do flat minima optimizers work? Advances in Neural Information Processing Systems , 35:16577--16595
2022
-
[41]
Kaplan, J. L. and Yorke, J. A. (2006). Chaotic behavior of multidimensional difference equations. In Functional Differential Equations and Approximation of Fixed Points: Proceedings, Bonn, July 1978 . Springer
2006
-
[42]
Kaur, S., Cohen, J., and Lipton, Z. C. (2023). On the maximum hessian eigenvalue and generalization. In Proceedings on , pages 51--65. PMLR
2023
-
[43]
Kendall, M. G. (1938). A new reasure of rank correlation. Biometrika
1938
-
[44]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Keskar, N. S., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P. T. P. (2016). On large-batch training for deep learning: Generalization gap and sharp minima. arXiv preprint arXiv:1609.04836
work page internal anchor Pith review arXiv 2016
-
[45]
Lanczos, C. (1950). An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. Journal of research of the National Bureau of Standards , 45(4):255--282
1950
-
[46]
Lin, L., Saad, Y., and Yang, C. (2016). Approximating spectral densities of large matrices. SIAM review , 58(1):34--65
2016
-
[47]
M., Li, Z., and Ma, T
Liu, H., Xie, S. M., Li, Z., and Ma, T. (2023). Same pre-training loss, better downstream: Implicit bias matters for language models. In International Conference on Machine Learning , pages 22188--22214. PMLR
2023
-
[48]
and Hutter, F
Loshchilov, I. and Hutter, F. (2019). Decoupled weight decay regularization
2019
-
[49]
and Gong, P
Ly, A. and Gong, P. (2025). Optimization on multifractal loss landscapes explains a diverse range of geometrical and dynamical properties of deep learning. Nature Communications , 16(1):3252
2025
-
[50]
and Ying, L
Ma, C. and Ying, L. (2021). On linear stability of sgd and input-smoothness of neural networks. Advances in Neural Information Processing Systems , 34:16805--16817
2021
-
[51]
Merity, S., Xiong, C., Bradbury, J., and Socher, R. (2016). Pointer sentinel mixture models
2016
-
[52]
Molchanov, I. (2017). Theory of Random Sets . Number 87 in Probability Theory and Stochastic Modeling. Springer, second edition edition
2017
-
[53]
and Michaeli, T
Mulayoff, R. and Michaeli, T. (2020). Unique properties of flat minima in deep networks. In International conference on machine learning , pages 7108--7118. PMLR
2020
-
[54]
Nanda, N., Chan, L., Lieberum, T., Smith, J., and Steinhardt, J. (2023). Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations
2023
-
[55]
Neyshabur, B., Bhojanapalli, S., McAllester, D., and Srebro, N. (2017). Exploring generalization in deep learning. Advances in neural information processing systems , 30
2017
-
[56]
H., Simsekli, U., Gurbuzbalaban, M., and Richard, G
Nguyen, T. H., Simsekli, U., Gurbuzbalaban, M., and Richard, G. (2019). First exit time analysis of stochastic gradient descent under heavy-tailed gradient noise. Advances in neural information processing systems , 32
2019
- [57]
-
[58]
A., Hoover, W
Posch, H. A., Hoover, W. G., and Vesely, F. J. (1986). Canonical dynamics of the nos \'e oscillator: Stability, order, and chaos. Physical review A , 33(6):4253
1986
-
[59]
Power, A., Burda, Y., Edwards, H., Babuschkin, I., and Misra, V. (2022). Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177
work page internal anchor Pith review arXiv 2022
-
[60]
Prieto, L., Barsbey, M., Mediano, P. A. M., and Birdal, T. (2025). Grokking at the edge of numerical stability. In The Thirteenth International Conference on Learning Representations
2025
-
[61]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). Language models are unsupervised multitask learners
2019
-
[62]
Rubin, N., Seroussi, I., and Ringel, Z. (2024). Grokking as a first order phase transition in two layer networks. In The Twelfth International Conference on Learning Representations
2024
-
[63]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Sagun, L., Evci, U., Guney, V. U., Dauphin, Y., and Bottou, L. (2017). Empirical analysis of the hessian of over-parametrized neural networks. arXiv preprint arXiv:1706.04454
work page Pith review arXiv 2017
-
[64]
Sasdelli, M., Ajanthan, T., Chin, T.-J., and Carneiro, G. (2021). A chaos theory approach to understand neural network optimization. In 2021 Digital Image Computing: Techniques and Applications (DICTA) , pages 1--10. IEEE
2021
-
[65]
Simsekli, U., Sagun, L., and Gurbuzbalaban, M. (2019). A tail-index analysis of stochastic gradient noise in deep neural networks. In International Conference on Machine Learning , pages 5827--5837. PMLR
2019
-
[66]
Simsekli, U., Sener, O., Deligiannidis, G., and Erdogdu, M. A. (2020). Hausdorff dimension, heavy tails, and generalization in neural networks. Advances in Neural Information Processing Systems , 33:5138--5151
2020
-
[67]
Singh Kalra, D., He, T., and Barkeshli, M. (2023). Universal sharpness dynamics in neural network training: Fixed point analysis, edge of stability, and route to chaos. arXiv e-prints , pages arXiv--2311
2023
-
[68]
Tsuzuku, Y., Sato, I., and Sugiyama, M. (2020). Normalized flat minima: Exploring scale invariant definition of flat minima for neural networks using pac-bayesian analysis. In International Conference on Machine Learning , pages 9636--9647. PMLR
2020
- [69]
-
[70]
and Harremos, P
Van Erven, T. and Harremos, P. (2014). R \'e nyi divergence and kullback-leibler divergence. IEEE Transactions on Information Theory , 60(7):3797--3820
2014
-
[71]
Wang, Z., Li, Z., and Li, J. (2022). Analyzing sharpness along gd trajectory: Progressive sharpening and edge of stability. Advances in Neural Information Processing Systems , 35:9983--9994
2022
-
[72]
Wen, K., Li, Z., and Ma, T. (2023). Sharpness minimization algorithms do not only minimize sharpness to achieve better generalization. Advances in Neural Information Processing Systems , 36:1024--1035
2023
-
[73]
Wu, D., Xia, S.-T., and Wang, Y. (2020). Adversarial weight perturbation helps robust generalization. Advances in neural information processing systems , 33:2958--2969
2020
- [74]
-
[75]
Yao, Z., Gholami, A., Lei, Q., Keutzer, K., and Mahoney, M. W. (2018). Hessian-based analysis of large batch training and robustness to adversaries. Advances in Neural Information Processing Systems , 31
2018
-
[76]
Yunis, D. (2017). The birkhoff ergodic theorem with applications. The University of Chicago. Dispon vel em
2017
-
[77]
Zhang, Y., Chen, C., Ding, T., Li, Z., Sun, R., and Luo, Z. (2024). Why transformers need adam: A hessian perspective. Advances in neural information processing systems , 37:131786--131823
2024
-
[78]
Zheng, Y., Zhang, R., and Mao, Y. (2021). Regularizing neural networks via adversarial model perturbation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 8156--8165
2021
- [79]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.