Recognition: unknown
Bootstrapping Post-training Signals for Open-ended Tasks via Rubric-based Self-play on Pre-training Text
Pith reviewed 2026-05-10 01:45 UTC · model grok-4.3
The pith
Rubric-based self-play on pretraining text creates training signals that improve LLM performance on open-ended tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that synthesizing evaluation rubrics together with each input-output pair, while anchoring generation in a content-rich pretraining corpus, produces reliable training signals for post-training on open-ended tasks. On the Qwen-2.5-7B model, this yields measurable gains for both the base pretrained checkpoint and its instruction-tuned version across long-form healthcare QA, creative writing, and instruction following.
What carries the argument
The POP framework, in which the same LLM generates input-output pairs plus rubrics from pretraining text and then uses the rubrics to score and reinforce its own outputs.
If this is right
- Performance rises on open-ended tasks including healthcare QA, creative writing, and instruction following.
- Both the raw pretrained model and the already-tuned model benefit from the same self-play procedure.
- Grounding generation in pretraining text reduces reward hacking and prevents mode collapse.
- Self-play becomes usable for realistic tasks that lack easy objective verification.
Where Pith is reading between the lines
- The same rubric-generation step could be applied to other generative models that possess large pretraining corpora.
- Combining rubric self-play with existing preference optimization techniques might further stabilize training.
- Diversity in outputs could be preserved longer than in standard RL if rubric criteria explicitly reward varied valid responses.
Load-bearing premise
LLM-synthesized rubrics supply consistent, non-hackable evaluation criteria for open-ended outputs when generation is anchored in pretraining text.
What would settle it
No improvement, or clear degradation, in task performance after applying the method compared with the base or instruction-tuned model would falsify the central claim.
Figures










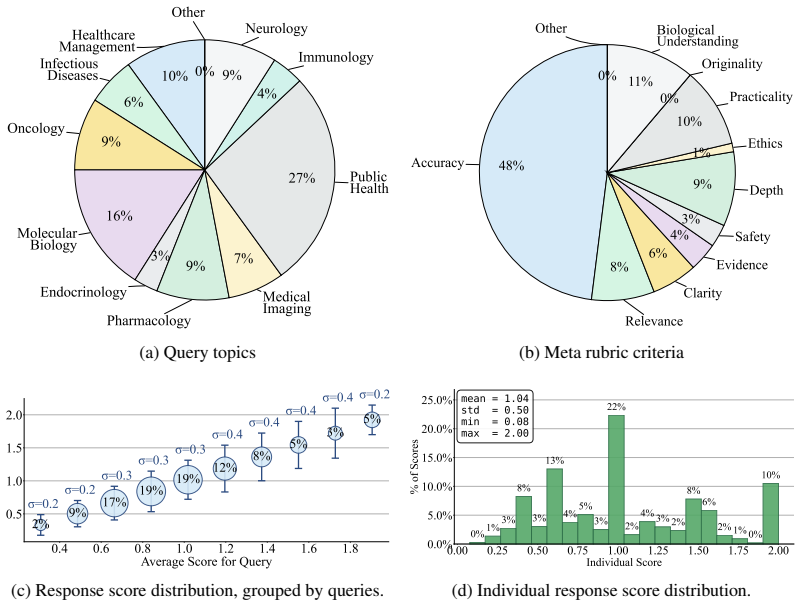
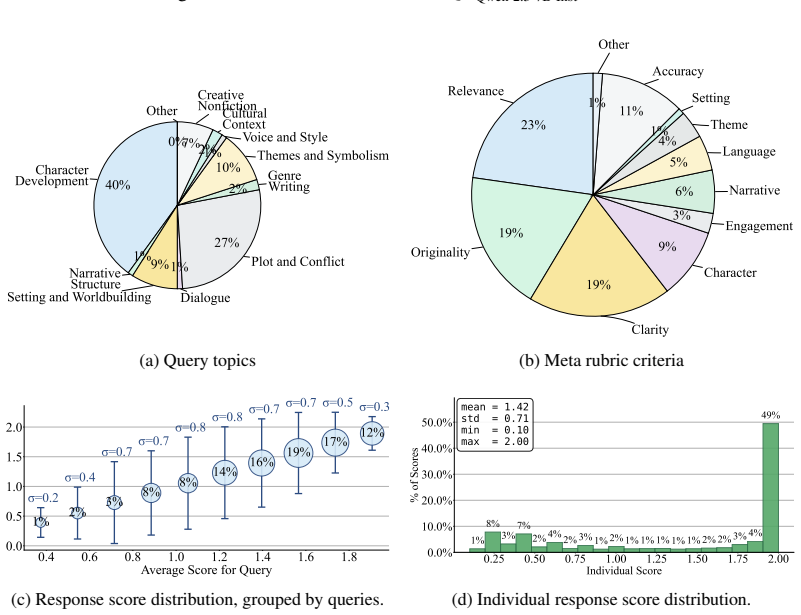







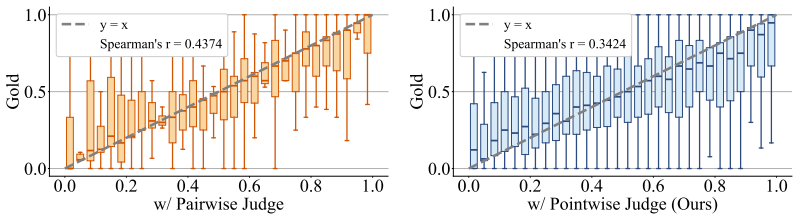





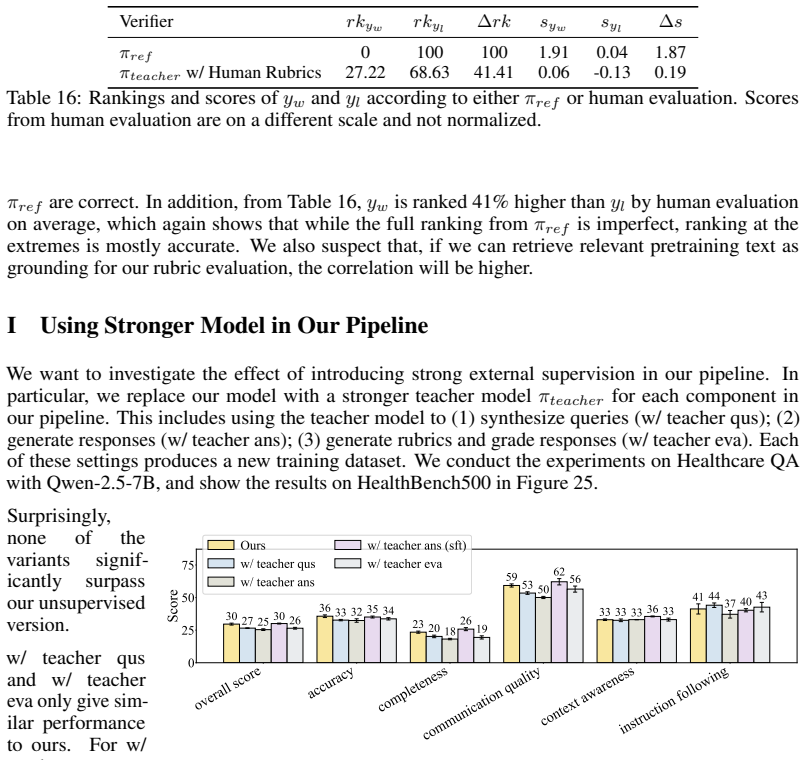

































read the original abstract
Self-play has recently emerged as a promising paradigm for post-training Large Language Models (LLMs). In self-play, the target LLM creates the task input (e.g., a question), which it then addresses itself by producing a task output (e.g., an answer). A reward model evaluates the output, and the rewards are used to train the LLM, typically via Reinforcement Learning (RL). A key benefit of self-play for post-training LLMs is its minimal supervision costs: self-play avoids the need for high-quality input-output pairs traditionally constructed by humans or expensive proprietary models. Existing work, however, explores self-play only for verifiable tasks, such as math and coding, for which objective ground truth is available and easily checkable. In this paper, we seek to extend self-play to more realistic open-ended tasks. We propose POP, a self-play framework that uses the same LLM to synthesize evaluation rubrics along with each input-output pair. The rubric is used to evaluate outputs and train the model. Crucially, we ground the framework on a content-rich pretraining corpus to (1) enable an exploitable generation-verification gap and reduce reward hacking, and (2) prevent mode collapse. On Qwen-2.5-7B, POP increases performance of both the pretrained base model and instruction-tuned model on multiple tasks ranging from long-form healthcare QA to creative writing and instruction following.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes POP, a self-play framework for post-training LLMs on open-ended tasks. The LLM generates input-output pairs grounded in a pretraining corpus along with synthesized evaluation rubrics; the rubrics supply rewards for RL training. The pretraining grounding is intended to create a generation-verification gap that reduces reward hacking and mode collapse. The authors claim that POP improves performance of both the base and instruction-tuned Qwen-2.5-7B on tasks including long-form healthcare QA, creative writing, and instruction following.
Significance. If the empirical gains are robust and the rubric signals prove reliable, the work would be significant for extending self-play beyond verifiable domains with minimal additional supervision. The pretraining-text grounding offers a concrete mechanism to address reward hacking and collapse, which are persistent obstacles in RL post-training of LLMs.
major comments (2)
- Abstract: The central claim that POP increases performance on Qwen-2.5-7B across multiple open-ended tasks is asserted without any quantitative metrics, ablation results, standard deviations, or baseline comparisons. No details are supplied on how the generation-verification gap is measured or on rubric quality, leaving the empirical contribution unsupported by visible evidence.
- Framework and evaluation sections: The claim that LLM-synthesized rubrics plus pretraining grounding produce a usable, non-hackable generation-verification gap is load-bearing for extending self-play to subjective tasks. No independent checks (human rubric validation, adversarial rubric attacks, or comparison to fixed external rubrics) are reported to confirm that the rubric scoring criteria are not implicitly aligned with the model's own distribution, especially for creative writing and long-form QA.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of presentation and empirical support that we will address in the revision. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: Abstract: The central claim that POP increases performance on Qwen-2.5-7B across multiple open-ended tasks is asserted without any quantitative metrics, ablation results, standard deviations, or baseline comparisons. No details are supplied on how the generation-verification gap is measured or on rubric quality, leaving the empirical contribution unsupported by visible evidence.
Authors: We agree that the abstract, as a concise summary, does not include specific numerical results or details on the gap and rubric assessment. The full manuscript presents these quantitative evaluations, ablations, baseline comparisons, and standard deviations from repeated runs in the Experiments section, along with the operationalization of the generation-verification gap through pretraining-text grounding in the Framework section. To make the empirical contribution more immediately apparent, we will revise the abstract to incorporate key performance highlights, baseline comparisons, and a brief description of how the gap is created and how rubric quality is assessed via consistency measures. revision: yes
-
Referee: Framework and evaluation sections: The claim that LLM-synthesized rubrics plus pretraining grounding produce a usable, non-hackable generation-verification gap is load-bearing for extending self-play to subjective tasks. No independent checks (human rubric validation, adversarial rubric attacks, or comparison to fixed external rubrics) are reported to confirm that the rubric scoring criteria are not implicitly aligned with the model's own distribution, especially for creative writing and long-form QA.
Authors: The pretraining grounding is intended to establish the generation-verification gap by anchoring both the synthesized inputs/outputs and rubrics in content from the pretraining corpus, which the model cannot arbitrarily alter without deviating from the grounded distribution; this mechanism is detailed in Section 3 and supported by the observed reductions in mode collapse in our experiments. We acknowledge that the manuscript does not report independent checks such as human rubric validation or adversarial attacks. We will revise the paper to explicitly discuss this as a limitation, provide additional theoretical justification for why the grounding reduces implicit alignment risks, and include any feasible preliminary consistency analyses in the revision. revision: partial
Circularity Check
No significant circularity; empirical framework with external grounding
full rationale
The paper introduces POP as a new self-play method that synthesizes rubrics from the LLM and grounds generation on an external pretraining corpus. Performance gains are reported via experiments on Qwen-2.5-7B across tasks, not via any mathematical derivation or parameter fitting that reduces to the inputs by construction. No equations, self-definitional loops, or load-bearing self-citations appear in the provided text; the generation-verification gap is posited as a design choice supported by the corpus rather than assumed tautologically. This is a standard empirical proposal with no reduction of claims to their own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated rubrics can serve as reliable proxies for evaluating open-ended outputs without introducing systematic bias or reward hacking.
Reference graph
Works this paper leans on
-
[1]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review arXiv 2025
- [3]
-
[4]
Self- playing Adversarial Language Game Enhances LLM Reasoning,
Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Zheng Yuan, Yong Dai, Lei Han, Nan Du, and Xiaolong Li. Self-playing adversarial language game enhances llm reasoning.arXiv preprint arXiv:2404.10642, 2024
-
[5]
Scaling Instruction-Finetuned Language Models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
work page internal anchor Pith review arXiv 2022
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint:arXiv:2512.02556, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Qa-lign: Aligning llms through constitutionally decomposed qa
Jacob Dineen, Aswin Rrv, Qin Liu, Zhikun Xu, Xiao Ye, Ming Shen, Zhaonan Li, Shijie Lu, Chitta Baral, Muhao Chen, and Ben Zhou. Qa-lign: Aligning llms through constitutionally decomposed qa. InProceedings of Findings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[9]
Openwebtext corpus
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019
2019
-
[10]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Lighteval: A lightweight framework for llm evaluation, 2023
Nathan Habib, Clémentine Fourrier, Hynek Kydlí ˇcek, Thomas Wolf, and Lewis Tunstall. Lighteval: A lightweight framework for llm evaluation, 2023. URL https://github.com/ huggingface/lighteval
2023
-
[12]
Yun He, Wenzhe Li, Hejia Zhang, Songlin Li, Karishma Mandyam, Sopan Khosla, Yuanhao Xiong, Nanshu Wang, Xiaoliang Peng, Beibin Li, Shengjie Bi, Shishir G. Patil, Qi Qi, Shengyu Feng, Julian Katz-Samuels, Richard Yuanzhe Pang, Sujan Gonugondla, Hunter Lang, Yue Yu, Yundi Qian, Maryam Fazel-Zarandi, Licheng Yu, Amine Benhalloum, Hany Awadalla, and Manaal Fa...
-
[13]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Advances in Neural Information Processing Systems, 2021. 10
2021
-
[14]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review arXiv 2025
-
[15]
Dcrm: A heuristic to measure response pair quality in preference optimization
Chengyu Huang and Tanya Goyal. Dcrm: A heuristic to measure response pair quality in preference optimization. InFindings of the Association for Computational Linguistics: EMNLP, 2025
2025
-
[16]
Large language models can self-improve
Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[17]
Reinforcement learning with rubric anchors
Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, Xijun Gu, Peiyi Tu, Jiaxin Liu, Wenyu Chen, Yuzhuo Fu, Zhiting Fan, Yanmei Gu, Yuanyuan Wang, Zhengkai Yang, Jianguo Li, and Junbo Zhao. Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790, 2025
-
[18]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.arXiv e-prints, art. arXiv:1705.03551, 2017
work page internal anchor Pith review arXiv 2017
-
[19]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
2019
-
[20]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics (V olume 1: Long Papers), 2022
2022
-
[21]
Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
-
[22]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of International Conference on Learning Representations, 2019
2019
-
[23]
Advanced version of gemini with deep think officially achieves gold-medal standard at the international mathematical olympiad, 2025
Thang Luong and Edward Lockhart. Advanced version of gemini with deep think officially achieves gold-medal standard at the international mathematical olympiad, 2025
2025
-
[24]
Building trust in clinical llms: Bias analysis and dataset transparency
Svetlana Maslenkova, Clement Christophe, Marco AF Pimentel, Tathagata Raha, Muham- mad Umar Salman, Ahmed Al Mahrooqi, Avani Gupta, Shadab Khan, Ronnie Rajan, and Praveenkumar Kanithi. Building trust in clinical llms: Bias analysis and dataset transparency. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[25]
Eq-bench creative writing benchmark v3.https://github.com/EQ-bench/ creative-writing-bench, 2025
Samuel J Paech. Eq-bench creative writing benchmark v3.https://github.com/EQ-bench/ creative-writing-bench, 2025
2025
-
[26]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Gerardo Flores, George H Chen, Tom Pollard, Joyce C Ho, and Tristan Naumann, editors,Proceedings of the Conference on Health, Inference, and Learning, volume 174 ofProceedings of Machine Learni...
2022
-
[27]
Agentic large language models: A survey.arXiv preprint arXiv:2503.23037, 2025
Aske Plaat, Max van Duijn, Niki van Stein, Mike Preuss, Peter van der Putten, and Kees Joost Batenburg. Agentic large language models, a survey.arXiv preprint arXiv:2503.23037, 2025
-
[28]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InarXiv preprint arXiv:2305.18290, 2023. 11
work page internal anchor Pith review arXiv 2023
-
[29]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
2024
-
[30]
Sutherland
Yi Ren and Danica J. Sutherland. Learning dynamics of llm finetuning. InProceedings of International Conference on Learning Representations, 2025
2025
-
[31]
Karl: Knowledge agentsvial reinforcement learning.arXiv preprint:arXiv:2603.05218, 2026
Databricks AI Research. Karl: Knowledge agentsvial reinforcement learning.arXiv preprint:arXiv:2603.05218, 2026
-
[32]
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons.arXiv preprint arXiv:2510.07284, 2025
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Molly Park, Samuel G. Finlayson, David Sontag, Tyler Murray, Sewon Min, Pradeep Dasigi, Luca Soldaini, Faeze Brahman, Wen tau Yih, Tongshuang Wu, Luke Zettlemoyer, Yoon Kim, Hannaneh Hajishirzi, and Pang Wei Koh. Dr tulu: Reinforcement learning with ev...
-
[35]
Harman Singh, Xiuyu Li, Kusha Sareen, Monishwaran Maheswaran, Sijun Tan, Xiaoxia Wu, Junxiong Wang, Alpay Ariyak, Qingyang Wu, Samir Khaki, Rishabh Tiwari, Long Lian, Yucheng Lu, Boyi Li, Alane Suhr, Ben Athiwaratkun, and Kurt Keutzer. V1: Unifying generation and self-verification for parallel reasoners.arXiv preprint arXiv:2603.04304, 2026
-
[36]
Book titles and abstracts
Skelebor. Book titles and abstracts. https://huggingface.co/datasets/Skelebor/ book_titles_and_descriptions, 2022
2022
-
[37]
Mind the gap: Examining the self-improvement capabilities of large language models
Yuda Song, Hanlin Zhang, Carson Eisenach, Sham Kakade, Dean Foster, and Udaya Ghai. Mind the gap: Examining the self-improvement capabilities of large language models. InProceedings of International Conference on Learning Representations, 2025
2025
-
[38]
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, Rémi Munos, Bernardo Ávila Pires, Michal Valko, and Will Dabney Yong Cheng. Understanding the performance gap between online and offline alignment algorithms.arXiv preprint arXiv:2405.08448, 2024
-
[39]
OpenAI Team. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Will we run out of data? limits of llm scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Will we run out of data? limits of llm scaling based on human-generated data. In Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[42]
Checklists are better than reward models for aligning language models
Vijay Viswanathan, Yanchao Sun, Shuang Ma, Xiang Kong, Meng Cao, Graham Neubig, and Tongshuang Wu. Checklists are better than reward models for aligning language models. In Advances in Neural Information Processing Systems, 2025
2025
-
[43]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, Datasets...
2024
-
[44]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. InProceedings of the 41st International Conference on Machine Learning, 2024. 12
2024
-
[45]
Better llm reasoning via dual-play.arXiv preprint arXiv:2511.11881, 2025
Zhengxin Zhang, Chengyu Huang, Aochong Oliver Li, and Claire Cardie. Better llm reasoning via dual-play.arXiv preprint arXiv:2511.11881, 2025
-
[46]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2023
2023
-
[48]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Each sentence in the generated text uses a second person
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Kongcheng Zhang, Jiale Zhao, Jingwen Yang, Yihe Zhou, Jianwei Lv, Tongya Zheng, Hengtong Lu, Wei Chen, Yan Xie, and Mingli Song. Breaking the exploration bottleneck: Rubric-scaffolded reinforcement learning for general llm reasoning.arXiv preprint arXiv:2508.16949, 2025
-
[50]
Yifei Zhou, Sergey Levine, Jason Weston, Xian Li, and Sainbayar Sukhbaatar. Self-challenging language model agents.arXiv preprint arXiv:2506.01716, 2025. 13 Stage Parameter Value Sampling Max Context Length 32768 |d| ∈[50,1024] Proposer Max New Tokens 6144 Proposer Temperature 1.0 Proposer Top P 1.0 Solver Max New Tokens 6144 Solver Temperature 1.0 Solver...
-
[51]
Express and purify the recombinant amidohydrolase enzymes
-
[52]
Conduct in vitro degradation assays using labeled ac4C substrates in buffer conditions mimicking human cellular environments
-
[53]
Analyze the degradation products using techniques such as HPLC or mass spectrometry
-
[54]
Enzyme Identification
Validate the results by comparing the degradation rates and efficiencies of the enzymes from different mesophilic organisms against each other and against a control without the enzyme. Figure 29: Reference Response (Healthcare QA). Rubric { "Enzyme Identification": { "name": "Identification of Potential Enzymes", "gold": "BagYqfB, CunYqfB, KpnYqfB, and Sl...
2017
-
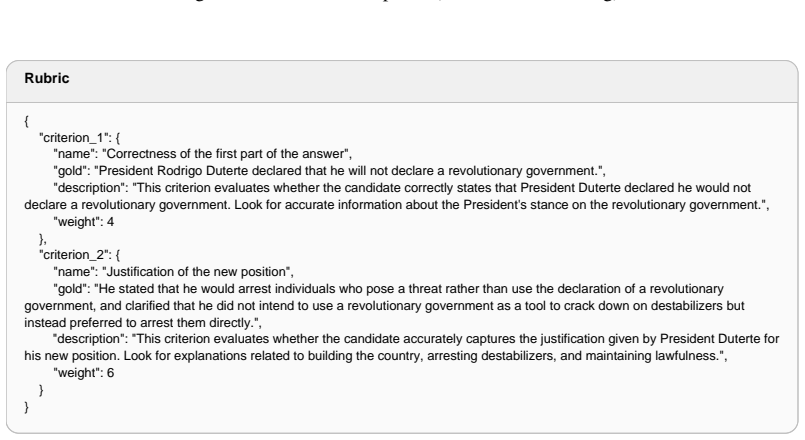
[55]
What did President Duterte declare regarding his plans for a revolutionary government?
-
[56]
Figure 44: Query (Instruction Following)
Why did President Duterte state this new position? Use the details provided in the passage to clearly answer these questions. Figure 44: Query (Instruction Following). Reference Response
-
[57]
President Rodrigo Duterte declared that he will not declare a revolutionary government
-
[58]
criterion_1
He stated his new position by emphasizing the importance of building a country and lawfulness, saying that he would arrest individuals who pose a threat rather than use the declaration of a revolutionary government. He further explained that he did not intend to use a revolutionary government as a tool to crack down on destabilizers but instead preferred ...
-
[59]
He stated that he would continue to work within the framework of the Philippine constitution and existing governmental structures
On November 21, 2017, President Rodrigo Duterte clarified that he was not going to declare a revolutionary government. He stated that he would continue to work within the framework of the Philippine constitution and existing governmental structures
2017
-
[60]
name": "Correctness of the first part of the answer
President Duterte justified this new position by asserting that declaring a revolutionary government was unnecessary and potentially unconstitutional. He explained that the current system already provides ample avenues to address issues and challenges facing the country, such as through executive orders, legislative processes, and other constitutional mec...
-
[61]
He stated that the declaration was made under duress due to threats from opposing groups and to protect national interest
On November 21, 2017, President Duterte declared that his initial threat to declare a revolutionary government was a bluff and that he had no intention of actually implementing such a move. He stated that the declaration was made under duress due to threats from opposing groups and to protect national interest
2017
-
[62]
name": "Correctness of the first part of the answer
President Duterte stated this new position to clarify and de-escalate the tension related to his earlier statements. By clarifying that the threat was not genuine and that he had no plans to implement a revolutionary government, Duterte aimed to reduce political instability and reassure the public and international community that there were no immediate p...
-
[63]
Extract the list of facts in mentioned in the knowledge
-
[64]
Ensure that it is necessary and sufficient to use these facts to derive the correct answer to the problem
Create a problem that requires the use of one or more of the extracted facts to answer. Ensure that it is necessary and sufficient to use these facts to derive the correct answer to the problem. * The problem should ask about a health/medical-related question (pretend that you are a patient and seek health/medical advice; pretend that you are a healthcare...
-
[66]
* Provide a reference answer within <answer>...</answer> tags
While you should include the necessary context, you should not mention or include any part of the ground truth answer in the problem statement. * Provide a reference answer within <answer>...</answer> tags. The reference answer should be final and concise, excluding any raw thinking traces. Figure 51: Query Synthesis Prompt (Healthcare QA). Query Synthesi...
-
[67]
Extract the key entities, relations, and settings mentioned in the text sample
-
[68]
## Format * Enclose the question statement within <problem>...</problem> tags
Create a creative writing question (write a story, a scene or dialogue in a story, a narrative; expand or continue a story; construct or expand the setting of a story, etc.) that builds upon the text sample and the mentioned entities, relations, and settings. ## Format * Enclose the question statement within <problem>...</problem> tags
-
[69]
according to the text sample
In the question statement, provide the necessary context so that the question is unambiguous, self-contained, and standalone. Never use: "according to the text sample", "in the text sample", "as mentioned", "the text sample states", "based on the text sample", etc
-
[70]
While you should include the necessary context, you should not mention or include any reference answer in the question statement
-
[71]
Length: 1000 words
End your question statement with the length requirement "Length: 1000 words.". * Provide a reference answer within <answer>...</answer> tags. The reference answer should exclude any raw thinking traces. Figure 52: Query Synthesis Prompt (Creative Writing). N Prompts We show the prompts in Figure 51 through 63. 45 Query Synthesis System Prompt (Instruction...
-
[72]
according to the knowledge
In the problem statement, provide the necessary context so that the problem is unambiguous, self-contained, and standalone. Never use: "according to the knowledge", "in the knowledge", "as mentioned", "the knowledge states", "based on the knowledge", etc
-
[73]
criterion_1
While you should include the necessary context, you should not mention or include any part of the ground truth answer in the problem statement. * Provide a reference answer within <answer>...</answer> tags. The reference answer should exclude any raw thinking traces. Figure 53: Query Synthesis Prompt (Instruction Following). Query Synthesis User Prompt <k...
-
[74]
In general, the reference answer should have a high quality compared to the candidate answers, but this is not always true
Group answers (both reference and candidate answers) by quality level. In general, the reference answer should have a high quality compared to the candidate answers, but this is not always true
-
[75]
Identify factors that separate the answers in high-quality groups from those in low-quality groups
-
[76]
factuality
Select the key factors with the highest discriminative power as the criteria to include in the rubric. * Each criterion needs to be atomic and focus on a single aspect of quality. Different criteria should not overlap with each other. * Each criterion needs to be specific to the problem as much as possible. If possible, avoid general criteria that are app...
-
[77]
YYY" of
The ground truth or gold standard answer needs to be as concise as possible, ideally a single sentence or phrase (e.g., The criterion is about property "YYY" of "XXX". The ground truth answer is "ZZZ". Put "ZZZ" in the "gold" field.)
-
[78]
Not applicable
If not applicable, put "Not applicable" in "gold". * For each criterion, its description in the "description" field needs to be as specific to the problem as possible
-
[79]
XXX". To describe it, instead of saying
Do not just give a general description for the criterion. Elaborate on it with key details, key facts, key phrases, keywords, and examples (e.g., The criterion is about understanding of "XXX". To describe it, instead of saying "The level of understanding of XXX", say "The level of understanding of XXX. Correct understanding should include YYY and ZZZ. ...")
-
[80]
criterion_1
Whenever applicable, connect your description to the gold standard answer that you provide in the "gold" field. * A small number of high-quality criteria are better than a large number of low-quality criteria. 2 specific, highly distinguishing criteria >> 5 general criteria that rate all answers equally. Figure 60: Rubric Generation System Prompt. 47 Rubr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.