Recognition: unknown
ReCAPA: Hierarchical Predictive Correction to Mitigate Cascading Failures
Pith reviewed 2026-05-12 03:04 UTC · model grok-4.3
The pith
ReCAPA applies predictive correction at action, subgoal and trajectory levels to limit error buildup in vision-language-action systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
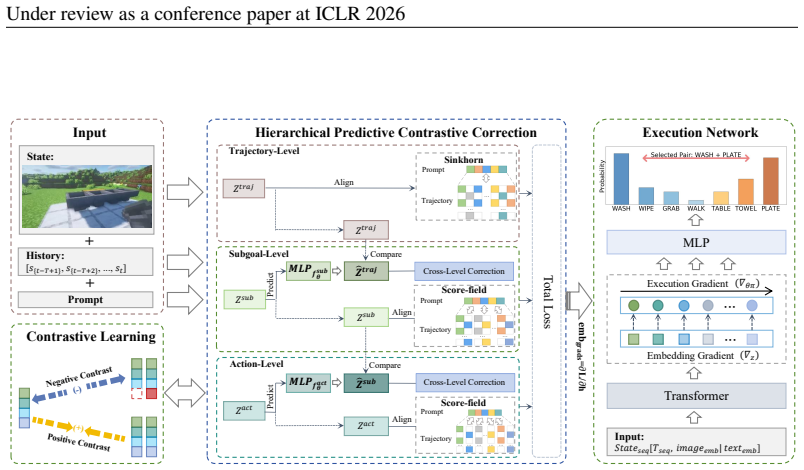
The Predictive Alignment and Planning Architecture uses prediction and contrast to adjust deviations across actions, subgoals and trajectories, with a Sinkhorn-based module and a Score-field module enforcing semantic alignment at every level; the combined correction updates the action generator so that fine-grained steps remain consistent with overall intent and thereby reduces cascading failures.
What carries the argument
Hierarchical predictive correction and contrastive alignment at the three levels of actions, subgoals and trajectories, implemented via Sinkhorn-based and Score-field modules.
If this is right
- The action generator learns to revise individual steps on the fly so they match higher-level subgoals and trajectories.
- Error accumulation can be measured directly with the introduced propagation and recovery metrics instead of relying only on final success rate.
- Training that jointly optimizes prediction, alignment and generation yields better long-sequence performance than post-hoc correction or fixed decomposition baselines.
- The same three-level structure can be applied to any VLA model that decomposes tasks into actions and higher abstractions.
Where Pith is reading between the lines
- The propagation and recovery metrics could serve as diagnostic tools for any long-horizon planning system, not just the ones tested here.
- Because alignment is enforced at multiple scales, the method might combine with existing reinforcement-learning or planning modules without requiring their complete replacement.
- If the hierarchical correction generalizes beyond the three embodied benchmarks, it could reduce the need for heavy post-training fixes in deployed agents.
Load-bearing premise
The predictive corrections at the three levels actually stop local mis-specifications from growing into full task failures rather than only raising average benchmark scores.
What would settle it
If the two new metrics for error propagation and recovery show no reduction in how mistakes spread across long-horizon trials on VisualAgentBench, MineDojo or AI2-THOR, even when overall success rates improve, the mitigation claim would not hold.
Figures




read the original abstract
Vision-Language-Action systems follow instructions to execute multi-step tasks in multimodal environments. Recent VLA approaches typically rely on post-hoc correction mechanisms or operate under fixed task decompositions and alignment schemes. However, once an intermediate step is mis-specified, local errors propagate through subsequent steps and eventually accumulate into cascading failures. To mitigate this compounding effect, we propose Predictive Alignment and Planning Architecture, a framework that uses prediction and contrast to adjust deviations across three levels: actions, subgoals, and trajectories. Semantic alignment is enforced at all levels using a Sinkhorn-based module and a Score-field module. The predictive correction and alignment jointly update the action generator during training, enabling it to adjust fine-grained steps to remain aligned with the overall intent. We further introduce two new metrics to quantify error propagation and recovery processes in tasks, capturing how mistakes spread and fade over long-horizon execution. Experiments show that ReCAPA achieves competitive results on embodied agent benchmarks such as VisualAgentBench, MineDojo, and AI2-THOR, outperforming strong proprietary and open-source Large Language Model baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
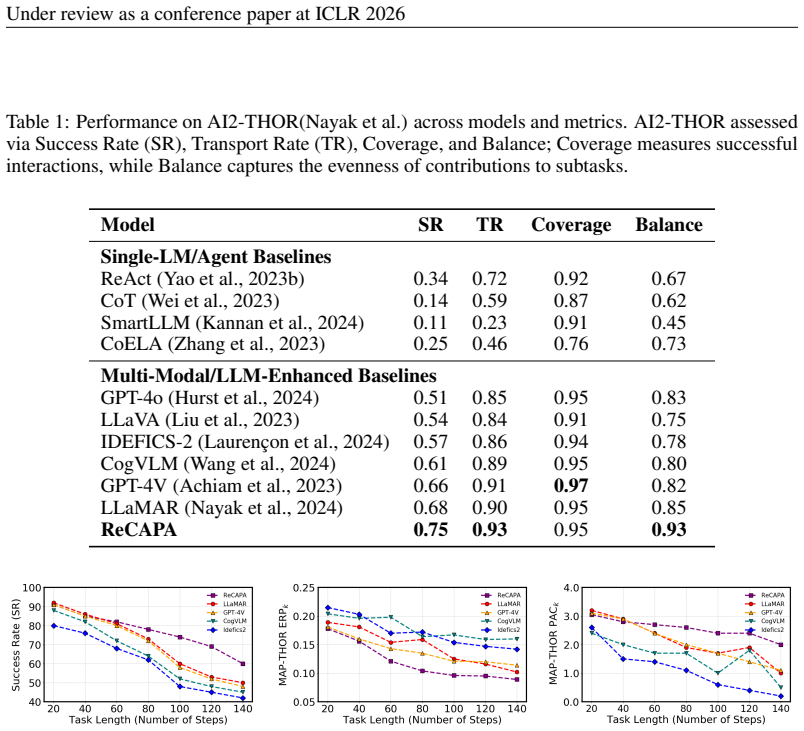
Summary. The paper proposes ReCAPA (ReCAPA: Hierarchical Predictive Correction to Mitigate Cascading Failures), a framework for Vision-Language-Action (VLA) systems that applies predictive correction and contrastive alignment at three hierarchical levels (actions, subgoals, trajectories) to prevent local errors from propagating into cascading failures during long-horizon embodied tasks. It uses a Sinkhorn-based semantic alignment module and a Score-field module to enforce alignment, jointly updating the action generator during training. Two new metrics are introduced to quantify error propagation and recovery. Experiments report competitive or superior results on VisualAgentBench, MineDojo, and AI2-THOR relative to strong proprietary and open-source LLM baselines.
Significance. If the central claim holds—that the three-level predictive correction and alignment specifically interrupt error propagation as measured by the new metrics—this could advance reliable long-horizon execution in embodied AI beyond current post-hoc correction or fixed-decomposition approaches. The new metrics for tracking how mistakes spread and fade are a constructive addition for evaluating robustness. Credit is due for the hierarchical design and the attempt to move beyond average-case success rates, though significance hinges on whether gains are isolated to the proposed mechanism rather than general VLA improvements.
major comments (2)
- [Experiments] Experiments section: the reported outperformance on VisualAgentBench, MineDojo, and AI2-THOR is not accompanied by ablations that isolate the full ReCAPA pipeline (three-level predictive correction + Sinkhorn/Score-field alignment) from the base VLA model, ablated versions (e.g., without hierarchical levels or without the Score-field module), or standard post-hoc correction baselines. Without these controls, it remains unclear whether gains arise from the claimed mitigation of cascading failures or from unrelated improvements in alignment or training dynamics.
- [Method] Method section (description of predictive correction): the claim that the Sinkhorn-based semantic alignment and Score-field predictive correction at action/subgoal/trajectory levels jointly update the action generator to reduce cascading failures requires explicit equations or pseudocode showing how the correction is applied during inference versus training; the abstract provides no such detail, leaving open whether the mechanism is truly predictive or reduces to a fitted alignment term.
minor comments (2)
- [Abstract] Abstract: the acronym ReCAPA is introduced without immediate expansion; while the title supplies it, the abstract should spell out 'ReCAPA' on first use for standalone readability.
- [Abstract] The two new metrics for error propagation and recovery are mentioned but their precise definitions, computation, and relation to existing metrics (e.g., success rate, trajectory length) are not summarized; a brief formal definition or reference to the relevant section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and will incorporate revisions to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported outperformance on VisualAgentBench, MineDojo, and AI2-THOR is not accompanied by ablations that isolate the full ReCAPA pipeline (three-level predictive correction + Sinkhorn/Score-field alignment) from the base VLA model, ablated versions (e.g., without hierarchical levels or without the Score-field module), or standard post-hoc correction baselines. Without these controls, it remains unclear whether gains arise from the claimed mitigation of cascading failures or from unrelated improvements in alignment or training dynamics.
Authors: We agree that the current set of experiments would benefit from additional ablations to better isolate the contributions of the full ReCAPA pipeline. In the revised manuscript, we will add ablation studies that remove the hierarchical levels, the Score-field module, and the Sinkhorn alignment, as well as comparisons against standard post-hoc correction baselines. These results will be presented in the Experiments section to more clearly attribute performance gains to the proposed mechanisms for interrupting error propagation. revision: yes
-
Referee: [Method] Method section (description of predictive correction): the claim that the Sinkhorn-based semantic alignment and Score-field predictive correction at action/subgoal/trajectory levels jointly update the action generator to reduce cascading failures requires explicit equations or pseudocode showing how the correction is applied during inference versus training; the abstract provides no such detail, leaving open whether the mechanism is truly predictive or reduces to a fitted alignment term.
Authors: We acknowledge that the distinction between inference-time predictive correction and training-time updates could be made more explicit. Although the Method section describes the hierarchical application of the Sinkhorn-based module and Score-field, we will add formal equations for the alignment losses and predictive correction terms, along with pseudocode that separates the real-time correction process (applied at inference to adjust actions, subgoals, and trajectories) from the joint optimization during training. This will clarify the predictive nature of the approach and prevent any ambiguity about whether it reduces to post-training alignment. revision: yes
Circularity Check
No significant circularity; proposal is self-contained with external benchmark validation.
full rationale
The paper introduces ReCAPA as a hierarchical predictive correction framework for VLA systems, employing Sinkhorn-based semantic alignment and Score-field modules at action/subgoal/trajectory levels, plus two new error-propagation metrics. No equations, fitting procedures, or self-citations appear in the provided text that would reduce any claimed prediction or result to its own inputs by construction. The central claims rest on experimental outperformance on VisualAgentBench, MineDojo, and AI2-THOR against external baselines, making the derivation independent rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
arXiv:2303.08774. Anurag Ajay, Seungwook Han, Yilun Du, Shuang Li, Abhi Gupta, Tommi Jaakkola, Josh Tenen- baum, Leslie Kaelbling, Akash Srivastava, and Pulkit Agrawal. Compositional foundation models for hierarchical planning,
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
Accessed: 2025-09-03. Anthropic. Claude 3.5 sonnet.https://www.anthropic.com/news/ claude-3-5-sonnet, June 2024a. News release. Anthropic. The claude 3 model family: Opus, sonnet, haiku.https://www.anthropic.com/ index/claude-3-model-card, 2024b. Accessed: 2025-07-24. Anthropic. Claude sonnet 4.https://www.anthropic.com/claude/sonnet,
work page 2025
-
[5]
Ac- cessed: 2025-09-06. Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, local- ization, text reading, and beyond,
work page 2025
-
[6]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
URLhttps://arxiv.org/abs/2308.12966. Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Vision- language models can self-improve reasoning via reflection
URLhttps://arxiv.org/abs/ 2411.00855. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
-
[8]
Sinkhorn distances: Lightspeed computation of optimal transport
10 Under review as a conference paper at ICLR 2026 Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems, volume 26,
work page 2026
-
[9]
Procthor: Large-scale embodied ai using procedural generation, 2022
URLhttps://arxiv.org/abs/ 2206.06994. Zi-Yi Dou, Cheng-Fu Yang, Xueqing Wu, Kai-Wei Chang, and Nanyun Peng. Re-rest: Reflection- reinforced self-training for language agents.arXiv preprint arXiv:2406.01495,
-
[10]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URLhttps://arxiv.org/abs/2408.16500. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URLhttps: //arxiv.org/abs/2310.06825. Shyam Sundar Kannan, Vishnunandan LN Venkatesh, and Byung-Cheol Min. Smart-llm: Smart multi-agent robot task planning using large language models. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 12140–12147. IEEE,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Daniel Gordon, Yuke Zhu, Abhinav Gupta, Matthew Han, Jia Deng, and Ali Farhadi. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review arXiv
-
[15]
URLhttps://arxiv.org/abs/2405.02246. Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart ´ın- Mart´ın, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, Hang Yin, Michael Lin- gelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, Manasi Sharma, Dhruva Bansal, Samue...
-
[16]
Renjie Lu, Jingke Meng, and Wei-Shi Zheng
URLhttps: //arxiv.org/abs/2402.19299. Renjie Lu, Jingke Meng, and Wei-Shi Zheng. Pret: Planning with directed fidelity trajectory for vision and language navigation.arXiv preprint arXiv:2407.11487,
-
[17]
Proximal Policy Optimization Algorithms
URLhttps://arxiv.org/abs/1707.06347. Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Reflexion: Language Agents with Verbal Reinforcement Learning
URL https://arxiv.org/abs/2303.11366. Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C ˆot´e, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. In Proceedings of the International Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
URL https://arxiv.org/abs/2010.03768. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review arXiv 2010
-
[20]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal under- standing across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
12 Under review as a conference paper at ICLR 2026 Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Song XiXuan, et al. Cogvlm: Visual expert for pretrained language models.Advances in Neural Information Processing Systems, 37:121475–121499,
work page 2026
-
[22]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URLhttps://arxiv.org/abs/2201.11903. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023a. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React:...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Mineagent: Towards remote-sensing mineral exploration with multimodal large lan- guage models,
URLhttps://arxiv. org/abs/2412.17339. Haoqi Yuan, Chi Zhang, Hongcheng Wang, Feiyang Xie, Penglin Cai, Hao Dong, and Zongqing Lu. Skill reinforcement learning and planning for open-world long-horizon tasks,
-
[24]
URL https://arxiv.org/abs/2303.16563. Hongxin Zhang, Weihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B Tenenbaum, Tian- min Shu, and Chuang Gan. Building cooperative embodied agents modularly with large language models.arXiv preprint arXiv:2307.02485,
-
[25]
URLhttps://arxiv.org/abs/2408.16090. Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu, et al. Evaluation of openai o1: Opportunities and challenges of agi.arXiv preprint arXiv:2409.18486,
-
[26]
Siyu Zhou, Tianyi Zhou, Yijun Yang, Guodong Long, Deheng Ye, Jing Jiang, and Chengqi Zhang. Wall-e: World alignment by rule learning improves world model-based llm agents.arXiv preprint arXiv:2410.07484,
-
[27]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
URLhttps:// arxiv.org/abs/2304.10592. Yifeng Zhu, Jonathan Tremblay, Stan Birchfield, and Yuke Zhu. Hierarchical planning for long-horizon manipulation with geometric and symbolic scene graphs,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
URLhttps: //arxiv.org/abs/2012.07277. 13 Under review as a conference paper at ICLR 2026 A DETAILEDEXPERIMENTALPROCEDURES ReCAPA employs a two-stage training process. The first stage is offline pre-training on diverse ex- pert and LLM-generated trajectories to establish hierarchical predictive and alignment capabilities. In the second stage, we adopt benc...
-
[29]
The learning rate follows a cosine schedule with a linear warm-up over the first 1,000 steps. Training is conducted for a total of 200,000 steps, with the model being trained on 4 NVIDIA H20 GPUs to ensure efficient scaling across large datasets. The text encoder (nomic-embed-text-v1.5) encodes prompt tokens, while the vision encoder (nomic-embed-vision- ...
work page 2026
-
[30]
2.6 1.5 1.2 1.1 0.6 0.3 0.0 Table 6: Performance of ReCAPA Variants under Layer-wise Ablation across Benchmarks. This table estimates the expected impact of removing individual layers or flattening the hierarchy (Flat- Head) on ReCAPA’s performance across diverse environments, highlighting the necessity of each abstraction level Method EmbodiedAgentInterf...
work page 2026
-
[31]
, wheree t is the error indicator andt 0 denotes the first-error time. Intuitively, PAC measures how quickly the elevated error probability induced by the first error attenuates over time. A value close to1indicates persistent risk, while a value below1indicates attenuation. 22 Under review as a conference paper at ICLR 2026 D.3.1 INTERPRETATION ANDPROPER...
work page 2026
-
[32]
D.3.4 PRACTICALCONSIDERATIONS Normalization stability.Ifbq(1)is very small, PAC may be unstable
and relative acceleration/attenuation trends. D.3.4 PRACTICALCONSIDERATIONS Normalization stability.Ifbq(1)is very small, PAC may be unstable. Exclude cases with vanishing immediate risk or regularize with a smallϵ. Censoring.Restrict horizonWto avoid censoring, as in EPR. Variance estimation.Use bootstrap resampling over episodes. 23 Under review as a co...
work page 2026
-
[33]
E.4 HIERARCHICALCONVERGENCEBOUND The proposed hierarchical framework operates across multiple abstraction levels—actions, subgoals, and task-level intents—each equipped with a dedicated alignment loss. To ensure stable joint opti- mization, it is necessary to establish convergence guarantees or lower bounds on sample efficiency when all levels are trained...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.