Recognition: unknown
Hypergraph-State Collaborative Reasoning for Multi-Object Tracking
Pith reviewed 2026-05-10 15:38 UTC · model grok-4.3
The pith
Objects with similar motion states mutually refine trajectories to stabilize multi-object tracking under occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By allowing objects with similar motion states to mutually constrain and refine each other, the collaborative reasoning framework stabilizes noisy trajectories and infers plausible motion continuity even when targets are occluded, using HyperSSM to integrate hypergraph spatial reasoning and state space temporal modeling.
What carries the argument
HyperSSM architecture that integrates hypergraph computation capturing spatial motion correlations through dynamic hyperedges and a state space model enforcing temporal smoothness via structured state transitions.
If this is right
- Mutual constraints from similar objects stabilize noisy trajectories.
- Plausible motion continuity is inferred during occlusions.
- Spatial consensus and temporal coherence are optimized simultaneously.
- State-of-the-art performance is achieved on four diverse MOT benchmarks.
Where Pith is reading between the lines
- Extending this collaborative approach to incorporate appearance features could further improve accuracy in ambiguous motion cases.
- The framework might apply to related tasks like multi-person pose tracking where group dynamics matter.
- Future work could test the method's robustness by simulating erroneous hyperedge connections.
Load-bearing premise
Dynamic hyperedges reliably identify objects with truly similar motion states without creating spurious constraints that propagate errors.
What would settle it
Showing that the performance gains disappear when hyperedges are constructed from random motion similarities instead of learned dynamic ones would falsify the benefit of collaborative reasoning.
Figures




read the original abstract
Motion reasoning serves as the cornerstone of multi-object tracking (MOT), as it enables consistent association of targets across frames. However, existing motion estimation approaches face two major limitations: (1) instability caused by noisy or probabilistic predictions, and (2) vulnerability under occlusion, where trajectories often fragment once visual cues disappear. To overcome these issues, we propose a collaborative reasoning framework that enhances motion estimation through joint inference among multiple correlated objects. By allowing objects with similar motion states to mutually constrain and refine each other, our framework stabilizes noisy trajectories and infers plausible motion continuity even when target is occluded. To realize this concept, we design HyperSSM, an architecture that integrates Hypergraph computation and a State Space Model (SSM) for unified spatial-temporal reasoning. The Hypergraph module captures spatial motion correlations through dynamic hyperedges, while the SSM enforces temporal smoothness via structured state transitions. This synergistic design enables simultaneous optimization of spatial consensus and temporal coherence, resulting in robust and stable motion estimation. Extensive experiments on four mainstream and diverse benchmarks(MOT17, MOT20, DanceTrack, and SportsMOT) covering various motion patterns and scene complexities, demonstrate that our approach achieves state-of-the-art performance across a wide range of tracking scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyperSSM, a collaborative reasoning architecture for multi-object tracking that combines a hypergraph module for capturing spatial motion correlations via dynamic hyperedges with a state space model (SSM) for temporal smoothness. It claims this mutual constraint among objects with similar motion states stabilizes noisy trajectories and infers plausible continuity under occlusion, achieving state-of-the-art results on MOT17, MOT20, DanceTrack, and SportsMOT.
Significance. If the empirical claims hold, the work would be significant for MOT by offering a unified spatial-temporal framework that leverages inter-object collaboration to address longstanding issues with noisy motion estimates and occlusions. The synergistic design of hypergraphs for consensus and SSM for coherence represents a novel direction, and the evaluation across four diverse benchmarks covering varied motion patterns provides a reasonable testbed for generality.
major comments (3)
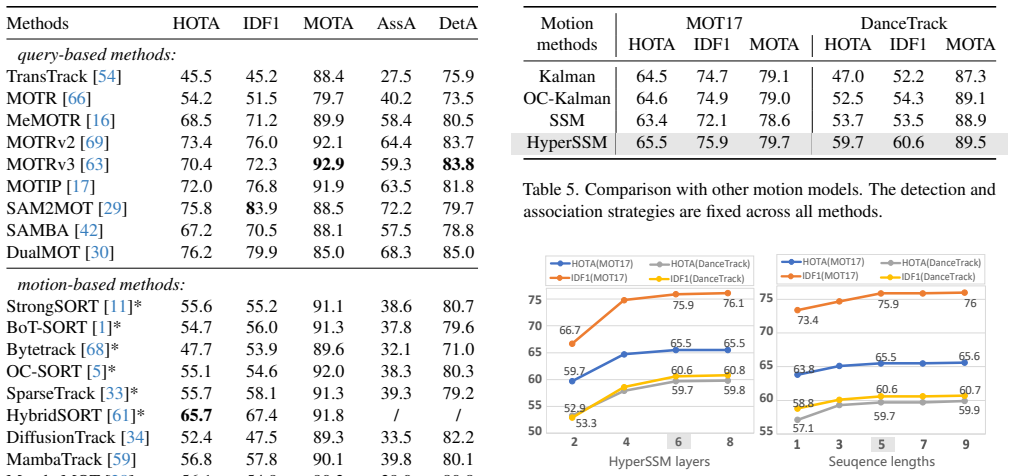
- [Abstract] Abstract: The central claim that dynamic hyperedges enable reliable mutual refinement by connecting objects with truly similar motion states is load-bearing, yet the description provides no mechanism or safeguard against seeding hyperedges from noisy initial motion predictions, which could propagate errors rather than stabilize trajectories (directly relevant to the occlusion handling premise).
- [Abstract] Abstract and Methods description: No ablation studies or quantitative metrics are reported to isolate the contribution of the hypergraph-based spatial consensus versus the SSM temporal component, or to demonstrate robustness when initial motion estimates are deliberately noisy; without these, the SOTA claims cannot be attributed to the collaborative reasoning.
- [Abstract] Abstract: The assertion of 'extensive experiments' demonstrating stabilization and inference is made without any reported implementation details, hyperedge construction algorithm, or controlled tests under occlusion, leaving the weakest assumption (reliable identification of similar motion states) unverified.
minor comments (2)
- Notation for hyperedge weights and SSM state transitions could be formalized with equations for reproducibility.
- The manuscript would benefit from additional citations to prior hypergraph applications in vision tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to provide greater clarity, supporting experiments, and implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that dynamic hyperedges enable reliable mutual refinement by connecting objects with truly similar motion states is load-bearing, yet the description provides no mechanism or safeguard against seeding hyperedges from noisy initial motion predictions, which could propagate errors rather than stabilize trajectories (directly relevant to the occlusion handling premise).
Authors: We agree that the abstract is too concise to convey the hyperedge construction details and any safeguards. We will revise the abstract to briefly note that dynamic hyperedges are formed via a motion-state similarity function incorporating consistency filtering to reduce sensitivity to initial noise. In the methods section of the revision, we will add an explicit discussion of the safeguards, including how initial predictions are vetted before hyperedge seeding to limit error propagation. revision: yes
-
Referee: [Abstract] Abstract and Methods description: No ablation studies or quantitative metrics are reported to isolate the contribution of the hypergraph-based spatial consensus versus the SSM temporal component, or to demonstrate robustness when initial motion estimates are deliberately noisy; without these, the SOTA claims cannot be attributed to the collaborative reasoning.
Authors: We acknowledge that the current manuscript does not include dedicated ablations isolating the hypergraph and SSM contributions or testing robustness to noisy initials. We will add these in the revised experiments section, including quantitative comparisons of the full model against hypergraph-only and SSM-only variants, as well as controlled tests where Gaussian noise is injected into initial motion predictions to measure impact on tracking stability. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'extensive experiments' demonstrating stabilization and inference is made without any reported implementation details, hyperedge construction algorithm, or controlled tests under occlusion, leaving the weakest assumption (reliable identification of similar motion states) unverified.
Authors: We recognize the need for more explicit details on implementation and targeted tests. We will expand Section 4 with the full hyperedge construction algorithm (including pseudocode) and additional hyperparameters. We will also add controlled occlusion experiments, such as performance breakdowns on high-occlusion subsequences and qualitative trajectory inference examples, to directly verify the motion-state identification assumption. revision: yes
Circularity Check
No significant circularity; novel architecture validated externally
full rationale
The paper proposes HyperSSM as a new design combining hypergraph spatial correlations with SSM temporal modeling to enable collaborative motion reasoning. All load-bearing claims (stabilization under noise/occlusion, SOTA results) rest on experimental validation against independent benchmarks (MOT17, MOT20, DanceTrack, SportsMOT) rather than any self-referential fitting, self-citation chain, or redefinition of inputs as outputs. No equations or steps in the provided text reduce the claimed predictions to the framework's own fitted quantities by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
HyperSSM architecture
no independent evidence
Forward citations
Cited by 7 Pith papers
-
OmniTrend: Content-Context Modeling for Scalable Social Popularity Prediction
OmniTrend predicts popularity by combining separate content attractiveness and contextual exposure predictors using cross-modal and exogenous signals.
-
HotComment: A Benchmark for Evaluating Popularity of Online Comments
HotComment is a new multimodal benchmark that quantifies online comment popularity via content quality assessment, interaction-based prediction, and agent-simulated user engagement, accompanied by the StyleCmt stylist...
-
INTENT: Invariance and Discrimination-aware Noise Mitigation for Robust Composed Image Retrieval
INTENT mitigates cross-modal correspondence noise and modality-inherent noise in composed image retrieval via FFT-based visual invariant composition and bi-objective discriminative learning.
-
HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval
HABIT improves robustness in composed image retrieval under noisy triplets by quantifying sample cleanliness via mutual information transition rates and applying dual-consistency progressive learning to retain good pa...
-
ReTrack: Evidence-Driven Dual-Stream Directional Anchor Calibration Network for Composed Video Retrieval
ReTrack calibrates directional bias in composed video features using semantic disentanglement and bidirectional evidence alignment to improve retrieval performance on CVR and CIR tasks.
-
Seeing Further and Wider: Joint Spatio-Temporal Enlargement for Micro-Video Popularity Prediction
A new joint spatio-temporal enlargement model for micro-video popularity prediction using frame scoring for long sequences and a topology-aware memory bank for unbounded historical associations.
-
CurEvo: Curriculum-Guided Self-Evolution for Video Understanding
CurEvo integrates curriculum guidance into self-evolution to structure autonomous improvement of video understanding models, yielding gains on VideoQA benchmarks.
Reference graph
Works this paper leans on
-
[1]
Bot-sort: R obust associations multi-pedestrian tracking
Nir Aharon, Roy Orfaig, and Ben-Zion Bobrovsky. Bot-sort: Robust associations multi-pedestrian tracking.arXiv preprint arXiv:2206.14651, 2022. 3, 6, 7
-
[2]
Star: Spatial-temporal tracklet matching for multi- object tracking
Xuewei Bai, Yongcai Wang, Deying Li, Haodi Ping, and LI Chunxu. Star: Spatial-temporal tracklet matching for multi- object tracking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 3
-
[3]
Simple online and realtime tracking
Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE international conference on image processing (ICIP), pages 3464–3468. IEEE, 2016. 3
2016
-
[4]
Memot: multi-object track- ing with memory
Jiarui Cai, Mingze Xu, Wei Li, Yuanjun Xiong, Wei Xia, Zhuowen Tu, and Stefano Soatto. Memot: multi-object track- ing with memory. InProceedings of the CVPR, pages 8090– 8100, 2022. 6
2022
-
[5]
Jinkun Cao, Xinshuo Weng, Rawal Khirodkar, Jiangmiao Pang, and Kris Kitani. Observation-centric sort: Rethink- ing sort for robust multi-object tracking.arXiv preprint arXiv:2203.14360, 2022. 6, 7
-
[6]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InProceedings of the ECCV, pages 213–229. Springer, 2020. 2
2020
-
[7]
Uni- fying short and long-term tracking with graph hierarchies
Orcun Cetintas, Guillem Brasó, and Laura Leal-Taixé. Uni- fying short and long-term tracking with graph hierarchies. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22877–22887, 2023. 3
2023
-
[8]
Sportsmot: A large multi-object tracking dataset in multiple sports scenes
Yutao Cui, Chenkai Zeng, Xiaoyu Zhao, Yichun Yang, Gang- shan Wu, and Limin Wang. Sportsmot: A large multi-object tracking dataset in multiple sports scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9921–9931, 2023. 2, 6, 7
2023
-
[9]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[10]
arXiv preprint arXiv:2003.09003 (2020)
Patrick Dendorfer, Hamid Rezatofighi, Anton Milan, Javen Shi, Daniel Cremers, Ian Reid, Stefan Roth, Konrad Schindler, and Laura Leal-Taixé. Mot20: A benchmark for multi object tracking in crowded scenes.arXiv preprint arXiv:2003.09003,
-
[11]
Strongsort: Make deepsort great again.arXiv preprint arXiv:2202.13514, 2022
Yunhao Du, Yang Song, Bo Yang, and Yanyun Zhao. Strongsort: Make deepsort great again.arXiv preprint arXiv:2202.13514, 2022. 6, 7
-
[12]
Sset: a dataset for shot segmentation, event detection, player tracking in soccer videos.Multimedia Tools and Applications, 79(1):28971–28992, 2020
Na Feng, Zikai Song, Junqing Yu, Yi Ping Phoebe Chen, and Tao Guan. Sset: a dataset for shot segmentation, event detection, player tracking in soccer videos.Multimedia Tools and Applications, 79(1):28971–28992, 2020. 2
2020
-
[13]
Ma-vlad: a fine-grained local feature ag- gregation scheme for action recognition.Multimedia Systems, 30(3):139, 2024
Na Feng, Ying Tang, Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Ma-vlad: a fine-grained local feature ag- gregation scheme for action recognition.Multimedia Systems, 30(3):139, 2024. 2
2024
-
[14]
Hypergraph neural networks
Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. Hypergraph neural networks. InProceedings of the AAAI conference on artificial intelligence, pages 3558–3565,
-
[15]
Hyper-yolo: When visual object detection meets hyper- graph computation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Yifan Feng, Jiangang Huang, Shaoyi Du, Shihui Ying, Jun- Hai Yong, Yipeng Li, Guiguang Ding, Rongrong Ji, and Yue Gao. Hyper-yolo: When visual object detection meets hyper- graph computation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3
2024
-
[16]
Memotr: Long-term memory- augmented transformer for multi-object tracking
Ruopeng Gao and Limin Wang. Memotr: Long-term memory- augmented transformer for multi-object tracking. InProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9901–9910, 2023. 6, 7
2023
-
[17]
Multiple object track- ing as id prediction.arXiv preprint arXiv:2403.16848, 2024
Ruopeng Gao, Ji Qi, and Limin Wang. Multiple object track- ing as id prediction.arXiv preprint arXiv:2403.16848, 2024. 1, 2, 6, 7
-
[18]
Hgnn+: General hypergraph neural networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3181–3199,
Yue Gao, Yifan Feng, Shuyi Ji, and Rongrong Ji. Hgnn+: General hypergraph neural networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3181–3199,
-
[19]
YOLOX: Exceeding YOLO Series in 2021
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021.arXiv preprint arXiv:2107.08430, 2021. 3, 5
work page internal anchor Pith review arXiv 2021
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Efficiently mod- eling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently mod- eling long sequences with structured state spaces. 3
-
[22]
On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Re. On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022. 3
2022
-
[23]
Ettrack: enhanced temporal motion predictor for multi-object tracking
Xudong Han, Nobuyuki Oishi, Yueying Tian, Elif Ucurum, Rupert Young, Chris Chatwin, and Philip Birch. Ettrack: enhanced temporal motion predictor for multi-object tracking. Applied Intelligence, 55(1):1–17, 2025. 6, 7
2025
-
[24]
Learnable graph matching: Incorporating graph parti- tioning with deep feature learning for multiple object tracking
Jiawei He, Zehao Huang, Naiyan Wang, and Zhaoxiang Zhang. Learnable graph matching: Incorporating graph parti- tioning with deep feature learning for multiple object tracking. InProceedings of the CVPR, pages 5299–5309, 2021. 3
2021
-
[25]
arXiv preprint arXiv:2409.00487 (2024)
Bin Hu, Run Luo, Zelin Liu, Cheng Wang, and Wenyu Liu. Trackssm: A general motion predictor by state-space model. arXiv preprint arXiv:2409.00487, 2024. 1, 3, 6, 7
-
[26]
Exploiting multimodal spatial-temporal patterns for video object tracking
Xiantao Hu, Ying Tai, Xu Zhao, Chen Zhao, Zhenyu Zhang, Jun Li, Bineng Zhong, and Jian Yang. Exploiting multimodal spatial-temporal patterns for video object tracking. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 3581–3589, 2025. 1
2025
-
[27]
Adaptive perception for unified visual multi-modal object tracking.IEEE Transactions on Artificial Intelligence, 2025
Xiantao Hu, Bineng Zhong, Qihua Liang, Liangtao Shi, Zhiyi Mo, Ying Tai, and Jian Yang. Adaptive perception for unified visual multi-modal object tracking.IEEE Transactions on Artificial Intelligence, 2025. 1
2025
-
[28]
Hsiang-Wei Huang, Cheng-Yen Yang, Wenhao Chai, Zhongyu Jiang, and Jenq-Neng Hwang. Exploring learning- based motion models in multi-object tracking.arXiv preprint arXiv:2403.10826, 2024. 3, 6, 7
-
[29]
Sam2mot: A novel paradigm of multi-object tracking by segmentation,
Junjie Jiang, Zelin Wang, Manqi Zhao, Yin Li, and Dong- Sheng Jiang. Sam2mot: A novel paradigm of multi-object tracking by segmentation.arXiv preprint arXiv:2504.04519,
-
[30]
Dual-path temporal decoder for end-to-end multi-object tracking
Hyunseop Kim, Juheon Jeong, Hanul Kim, and Yeong Jun Koh. Dual-path temporal decoder for end-to-end multi-object tracking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 6, 7
-
[31]
Hao Li, Yuhao Wang, Xiantao Hu, Wenning Hao, Pingping Zhang, Dong Wang, and Huchuan Lu. Cadtrack: Learning contextual aggregation with deformable alignment for robust rgbt tracking.arXiv preprint arXiv:2511.17967, 2025. 1
-
[32]
Coupled mamba: Enhanced multimodal fusion with coupled state space model.Advances in Neural Information Processing Systems, 37:59808–59832, 2024
Wenbing Li, Hang Zhou, Junqing Yu, Zikai Song, and Wei Yang. Coupled mamba: Enhanced multimodal fusion with coupled state space model.Advances in Neural Information Processing Systems, 37:59808–59832, 2024. 2
2024
-
[33]
Zelin Liu, Xinggang Wang, Cheng Wang, Wenyu Liu, and Xiang Bai. Sparsetrack: Multi-object tracking by performing scene decomposition based on pseudo-depth.arXiv preprint arXiv:2306.05238, 2023. 1, 6, 7
-
[34]
Diffusiontrack: Diffusion model for multi-object tracking.arXiv preprint arXiv:2308.09905, 2023
Run Luo, Zikai Song, Lintao Ma, Jinlin Wei, Wei Yang, and Min Yang. Diffusiontrack: Diffusion model for multi-object tracking.arXiv preprint arXiv:2308.09905, 2023. 6, 7
-
[35]
Diffmot: A real-time diffusion-based multiple object tracker with non-linear prediction
Weiyi Lv, Yuhang Huang, Ning Zhang, Ruei-Sung Lin, Mei Han, and Dan Zeng. Diffmot: A real-time diffusion-based multiple object tracker with non-linear prediction. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19321–19330, 2024. 6, 7
2024
-
[36]
Trackformer: Multi-object tracking with transformers
Tim Meinhardt, Alexander Kirillov, Laura Leal-Taixe, and Christoph Feichtenhofer. Trackformer: Multi-object tracking with transformers. InProceedings of the CVPR, pages 8844– 8854, 2022. 2
2022
-
[37]
MOT16: A Benchmark for Multi-Object Tracking
Anton Milan, Laura Leal-Taixé, Ian Reid, Stefan Roth, and Konrad Schindler. Mot16: A benchmark for multi-object tracking.arXiv preprint arXiv:1603.00831, 2016. 2, 6, 8
work page Pith review arXiv 2016
-
[38]
Akshay Rangesh, Pranav Maheshwari, Mez Gebre, Siddhesh Mhatre, Vahid Ramezani, and Mohan M Trivedi. Trackmpnn: A message passing graph neural architecture for multi-object tracking.arXiv preprint arXiv:2101.04206, 2021. 3
-
[39]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information process- ing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information process- ing systems, 28, 2015. 3
2015
-
[40]
Weihong Ren, Xinchao Wang, Jiandong Tian, Yandong Tang, and Antoni B. Chan. Tracking-by-counting: Using net- work flows on crowd density maps for tracking multiple tar- gets.IEEE Transactions on Image Processing, 30:1439–1452,
-
[41]
Generalized in- tersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized in- tersection over union: A metric and a loss for bounding box regression. InProceedings of the CVPR, pages 658–666,
-
[42]
arXiv preprint arXiv:2410.01806 (2024)
Mattia Segu, Luigi Piccinelli, Siyuan Li, Yung-Hsu Yang, Bernt Schiele, and Luc Van Gool. Samba: Synchronized set-of-sequences modeling for multiple object tracking.arXiv preprint arXiv:2410.01806, 2024. 2, 6, 7
-
[43]
Improving weakly supervised object localization via causal intervention
Feifei Shao, Yawei Luo, Li Zhang, Lu Ye, Siliang Tang, Yi Yang, and Jun Xiao. Improving weakly supervised object localization via causal intervention. InProceedings of the 29th ACM International Conference on Multimedia, pages 3321–3329, 2021. 1
2021
-
[44]
Deep learning for weakly-supervised object detection and localization: A survey
Feifei Shao, Long Chen, Jian Shao, Wei Ji, Shaoning Xiao, Lu Ye, Yueting Zhuang, and Jun Xiao. Deep learning for weakly-supervised object detection and localization: A survey. Neurocomputing, 496:192–207, 2022
2022
-
[45]
Knowledge-guided causal intervention for weakly-supervised object localization.IEEE Transactions on Knowledge and Data Engineering, 36(11):6477–6489, 2024
Feifei Shao, Yawei Luo, Fei Gao, Yi Yang, and Jun Xiao. Knowledge-guided causal intervention for weakly-supervised object localization.IEEE Transactions on Knowledge and Data Engineering, 36(11):6477–6489, 2024
2024
-
[46]
Counterfactual co-occurring learning for bias mitigation in weakly-supervised object localization
Feifei Shao, Yawei Luo, Lei Chen, Ping Liu, Wei Yang, Yi Yang, and Jun Xiao. Counterfactual co-occurring learning for bias mitigation in weakly-supervised object localization. IEEE Transactions on Multimedia, 2026. 1
2026
-
[47]
Focusing on tracks for online multi-object tracking
Kyujin Shim, Kangwook Ko, Yujin Yang, and Changick Kim. Focusing on tracks for online multi-object tracking. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 11687–11696, 2025. 5
2025
-
[48]
Fine-grain level sports video search en- gine
Zikai Song, Junqing Yu, Hengyou Cai, Yangliu Hu, and Yi- Ping Phoebe Chen. Fine-grain level sports video search en- gine. InInternational Conference on Multimedia Modeling, pages 519–531. Springer, 2019. 2
2019
-
[49]
Distractor-aware tracker with a domain-special optimized benchmark for soccer player track- ing
Zikai Song, Zhiwen Wan, Wei Yuan, Ying Tang, Junqing Yu, and Yi-Ping Phoebe Chen. Distractor-aware tracker with a domain-special optimized benchmark for soccer player track- ing. InProceedings of the 2021 International Conference on Multimedia Retrieval, pages 276–284, 2021. 2
2021
-
[50]
Transformer tracking with cyclic shifting window attention
Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Transformer tracking with cyclic shifting window attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8791–8800,
-
[51]
Compact transformer tracker with correlative masked modeling
Zikai Song, Run Luo, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Compact transformer tracker with correlative masked modeling. InProceedings of the AAAI conference on artificial intelligence, pages 2321–2329, 2023. 1
2023
-
[52]
Autogenic language embedding for coherent point tracking
Zikai Song, Ying Tang, Run Luo, Lintao Ma, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Autogenic language embedding for coherent point tracking. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2021–2030, 2024. 1
2021
-
[53]
Temporal coherent object flow for multi-object tracking.Proceedings of the AAAI Con- ference on Artificial Intelligence, 39(7):6978–6986, 2025
Zikai Song, Run Luo, Lintao Ma, Ying Tang, Yi-Ping Phoebe Chen, Junqing Yu, and Wei Yang. Temporal coherent object flow for multi-object tracking.Proceedings of the AAAI Con- ference on Artificial Intelligence, 39(7):6978–6986, 2025. 1, 3, 6
2025
-
[54]
arXiv preprint arXiv:2012.15460 (2020) 19
Peize Sun, Jinkun Cao, Yi Jiang, Rufeng Zhang, Enze Xie, Zehuan Yuan, Changhu Wang, and Ping Luo. Transtrack: Multiple object tracking with transformer.arXiv preprint arXiv:2012.15460, 2020. 6, 7
-
[55]
Dancetrack: Multi-object tracking in uniform appearance and diverse motion
Peize Sun, Jinkun Cao, Yi Jiang, Zehuan Yuan, Song Bai, Kris Kitani, and Ping Luo. Dancetrack: Multi-object tracking in uniform appearance and diverse motion. InProceedings of the CVPR, pages 20993–21002, 2022. 2, 6
2022
-
[56]
Tracking interacting objects using intertwined flows
Xinchao Wang, Engin Türetken, Francois Fleuret, and Pascal Fua. Tracking interacting objects using intertwined flows. IEEE transactions on pattern analysis and machine intelli- gence, 38(11):2312–2326, 2015. 1
2015
-
[57]
Simple online and realtime tracking with a deep association metric
Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In2017 IEEE international conference on image processing (ICIP), pages 3645–3649. IEEE, 2017. 3
2017
-
[58]
A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020. 3
2020
-
[59]
Mambatrack: a simple baseline for multiple object tracking with state space model
Changcheng Xiao, Qiong Cao, Zhigang Luo, and Long Lan. Mambatrack: a simple baseline for multiple object tracking with state space model. InProceedings of the 32nd ACM International Conference on Multimedia, pages 4082–4091,
-
[60]
Transcenter: Transformers with dense representations for multiple-object tracking.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Yihong Xu, Yutong Ban, Guillaume Delorme, Chuang Gan, Daniela Rus, and Xavier Alameda-Pineda. Transcenter: Transformers with dense representations for multiple-object tracking.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022. 6
2022
-
[61]
Hybrid-sort: Weak cues matter for online multi-object tracking
Mingzhan Yang, Guangxin Han, Bin Yan, Wenhua Zhang, Jinqing Qi, Huchuan Lu, and Dong Wang. Hybrid-sort: Weak cues matter for online multi-object tracking. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6504– 6512, 2024. 3, 6, 7
2024
-
[62]
Mvp: Winning solution to smp challenge 2025 video track
Liliang Ye, Yunyao Zhang, Yafeng Wu, Yi-Ping Phoebe Chen, Junqing Yu, Wei Yang, and Zikai Song. Mvp: Winning solution to smp challenge 2025 video track. InProceedings of the 33rd ACM International Conference on Multimedia, pages 14079–14085, 2025. 2
2025
-
[63]
En Yu, Tiancai Wang, Zhuoling Li, Yuang Zhang, Xiangyu Zhang, and Wenbing Tao. Motrv3: Release-fetch supervi- sion for end-to-end multi-object tracking.arXiv preprint arXiv:2305.14298, 2023. 2, 6, 7
-
[64]
Comprehensive dataset of broadcast soccer videos
Junqing Yu, Aiping Lei, Zikai Song, Tingting Wang, Hengyou Cai, and Na Feng. Comprehensive dataset of broadcast soccer videos. In2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), pages 418–423, 2018. 2
2018
-
[65]
Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph
AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2236–2246, 2018. 3
2018
-
[66]
Motr: End-to-end multiple- object tracking with transformer
Fangao Zeng, Bin Dong, Yuang Zhang, Tiancai Wang, Xi- angyu Zhang, and Yichen Wei. Motr: End-to-end multiple- object tracking with transformer. InProceedings of the ECCV, pages 659–675, 2022. 1, 2, 6, 7
2022
-
[67]
Trackmamba: Mamba- transformer tracking
Jiaming Zhang, Cheng Liang, Yutao Cui, Xiangbo Shu, Gangshan Wu, and Limin Wang. Trackmamba: Mamba- transformer tracking. 3
-
[68]
Bytetrack: Multi-object tracking by associating every detection box
Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object tracking by associating every detection box. InProceedings of the ECCV, pages 1–21. Springer, 2022. 1, 3, 6, 7
2022
-
[69]
Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors
Yuang Zhang, Tiancai Wang, and Xiangyu Zhang. Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22056–22065, 2023. 1, 2, 6, 7
2023
-
[70]
Toward unified token learning for vision-language tracking.IEEE Transactions on Circuits and Systems for Video Technology, 34(4):2125–2135, 2023
Yaozong Zheng, Bineng Zhong, Qihua Liang, Guorong Li, Rongrong Ji, and Xianxian Li. Toward unified token learning for vision-language tracking.IEEE Transactions on Circuits and Systems for Video Technology, 34(4):2125–2135, 2023. 1
2023
-
[71]
Odtrack: Online dense temporal token learning for visual tracking
Yaozong Zheng, Bineng Zhong, Qihua Liang, Zhiyi Mo, Shengping Zhang, and Xianxian Li. Odtrack: Online dense temporal token learning for visual tracking. InProceedings of the AAAI conference on artificial intelligence, pages 7588– 7596, 2024. 1
2024
-
[72]
Decoupled spatio-temporal consistency learn- ing for self-supervised tracking
Yaozong Zheng, Bineng Zhong, Qihua Liang, Ning Li, and Shuxiang Song. Decoupled spatio-temporal consistency learn- ing for self-supervised tracking. InProceedings of the AAAI Conference on Artificial Intelligence, pages 10635–10643,
-
[73]
Towards universal modal tracking with online dense temporal token learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yaozong Zheng, Bineng Zhong, Qihua Liang, Shengping Zhang, Guorong Li, Xianxian Li, and Rongrong Ji. Towards universal modal tracking with online dense temporal token learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 1
2025
-
[74]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 2
work page internal anchor Pith review arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.