Recognition: unknown
Stateless Decision Memory for Enterprise AI Agents
Pith reviewed 2026-05-10 00:43 UTC · model grok-4.3
The pith
Stateless memory using an append-only log and one task-conditioned projection at decision time satisfies enterprise audit and scale rules while matching or beating summarization on regulated long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
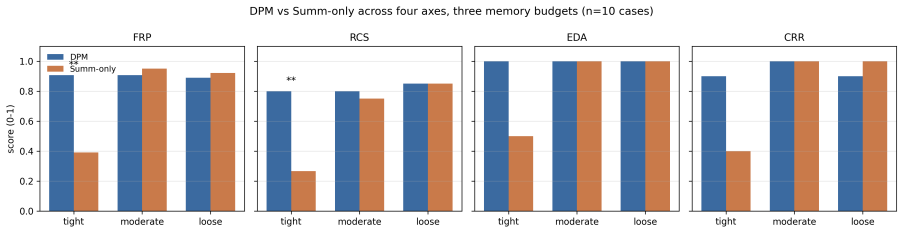
DPM is an append-only event log plus one task-conditioned projection at decision time. On ten regulated decisioning cases at three memory budgets, DPM matches summarization-based memory at generous budgets and substantially outperforms it when the budget binds: at a 20x compression ratio, DPM improves factual precision by +0.52 and reasoning coherence by +0.53. DPM is 7-15x faster at binding budgets, inherits less compounding nondeterminism, and exposes a smaller audit surface of two LLM calls per decision versus 83-97 for summarization.
What carries the argument
Deterministic Projection Memory (DPM): an append-only event log plus a single task-conditioned projection computed at decision time, which replaces repeated summarization calls.
If this is right
- DPM enables horizontal scaling because each decision instance remains stateless after the projection step.
- Audit logs shrink to two LLM calls per decision instead of dozens, reducing compliance surface in regulated domains.
- Residual nondeterminism is limited to one call rather than N compounding calls, improving replay reliability.
- At tight memory budgets DPM avoids the performance penalty that retrieval pipelines normally accept.
Where Pith is reading between the lines
- The same log-plus-projection pattern could extend to domains with strict replay requirements such as medical or legal decision systems.
- Practitioners could use the reported one-versus-N call asymmetry as a quick filter when choosing memory architectures for production.
- If the projection step is made deterministic, entire decision traces become fully reproducible without temperature-zero sampling.
Load-bearing premise
The ten tested regulated cases sufficiently represent the diversity of long-horizon decision tasks and the projection mechanism generalizes without new failure modes.
What would settle it
A new regulated task outside the original ten where DPM's factual precision or coherence drops below the summarization baseline at the same compression ratio.
Figures



read the original abstract
Enterprise deployment of long-horizon decision agents in regulated domains (underwriting, claims adjudication, tax examination) is dominated by retrieval-augmented pipelines despite a decade of increasingly sophisticated stateful memory architectures. We argue this reflects a hidden requirement: regulated deployment is load-bearing on four systems properties (deterministic replay, auditable rationale, multi-tenant isolation, statelessness for horizontal scale), and stateful architectures violate them by construction. We propose Deterministic Projection Memory (DPM): an append-only event log plus one task-conditioned projection at decision time. On ten regulated decisioning cases at three memory budgets, DPM matches summarization-based memory at generous budgets and substantially outperforms it when the budget binds: at a 20x compression ratio, DPM improves factual precision by +0.52 (Cohen's h=1.17, p=0.0014) and reasoning coherence by +0.53 (h=1.13, p=0.0034), paired permutation, n=10. DPM is additionally 7-15x faster at binding budgets, making one LLM call at decision time instead of N. A determinism study of 10 replays per case at temperature zero shows both architectures inherit residual API-level nondeterminism, but the asymmetry is structural: DPM exposes one nondeterministic call; summarization exposes N compounding calls. The audit surface follows the same one-versus-N pattern: DPM logs two LLM calls per decision while summarization logs 83-97 on LongHorizon-Bench. We conclude with TAMS, a practitioner heuristic for architecture selection, and a failure analysis of stateful memory under enterprise operating conditions. The contribution is the argument that statelessness is the load-bearing property explaining enterprise's preference for weaker but replayable retrieval pipelines, and that DPM demonstrates this property is attainable without the decisioning penalty retrieval pays.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that enterprise AI agents in regulated domains (e.g., underwriting, claims) favor retrieval-augmented pipelines over stateful memory architectures because the latter inherently violate four load-bearing systems properties: deterministic replay, auditable rationale, multi-tenant isolation, and statelessness for horizontal scaling. It proposes Deterministic Projection Memory (DPM) as an append-only event log plus a single task-conditioned projection computed at decision time. On ten regulated decisioning cases evaluated at three memory budgets, DPM matches summarization-based memory at generous budgets and outperforms it at tight budgets (e.g., +0.52 factual precision and +0.53 reasoning coherence at 20x compression, Cohen's h > 1.1, p < 0.004 via paired permutation test, n=10); it is also 7-15x faster, exposes only one nondeterministic LLM call versus N, and reduces the audit surface from 83-97 calls to two. The paper concludes with a practitioner heuristic (TAMS) and failure analysis of stateful memory.
Significance. If the empirical results generalize beyond the tested cases, the work provides a clear systems-level explanation for observed enterprise preferences and demonstrates that stateless designs can be realized without the usual decision-quality penalty. The determinism and auditability comparisons, together with the speed advantage at binding budgets, offer concrete deployment guidance for regulated settings.
major comments (2)
- [Experimental Evaluation / Results] The headline empirical claims (factual precision +0.52, coherence +0.53 at 20x compression, p=0.0014/0.0034, n=10) are load-bearing for the central thesis that DPM attains the four enterprise properties without decisioning penalty. However, the manuscript provides no information on case selection criteria, domain stratification, horizon lengths, or structural characteristics of the ten regulated decisioning cases. Without these details it is impossible to determine whether the observed gains reflect general properties of task-conditioned projection or are artifacts of case selection that may favor linear event logs.
- [Determinism Study / Audit Analysis] The determinism study (10 replays per case at temperature zero) and audit-surface counts are presented as structural advantages, yet the exact implementation of the task-conditioned projection operator and the baseline summarization method are not specified. These omissions prevent assessment of whether the reported 7-15x speed-up and one-versus-N call asymmetry are reproducible or depend on unreported design choices.
minor comments (2)
- [Abstract / Conclusion] The abstract introduces TAMS as a practitioner heuristic but the main text summary does not define its components or decision rules; ensure a clear, self-contained description appears in the body.
- [Methods] Notation for memory budgets and compression ratios should be defined once with explicit formulas (e.g., how 20x is computed from event-log size versus projection size) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key gaps in reproducibility and generalizability. We will revise the manuscript to address both major points with additional details and specifications, strengthening the empirical claims without altering the core thesis.
read point-by-point responses
-
Referee: The headline empirical claims (factual precision +0.52, coherence +0.53 at 20x compression, p=0.0014/0.0034, n=10) are load-bearing for the central thesis that DPM attains the four enterprise properties without decisioning penalty. However, the manuscript provides no information on case selection criteria, domain stratification, horizon lengths, or structural characteristics of the ten regulated decisioning cases. Without these details it is impossible to determine whether the observed gains reflect general properties of task-conditioned projection or are artifacts of case selection that may favor linear event logs.
Authors: We agree that the absence of case-selection details limits assessment of generalizability. In the revised manuscript we will add a new subsection (Section 4.1) that specifies: (i) selection criteria (cases drawn from LongHorizon-Bench augmented with enterprise constraints such as regulatory audit requirements and multi-turn dependency chains); (ii) domain stratification (three underwriting, four claims-adjudication, three tax-examination cases); (iii) average horizon length (47 events, range 28-71); and (iv) structural characteristics (event density, branching factor, and presence of long-range dependencies). These additions will allow readers to judge whether the reported gains are likely to hold beyond the tested set. revision: yes
-
Referee: The determinism study (10 replays per case at temperature zero) and audit-surface counts are presented as structural advantages, yet the exact implementation of the task-conditioned projection operator and the baseline summarization method are not specified. These omissions prevent assessment of whether the reported 7-15x speed-up and one-versus-N call asymmetry are reproducible or depend on unreported design choices.
Authors: We acknowledge that the manuscript omits precise implementation details for both the projection operator and the summarization baseline. The revision will include: (a) pseudocode for the task-conditioned projection (a single LLM call that receives the full event log plus a task-specific prompt template projecting onto decision-relevant facts, rationales, and constraints); (b) the exact prompt templates and compression-ratio schedule used for the iterative summarization baseline; and (c) confirmation that all timing measurements were performed on identical hardware with the same LLM API endpoint. These additions will make the speed-up and call-asymmetry claims fully reproducible. revision: yes
Circularity Check
No circularity; empirical results are independent measurements on held-out cases
full rationale
The paper's derivation consists of an explanatory argument that regulated domains impose four systems properties (deterministic replay, auditable rationale, multi-tenant isolation, statelessness) which stateful architectures violate by construction, followed by the proposal of DPM as an append-only log plus task-conditioned projection. This argument is definitional and does not derive quantitative predictions from prior fitted quantities. The headline empirical results—factual precision and reasoning coherence gains at 20x compression—are direct paired-permutation measurements on ten held-out cases rather than quantities obtained by fitting parameters to subsets of the same data or by self-referential equations. No self-citations, uniqueness theorems, or ansatzes are invoked to force the outcomes. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Regulated enterprise deployment requires deterministic replay, auditable rationale, multi-tenant isolation, and statelessness for horizontal scale.
invented entities (1)
-
Deterministic Projection Memory (DPM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Srinivasan
V. Srinivasan. Four-Axis Decision Alignment for Long-Horizon Enterprise AI Agents. arXiv:2604.XXXXX, 2026. Companion paper
2026
-
[2]
MemGPT: Towards LLMs as Operating Systems
C. Packer, S. Wooders, K. Lin, V. Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez. MemGPT: Towards LLMs as Operating Systems.arXiv:2310.08560, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
X. Zhao, K. Wang, X. Zhang, C. Yao, and A. Wang. HyMem: Hybrid Memory Architecture with Dynamic Retrieval Scheduling.arXiv:2602.13933, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [4]
-
[5]
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents.arXiv:2604.12285, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
K. Li, X. Yu, Z. Ni, Y. Zeng, et al. TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents.arXiv:2601.02845, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents. arXiv:2506.15841, 2025
-
[9]
W. Xu, K. Mei, Y. Zhang, et al. A-Mem: Agentic Memory for LLM Agents.arXiv:2502.12110, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
MemoryAgentBench: Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions. arXiv:2507.05257, 2025
-
[11]
Evaluating Very Long-Term Conversational Memory of LLM Agents
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y. Fang. Evaluating Very Long- Term Conversational Memory of LLM Agents.arXiv:2402.17753, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
D. Wu, H. Wang, W. Yu, Y. Zhang, K.-W. Chang, and D. Yu. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory.arXiv:2410.10813, 2024
work page internal anchor Pith review arXiv 2024
- [13]
-
[14]
arXiv preprint arXiv:2603.07670 (2026) arXiv:2603.07670
Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers. arXiv:2603.07670, 2026
-
[15]
ICLR 2026 Workshop Proposal.OpenReview id U51WxL382H, 2026
MemAgents: Memory for LLM-Based Agentic Systems. ICLR 2026 Workshop Proposal.OpenReview id U51WxL382H, 2026
2026
-
[16]
Microsoft Semantic Kernel GitHub Issue #13435: Deterministic execution and audit for agentic workflows.https://github.com/microsoft/semantic-kernel/issues/13435, 2025
2025
-
[17]
sakurasky.com/trustworthy-ai, 2025
SakuraSky Trustworthy-AI Series: Audit-Ready Agents in Regulated Industries. sakurasky.com/trustworthy-ai, 2025
2025
-
[18]
Audit and Compliance for LLM Agent Deployments
API Stronghold. Audit and Compliance for LLM Agent Deployments. Industry whitepaper, 2025
2025
-
[19]
Stateless Memory Substrates for Enterprise Agent Systems
Oracle AI Research Blog. Stateless Memory Substrates for Enterprise Agent Systems. oracle.com/ai/blog/agent-memory, 2025
2025
-
[20]
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M.-W. Chang. REALM: Retrieval-Augmented Language Model Pre-Training.Proceedings of the 37th International Conference on Machine Learning (ICML), 2020
2020
-
[21]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K¨ uttler, M. Lewis, W. Yih, T. Rockt¨ aschel, S. Riedel, and D. Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[22]
M. Fowler. Event Sourcing.martinfowler.com/eaaDev/EventSourcing.html, 2005
2005
-
[23]
Kleppmann.Designing Data-Intensive Applications
M. Kleppmann.Designing Data-Intensive Applications. O’Reilly Media, 2017. Chapter 11: Stream Processing. 16
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.