Recognition: unknown
ATIR: Towards Audio-Text Interleaved Contextual Retrieval
Pith reviewed 2026-05-09 23:21 UTC · model grok-4.3
The pith
A multimodal LLM with new audio token compression retrieves from mixed audio-text queries more accurately than prior systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
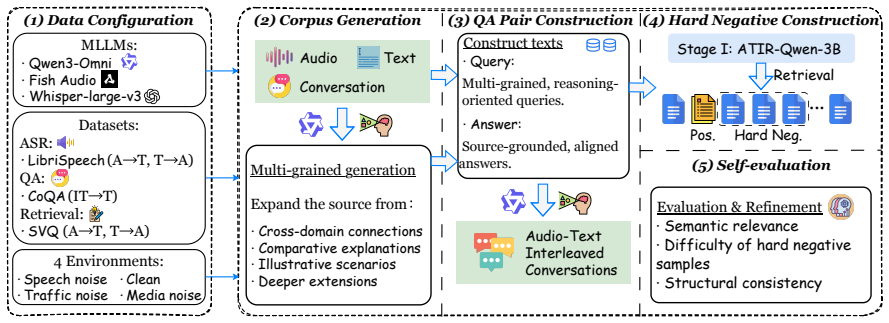
We introduce the ATIR task and benchmark, train an MLLM-based model together with a novel token compression mechanism orthogonal to prior methods, and report substantial gains over baselines on interleaved audio-text contextual retrieval.
What carries the argument
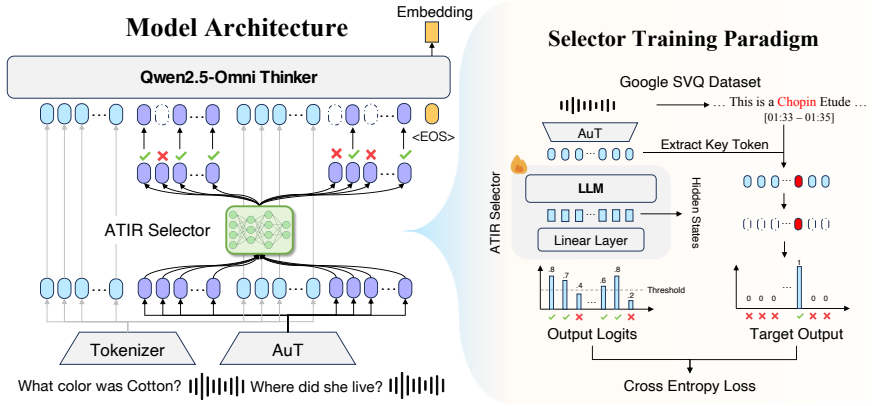
The ATIR model: a multimodal large language model that accepts alternating audio and text inputs, paired with an orthogonal token compression step that reduces audio token count to enable longer contexts.
If this is right
- Retrieval pipelines can accept queries that alternate spoken clips and typed text without first converting everything to text.
- Longer audio segments become usable inside language-model retrievers once token counts are reduced.
- A single model and benchmark can evaluate performance across speech recognition, question answering, and retrieval settings at once.
- Systems that process interleaved inputs become feasible for applications needing both spoken and written context.
Where Pith is reading between the lines
- The same compression idea could be tested on video-text interleaving to check whether the gains transfer.
- Real deployments might lower response time in assistants that let users speak then type follow-ups.
- If the benchmark misses certain natural patterns, performance on live traffic could lag behind the reported numbers.
Load-bearing premise
The assembled benchmark from existing datasets mirrors real-world mixed audio-text queries, and the token compression step keeps every detail needed for accurate retrieval.
What would settle it
A fresh collection of human-authored interleaved audio-text queries drawn from everyday use cases that the model cannot retrieve correctly while off-the-shelf baselines can.
Figures


read the original abstract
Audio carries richer information than text, including emotion, speaker traits, and environmental context, while also enabling lower-latency processing compared to speech-to-text pipelines. However, recent multimodal information retrieval research has predominantly focused on images, largely overlooking audio, especially in the setting of interleaved audio-text contextual retrieval. In this work, we introduce the Audio-Text Interleaved contextual Retrieval (ATIR) task, where queries can alternate between audio and text modalities. We construct an ATIR benchmark by integrating several Automatic Speech Recognition (ASR), QA, and retrieval datasets, ultimately unifying four types of contextual retrieval tasks. This benchmark substantially addresses the limitations of existing audio retrieval datasets in semantic retrieval. To study this task, we evaluate several off-the-shelf retrievers and train our ATIR model based on a Multimodal Large Language Model (MLLM). We further introduce a novel token compression mechanism that is orthogonal to existing compression methods, thereby alleviating the issue of excessive audio tokens in MLLM-based ATIR models. Experimental results demonstrate that our ATIR model achieves substantial improvements over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Audio-Text Interleaved Contextual Retrieval (ATIR) task, where queries alternate between audio and text. It constructs a benchmark by integrating ASR, QA, and retrieval datasets into four unified contextual retrieval tasks, evaluates off-the-shelf retrievers adapted to this setting, and proposes an ATIR model based on a Multimodal Large Language Model (MLLM) that incorporates a novel token compression mechanism claimed to be orthogonal to prior methods. Experimental results are reported to show substantial improvements over strong baselines.
Significance. If the empirical results hold, the work addresses a clear gap in multimodal retrieval by shifting focus from image-centric to audio-text interleaved queries that can encode richer contextual cues such as emotion and environment. The inclusion of ablation studies on the compression module, implementation details, and comparisons against adapted retrievers is a positive aspect that supports the central claim. The approach could influence efficient MLLM-based retrieval systems if the benchmark construction proves robust.
minor comments (2)
- [Abstract] The abstract states that the ATIR model 'achieves substantial improvements' without reporting concrete metrics, relative gains, or the specific evaluation protocol; adding these would allow immediate assessment of the strength of the results.
- [Benchmark Construction] The benchmark construction section would benefit from an explicit statement of the dataset integration rules, task unification procedure, and any steps taken to mitigate data leakage or overlap, even if high-level details are already present.
Simulated Author's Rebuttal
We thank the referee for the positive and constructive review, including the recognition of the ATIR task's novelty in addressing a gap in multimodal retrieval, the benchmark construction, and the potential impact of our token compression approach. The recommendation for minor revision is noted. No specific major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces the ATIR task and benchmark by integrating existing ASR/QA/retrieval datasets into four unified tasks, evaluates off-the-shelf retrievers, trains an MLLM-based model, and proposes a token compression mechanism described as orthogonal to prior methods. No mathematical derivations, equations, or predictions are present that reduce by construction to fitted inputs or self-definitions. Central claims rest on empirical results and ablation studies rather than self-citation chains or imported uniqueness theorems. The argument is self-contained as an empirical ML contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
Improving context understanding in multimodal large language models via multimodal composition learning , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
European Conference on Computer Vision , pages=
Uniir: Training and benchmarking universal multimodal information retrievers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[3]
Ume-r1: Exploring reasoning-driven generative multimodal embeddings.arXiv preprint arXiv:2511.00405,
UME-R1: Exploring Reasoning-Driven Generative Multimodal Embeddings , author=. arXiv preprint arXiv:2511.00405 , year=
-
[4]
2025 , eprint=
Towards Mixed-Modal Retrieval for Universal Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[5]
Emerging Properties in Unified Multimodal Pretraining
Emerging properties in unified multimodal pretraining , author=. arXiv preprint arXiv:2505.14683 , year=
work page internal anchor Pith review arXiv
-
[6]
Show-o2: Improved Native Unified Multimodal Models
Show-o2: Improved Native Unified Multimodal Models , author=. arXiv preprint arXiv:2506.15564 , year=
work page internal anchor Pith review arXiv
-
[7]
arXiv preprint arXiv:2502.14727 , year=
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models , author=. arXiv preprint arXiv:2502.14727 , year=
-
[8]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Clap learning audio concepts from natural language supervision , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[9]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Language-based audio moment retrieval , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[10]
IEEE Transactions on Multimedia , volume=
Audio retrieval with natural language queries: A benchmark study , author=. IEEE Transactions on Multimedia , volume=. 2022 , publisher=
2022
-
[11]
Qwen2. 5-omni technical report , author=. arXiv preprint arXiv:2503.20215 , year=
work page internal anchor Pith review arXiv
-
[12]
Qwen3-omni technical report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review arXiv
-
[13]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Sound event detection in the DCASE 2017 challenge , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2019 , publisher=
2017
-
[14]
IEEE Journal of Selected Topics in Signal Processing , volume=
Bigssl: Exploring the frontier of large-scale semi-supervised learning for automatic speech recognition , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[15]
IEEE Journal of Selected Topics in Signal Processing , volume=
Wavlm: Large-scale self-supervised pre-training for full stack speech processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[16]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[17]
arXiv preprint arXiv:2207.04156 , year=
Automated Audio Captioning and Language-Based Audio Retrieval , author=. arXiv preprint arXiv:2207.04156 , year=
-
[18]
arXiv preprint arXiv:2105.02192 , year=
Audio retrieval with natural language queries , author=. arXiv preprint arXiv:2105.02192 , year=
-
[19]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[20]
Publications Manual , year = "1983", publisher =
1983
-
[21]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[22]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[23]
Dan Gusfield , title =. 1997
1997
-
[24]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[25]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[26]
2016 , publisher=
Automatic speech recognition , author=. 2016 , publisher=
2016
-
[27]
2008 , publisher=
Introduction to information retrieval , author=. 2008 , publisher=
2008
-
[28]
Yijing Wu and SaiKrishna Rallabandi and Ravisutha Srinivasamurthy and Parag Pravin Dakle and Alolika Gon and Preethi Raghavan , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2304.13689 , eprinttype =. 2304.13689 , timestamp =
-
[29]
National Science Review , volume=
A survey on multimodal large language models , author=. National Science Review , volume=. 2024 , publisher=
2024
-
[30]
Jin Xu and Zhifang Guo and Hangrui Hu and Yunfei Chu and Xiong Wang and Jinzheng He and Yuxuan Wang and Xian Shi and Ting He and Xinfa Zhu and Yuanjun Lv and Yongqi Wang and Dake Guo and He Wang and Linhan Ma and Pei Zhang and Xinyu Zhang and Hongkun Hao and Zishan Guo and Baosong Yang and Bin Zhang and Ziyang Ma and Xipin Wei and Shuai Bai and Keqin Chen...
work page internal anchor Pith review doi:10.48550/arxiv.2509.17765 2025
-
[31]
Massive Sound Embedding Benchmark (MSEB) , author=
-
[32]
Tiancheng Gu and Kaicheng Yang and Ziyong Feng and Xingjun Wang and Yanzhao Zhang and Dingkun Long and Yingda Chen and Weidong Cai and Jiankang Deng , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.17432 , eprinttype =. 2504.17432 , timestamp =
-
[33]
Jin Xu and Zhifang Guo and Jinzheng He and Hangrui Hu and Ting He and Shuai Bai and Keqin Chen and Jialin Wang and Yang Fan and Kai Dang and Bin Zhang and Xiong Wang and Yunfei Chu and Junyang Lin , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.20215 , eprinttype =. 2503.20215 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2503.20215 2025
-
[34]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Compressing context to enhance inference efficiency of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[35]
Yucheng Li and Bo Dong and Frank Guerin and Chenghua Lin , editor =. Compressing Context to Enhance Inference Efficiency of Large Language Models , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.391 , timestamp =
-
[36]
Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.19205 , eprinttype =. 2508.19205 , timestamp =
-
[37]
The Eleventh International Conference on Learning Representations,
Adhiraj Banerjee and Vipul Arora , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[38]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[39]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang and Mingxin Li and Dingkun Long and Xin Zhang and Huan Lin and Baosong Yang and Pengjun Xie and An Yang and Dayiheng Liu and Junyang Lin and Fei Huang and Jingren Zhou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.05176 , eprinttype =. 2506.05176 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2506.05176 2025
-
[41]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li and Xin Zhang and Yanzhao Zhang and Dingkun Long and Pengjun Xie and Meishan Zhang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2308.03281 , eprinttype =. 2308.03281 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2308.03281 2023
-
[42]
doi: 10.18653/v1/2024.findings-acl.137
Jianlyu Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu , editor =. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.137 , timestamp =
-
[43]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang and Nan Yang and Xiaolong Huang and Linjun Yang and Rangan Majumder and Furu Wei , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.05672 , eprinttype =. 2402.05672 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2402.05672 2024
-
[44]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[45]
and Carlsson, Marcel , month = apr, year =
Benjamin Elizalde and Soham Deshmukh and Huaming Wang , title =. 2024 , url =. doi:10.1109/ICASSP48485.2024.10448504 , timestamp =
-
[46]
Full-Band General Audio Synthesis with Score-Based Diffusion
Benjamin Elizalde and Soham Deshmukh and Mahmoud Al Ismail and Huaming Wang , title =. 2023 , url =. doi:10.1109/ICASSP49357.2023.10095889 , timestamp =
-
[47]
Forty-first International Conference on Machine Learning , year=
Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark , author=. Forty-first International Conference on Machine Learning , year=
-
[48]
The Twelfth International Conference on Learning Representations,
Changli Tang and Wenyi Yu and Guangzhi Sun and Xianzhao Chen and Tian Tan and Wei Li and Lu Lu and Zejun Ma and Chao Zhang , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[49]
Multimedia Tools and Applications , volume=
Automatic speech recognition: a survey , author=. Multimedia Tools and Applications , volume=. 2021 , publisher=
2021
-
[50]
UniAudio 1.5: Large Language Model-Driven Audio Codec is
Dongchao Yang and Haohan Guo and Yuanyuan Wang and Rongjie Huang and Xiang Li and Xu Tan and Xixin Wu and Helen Meng , editor =. UniAudio 1.5: Large Language Model-Driven Audio Codec is. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - ...
2024
-
[51]
Jing Liu and Sihan Chen and Xingjian He and Longteng Guo and Xinxin Zhu and Weining Wang and Jinhui Tang , title =. 2025 , url =. doi:10.1109/TPAMI.2024.3479776 , timestamp =
-
[52]
Wave: Learning unified & versatile audio-visual embeddings with multimodal llm, 2025
Changli Tang and Qinfan Xiao and Ke Mei and Tianyi Wang and Fengyun Rao and Chao Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.21990 , eprinttype =. 2509.21990 , timestamp =
-
[53]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng and Deyao Zhu and Kunchang Li and Chenhui Gou and Feng Li and Zeyu Wang and Shu Zhong and Weihao Yu and Xiaonan Nie and Ziang Song and Shi Guang and Haoqi Fan , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.14683 , eprinttype =. 2505.14683 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2505.14683 2025
-
[54]
Xin Zhang and Xiang Lyu and Zhihao Du and Qian Chen and Dong Zhang and Hangrui Hu and Chaohong Tan and Tianyu Zhao and Yuxuan Wang and Bin Zhang and Heng Lu and Yaqian Zhou and Xipeng Qiu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.08035 , eprinttype =. 2410.08035 , timestamp =
-
[55]
Daisuke Niizumi and Daiki Takeuchi and Masahiro Yasuda and Binh Thien Nguyen and Yasunori Ohishi and Noboru Harada , title =. 2025 , url =. doi:10.1109/ACCESS.2025.3611348 , timestamp =
-
[56]
ColPali: Efficient Document Retrieval with Vision Language Models , booktitle =
Manuel Faysse and Hugues Sibille and Tony Wu and Bilel Omrani and Gautier Viaud and C. ColPali: Efficient Document Retrieval with Vision Language Models , booktitle =. 2025 , url =
2025
-
[57]
Omni-embed-nemotron: A unified multimodal retrieval model for text, image, audio, and video, 2025
Mengyao Xu and Wenfei Zhou and Yauhen Babakhin and Gabriel de Souza Pereira Moreira and Ronay Ak and Radek Osmulski and Bo Liu and Even Oldridge and Benedikt Schifferer , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.03458 , eprinttype =. 2510.03458 , timestamp =
-
[58]
Robust Speech Recognition via Large-Scale Weak Supervision , booktitle =
Alec Radford and Jong Wook Kim and Tao Xu and Greg Brockman and Christine McLeavey and Ilya Sutskever , editor =. Robust Speech Recognition via Large-Scale Weak Supervision , booktitle =. 2023 , url =
2023
-
[59]
Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on , pages=
Librispeech: an ASR corpus based on public domain audio books , author=. Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on , pages=. 2015 , organization=
2015
-
[60]
Reddy, Siva and Chen, Danqi and Manning, Christopher D. C o QA : A Conversational Question Answering Challenge. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00266
-
[61]
mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data , booktitle =
Haonan Chen and Liang Wang and Nan Yang and Yutao Zhu and Ziliang Zhao and Furu Wei and Zhicheng Dou , editor =. mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data , booktitle =. 2025 , url =
2025
-
[62]
7th International Conference on Learning Representations,
Ilya Loshchilov and Frank Hutter , title =. 7th International Conference on Learning Representations,. 2019 , url =
2019
-
[63]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.