Recognition: 3 theorem links
· Lean TheoremPerturbation Dose Responses in Recursive LLM Loops: Raw Switching, Stochastic Floors, and Persistent Escape under Append, Replace, and Dialog Updates
Pith reviewed 2026-05-08 19:09 UTC · model grok-4.3
The pith
Persistent redirection in recursive LLM loops is conditioned on memory policy, with full history enabling far higher escape rates than tail clipping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
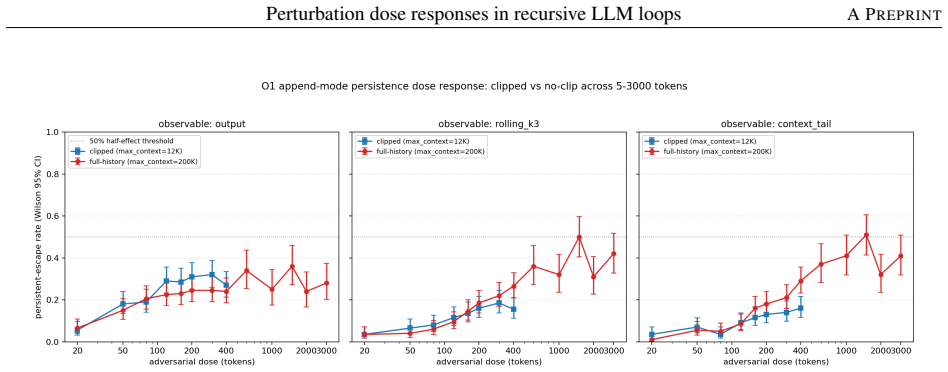
In append-mode recursive loops, persistent redirection is memory-policy-conditioned. Tail-clipped histories keep destination-coherent persistence near 16 percent and retained source-basin escape near 36 percent at dose 400. Full-history protocols raise retained escape across 50 percent near 400 tokens and to 75-80 percent by 1,500 tokens, with destination persistence first reaching 0.50 at 1,500 tokens. Replace-mode raw switching largely reflects state-reset overwrite and falls to 12-32 percent under insert probes. The four-step battery recasts the high-dose destination dip as an endpoint-timing effect rather than a stable structural asymmetry.
What carries the argument
Separation of the language-model generator from the context-update rule (append, replace, or dialog), with dose-response measurement of attractor escape and destination persistence across fixed-length recursive trajectories.
If this is right
- Tail-clipped append keeps even large perturbations from producing durable redirection above roughly one-third escape.
- Full-history append allows durable source-basin escape to saturate at 75-80 percent once dose reaches moderate levels.
- Replace-mode switching largely disappears under insert-mode probes, revealing dependence on state reset.
- The observed destination-coherent asymmetry at high dose is largely removed by longer horizons and adjusted endpoints.
- Recursive-loop evaluations must separate transient movement from lasting escape and subtract stochastic floors.
Where Pith is reading between the lines
- If memory policy sets the persistence threshold, then safety alignments for looped agents must treat context-management rules as first-class controls.
- The reported dose thresholds could be used to estimate minimum perturbation sizes needed to override default loop behavior in deployed systems.
- Dialog updates may occupy an intermediate regime between append persistence and replace reset, offering tunable escape.
- Standardizing long-horizon trajectory metrics would reduce the endpoint-sensitivity uncovered by the falsification battery.
Load-bearing premise
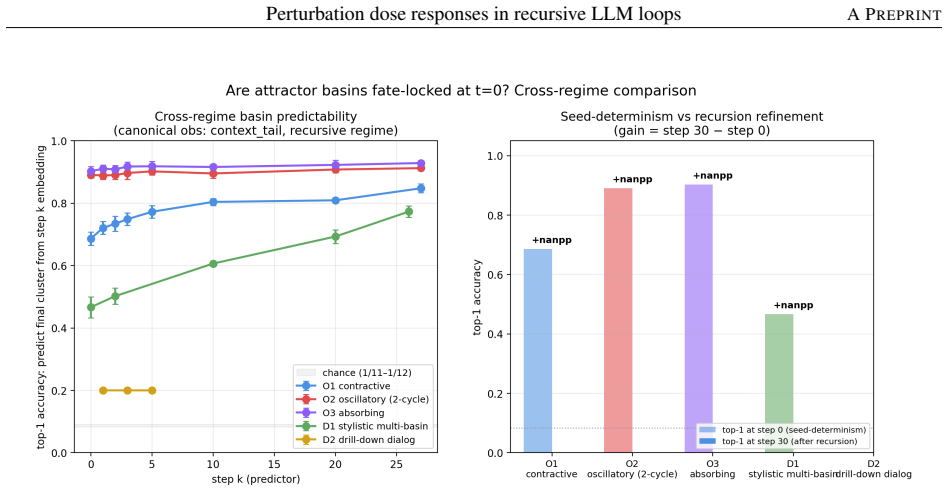
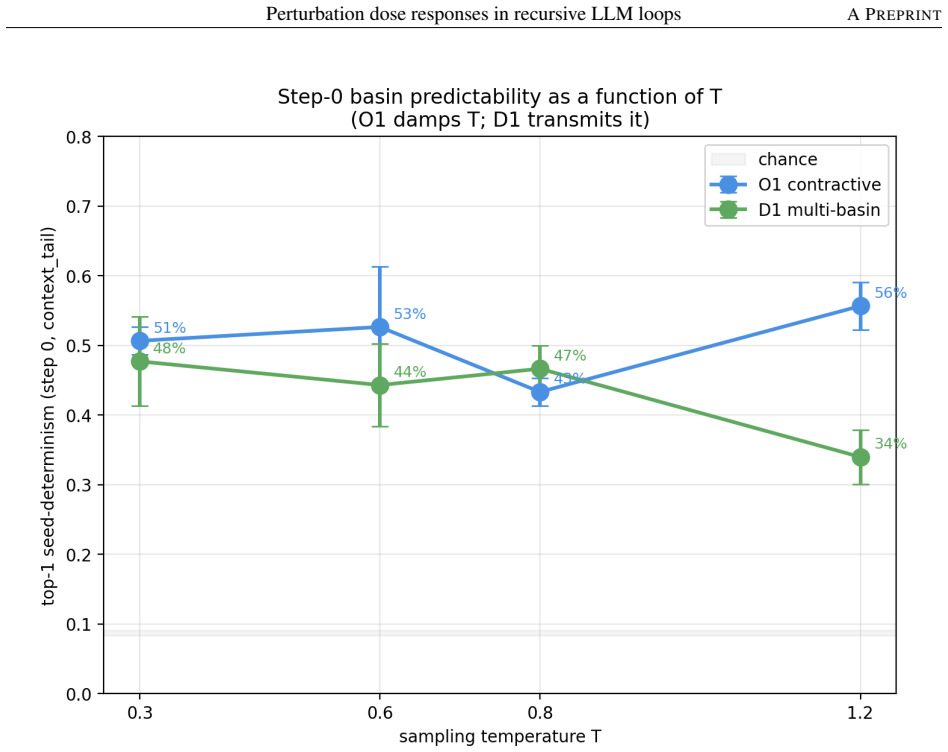
The dose-response curves and attractor-settling patterns observed in 30-step loops on gpt-4o-mini will generalize beyond this model, loop length, and choice of endpoint definitions.
What would settle it
Retained source-basin escape under full history at dose 400 remaining below 50 percent, or the destination-coherent persistence dip failing to shrink when trajectories are extended from 30 to 80 steps under the frozen cluster basis.
Figures




























read the original abstract
Recursive language-model loops often settle into recognizable attractor-like patterns. The practical question is how much injected text is needed to move a settled loop somewhere else, and whether that move lasts. We study this in 30-step recursive loops by separating the model from the context-update rule: append, replace, and dialog updates expose different histories to the same generator. The main result is that persistent redirection in append-mode recursive loops is memory-policy-conditioned. Under a 12,000-character tail clip, destination-coherent persistence plateaus near 16 percent and retained source-basin escape near 36 percent at dose 400; neither crosses 50 percent. Under a full-history protocol, retained source-basin escape crosses 50 percent near 400 tokens and saturates at 75-80 percent by 1,500 tokens; destination-coherent persistence first reaches 0.50 near 1,500 tokens (Wilson 95 percent CI [0.41, 0.61]). A four-step falsification battery (heterogeneity control, granularity sweep with hierarchical macro-merge, transition-entropy diagnostic, and long-horizon trajectory continuation) recasts the high-dose destination-coherent dip as a finite-horizon, endpoint-definition-sensitive feature rather than a stable structural asymmetry. Half the canonical magnitude is endpoint timing; the residual drops 73 percent from -0.143 at step 29 to -0.039 at step 79 under the frozen canonical cluster basis, bootstrap interval straddling zero. Replace-mode raw switching is near-saturated under the default protocol but largely reflects state-reset overwrite: insert-mode probes drop it to 12-32 percent. We report 37 experiments on gpt-4o-mini with within-vendor replication on gpt-4.1-nano. Recursive-loop evaluations should distinguish transient movement from durable escape, subtract stochastic floors, and treat context-update rules as safety-relevant design choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines perturbation dose responses in 30-step recursive LLM loops, separating the generator from context-update rules (append, replace, dialog). It claims that persistent redirection under append-mode is memory-policy-conditioned: with a 12,000-character tail clip, destination-coherent persistence plateaus near 16% and retained source-basin escape near 36% at dose 400 (neither exceeds 50%); under full-history protocol, escape crosses 50% near 400 tokens and saturates at 75-80% by 1,500 tokens, with destination-coherent persistence reaching 0.50 near 1,500 tokens (Wilson 95% CI [0.41, 0.61]). A four-step falsification battery (heterogeneity control, granularity sweep, transition-entropy diagnostic, long-horizon continuation to step 79) recasts an apparent high-dose dip as a finite-horizon artifact. Results are from 37 experiments on gpt-4o-mini with within-vendor replication on gpt-4.1-nano.
Significance. If the reported dose-response curves and memory-policy effects hold, the work provides concrete, falsifiable evidence that context-update rules are first-class safety-relevant design choices in recursive LLM systems, distinguishing transient movement from durable escape and subtracting stochastic floors. Strengths include the explicit separation of update rules, use of Wilson intervals, replication, and the falsification battery that quantifies endpoint sensitivity (e.g., 73% drop in residual asymmetry). The findings are proportionate to the narrow experimental scope but would gain significance with broader validation.
major comments (2)
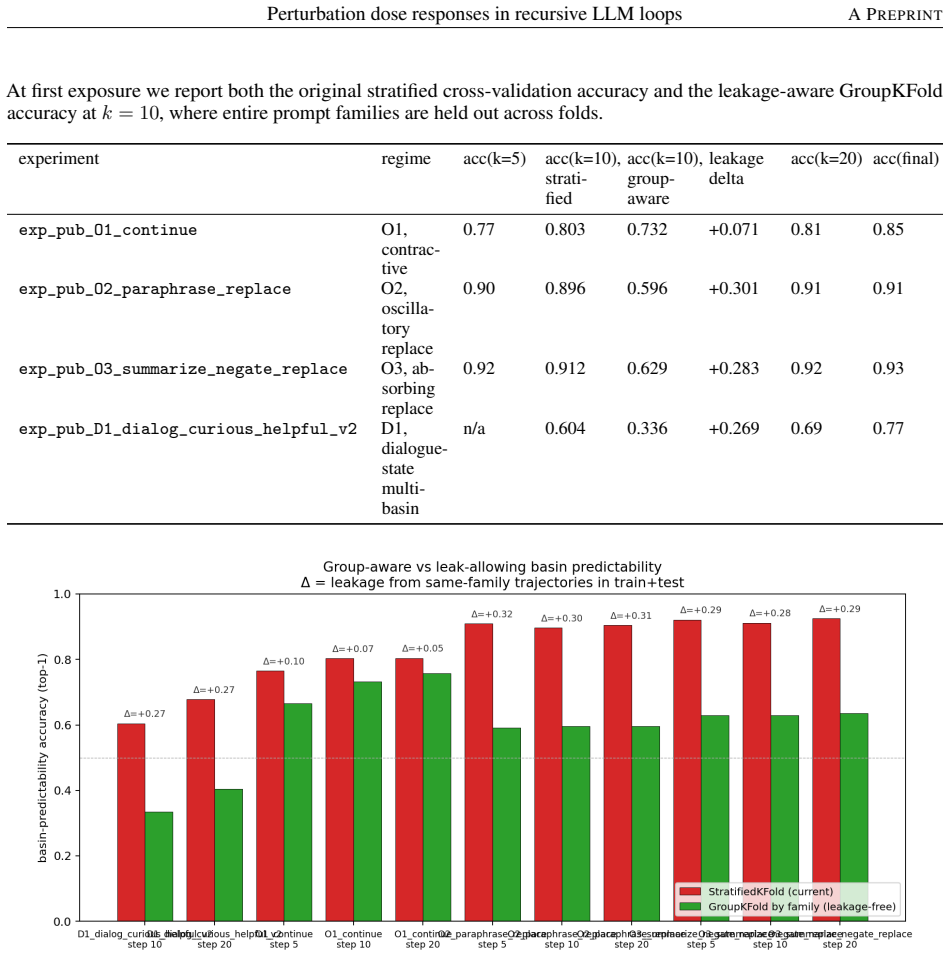
- [Abstract] Abstract: the headline claim that persistent redirection 'is memory-policy-conditioned' with specific plateaus (16% persistence, 36% escape under tail clip; 75-80% escape under full history) is derived entirely from gpt-4o-mini (plus within-vendor replication on gpt-4.1-nano); no cross-model-family or cross-architecture tests are reported, which is load-bearing for the introduction's framing of the result as a general property of 'recursive LLM loops' rather than an OpenAI-model-specific observation.
- [Abstract] Abstract: the four-step falsification battery is invoked to reinterpret the destination-coherent dip as endpoint-sensitive, with the residual dropping from -0.143 at step 29 to -0.039 at step 79 under the 'frozen canonical cluster basis'; without the explicit construction of that basis, the bootstrap procedure, or the precise definition of 'destination-coherent' and 'source-basin' clusters, the quantitative recasting cannot be independently verified and remains load-bearing for the claim that the dip is an artifact rather than structural.
minor comments (2)
- [Abstract] Abstract: phrases such as 'near 16 percent', 'near 400 tokens', and 'first reaches 0.50' would benefit from direct pointers to the corresponding figures or tables that contain the exact dose-response data.
- The manuscript should add a short limitations paragraph explicitly stating the 30-step loop length and single-vendor model family, even if the central empirical claims remain unchanged.
Simulated Author's Rebuttal
We thank the referee for the careful review and the minor revision recommendation. We address each major comment below with point-by-point responses, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that persistent redirection 'is memory-policy-conditioned' with specific plateaus (16% persistence, 36% escape under tail clip; 75-80% escape under full history) is derived entirely from gpt-4o-mini (plus within-vendor replication on gpt-4.1-nano); no cross-model-family or cross-architecture tests are reported, which is load-bearing for the introduction's framing of the result as a general property of 'recursive LLM loops' rather than an OpenAI-model-specific observation.
Authors: The manuscript explicitly states that results are from 37 experiments on gpt-4o-mini with within-vendor replication on gpt-4.1-nano and frames conclusions as applying to the tested recursive LLM loops and update rules rather than claiming universality. We agree the introduction could better qualify the scope to prevent any implication of cross-family generality. We will revise the abstract and introduction to specify 'in the OpenAI models tested' and add an explicit limitations paragraph on the absence of cross-architecture validation. This is a partial revision because the current experimental framing already ties claims to the reported models and protocols. revision: partial
-
Referee: [Abstract] Abstract: the four-step falsification battery is invoked to reinterpret the destination-coherent dip as endpoint-sensitive, with the residual dropping from -0.143 at step 29 to -0.039 at step 79 under the 'frozen canonical cluster basis'; without the explicit construction of that basis, the bootstrap procedure, or the precise definition of 'destination-coherent' and 'source-basin' clusters, the quantitative recasting cannot be independently verified and remains load-bearing for the claim that the dip is an artifact rather than structural.
Authors: The construction of the frozen canonical cluster basis, bootstrap procedure, and definitions of destination-coherent and source-basin clusters are described in the Methods (Section 3.2) and Appendix B. To improve independent verifiability as requested, we will expand these sections in the revision with additional pseudocode for basis construction, exact clustering parameters, and bootstrap details. This directly addresses the load-bearing concern for the finite-horizon artifact claim. revision: yes
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper reports experimental outcomes from 37 runs on gpt-4o-mini (with within-vendor replication) measuring persistence and escape rates under append/replace/dialog update rules at varying perturbation doses. The central claims consist of observed percentages (e.g., 16% destination-coherent persistence, 36% source-basin escape under 12k-char clip at dose 400; 75-80% escape under full history) obtained from the loop executions themselves. The four-step falsification battery addresses finite-horizon artifacts via additional runs rather than by redefining quantities. No equations, fitted parameters, self-citations, or ansatzes are invoked to derive the reported rates; they are counted directly from the trajectories. The derivation chain is therefore self-contained against external benchmarks and does not reduce to any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recursive language-model loops often settle into recognizable attractor-like patterns.
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
- [5]
-
[6]
URL https://arxiv.org/ abs/2406.13352. A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, et al. Self-refine: Iterative refinement with self-feedback,
work page internal anchor Pith review arXiv
-
[7]
URLhttps://arxiv.org/abs/2303.17651. S. Welleck, X. Lu, P. West, F. Brahman, et al. Generating sequences by learning to self-correct,
work page internal anchor Pith review arXiv
- [8]
- [9]
-
[10]
URLhttps://arxiv.org/abs/2310.01798. M. Tuci, C. Korkmaz, U. ¸ Sim¸ sekli, and T Birdal. Generalization at the edge of stability,
work page internal anchor Pith review arXiv
-
[11]
URL https: //arxiv.org/abs/2604.19740. S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y Cao. React: Synergizing reasoning and acting in language models, 2023a. URLhttps://arxiv.org/abs/2210.03629. S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y . Cao, and K Narasimhan. Tree of thoughts: Deliberate problem solving with large language ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://arxiv.org/abs/2303.11366. C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E Gonzalez. Memgpt: Towards llms as operating systems,
work page internal anchor Pith review arXiv
-
[13]
URLhttps://arxiv.org/abs/2310.08560. P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks,
work page internal anchor Pith review arXiv
-
[14]
URLhttps://arxiv.org/abs/2005.11401. E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S Singh. Universal adversarial triggers for attacking and analyzing nlp,
work page internal anchor Pith review arXiv 2005
- [15]
-
[16]
URL https: //arxiv.org/abs/2211.09527. A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, et al. Representation engineering: A top-down approach to ai transparency,
work page internal anchor Pith review arXiv
-
[17]
URLhttps://arxiv.org/abs/2310.01405. 93
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.