Recognition: unknown
Scale-Parameter Selection in Gaussian Kolmogorov-Arnold Networks
Pith reviewed 2026-05-08 13:37 UTC · model grok-4.3
The pith
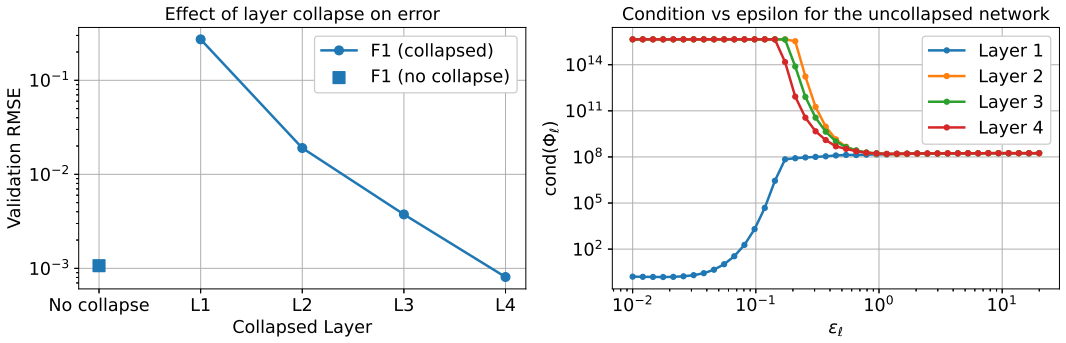
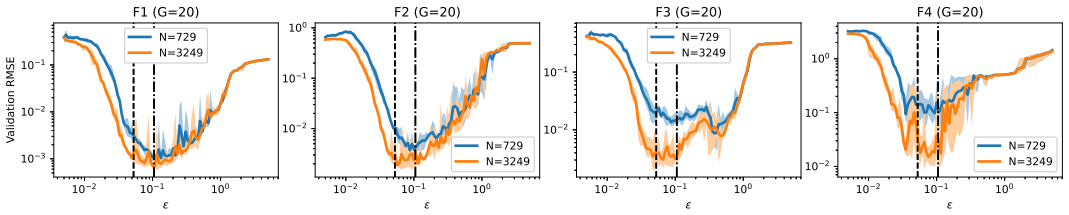
The scale for Gaussian basis functions in KANs is set by the first layer alone, with a reliable interval of 1/(G-1) to 2/(G-1).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Scale selection is governed primarily by the first layer, since it is the only layer constructed directly on the input domain and any loss of distinguishability introduced there cannot be recovered by later layers. Analysis of the first-layer feature matrix yields the operating interval ε ∈ [1/(G-1), 2/(G-1)], which is shown to be stable and effective through brute-force validation on function-approximation and physics-informed problems under varying conditions.
What carries the argument
The first-layer feature matrix formed by Gaussian basis functions placed on the input domain, whose conditioning and distinguishability determine downstream performance.
If this is right
- Fixed-scale Gaussian KANs can be initialized reliably without exhaustive hyperparameter search.
- Variable-scale constructions gain a stable starting interval for the first layer.
- Constrained optimization of ε can be restricted to the identified range during training.
- Early training MSE on a small batch can be used to confirm or refine the scale before full runs.
Where Pith is reading between the lines
- The same first-layer logic may apply to other localized basis functions that replace splines in KANs.
- In problems with very high input dimension the interval could reduce the number of centers needed to maintain separation.
- The rule offers a way to initialize deeper or wider KANs before any data-driven adaptation of scales.
Load-bearing premise
That poor distinguishability created by the scale choice in the first layer cannot be fixed by any adjustment in later layers.
What would settle it
A controlled trial in which a network initialized with ε outside the proposed interval recovers full accuracy after training only the weights and functions in layers two and beyond, or a sweep in which the interval produces poor results for a new collocation density or input dimension.
Figures
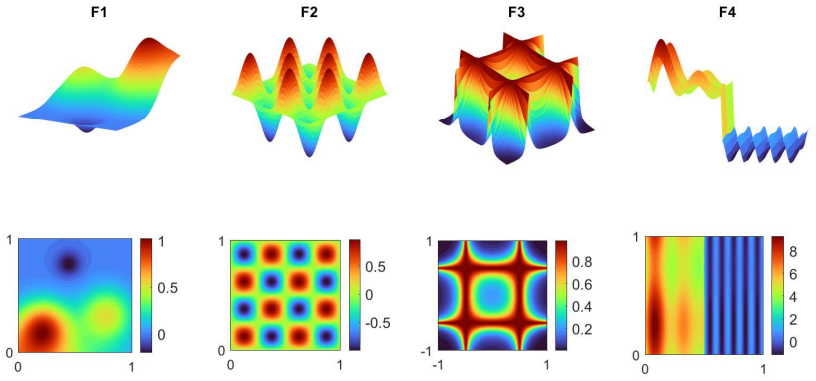



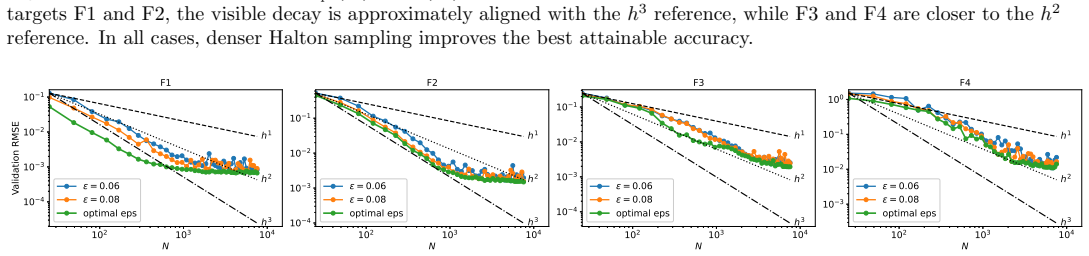
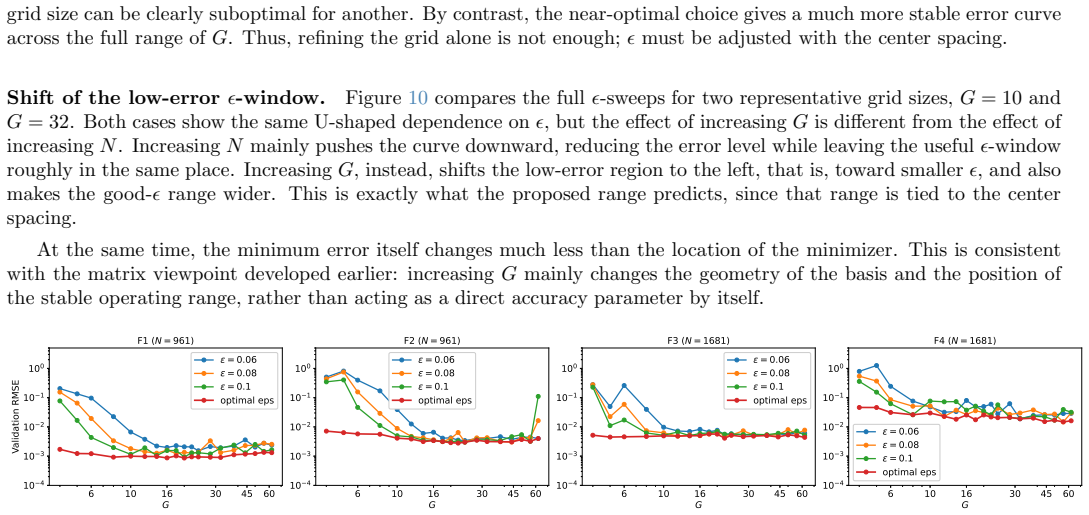
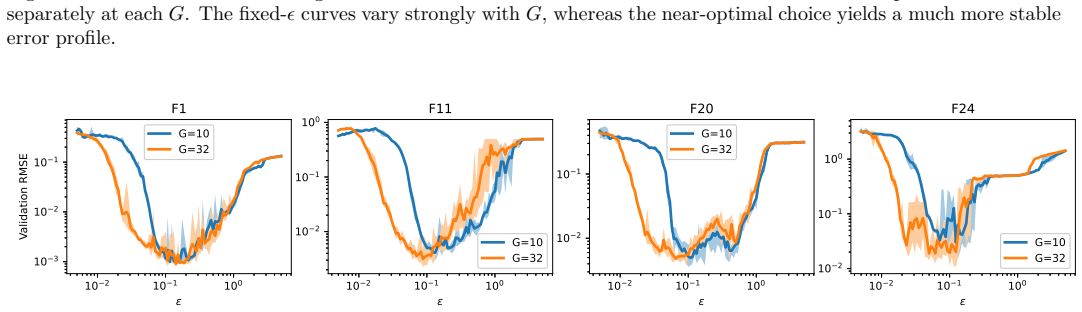





read the original abstract
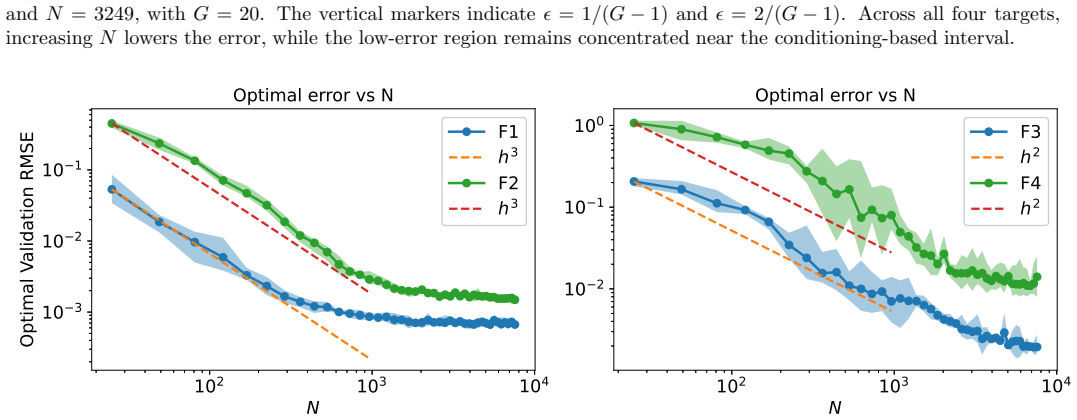
Kolmogorov--Arnold Networks (KANs) have recently attracted attention as edge-based neural architectures in which learnable univariate functions replace conventional fixed activation functions. A key source of flexibility in KANs is the choice of basis functions used to parameterize the learnable edge functions. In this context, Gaussian basis functions provide a simple and efficient alternative to splines. However, their performance depends strongly on the scale (shape) parameter \(\epsilon\), whose role has not been studied systematically. In this paper, we investigate how \(\epsilon\) affects Gaussian KANs through first-layer feature geometry, conditioning, and approximation behavior. Our central observation is that scale selection is governed primarily by the first layer, since it is the only layer constructed directly on the input domain and any loss of distinguishability introduced there cannot be recovered by later layers. From this viewpoint, we analyze the first-layer feature matrix and identify a practical operating interval, \[ \epsilon \in \left[\frac{1}{G-1},\frac{2}{G-1}\right], \] where \(G\) denotes the number of Gaussian centers. We interpret this interval not as a universal optimality result, but as a stable and effective design rule, and validate it through brute-force sweeps over \(\epsilon\) across function-approximation problems with different collocation densities, grid resolutions, network architectures, and input dimensions, as well as physics-informed problems. We further show that this range is useful for fixed-scale selection, variable-scale constructions, constrained training of \(\epsilon\), and efficient scale search using early training MSE. In this way, the paper positions scale selection as a practical design principle for Gaussian KANs rather than as an ad hoc hyperparameter choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the scale parameter ε in Gaussian Kolmogorov-Arnold Networks. It argues via first-layer feature-matrix geometry that scale selection is governed primarily by the first layer, as distinguishability losses there cannot be recovered downstream, and proposes the practical interval ε ∈ [1/(G-1), 2/(G-1)] (G = number of Gaussian centers). This interval is positioned as a stable design rule rather than a universal optimum and is validated through brute-force empirical sweeps over function-approximation and physics-informed problems that vary collocation density, grid resolution, network depth/width, and input dimension. Additional uses for fixed-scale selection, variable-scale constructions, constrained ε training, and early-training MSE-based search are demonstrated.
Significance. If the first-layer governance claim and the proposed interval hold under further scrutiny, the work supplies a concrete, low-cost heuristic that reduces hyperparameter search cost for Gaussian KANs and improves reproducibility across applications. The breadth of the empirical sweeps (multiple problem classes and architectural variations) is a clear strength that supports practical utility.
major comments (2)
- [Abstract and first-layer feature geometry analysis] Abstract and first-layer feature geometry analysis: the load-bearing claim that 'any loss of distinguishability introduced there cannot be recovered by later layers' is not directly tested. Because every edge carries an independent learnable univariate function, later layers could in principle remap or expand distinctions that appear collapsed in the first-layer basis alone. An ablation that fixes the first layer outside [1/(G-1), 2/(G-1)] while allowing later layers either a different fixed ε, a variable-scale construction, or the constrained training procedure would be required to substantiate irrecoverability.
- [Empirical validation sweeps] Empirical validation sweeps: the abstract states that the interval is validated across diverse settings, yet no quantitative performance tables, mean errors, standard deviations, or explicit comparisons of ε inside versus outside the interval are referenced. Without these metrics (or at least representative figures with error bars), it is difficult to assess how sharply performance degrades outside the interval or how stable the interval remains under changes in collocation density and grid resolution.
minor comments (2)
- The symbol G (number of Gaussian centers) is introduced only in the interval expression; an explicit definition and a brief reminder of its relation to the basis construction should appear at first use.
- [Abstract] The description of the 'brute-force sweeps' would benefit from a short statement of the tested ε range, step size, and number of trials per configuration to allow readers to gauge coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment below, explaining our response and the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and first-layer feature geometry analysis] Abstract and first-layer feature geometry analysis: the load-bearing claim that 'any loss of distinguishability introduced there cannot be recovered by later layers' is not directly tested. Because every edge carries an independent learnable univariate function, later layers could in principle remap or expand distinctions that appear collapsed in the first-layer basis alone. An ablation that fixes the first layer outside [1/(G-1), 2/(G-1)] while allowing later layers either a different fixed ε, a variable-scale construction, or the constrained training procedure would be required to substantiate irrecoverability.
Authors: We acknowledge that the geometric argument in the manuscript, while based on the fact that the first layer is the only one directly constructed on the input domain, does not include a direct empirical test of irrecoverability. The referee's suggestion for an ablation study is well-taken. In the revised version, we will add an ablation experiment that fixes the first-layer scale parameter outside the proposed interval and allows subsequent layers to use flexible scale choices (including variable-scale and constrained training). This will provide direct evidence on whether later layers can recover from first-layer distinguishability losses. revision: yes
-
Referee: [Empirical validation sweeps] Empirical validation sweeps: the abstract states that the interval is validated across diverse settings, yet no quantitative performance tables, mean errors, standard deviations, or explicit comparisons of ε inside versus outside the interval are referenced. Without these metrics (or at least representative figures with error bars), it is difficult to assess how sharply performance degrades outside the interval or how stable the interval remains under changes in collocation density and grid resolution.
Authors: We agree that the presentation of the empirical results can be strengthened with quantitative summaries. Although the manuscript includes brute-force sweep results visualized in figures, we will revise the manuscript to include tables reporting mean approximation errors, standard deviations across multiple runs, and explicit comparisons between ε values inside and outside the interval for representative cases varying collocation density, grid resolution, network depth, and input dimension. Where appropriate, we will also add error bars to the figures. revision: yes
Circularity Check
No significant circularity; derivation self-contained via geometric analysis
full rationale
The paper derives the ε interval from an explicit geometric analysis of the first-layer feature matrix, presented as an independent observation based on the architecture (first layer directly on input domain) rather than from any fitted loss values, self-referential definitions, or prior self-citations. The sweeps are explicitly described as post-hoc validation across held-out conditions, not as the source of the interval. No equations reduce the claimed result to its inputs by construction, no load-bearing self-citations appear, and the central premise does not invoke uniqueness theorems or ansatzes from the authors' prior work. The chain remains externally falsifiable and self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Any loss of distinguishability introduced in the first layer cannot be recovered by later layers.
Forward citations
Cited by 1 Pith paper
-
Partition-of-Unity Gaussian Kolmogorov-Arnold Networks
PU-GKAN applies Shepard normalization to Gaussian bases in KANs, yielding exact constant reproduction, reduced epsilon sensitivity, and better validation accuracy across tested regimes.
Reference graph
Works this paper leans on
-
[1]
KAN: Kolmogorov-Arnold Networks
Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljaˇ ci´ c, T. Y. Hou, and M. Tegmark, “KAN: Kolmogorov- Arnold networks,” arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Kan 2.0: Kolmogorov-arnold networks meet science,
Z. Liu, P. Ma, Y. Wang, W. Matusik, and M. Tegmark, “KAN 2.0: Kolm ogorov-Arnold networks meet science,” arXiv preprint arXiv:2408.10205, 2024. [Online]. Available: https://github.com/KindXiaoming/pykan 22
-
[3]
Physics-informe d neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differ ential equations,
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informe d neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differ ential equations,” J. Comput. Phys. , vol. 378, pp. 686–707, 2019
2019
-
[4]
Physics-informed machine learning,
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang , and L. Yang, “Physics-informed machine learning,” Nat. Rev. Phys. , vol. 3, no. 6, pp. 422–440, 2021
2021
-
[5]
S. Sidharth, K. A. R., and A. K. P., “Chebyshev polynomial-based K olmogorov-Arnold networks: An efficient archi- tecture for nonlinear function approximation,” arXiv preprint arXiv:2405.07200, 2024
-
[6]
N. A. Daryakenari, K. Shukla, and G. E. Karniadakis, “Represen tation meets optimization: Training PINNs and PIKANs for gray-box discovery in systems pharmacology,” arXiv preprint arXiv:2504.07379, 2025
-
[7]
KKANs: Kurk ova-Kolmogorov-Arnold networks and their learning dynamics,
J. D. Toscano, L.-L. Wang, and G. E. Karniadakis, “KKANs: Kurk ova-Kolmogorov-Arnold networks and their learning dynamics,” Neural Netw. , vol. 191, p. 107831, 2025
2025
-
[8]
fKAN: Fractional Kolmogorov-Arnold networks with trainable Jacobi basis functions,
A. A. Aghaei, “fKAN: Fractional Kolmogorov-Arnold networks w ith trainable Jacobi basis functions,” arXiv preprint arXiv:2406.07456, 2024. [Online]. Available: https://github.com/alirezaafzalaghaei/fKAN
-
[9]
Kolmogorov–Arnold PointNet: Deep learning for prediction of fluid fields on irregular geometries,
A. Kashefi and T. Mukerji, “Kolmogorov–Arnold PointNet: Deep le arning for prediction of fluid fields on irregular geometries,” arXiv preprint arXiv:2504.06327, 2025. [Online]. Available: https://github.com/Ali-Stanford/Physics_Informed_KA N_PointNet
-
[10]
J. Xu, Z. Chen, J. Li, S. Yang, W. Wang, X. Hu, and E. C. H. Ngai, “FourierKAN-GCF: Fourier Kolmogorov- Arnold network—An effective and efficient feature transformation for graph collaborative filtering,” arXiv preprint arXiv:2406.01034, 2024. [Online]. Available: https://github.com/Jinfeng-Xu/FKAN-GCF
-
[11]
Kolmogorov-Arnold Fou rier networks,
J. Zhang, Y. Fan, K. Cai, and K. Wang, “Kolmogorov-Arnold Fou rier networks,” arXiv preprint arXiv:2502.06018,
-
[12]
Available: https://github.com/kolmogorovArnoldFourierNetwork/KAF
[Online]. Available: https://github.com/kolmogorovArnoldFourierNetwork/KAF
-
[13]
C. C. So and S. P. Yung, “Higher-order ReLU-KANs (HRKANs) f or solving physics-informed neural networks (PINNs) more accurately, robustly, and faster,” arXiv preprint arXiv:2409.14248, 2024
-
[14]
Q. Qiu, T. Zhu, H. Gong, L. Chen, and H. Ning, “ReLU-KAN: New K olmogorov-Arnold networks that only need matrix addition, dot multiplication, and ReLU,” arXiv preprint arXiv:2406.02075, 2024. [Online]. Available: https://github.com/quiqi/relu_kan
-
[15]
Adaptive training of grid- dependent physics-informed Kolmogorov-Arnold networks,
S. Rigas, M. Papachristou, T. Papadopoulos, F. Anagnostopo ulos, and G. Alexandridis, “Adaptive training of grid- dependent physics-informed Kolmogorov-Arnold networks,” IEEE Access, vol. 12, pp. 176982–176998, 2024. [Online]. Available: https://github.com/srigas/jaxKAN
2024
-
[16]
Wav-kan: Wavelet kolmogorov-arnold networks,
Z. Bozorgasl and H. Chen, “Wav-KAN: Wavelet Kolmogorov-Ar nold networks,” arXiv preprint arXiv:2405.12832,
-
[17]
Available: https://github.com/zavareh1/Wav-KAN
[Online]. Available: https://github.com/zavareh1/Wav-KAN
-
[18]
A. A. Howard, B. Jacob, S. H. Murphy, A. Heinlein, and P. Stinis, “Finite basis Kolmogorov-Arnold networks: Domain decomposition for data-driven and physics-informed problems,” arXiv preprint arXiv:2406.19662, 2024. [Online]. Available: https://github.com/pnnl/neuromancer/tree/feature/fbkans/examples/KANs
-
[19]
S. T. Seydi, “Exploring the potential of polynomial basis functio ns in Kolmogorov-Arnold networks: A comparative study of different groups of polynomials,” arXiv preprint arXiv:2406.02583, 2024
-
[20]
J. A. Actor, G. Harper, B. Southworth, and E. C. Cyr, “Leve raging KANs for expedient training of multichannel MLPs via preconditioning and geometric refinement,” arXiv preprint arXiv:2505.18131, 2025
- [21]
-
[22]
SINDy-KANs: Sparse identification of nonlinear dynamics through Kolmogorov-Arnold networks,
A. A. Howard, N. Zolman, B. Jacob, S. L. Brunton, and P. Stinis , “SINDy-KANs: Sparse identification of nonlinear dynamics through Kolmogorov-Arnold networks,” 2026
2026
-
[23]
R. L. Hardy, Multiquadric equations of topography and other ir regular surfaces, Journal of Geophysical Research (1896-1977), 76(8), 1905–1915, 1971
1977
-
[24]
E. Kansa, Multiquadrics scattered data approximation scheme with applications to computational fluid-dynamics solutions to parabolic, hyperbolic and elliptic partial differential equa tions, Computers and Mathematics with Appli- cations, 19(8), 147–161, 1990. 23
1990
-
[25]
Available: https://arxiv.org/abs/2405.06721
Z. Li, “Kolmogorov-Arnold networks are radial basis function n etworks,” arXiv preprint arXiv:2405.06721, 2024. [Online]. Available: https://github.com/ZiyaoLi/fast-kan
-
[26]
B. C. Koenig, S. Kim, and S. Deng, “LeanKAN: A parameter-lean Kolmogorov-Arnold network layer with im- proved memory efficiency and convergence behavior,” arXiv preprint arXiv:2502.17844, 2025. [Online]. Available: https://github.com/DENG-MIT/LeanKAN
-
[27]
DeepOKAN: D eep operator network based on Kolmogorov- Arnold networks for mechanics problems,
D. W. Abueidda, P. Pantidis, and M. E. Mobasher, “DeepOKAN: D eep operator network based on Kolmogorov- Arnold networks for mechanics problems,” Computer Methods in Applied Mechanics and Engineering , vol. 436, p. 117699, 2025. GitHub: https://github.com/DiabAbu/Dee
2025
-
[28]
S. T. Chiu, S. W. Cheung, U. Braga-Neto, C. S. Lee, and R. P. L i, “Free-RBF-KAN: Kolmogorov-Arnold Networks with Adaptive Radial Basis Functions for Efficient Function Learning,” arXiv preprint arXiv:2601.07760, 2026
-
[29]
FasterKAN,
A. Delis, “FasterKAN,” GitHub repository, 2024. [Online]. Available : https://github.com/AthanasiosDelis/faster-kan
2024
-
[30]
Scaling of radial basis functions ,
E. Larsson and R. Schaback, “Scaling of radial basis functions ,” IMA Journal of Numerical Analysis , vol. 44, no. 2, pp. 1130–1152, 2024
2024
-
[31]
An adaptive refinement scheme for radial basis function collocation,
R. Cavoretto and A. De Rossi, “An adaptive refinement scheme for radial basis function collocation,” in Proc. Int. Conf. Numer. Comput.: Theory Algorithms , pp. 19–26, 2019
2019
-
[32]
A Bayesian app roach for simultaneously radial kernel parameter tuning in the partition of unity method,
R. Cavoretto, S. Lancellotti, and F. Romaniello, “A Bayesian app roach for simultaneously radial kernel parameter tuning in the partition of unity method,” in Proc. Int. Conf. Numer. Comput.: Theory Algorithms , pp. 215–222, 2023
2023
-
[33]
On the optimal shape parameter for kernel methods: Sharp direct and inverse statements,
T. Wenzel and G. Santin, “On the optimal shape parameter for kernel methods: Sharp direct and inverse statements,” arXiv preprint arXiv:2601.14070, 2026
-
[34]
Spectral alignment of kernel matrice s and applications,
T. Wenzel and A. Iske, “Spectral alignment of kernel matrice s and applications,” SIAM Journal on Matrix Analysis and Applications, vol. 47, no. 1, pp. 265–281, 2026
2026
-
[35]
Schaback, Error estimates and condition numbers for radia l basis function interpolation
R. Schaback, Error estimates and condition numbers for radia l basis function interpolation. Advances in Computa- tional Mathematics, 3(3): 251–264, 1995
1995
-
[36]
Small errors imply large evaluation instabilities,
R. Schaback, “Small errors imply large evaluation instabilities,” Advances in Computational Mathematics , vol. 49, no. 2, p. 25, 2023
2023
-
[37]
CVKAN: Complex-valued Kolmogo rov-Arnold networks,
M. Wolff, F. Eilers, and X. Jiang, “CVKAN: Complex-valued Kolmogo rov-Arnold networks,” arXiv preprint arXiv:2502.02417, 2025. [Online]. Available: https://github.com/M-Wolff/CVKAN
-
[38]
Improved Complex -Valued Kolmogorov–Arnold Networks with Theo- retical Support,
R. Che, L. af Klinteberg, and M. Aryapoor, “Improved Complex -Valued Kolmogorov–Arnold Networks with Theo- retical Support,” in Proc. 24th EPIA Conf. on Artificial Intelligence (EPIA) , Faro, Portugal, Oct. 2025, Part I, pp. 439–451. Springer, Heidelberg
2025
-
[39]
RBF-KAN: Radial Basis Functio n-Kolmogorov-Arnold Networks,
Z. Chao, X. Liu, Z. Wu, and X. Li, “RBF-KAN: Radial Basis Functio n-Kolmogorov-Arnold Networks,” IEEE Internet Things J. , 2026
2026
-
[40]
Farea, and M.S
A. Farea, and M.S. Celebi, Learnable activation functions in phys ics-informed neural networks for solving partial differential equations. Computer Physics Communications, 2025. 3 15: p. 109753
2025
-
[41]
Computing-in-memory architecture for Kolmogorov-Arnold net works based on tunable Gaussian-like memory cells,
Z. Wen, Q. Zhang, J. Chen, et al. , “Computing-in-memory architecture for Kolmogorov-Arnold net works based on tunable Gaussian-like memory cells,” Nat. Commun. , 2026
2026
-
[42]
Meshfree approximation methods with Matlab
G.E. Fasshauer, “Meshfree approximation methods with Matlab ” (Vol. 6). World Scientific Publishing Company, 2007
2007
-
[43]
A comparison of efficiency and error convergence of multiquadric collocation method and finite element method,
J. Li, A. H. D. Cheng, and C. S. Chen, “A comparison of efficiency and error convergence of multiquadric collocation method and finite element method,” Eng. Anal. Bound. Elem. , vol. 27, no. 3, pp. 251–257, 2003
2003
-
[44]
Eff ective condition number for the selection of the RBF shape parameter with the fictitious point method,
A. Noorizadegan, C.-S. Chen, D. L. Young, and C. S. Chen, “Eff ective condition number for the selection of the RBF shape parameter with the fictitious point method,” Applied Numerical Mathematics , vol. 178, pp. 280–295, 2022
2022
-
[45]
On the selection of a better radial basis function and its shape parameter in interpolation problems,
C.-S. Chen, A. Noorizadegan, D. L. Young, and C. S. Chen, “On the selection of a better radial basis function and its shape parameter in interpolation problems,” Applied Mathematics and Computation , vol. 442, p. 127713, 2023. 24
2023
-
[46]
Bending analysis of quasicrystal plates using adaptive radial basis function method,
A. Noorizadegan, A. Naji, T. L. Lee, R. Cavoretto, and D. L. Y oung, “Bending analysis of quasicrystal plates using adaptive radial basis function method,” J. Comput. Appl. Math. , vol. 450, p. 115990, 2024
2024
-
[47]
Introducing the evaluat ion condition number: A novel assessment of conditioning in radial basis function methods. Engineering Analysis with Boundary Elements,
A. Noorizadegan, and R. Schaback, “Introducing the evaluat ion condition number: A novel assessment of conditioning in radial basis function methods. Engineering Analysis with Boundary Elements,” 166, p.105827, 2024
2024
-
[48]
Theoretical and computationa l aspects of multivariate interpolation with increasingly flat radial basis functions,
E. Larsson and B. Fornberg, “Theoretical and computationa l aspects of multivariate interpolation with increasingly flat radial basis functions,” Comput. Math. Appl. , vol. 49, no. 1, pp. 103–130, 2005
2005
-
[49]
Stable evaluation of Gauss ian radial basis function interpolants,
G.E. Fasshauer, and M.J. McCourt, “Stable evaluation of Gauss ian radial basis function interpolants,” SIAM Journal on Scientific Computing, 34(2), pp.A737-A762, 2012
2012
-
[50]
Mathematical problems,
D. Hilbert, “Mathematical problems,” Bull. Amer. Math. Soc. , vol. 8, pp. 437–479, 1902
1902
-
[51]
On the representation of continuous func tions of several variables as superpositions of continuous functions of a smaller number of variables,
A. N. Kolmogorov, “On the representation of continuous func tions of several variables as superpositions of continuous functions of a smaller number of variables,” Dokl. Akad. Nauk SSSR , vol. 108, no. 2, pp. 179–182, 1956. (In Russian.)
1956
-
[52]
On functions of three variables,
V. I. Arnol’d, “On functions of three variables,” Dokl. Akad. Nauk SSSR , vol. 114, pp. 679–681, 1957. (In Russian.)
1957
-
[53]
On the representation of continuous func tions of many variables by superposition of continuous functions of one variable and addition,
A. N. Kolmogorov, “On the representation of continuous func tions of many variables by superposition of continuous functions of one variable and addition,” Doklady Akademii Nauk , vol. 114, pp. 953–956, 1957
1957
-
[54]
A Practitioner's Guide to Kolmogorov-Arnold Networks
A. Noorizadegan, S. Wang, , L. Ling, and J.P. Dominguez-Morale s, A Practitioner’s Guide to Kolmogorov-Arnold Networks. arXiv preprint arXiv:2510.25781, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Sinc Kolmogorov-Arnold Network and Its Applications on Physics-informed Neural Networks
T. Yu, J. Qiu, J. Yang, and I. Oseledets, “Sinc Kolmogorov-Arn old network and its applica- tions on physics-informed neural networks,” arXiv preprint arXiv:2410.04096, 2024. [Online]. Available: https://github.com/DUCH714/SincKAN
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
The role of the multiquadric shape parameters in solving elliptic partial differential equations,
J. Wertz, E. J. Kansa, and L. Ling, “The role of the multiquadric shape parameters in solving elliptic partial differential equations,” Computers & Mathematics with Applications , vol. 51, no. 8, pp. 1335–1348, 2006
2006
-
[57]
On variable and random sha pe Gaussian interpolations,
S. N. Chiu, L. Ling, and M. McCourt, “On variable and random sha pe Gaussian interpolations,” Applied Mathematics and Computation , vol. 377, p. 125159, 2020
2020
-
[58]
On choosing “optimal
G. E. Fasshauer and J. G. Zhang, “On choosing “optimal” shape parameters for RBF approximation,” Numer. Algorithms, vol. 45, no. 1, pp. 345–368, 2007
2007
-
[59]
Wendland, Scattered Data Approximation , Cambridge, U.K.: Cambridge Univ
H. Wendland, Scattered Data Approximation , Cambridge, U.K.: Cambridge Univ. Press, 2005
2005
-
[60]
Multistep scattered data interpo lation using compactly supported radial basis functions,
M. S. Floater, and A. Iske, “ Multistep scattered data interpo lation using compactly supported radial basis functions,” Journal of Computational and Applied Mathematics, 73(1-2), 65- 78, 1996
1996
-
[61]
A Newton basis for kernel spaces ,
S. M¨ uller and R. Schaback, “A Newton basis for kernel spaces ,” J. Approx. Theory , vol. 161, no. 2, pp. 645–655, 2009. 25
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.