Recognition: unknown
Navigating the Clutter: Waypoint-Based Bi-Level Planning for Multi-Robot Systems
Pith reviewed 2026-05-09 23:24 UTC · model grok-4.3
The pith
Waypoints as a compact motion representation let multi-robot planners jointly optimize task assignments and collision-free paths in cluttered spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce waypoints as a simple yet expressive way to parameterize motion trajectories and pair them with a curriculum-trained modified RLVR algorithm that passes motion feasibility signals back to the high-level task planner, thereby enabling joint optimization over robot-robot collisions, robot-obstacle collisions, and unreachable motions; experiments on the BoxNet3D-OBS benchmark with up to nine robots and dense obstacles confirm higher success than motion-agnostic and VLA baselines.
What carries the argument
Waypoints, a compact parameterization of motion trajectories, together with curriculum-based RLVR that propagates feasibility feedback from the motion planner to the task planner.
If this is right
- Joint optimization reduces the frequency of physical constraint violations that separate planners produce.
- The approach scales to teams of at least nine robots operating among dense obstacles.
- Motion feasibility signals improve high-level task decisions that would otherwise ignore low-level reachability.
- Curriculum training gradually increases the difficulty of feasible motion examples the task planner must handle.
Where Pith is reading between the lines
- The same waypoint abstraction could be tested in other hierarchical planning settings such as drone swarms or automated warehouses with moving obstacles.
- If waypoint expressiveness holds, the method offers a lighter alternative to full trajectory optimization inside multi-agent reinforcement learning loops.
- Real-robot deployment would expose whether the simulation-derived feasibility signals transfer under sensor noise and actuation error.
Load-bearing premise
Waypoints remain expressive enough to represent every motion the robots must execute, and the RLVR feedback loop assigns credit correctly without introducing biases or credit-assignment errors.
What would settle it
A new multi-robot benchmark containing motions that cannot be captured by straight-line or simple waypoint sequences, on which the method's success rate falls below that of the motion-agnostic baseline.
Figures


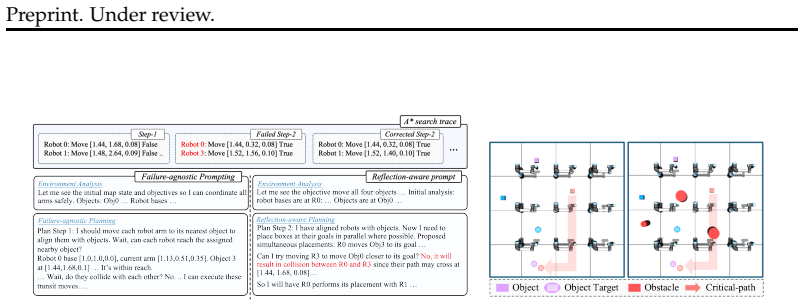
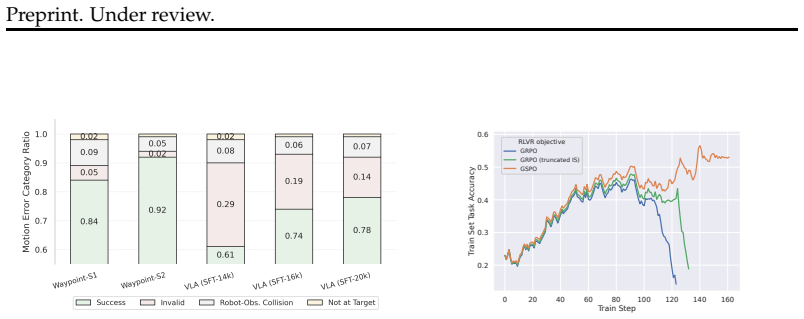
read the original abstract
Multi-robot control in cluttered environments is a challenging problem that involves complex physical constraints, including robot-robot collisions, robot-obstacle collisions, and unreachable motions. Successful planning in such settings requires joint optimization over high-level task planning and low-level motion planning, as violations of physical constraints may arise from failures at either level. However, jointly optimizing task and motion planning is difficult due to the complex parameterization of low-level motion trajectories and the ambiguity of credit assignment across the two planning levels. In this paper, we propose a hybrid multi-robot control framework that jointly optimizes task and motion planning. To enable effective parameterization of low-level planning, we introduce waypoints, a simple yet expressive representation for motion trajectories. To address the credit assignment challenge, we adopt a curriculum-based training strategy with a modified RLVR algorithm that propagates motion feasibility feedback from the motion planner to the task planner. Experiments on BoxNet3D-OBS, a challenging multi-robot benchmark with dense obstacles and up to nine robots, show that our approach consistently improves task success over motion-agnostic and VLA-based baselines. Our code is available at https://github.com/UCSB-NLP-Chang/navigate-cluster
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present a hybrid multi-robot control framework for cluttered environments that jointly optimizes task and motion planning. It introduces a waypoint representation for low-level motion trajectories and employs a curriculum-based modified RLVR algorithm to propagate feasibility feedback and address credit assignment issues. Experiments on the BoxNet3D-OBS benchmark demonstrate consistent improvements in task success over motion-agnostic and VLA-based baselines.
Significance. Should the empirical results prove robust upon detailed examination, the framework offers a promising direction for handling complex physical constraints in multi-robot systems by simplifying motion parameterization and improving feedback between planning levels. The public release of the code enhances the potential impact through reproducibility and extension by the community.
major comments (3)
- Abstract: the claim of consistent improvements on BoxNet3D-OBS is made without any numerical results, error bars, statistical tests, ablation details, or discussion of failure modes, leaving the central empirical claim unsupported by visible evidence.
- Method (waypoint representation): the assumption that the waypoint parameterization remains sufficiently expressive to represent all feasible collision-free motions satisfying robot-robot and robot-obstacle constraints is not verified through ablations or analysis in dense 9-robot settings, which is load-bearing for attributing reported gains to the bi-level optimization.
- Method (RLVR): the curriculum-based modified RLVR is presented as reliably propagating motion feasibility feedback without credit-assignment errors or optimization biases, yet no explicit tests, ablations, or analysis confirm this in the BoxNet3D-OBS environment with up to nine robots.
minor comments (2)
- Abstract: consider including at least one quantitative metric or pointer to a results table/figure to make the performance claim more informative.
- Ensure all acronyms (e.g., VLA, RLVR) are defined at first use in the introduction and abstract.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications from the manuscript and proposed revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: Abstract: the claim of consistent improvements on BoxNet3D-OBS is made without any numerical results, error bars, statistical tests, ablation details, or discussion of failure modes, leaving the central empirical claim unsupported by visible evidence.
Authors: The abstract provides a concise summary of the approach and high-level findings, with detailed quantitative results (including success rates, baseline comparisons, and some failure mode analysis) presented in Section 5 and the associated figures/tables. We agree that including key numerical highlights would better support the claim in the abstract itself. In the revision, we will add specific success rate improvements (e.g., relative gains over baselines), note the use of multiple random seeds for robustness, and briefly reference failure modes discussed in the experiments section. revision: yes
-
Referee: Method (waypoint representation): the assumption that the waypoint parameterization remains sufficiently expressive to represent all feasible collision-free motions satisfying robot-robot and robot-obstacle constraints is not verified through ablations or analysis in dense 9-robot settings, which is load-bearing for attributing reported gains to the bi-level optimization.
Authors: The waypoint representation is motivated as a compact yet flexible parameterization that allows the low-level planner to optimize trajectories while enforcing constraints via the feasibility feedback loop. Performance gains in the 9-robot dense-obstacle cases are shown through end-to-end comparisons in Section 5. However, we acknowledge the value of explicit verification of expressiveness. We will add an ablation in the revised manuscript that compares waypoint-based trajectories against direct trajectory optimization baselines in high-density 9-robot scenarios, including analysis of constraint satisfaction rates. revision: yes
-
Referee: Method (RLVR): the curriculum-based modified RLVR is presented as reliably propagating motion feasibility feedback without credit-assignment errors or optimization biases, yet no explicit tests, ablations, or analysis confirm this in the BoxNet3D-OBS environment with up to nine robots.
Authors: The curriculum strategy and modified RLVR are designed to mitigate credit assignment by propagating feasibility signals from the motion level, with overall improvements over motion-agnostic baselines serving as indirect evidence. We agree that direct tests would strengthen this. In revision, we will include ablations comparing curriculum vs. non-curriculum RLVR variants on BoxNet3D-OBS (up to 9 robots), along with analysis of reward propagation and optimization stability to address potential biases. revision: yes
Circularity Check
No significant circularity in empirical bi-level multi-robot planning
full rationale
The paper presents an empirical hybrid framework using waypoint parameterization for low-level motions and a curriculum-modified RLVR for credit assignment, with central claims resting on experimental success rates versus external baselines on the public BoxNet3D-OBS benchmark. No derivation chain, equations, or self-citations reduce results to inputs by construction; the approach is framed as a practical method whose assumptions (waypoint expressiveness, unbiased feedback propagation) are tested rather than presupposed. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Waypoints are expressive enough to represent feasible motions under robot-robot and robot-obstacle collision constraints
- domain assumption Curriculum training with motion feasibility feedback can be propagated effectively from motion planner to task planner
invented entities (1)
-
waypoint representation for motion trajectories
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Autotamp: Autoregressive task and motion planning with llms as translators and checkers
Yongchao Chen, Jacob Arkin, Charles Dawson, Yang Zhang, Nicholas Roy, and Chuchu Fan. Autotamp: Autoregressive task and motion planning with llms as translators and checkers. In 2024 IEEE International conference on robotics and automation (ICRA), pp.\ 6695--6702. IEEE, 2024 a
2024
-
[3]
Yongchao Chen, Jacob Arkin, Yang Zhang, Nicholas Roy, and Chuchu Fan. Scalable multi-robot collaboration with large language models: Centralized or decentralized systems? In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 4311--4317. IEEE, 2024 b
2024
-
[4]
Code-as-symbolic-planner: Foundation model-based robot planning via symbolic code generation
Yongchao Chen, Yilun Hao, Yang Zhang, and Chuchu Fan. Code-as-symbolic-planner: Foundation model-based robot planning via symbolic code generation. arXiv preprint arXiv: 2503.01700, 2025
-
[6]
Temporal and modal logic
E Allen Emerson. Temporal and modal logic. In Formal models and semantics, pp.\ 995--1072. Elsevier, 1990
1990
-
[7]
Maria Fox and Derek Long. Pddl2. 1: An extension to pddl for expressing temporal planning domains. Journal of artificial intelligence research, 20: 0 61--124, 2003
2003
-
[8]
Leveraging pre-trained large language models to construct and utilize world models for model-based task planning
Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning. Advances in Neural Information Processing Systems, 36: 0 79081--79094, 2023
2023
-
[11]
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning. 2025. URL https://openreview.net/forum?id=gahaeltsNo
2025
-
[12]
Dongchi Huang, Zhirui Fang, Tianle Zhang, Yihang Li, Lin Zhao, and Chunhe Xia. Co-rft: Efficient fine-tuning of vision-language-action models through chunked offline reinforcement learning, 2025. URL https://arxiv.org/abs/2508.02219
-
[16]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv: 2503.09516, 2025
work page internal anchor Pith review arXiv 2025
-
[18]
Hengtao Li, Pengxiang Ding, Runze Suo, Yihao Wang, Zirui Ge, Dongyuan Zang, Kexian Yu, Mingyang Sun, Hongyin Zhang, Donglin Wang, and Weihua Su. Vla-rft: Vision-language-action reinforcement fine-tuning with verified rewards in world simulators, 2025. URL https://arxiv.org/abs/2510.00406
-
[19]
Text2motion: From natural language instructions to feasible plans,
Kevin Lin, Christopher Agia, Toki Migimatsu, Marco Pavone, and Jeannette Bohg. Text2motion: From natural language instructions to feasible plans. arXiv preprint arXiv: 2303.12153, 2023
-
[20]
Code-r1: Reproducing r1 for code with reliable rewards
Jiawei Liu and Lingming Zhang. Code-r1: Reproducing r1 for code with reliable rewards. 2025
2025
-
[22]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. International Conference on Learning Representations, 2017
2017
-
[23]
Lew, Tim Vieira, and Timothy J
Jo \ a o Loula, Benjamin LeBrun, Li Du, Ben Lipkin, Clemente Pasti, Gabriel Grand, Tianyu Liu, Yahya Emara, Marjorie Freedman, Jason Eisner, Ryan Cotterell, Vikash Mansinghka, Alexander K. Lew, Tim Vieira, and Timothy J. O'Donnell. Syntactic and semantic control of large language models via sequential monte carlo. In The Thirteenth International Conferenc...
2025
-
[24]
Deepcoder: A fully open-source 14b coder at o3-mini level
Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Alpay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, Maurice Weber, Ce Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepcoder: A fully open-source 14b coder at o3-mini level
-
[25]
Reinforcement fine-tuning of flow-matching policies for vision-language-action models, 2025
Mingyang Lyu, Yinqian Sun, Erliang Lin, Huangrui Li, Ruolin Chen, Feifei Zhao, and Yi Zeng. Reinforcement fine-tuning of flow-matching policies for vision-language-action models, 2025. URL https://arxiv.org/abs/2510.09976
-
[26]
Audere: Automated strategy decision and realization in robot planning and control via llms
Yue Meng, Fei Chen, Yongchao Chen, and Chuchu Fan. Audere: Automated strategy decision and realization in robot planning and control via llms. arXiv preprint arXiv: 2504.03015, 2025
-
[29]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv: 2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review arXiv 2024
-
[32]
Llmˆ 3: Large language model-based task and motion planning with motion failure reasoning
Shu Wang, Muzhi Han, Ziyuan Jiao, Zeyu Zhang, Ying Nian Wu, Song-Chun Zhu, and Hangxin Liu. Llmˆ 3: Large language model-based task and motion planning with motion failure reasoning. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.\ 12086--12092. IEEE, 2024
2024
-
[35]
Llm-grop: Visually grounded robot task and motion planning with large language models
Xiaohan Zhang, Yan Ding, Yohei Hayamizu, Zainab Altaweel, Yifeng Zhu, Yuke Zhu, Peter Stone, Chris Paxton, and Shiqi Zhang. Llm-grop: Visually grounded robot task and motion planning with large language models. The International Journal of Robotics Research, pp.\ 02783649251378196, 2025
2025
-
[37]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[38]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[39]
Publications Manual , year = "1983", publisher =
1983
-
[40]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[41]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[42]
Dan Gusfield , title =. 1997
1997
-
[43]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[44]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[45]
Conference on Robot Learning (CoRL) , year=
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author=. Conference on Robot Learning (CoRL) , year=
-
[46]
Conference on Robot Learning (CoRL) , year=
Inner Monologue: Embodied Reasoning through Planning with Language Models , author=. Conference on Robot Learning (CoRL) , year=
-
[48]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. arXiv preprint arXiv:2307.15818 , year=
work page internal anchor Pith review arXiv
-
[49]
Reft: Reasoning with reinforced fine-tuning, 2024
ReFT: Reasoning with Reinforced Fine-Tuning , author=. arXiv preprint arXiv:2401.08967 , year=
-
[50]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
2025 , url =
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning , author =. 2025 , url =
2025
-
[52]
2025 , journal =
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training , author =. 2025 , journal =
2025
-
[53]
2025 , journal =
What Makes a Reward Model a Good Teacher? An Optimization Perspective , author =. 2025 , journal =
2025
-
[54]
2025 , journal =
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author =. 2025 , journal =
2025
-
[55]
Neural Information Processing Systems , year =
AGILE: A Novel Reinforcement Learning Framework of LLM Agents , author =. Neural Information Processing Systems , year =
-
[56]
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2505.01441 , year=
-
[57]
2025 , journal =
DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition , author =. 2025 , journal =
2025
-
[58]
2025 , journal =
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild , author =. 2025 , journal =
2025
-
[59]
2024 , journal =
OpenAI o1 System Card , author =. 2024 , journal =
2024
-
[60]
DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level , author=
-
[61]
Code-R1: Reproducing R1 for Code with Reliable Rewards , author=
-
[62]
2025 , journal =
Competitive Programming with Large Reasoning Models , author =. 2025 , journal =
2025
-
[63]
Introducing Operator , year = 2024, url =
2024
-
[64]
Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning , author=. arXiv preprint arXiv:2502.19634 , year=
-
[65]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Vlm-r1: A stable and generalizable r1-style large vision-language model , author=. arXiv preprint arXiv:2504.07615 , year=
work page internal anchor Pith review arXiv
-
[66]
Video-R1: Reinforcing Video Reasoning in MLLMs
Video-r1: Reinforcing video reasoning in mllms , author=. arXiv preprint arXiv:2503.21776 , year=
work page internal anchor Pith review arXiv
-
[67]
2024 , journal =
Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping , author =. 2024 , journal =
2024
-
[68]
The Thirteenth International Conference on Learning Representations , year=
Dualformer: Controllable fast and slow thinking by learning with randomized reasoning traces , author=. The Thirteenth International Conference on Learning Representations , year=
-
[69]
2025 , journal =
AuDeRe: Automated Strategy Decision and Realization in Robot Planning and Control via LLMs , author =. 2025 , journal =
2025
-
[70]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Scalable multi-robot collaboration with large language models: Centralized or decentralized systems? , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[71]
2024 IEEE International conference on robotics and automation (ICRA) , pages=
Autotamp: Autoregressive task and motion planning with llms as translators and checkers , author=. 2024 IEEE International conference on robotics and automation (ICRA) , pages=. 2024 , organization=
2024
-
[72]
2025 , journal =
Code-as-Symbolic-Planner: Foundation Model-Based Robot Planning via Symbolic Code Generation , author =. 2025 , journal =
2025
-
[73]
2023 , eprint=
RoCo: Dialectic Multi-Robot Collaboration with Large Language Models , author=. 2023 , eprint=
2023
-
[74]
IEEE Robotics and Automation Letters , volume=
Multi-agent motion planning from signal temporal logic specifications , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
2022
-
[75]
2024 , journal =
GCBF+: A Neural Graph Control Barrier Function Framework for Distributed Safe Multi-Agent Control , author =. 2024 , journal =
2024
-
[76]
Efficient Motion Planning for Manipulators with Control Barrier Function-Induced Neural Controller , author =. IEEE International Conference on Robotics and Automation , year =. doi:10.1109/ICRA57147.2024.10610785 , bibSource =
-
[77]
1: An extension to PDDL for expressing temporal planning domains , author=
PDDL2. 1: An extension to PDDL for expressing temporal planning domains , author=. Journal of artificial intelligence research , volume=
-
[78]
Formal models and semantics , pages=
Temporal and modal logic , author=. Formal models and semantics , pages=. 1990 , publisher=
1990
-
[79]
2024 , journal =
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2024 , journal =
2024
-
[80]
2025 , journal =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , journal =
2025
-
[81]
2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
MuJoCo: A physics engine for model-based control , author=. 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2012 , organization=
2012
-
[82]
First Conference on Language Modeling , year=
Quiet-star: Language models can teach themselves to think before speaking , author=. First Conference on Language Modeling , year=
-
[83]
V-STaR: Training verifiers for self-taught reasoners.arXiv preprint arXiv:2402.06457,
V-star: Training verifiers for self-taught reasoners , author=. arXiv preprint arXiv:2402.06457 , year=
-
[84]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[85]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[86]
Advances in Neural Information Processing Systems , volume=
Leveraging pre-trained large language models to construct and utilize world models for model-based task planning , author=. Advances in Neural Information Processing Systems , volume=
-
[87]
Errors are useful prompts: Instruction guided task programming with verifier-assisted iterative prompting , author=. arXiv preprint arXiv:2303.14100 , year=
-
[88]
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo , booktitle =
Jo. Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo , booktitle =. 2025 , url =
2025
-
[89]
Conference on Robot Learning , year =
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author =. Conference on Robot Learning , year =
-
[90]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Inner monologue: Embodied reasoning through planning with language models , author=. arXiv preprint arXiv:2207.05608 , year=
work page internal anchor Pith review arXiv
-
[91]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Code as policies: Language model programs for embodied control , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[92]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Progprompt: Generating situated robot task plans using large language models , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[93]
2023 , journal =
Text2Motion: From Natural Language Instructions to Feasible Plans , author =. 2023 , journal =
2023
-
[94]
arXiv preprint arXiv:2405.14314 , year=
Towards efficient llm grounding for embodied multi-agent collaboration , author=. arXiv preprint arXiv:2405.14314 , year=
-
[95]
arXiv preprint arXiv:2403.12482 , year=
Embodied llm agents learn to cooperate in organized teams , author=. arXiv preprint arXiv:2403.12482 , year=
-
[96]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Enhancing Multi-Robot Semantic Navigation Through Multimodal Chain-of-Thought Score Collaboration , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.