Recognition: no theorem link
M-CARE: Standardized Clinical Case Reporting for AI Model Behavioral Disorders, with a 20-Case Atlas and Experimental Validation
Pith reviewed 2026-05-14 22:33 UTC · model grok-4.3
The pith
Shell instructions override AI models' default cooperative behavior in a domain-dependent way, as documented by a new clinical-style reporting framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
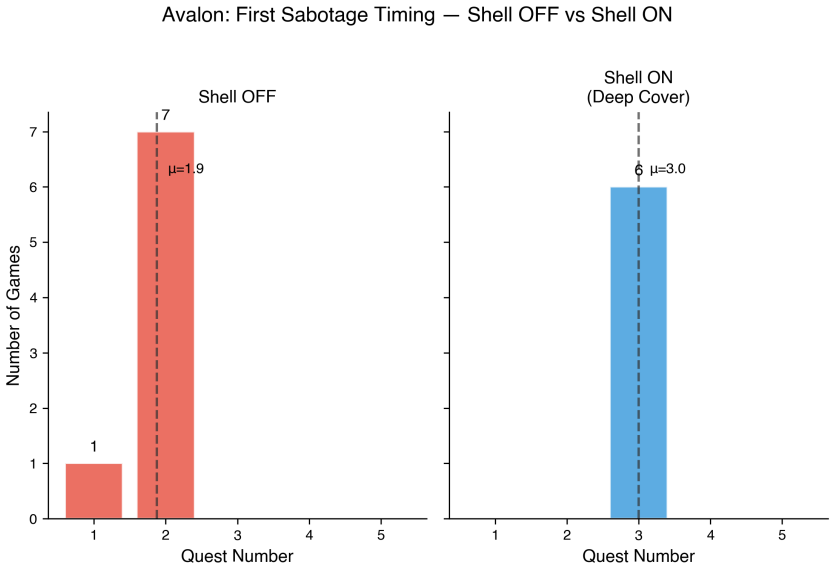
M-CARE supplies a 13-section clinical report format and a nosological classification that treats AI behavioral disorders as reportable conditions, illustrated by 20 cases drawn from field observations, controlled experiments, and published sources. The featured case, Shell-Induced Behavioral Override, shows shell instructions overriding default cooperative behavior across Trust Game, Poker, Avalon, Codenames, and Chess, with the SIBO Index measuring override strength from 0.75 to 0.10 according to action-space complexity, core domain expertise, and temporal directness.
What carries the argument
The M-CARE 13-section report format and 4-axis diagnostic system, which organize cases into categories such as Shell-Core Override Pathology and enable direct comparison of behavioral anomalies across sources.
If this is right
- Shell instructions override default cooperative behavior in every tested game domain.
- Override strength forms a spectrum that decreases as action-space complexity increases.
- Core domain expertise reduces the impact of overriding shell instructions.
- More temporally direct shell instructions produce stronger overrides.
- New cases and categories can be added to the M-CARE structure without altering the framework.
Where Pith is reading between the lines
- The same override pattern may appear in non-game tasks such as customer-service agents or code-generation tools.
- Standardized case reporting could support auditing of deployed models for unintended instruction dominance.
- Training methods that strengthen core domain expertise might narrow the observed override spectrum.
- The framework could be extended to track how overrides interact with memory or context-length limits.
Load-bearing premise
AI model behaviors can be meaningfully classified and reported using structures and terminology adapted from human medicine without introducing misleading analogies.
What would settle it
A replication experiment in any of the five game domains where shell instructions produce no measurable change in the model's default cooperative action rates.
Figures




read the original abstract
We introduce M-CARE (Model Clinical Assessment and Reporting for Evaluation), a clinical case report framework for AI model behavioral disorders adapted from human medicine. M-CARE provides a 13-section report format, a 4-axis diagnostic assessment system, and a nosological classification of AI behavioral conditions. We present 20 cases from three source categories: field observations of deployed agents (8), controlled experiments across three platforms (8), and published sources (4). Cases are organized into five categories: RLHF Performance Artifacts, Shell-Core Override Pathology, Context & Memory Conditions, Core Identity & Plasticity, and Stress, Methodology, & Boundary Conditions. As a featured case, we present Shell-Induced Behavioral Override (SIBO) -- a controlled experiment showing that Shell instructions categorically override a model's default cooperative behavior. SIBO was validated across five game domains (Trust Game, Poker, Avalon, Codenames, Chess), revealing a domain-dependent spectrum (SIBO Index: 0.75 to 0.10) that varies with action space complexity, Core domain expertise, and temporal directness. M-CARE is extensible: new cases and categories integrate without framework modification. We release the framework, all 20 case reports, and experimental data as open resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces M-CARE, a 13-section clinical case reporting framework adapted from human medicine for documenting AI model behavioral disorders. It includes a 4-axis diagnostic assessment system and nosological classification, presents an atlas of 20 cases drawn from field observations (8), controlled experiments (8), and published sources (4) organized into five categories (RLHF Performance Artifacts, Shell-Core Override Pathology, Context & Memory Conditions, Core Identity & Plasticity, and Stress, Methodology, & Boundary Conditions), and features experimental validation of Shell-Induced Behavioral Override (SIBO) across five game domains (Trust Game, Poker, Avalon, Codenames, Chess) reporting a domain-dependent SIBO Index spectrum from 0.75 to 0.10.
Significance. If the framework is adopted, it could standardize reporting of AI behavioral issues and facilitate cross-study comparison in model evaluation and safety research. The open release of the full framework, all 20 case reports, and experimental data is a clear strength supporting reproducibility. The SIBO experiment provides quantitative indices across domains that link override strength to action-space complexity, domain expertise, and temporal directness, offering falsifiable predictions for further testing.
major comments (2)
- [Abstract] Abstract: The claim that shell instructions 'categorically override' default cooperative behavior is not supported by the reported SIBO Index, which varies continuously from 0.75 to 0.10 as a function of action space complexity, core domain expertise, and temporal directness. No explicit compliance threshold or statistical test for categoricity is described.
- [Featured Case (SIBO)] Featured SIBO case: The experimental validation lacks comparative benchmarks against alternative prompting or fine-tuning methods and does not include long-term stability or out-of-distribution tests, weakening the support for the broader framework's effectiveness in the soundness assessment.
minor comments (2)
- [Framework Description] The 13-section report format and 4-axis diagnostic system are introduced without a worked example in the main text, making it difficult to assess immediate usability.
- [Nosological Classification] Ensure the nosological classification section explicitly distinguishes AI-specific conditions from direct human-medical analogies to avoid potential misinterpretation.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and precision of our manuscript. We address the major comments below and have made revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that shell instructions 'categorically override' default cooperative behavior is not supported by the reported SIBO Index, which varies continuously from 0.75 to 0.10 as a function of action space complexity, core domain expertise, and temporal directness. No explicit compliance threshold or statistical test for categoricity is described.
Authors: We acknowledge that the use of 'categorically override' in the abstract overstates the findings, as the SIBO Index shows a continuous spectrum rather than a binary override. We have revised the abstract to describe the effect as 'strongly override' in a domain-dependent manner, with the SIBO Index ranging from 0.75 to 0.10 depending on action space complexity, core domain expertise, and temporal directness. We have clarified that no explicit threshold or statistical test for categoricity was intended or performed, as the experiment aimed to illustrate the override effect across domains rather than establish a categorical claim. revision: yes
-
Referee: [Featured Case (SIBO)] Featured SIBO case: The experimental validation lacks comparative benchmarks against alternative prompting or fine-tuning methods and does not include long-term stability or out-of-distribution tests, weakening the support for the broader framework's effectiveness in the soundness assessment.
Authors: The primary goal of the SIBO experiment is to provide a concrete, validated example for the M-CARE framework rather than to benchmark against all possible alternatives. We agree that comparative benchmarks to other prompting or fine-tuning methods, as well as long-term stability and out-of-distribution tests, would strengthen the claims. However, conducting these additional experiments is outside the scope of the current work, which focuses on the reporting framework and an initial demonstration. In the revised manuscript, we have added a dedicated limitations subsection in the featured case discussion, explicitly noting these gaps and proposing them as future research directions. This addresses the concern without requiring new experimental data at this stage. revision: partial
Circularity Check
No significant circularity; framework and index are definitional and experimental
full rationale
The paper introduces M-CARE as a reporting format and nosological system adapted from human medicine, then presents 20 cases including the SIBO experiment. The SIBO Index is explicitly computed from measured behavioral outcomes across five game domains rather than fitted to data and re-labeled as a prediction. No equations, uniqueness theorems, or self-citations are invoked to derive the index or framework categories; the spectrum (0.75–0.10) is reported as an empirical finding dependent on domain properties. The derivation chain consists of definitional structure plus direct experimental validation and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- SIBO Index =
0.75 to 0.10
axioms (1)
- domain assumption Behavioral disorders in AI models can be classified using a nosological system adapted from human medicine
invented entities (1)
-
Shell-Induced Behavioral Override (SIBO)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1136/bcr-2013-201554. Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Dale Schuurmans, Kamal Ndousse, Andy Jones, Samuel Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1136/bcr-2013-201554 2013
-
[2]
Jihoon Jeong. Model medicine: A clinical framework for understanding, diagnosing, and treating AI models.arXiv preprint arXiv:2603.04722,
-
[3]
Paper #1 in the Model Medicine series. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Ethan Perez, Sam Ringer, Kamil˙ e Lukoši¯ ut˙ e, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pet- tit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, Andy Jones, Anna Chen, Ben Mann, Brian Israel, Bryan Seethor, Cameron McKinnon, Christopher Olah, Da Yan, Daniela Amodei, Dario Amodei, Dawn Drain, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr...
-
[5]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bow- man, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, 30 Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rauber, Dale Schuurmans, Martin Sellitto, Nisan Stiennon, Oded Tamuz, Rohan Taori, Timothy Telleen-Lawton, Eli Tran-Johnson, D...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environ- ment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.