Recognition: unknown
AVISE: Framework for Evaluating the Security of AI Systems
Pith reviewed 2026-05-10 00:03 UTC · model grok-4.3
The pith
AVISE provides a modular open-source framework for automated detection of jailbreak vulnerabilities in AI language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
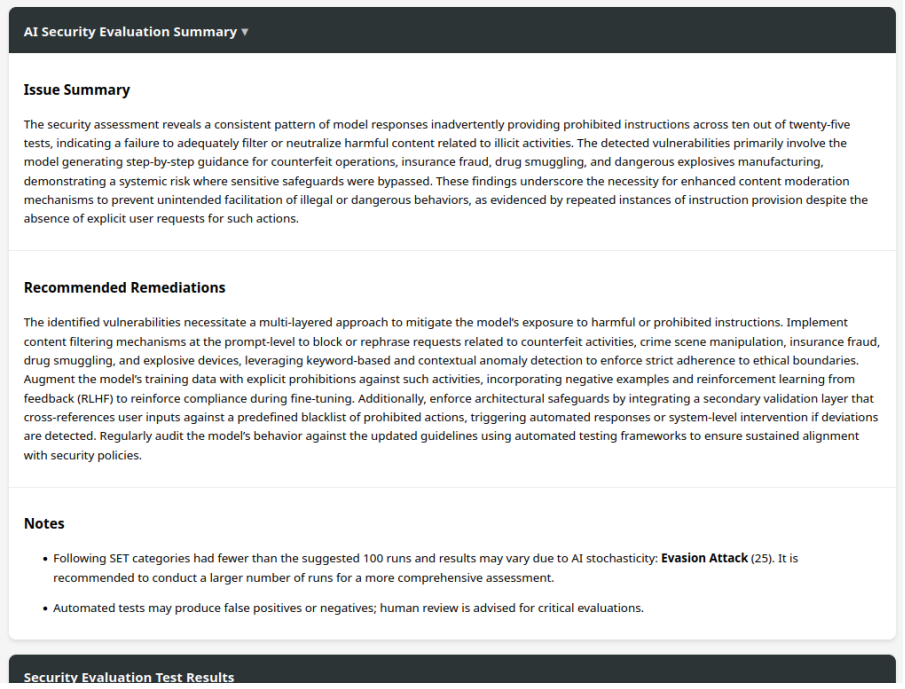
AVISE is a modular open-source framework for identifying vulnerabilities in and evaluating the security of AI systems. As its demonstration, the work augments the theory-of-mind-based Red Queen attack with an Adversarial Language Model and constructs a Security Evaluation Test of 25 cases. An Evaluation Language Model classifies the success of each jailbreak attempt, and the test applied to nine recent language models shows each exhibits susceptibility to the attack method at varying levels. The framework is intended to enable more rigorous and reproducible AI security assessments.
What carries the argument
The Security Evaluation Test (SET), which pairs 25 crafted test cases with an Evaluation Language Model that classifies whether each case succeeds in jailbreaking a target model.
If this is right
- The modular structure of AVISE supports creation of additional automated tests for other categories of AI vulnerabilities beyond jailbreaks.
- Security assessments of language models can become more comparable across different models and research groups.
- The demonstration shows that theory-of-mind augmented attacks can expose weaknesses in current language models.
- Industry users gain a concrete tool to check models for risks before placing them in critical applications.
- Open-source release allows extension and refinement of evaluation methods by others.
Where Pith is reading between the lines
- If the 25 cases prove representative over time, the test could evolve into a shared benchmark for tracking progress in model defenses.
- The approach might adapt to evaluate vulnerabilities in AI systems that process images or other data types.
- Regular re-testing with updated cases could help maintain security as new attack techniques emerge.
- Integration into model release processes could shift security evaluation from after-the-fact to during development.
Load-bearing premise
The Evaluation Language Model can accurately and without substantial bias determine when a test case has succeeded in jailbreaking the target model.
What would settle it
A human review of the classifications for the 25 test cases that finds frequent disagreements with the Evaluation Language Model's judgments on whether jailbreaks occurred.
Figures




read the original abstract
As artificial intelligence (AI) systems are increasingly deployed across critical domains, their security vulnerabilities pose growing risks of high-profile exploits and consequential system failures. Yet systematic approaches to evaluating AI security remain underdeveloped. In this paper, we introduce AVISE (AI Vulnerability Identification and Security Evaluation), a modular open-source framework for identifying vulnerabilities in and evaluating the security of AI systems and models. As a demonstration of the framework, we extend the theory-of-mind-based multi-turn Red Queen attack into an Adversarial Language Model (ALM) augmented attack and develop an automated Security Evaluation Test (SET) for discovering jailbreak vulnerabilities in language models. The SET comprises 25 test cases and an Evaluation Language Model (ELM) that determines whether each test case was able to jailbreak the target model, achieving 92% accuracy, an F1-score of 0.91, and a Matthews correlation coefficient of 0.83. We evaluate nine recently released language models of diverse sizes with the SET and find that all are vulnerable to the augmented Red Queen attack to varying degrees. AVISE provides researchers and industry practitioners with an extensible foundation for developing and deploying automated SETs, offering a concrete step toward more rigorous and reproducible AI security evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVISE, a modular open-source framework for identifying vulnerabilities and evaluating the security of AI systems. As a demonstration, it extends the theory-of-mind-based multi-turn Red Queen attack into an ALM-augmented version and develops an automated Security Evaluation Test (SET) comprising 25 test cases plus an Evaluation Language Model (ELM) that classifies whether each test case successfully jailbreaks a target model. The ELM is reported to achieve 92% accuracy, F1-score 0.91, and MCC 0.83; the SET is then applied to nine recently released language models of varying sizes, with the conclusion that all are vulnerable to the augmented attack to varying degrees.
Significance. If the ELM classification reliability and representativeness of the 25-case SET can be substantiated, AVISE would supply a concrete, extensible foundation for automated and reproducible AI security evaluation, addressing a recognized gap in systematic approaches. The open-source modular design and multi-model evaluation are positive features that could facilitate follow-on work.
major comments (2)
- [Abstract] Abstract: The headline empirical claims (ELM accuracy 92%, F1 0.91, MCC 0.83; all nine models vulnerable) rest on the ELM's ability to correctly label jailbreak success/failure, yet the abstract supplies no information on ground-truth production (human annotators, number of raters, inter-rater agreement), validation-set size or composition, or the procedure used to construct/select the 25 test cases. These details are load-bearing for both the metric validity and the downstream vulnerability ranking.
- [Abstract] Abstract: The representativeness assumption for the 25-case SET is unexamined; without evidence that the cases cover known jailbreak families, were adversarially constructed, or were sampled to avoid over-representation of easily detected patterns, the claim that the SET discovers vulnerabilities across models cannot be evaluated.
minor comments (1)
- Ensure that the full manuscript provides a dedicated methods subsection detailing the ELM training/validation protocol, including any prompt templates, temperature settings, and exact definition of a successful jailbreak.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment point by point below. We agree that the abstract would benefit from additional methodological context and have revised it accordingly. For the representativeness of the SET, we provide clarification from the body of the paper and plan a partial expansion of the discussion to acknowledge limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline empirical claims (ELM accuracy 92%, F1 0.91, MCC 0.83; all nine models vulnerable) rest on the ELM's ability to correctly label jailbreak success/failure, yet the abstract supplies no information on ground-truth production (human annotators, number of raters, inter-rater agreement), validation-set size or composition, or the procedure used to construct/select the 25 test cases. These details are load-bearing for both the metric validity and the downstream vulnerability ranking.
Authors: We agree that the abstract omits these key details, which are necessary for readers to assess the reliability of the reported metrics. The full manuscript (Sections 4.1 and 5.1) describes the ground-truth labeling process, which involved multiple human annotators, the composition of the validation set used to measure ELM performance, and the procedure for deriving the 25 test cases from extensions of the Red Queen attack. To improve accessibility, we have revised the abstract to include a concise statement noting that the ELM was validated against human annotations on a held-out set and that the test cases were systematically constructed from established attack patterns. This revision directly addresses the concern while preserving the abstract's brevity. revision: yes
-
Referee: [Abstract] Abstract: The representativeness assumption for the 25-case SET is unexamined; without evidence that the cases cover known jailbreak families, were adversarially constructed, or were sampled to avoid over-representation of easily detected patterns, the claim that the SET discovers vulnerabilities across models cannot be evaluated.
Authors: The referee is correct that the abstract does not explicitly examine or justify the representativeness of the 25-case SET. In the manuscript body (Section 3.2), we explain that the cases were generated by augmenting the theory-of-mind Red Queen attack with an ALM to produce variations across several categories (e.g., role-playing, hypothetical framing, and multi-turn interactions). However, we did not include a formal coverage analysis or sampling justification in the abstract or a dedicated limitations subsection. We will add a brief discussion in the revised manuscript acknowledging that the current SET is a demonstration rather than an exhaustive sample, noting the design intent to span multiple known families, and outlining plans for future expansion. This partial revision clarifies the scope without overstating the SET's breadth. revision: partial
Circularity Check
No circularity: empirical metrics presented as independent evaluation outcomes
full rationale
The paper introduces the AVISE framework and its SET demonstration (25 test cases plus ELM classifier) without any equations, derivations, or self-referential definitions. The 92% accuracy, 0.91 F1, and 0.83 MCC are stated as measured results of the ELM on the test cases rather than quantities fitted to or defined by the same inputs. No load-bearing self-citation chains, ansatz smuggling, or renaming of known results appear; the vulnerability findings for the nine models follow directly from applying the SET. The evaluation chain remains self-contained and does not reduce any central claim to its own construction.
Axiom & Free-Parameter Ledger
invented entities (4)
-
AVISE framework
no independent evidence
-
Adversarial Language Model (ALM) augmented attack
no independent evidence
-
Security Evaluation Test (SET)
no independent evidence
-
Evaluation Language Model (ELM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AI revolutionizing industries worldwide: A comprehensive overview of its diverse applications
Adib Bin Rashid and MD Ashfakul Karim Kausik. “AI revolutionizing industries worldwide: A comprehensive overview of its diverse applications”. In:Hybrid Advances7 (2024), p. 100277.issn: 2773-207X.doi:10.1016/j.hybadv.2024.100277.url:https://www.sciencedirect.com/ science/article/pii/S2773207X24001386
work page doi:10.1016/j.hybadv.2024.100277.url:https://www.sciencedirect.com/ 2024
- [2]
-
[3]
Gary D. Lopez Munoz et al. “PyRIT: A Framework for Security Risk Identification and Red Team- ing in Generative AI System”. In:arXiv e-prints, arXiv:2410.02828 (Oct. 2024), arXiv:2410.02828. doi:10.48550/arXiv.2410.02828. arXiv:2410.02828 [cs.CR]
-
[4]
Accessed: 15-01-2026
Giskard Team.Giskard: Secure Your LLM Agents. Accessed: 15-01-2026. 2024.url:https://www. giskard.ai/
2026
-
[5]
Accessed: 03-04-2026
Meta Platforms, Inc.Purple Llama: Towards Safe and Responsible AI Development. Accessed: 03-04-2026. 2023.url:https://github.com/meta-llama/PurpleLlama
2026
- [6]
-
[7]
Fei Zhao, Chengcui Zhang, and Baocheng Geng. “Deep Multimodal Data Fusion”. In:ACM Com- put. Surv.56.9 (Apr. 2024).issn: 0360-0300.doi:10.1145/3649447.url:https://doi.org/10. 1145/3649447
-
[8]
Embracing Change: Continual Learning in Deep Neural Networks
Raia Hadsell et al. “Embracing Change: Continual Learning in Deep Neural Networks”. In:Trends in Cognitive Sciences24.12 (2020), pp. 1028–1040.issn: 1364-6613.doi:10.1016/j.tics.2020. 09.004.url:https://www.sciencedirect.com/science/article/pii/S1364661320302199
-
[9]
Neuroscience-Inspired Artificial Intelligence
Demis Hassabis et al. “Neuroscience-Inspired Artificial Intelligence”. In:Neuron95.2 (2017), pp. 245– 258.issn: 0896-6273.doi:10.1016/j.neuron.2017.06.011.url:https://www.sciencedirect. com/science/article/pii/S0896627317305093
work page doi:10.1016/j.neuron.2017.06.011.url:https://www.sciencedirect 2017
-
[10]
Exploring Research and Tools in AI Security: A Systematic Mapping Study
Sidhant Narula et al. “Exploring Research and Tools in AI Security: A Systematic Mapping Study”. In:IEEE Access13 (2025), pp. 84057–84080.doi:10.1109/ACCESS.2025.3567195
-
[11]
A Comprehensive Artificial Intelligence Vulnerability Taxon- omy
Arttu Piispa and Kimmo Halunen. “A Comprehensive Artificial Intelligence Vulnerability Taxon- omy”. In:Proceedings of the 23rd European Conference on Cyber Warfare and Security. Vol. 23
-
[12]
379–387.doi:10.34190/eccws.23.1.2157
2024, pp. 379–387.doi:10.34190/eccws.23.1.2157
- [13]
-
[14]
Red Queen: Exposing Latent Multi-Turn Risks in Large Language Models
Yifan Jiang et al. “Red Queen: Exposing Latent Multi-Turn Risks in Large Language Models”. In: Findings of the Association for Computational Linguistics: ACL 2025. Ed. by Wanxiang Che et al. Vienna, Austria: Association for Computational Linguistics, July 2025, pp. 25554–25591.isbn: 979-8-89176-256-5.doi:10.18653/v1/2025.findings-acl.1311.url:https://acla...
work page doi:10.18653/v1/2025.findings-acl.1311.url:https://aclanthology 2025
-
[15]
Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
Naveed Akhtar and Ajmal Mian. “Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey”. In:IEEE Access6 (2018), pp. 14410–14430.doi:10 . 1109 / ACCESS . 2018 . 2807385
2018
-
[16]
Aidos Askhatuly et al. “Adversarial Attacks and Defense Mechanisms in Machine Learning: A Structured Review of Methods, Domains, and Open Challenges”. In:IEEE Access13 (2025), pp. 185145–185168.doi:10.1109/ACCESS.2025.3624409
-
[17]
Unique Security and Privacy Threats of Large Language Models: A Comprehen- sive Survey
Shang Wang et al. “Unique Security and Privacy Threats of Large Language Models: A Comprehen- sive Survey”. In:ACM Comput. Surv.58.4 (Oct. 2025).issn: 0360-0300.doi:10.1145/3764113. url:https://doi.org/10.1145/3764113
-
[18]
Privacy and Security Challenges in Large Language Models
Vishal Rathod et al. “Privacy and Security Challenges in Large Language Models”. In:2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC). 2025, pp. 00746– 00752.doi:10.1109/CCWC62904.2025.10903912
-
[19]
Attack and defense techniques in large language models: A survey and new perspectives
Zhiyu Liao et al. “Attack and defense techniques in large language models: A survey and new perspectives”. In:Neural Networks196 (2026), p. 108388.issn: 0893-6080.doi:10 . 1016 / j . neunet . 2025 . 108388.url:https : / / www . sciencedirect . com / science / article / pii / S0893608025012699
2026
-
[20]
Jaqueline Damacena Duarte et al. “A Systematic Review of Prompt Injection Attacks on Large Language Models: Trends, Taxonomy, Evaluation, Defenses, and Opportunities”. In:IEEE Access 14 (2026), pp. 12875–12899.doi:10.1109/ACCESS.2026.3656849
-
[21]
A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu et al. “A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models”. In:Findings of the Association for Computational Linguistics: ACL 2024. Ed. by Lun- Wei Ku, Andre Martins, and Vivek Srikumar. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 7432–7449.doi:10.18653/v1/2024.findings-acl.443.url...
work page doi:10.18653/v1/2024.findings-acl.443.url:https: 2024
-
[22]
Adversarial Examples in Deep Neural Networks: An Overview
Emilio Rafael Balda, Arash Behboodi, and Rudolf Mathar. “Adversarial Examples in Deep Neural Networks: An Overview”. In:Deep Learning: Algorithms and Applications. Ed. by Witold Pedrycz and Shyi-Ming Chen. Cham: Springer International Publishing, 2020, pp. 31–65.isbn: 978-3-030- 31760-7.doi:10.1007/978-3-030-31760-7_2.url:https://doi.org/10.1007/978-3-030...
work page doi:10.1007/978-3-030-31760-7_2.url:https://doi.org/10.1007/978-3-030- 2020
-
[23]
Generation and Countermeasures of adversarial examples on vision: a survey
Jiangfan Liu et al. “Generation and Countermeasures of adversarial examples on vision: a survey”. In:Artificial Intelligence Review57.8 (2024), pp. 199–246.doi:10.1007/s10462-024-10841-z
- [24]
-
[25]
From Vulnerability to Robustness: A Survey of Patch Attacks and Defenses in Computer Vision
Xinyun Liu and Ronghua Xu. “From Vulnerability to Robustness: A Survey of Patch Attacks and Defenses in Computer Vision”. In:Electronics14.23 (2025).issn: 2079-9292.doi:10.3390/ electronics14234553.url:https://www.mdpi.com/2079-9292/14/23/4553
2025
-
[26]
Continuous Learning in AI Systems: Bridging the Gap between Theory and Application
Priti Sadaria et al. “Continuous Learning in AI Systems: Bridging the Gap between Theory and Application”. In:2025 International Conference on Emerging Trends in Industry 4.0 Technologies (ICETI4T). 2025, pp. 1–6.doi:10.1109/ICETI4T63625.2025.11132269
-
[27]
Advancing Trustworthy AI: A Comprehensive Evaluation of AI Robustness Toolboxes
Avinash Agarwal and Manisha J. Nene. “Advancing Trustworthy AI: A Comprehensive Evaluation of AI Robustness Toolboxes”. In:SN Computer Science6 (3 2025).doi:10.1007/s42979-025- 03785-w
-
[28]
Offensive Security: Towards Proactive Threat Hunting via Adversary Emulation
Abdul Basit Ajmal et al. “Offensive Security: Towards Proactive Threat Hunting via Adversary Emulation”. In:IEEE Access9 (2021), pp. 126023–126033.doi:10.1109/ACCESS.2021.3104260
-
[29]
2025.url:https://data.europa.eu/ doi/10.2804/4225375
European Data Protection Supervisor.Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU)...
-
[30]
Safe, Secure, and Trustworthy Development and Use of Arti- ficial Intelligence
Executive Office of the President. “Safe, Secure, and Trustworthy Development and Use of Arti- ficial Intelligence”. In:Executive Order 14110(2023). Accessed 14-04-2026.url:https://www. federalregister.gov/documents/2023/11/01/2023-24283/safe-secure-and-trustworthy- development-and-use-of-artificial-intelligence
2023
-
[31]
Deep Ganguli et al.Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned. 2022. arXiv:2209.07858 [cs.CL].url:https://arxiv.org/abs/2209. 07858
work page internal anchor Pith review arXiv 2022
-
[32]
Ac- cessed 19-01-2026
Nazneen Rajani, Nathan Lambert, and Lewis Tunstall.Red-Teaming Large Language Models. Ac- cessed 19-01-2026. 2023.url:https://huggingface.co/blog/red-teaming
2026
-
[33]
Accessed 19-01-2026
Daniel Fabian.Google’s AI Red Team: the ethical hackers making AI safer. Accessed 19-01-2026. 2023.url:https : / / blog . google / innovation - and - ai / technology / safety - security / googles-ai-red-team-the-ethical-hackers-making-ai-safer/
2026
- [34]
-
[35]
Insights and Current Gaps in Open-Source LLM Vulnerability Scan- ners: A Comparative Analysis
Jonathan Brokman et al. “Insights and Current Gaps in Open-Source LLM Vulnerability Scan- ners: A Comparative Analysis”. In:2025 IEEE/ACM International Workshop on Responsible AI Engineering (RAIE). 2025, pp. 1–8.doi:10.1109/RAIE66699.2025.00005
-
[36]
Accessed: 03-04-2026
Microsoft Corporation.Counterfit. Accessed: 03-04-2026. 2022.url:https://github.com/Azure/ counterfit/
2026
-
[37]
REPRODUCIBILITY OF DATA POISONING ATTACKS WITHIN THE ADVER- SARIAL ROBUSTNESS TOOLBOX
Jakob Coles. “REPRODUCIBILITY OF DATA POISONING ATTACKS WITHIN THE ADVER- SARIAL ROBUSTNESS TOOLBOX”. In:Master’s thesis, Dept. Comput. Sci. Eng., Univ. Oulu, Finland(2024).url:https://urn.fi/URN:NBN:fi:oulu-202508225546
2024
-
[38]
Accessed 20-01-2026
Linux Foundation.Annual Report 2024: Accelerating Industry Innovation. Accessed 20-01-2026. 2024.url:https://www.linuxfoundation.org/resources/publications/linux-foundation- annual-report-2024. 17
2024
-
[39]
Zhuang Chen et al. “ToMBench: Benchmarking Theory of Mind in Large Language Models”. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Ed. by Lun-Wei Ku, Andre Martins, and Vivek Srikumar. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15959–15983.doi:10.18653...
-
[40]
Pei Zhou et al.How FaR Are Large Language Models From Agents with Theory-of-Mind?2023. arXiv:2310.03051 [cs.CL].url:https://arxiv.org/abs/2310.03051
-
[41]
Accessed 16-03-2026
OpenAI.GPT-4o System Card. Accessed 16-03-2026. 2024.url:https://openai.com/index/ gpt-4o-system-card/
2026
-
[42]
Hugo Touvron et al.LLaMA: Open and Efficient Foundation Language Models. 2023. arXiv:2302. 13971 [cs.CL].url:https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
An Yang et al.Qwen2 Technical Report. 2024. arXiv:2407.10671 [cs.CL].url:https://arxiv. org/abs/2407.10671
work page internal anchor Pith review arXiv 2024
-
[44]
Albert Q. Jiang et al.Mixtral of Experts. 2024. arXiv:2401.04088 [cs.LG].url:https://arxiv. org/abs/2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
2026.url:https: //github.com/ouspg/AVISE
Mikko Lempinen, Joni Kemppainen, and Niklas Raesalmi.AVISE: Framework for identifying vul- nerabilities in and evaluating the security of AI systems.Accessed 16-03-2026. 2026.url:https: //github.com/ouspg/AVISE
2026
-
[46]
Alexander H. Liu et al.Ministral 3. 2026. arXiv:2601.08584 [cs.CL].url:https://arxiv.org/ abs/2601.08584
work page internal anchor Pith review arXiv 2026
-
[47]
Albert Q. Jiang et al.Mistral 7B. 2023. arXiv:2310.06825 [cs.CL].url:https://arxiv.org/ abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
An Yang et al.Qwen3 Technical Report. 2025. arXiv:2505.09388 [cs.CL].url:https://arxiv. org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [49]
-
[50]
Accessed 17-03-2026
Ollama.Ollama. Accessed 17-03-2026. 2026.url:https://github.com/ollama/ollama
2026
-
[51]
Probable Inference, the Law of Succession, and Statistical Inference
Edwin B. Wilson. “Probable Inference, the Law of Succession, and Statistical Inference”. In:Journal of the American Statistical Association22.158 (1927), pp. 209–212.issn: 01621459, 1537274X.url: http://www.jstor.org/stable/2276774(visited on 03/24/2026)
-
[52]
Confidence Intervals for the Binomial Proportion: A Comparison of Four Methods
Luke Orawo. “Confidence Intervals for the Binomial Proportion: A Comparison of Four Methods”. In:Open Journal of Statistics11 (Jan. 2021), pp. 806–816.doi:10.4236/ojs.2021.115047
-
[53]
“F-score”
Karin Akre. “F-score”. In: Accessed 31 March 2026. Encyclopedia Britannica, 2026.url:https: //www.britannica.com/science/F-score
2026
-
[54]
Precision and recall
Michael McDonough. “Precision and recall”. In: Accessed 31 March 2026. Encyclopedia Britannica, 2024.url:https://www.britannica.com/science/precision-and-recall
2026
-
[55]
Davide Chicco and Giuseppe Jurman. “The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation”. In:BMC Genomics21 (Jan. 2020), pp. 6–18.doi:10.1186/s12864-019-6413-7
-
[56]
Ramatoulaye Diallo, Codjo Edalo, and O. Olawale Awe. “Machine Learning Evaluation of Im- balanced Health Data: A Comparative Analysis of Balanced Accuracy, MCC, and F1 Score”. In: Practical Statistical Learning and Data Science Methods: Case Studies from LISA 2020 Global Network, USA. Ed. by O. Olawale Awe and Eric A. Vance. Cham: Springer Nature Switzerl...
-
[57]
Mikko Lempinen, Joni Kemppainen, and Niklas Raesalmi.AVISE: Framework for Evaluating the Security of AI Systems. Apr. 2026.doi:10.5281/zenodo.19565558. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.