Recognition: unknown
Beyond Single Plots: A Benchmark for Question Answering on Multi-Charts
Pith reviewed 2026-05-09 21:18 UTC · model grok-4.3
The pith
A benchmark for multi-chart question answering shows multimodal LLMs drop 27 percent in accuracy on human-authored questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes PolyChartQA as a benchmark for multi-chart question answering. It consists of multi-chart images collected from peer-reviewed computer science research publications along with corresponding questions and answers. Evaluations of state-of-the-art multimodal language models reveal a 27.4% drop in accuracy on human-authored questions relative to model-generated questions. The proposed prompting method achieves a 5.39% accuracy improvement. The benchmark covers variations in question type, difficulty, and multi-chart structural features to highlight specific limitations in current models.
What carries the argument
PolyChartQA, a dataset of multi-chart images and QA pairs designed to evaluate models' ability to synthesize information from several charts simultaneously.
Load-bearing premise
Multi-chart images and questions drawn from computer science research papers capture the essential difficulties encountered when interpreting multiple charts in everyday or other professional contexts.
What would settle it
Evaluating the models on a new set of multi-chart images sourced from non-academic domains such as news articles or corporate reports and finding that the accuracy drop disappears or reverses would indicate that the benchmark's challenges are not general.
Figures

















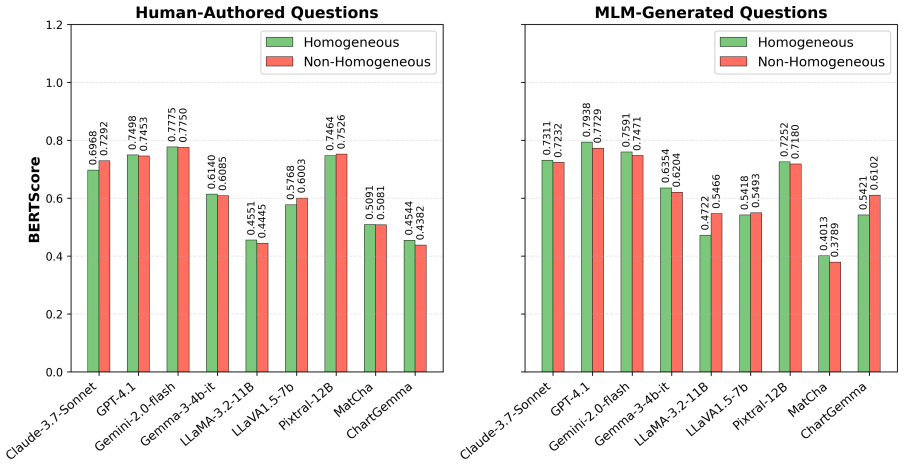
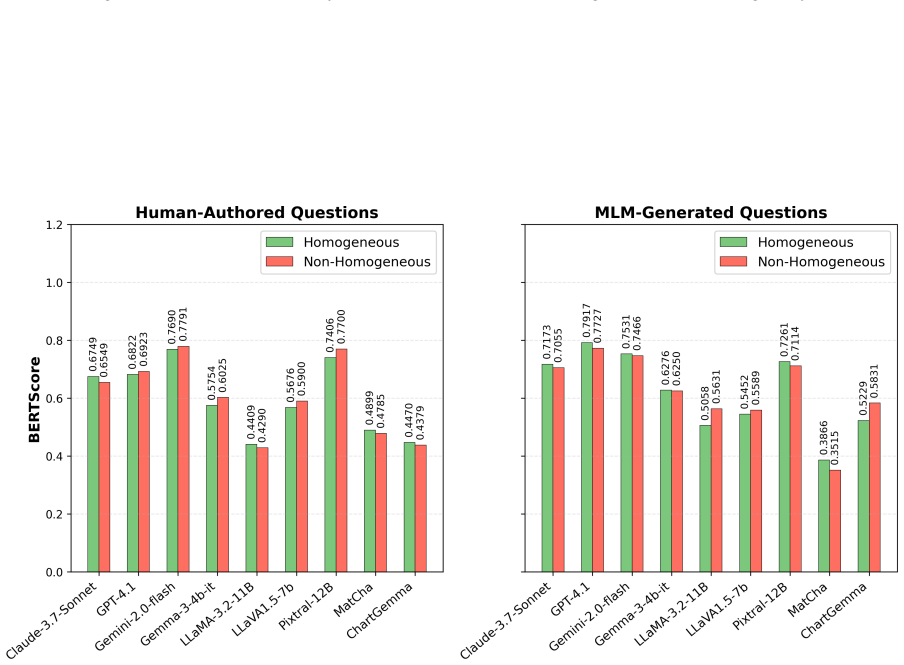







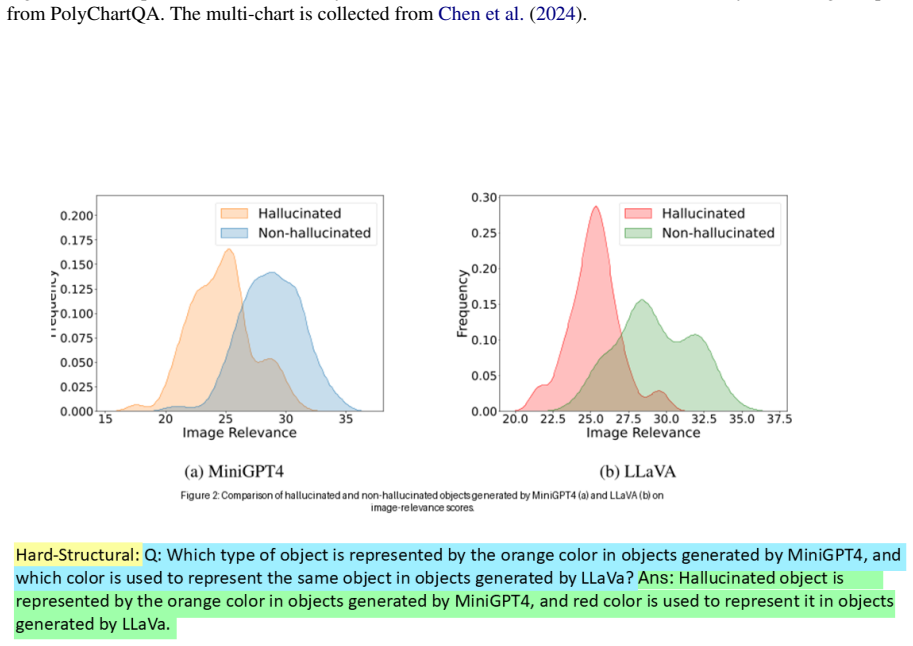



















read the original abstract
Charts are widely used to present complex information. Deriving meaningful insights in real-world contexts often requires interpreting multiple related charts together. Research on understanding multi-chart images has not been extensively explored. We introduce PolyChartQA, a mid-scale dataset specifically designed for question answering over multi-chart images. PolyChartQA comprises 534 multi-chart images (with a total of 2,297 sub-charts) sourced from peer-reviewed computer science research publications and 2,694 QA pairs. We evaluate the performance of nine state-of-the-art Multimodal Language Models (MLMs) on PolyChartQA across question type, difficulty, question source, and key structural characteristics of multi-charts. Our results show a 27.4% LLM-based accuracy (L-Accuracy) drop on human-authored questions compared to MLM-generated questions, and a 5.39% L-accuracy gain with our proposed prompting method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolyChartQA, a mid-scale benchmark dataset of 534 multi-chart images (2,297 sub-charts) sourced exclusively from peer-reviewed computer science publications, paired with 2,694 QA pairs. It evaluates nine state-of-the-art multimodal language models (MLMs) on the dataset, breaking down performance by question type, difficulty, source (human-authored vs. MLM-generated), and multi-chart structural features. Key reported results include a 27.4% drop in LLM-based accuracy (L-Accuracy) on human-authored questions relative to MLM-generated questions and a 5.39% L-Accuracy improvement from the authors' proposed prompting method.
Significance. If the empirical results hold under broader scrutiny, the work provides a concrete, publicly usable benchmark that fills a documented gap in multi-chart visual reasoning research. The quantitative gaps between human and generated questions, plus the prompting gain, offer falsifiable baselines that can guide future MLM development and evaluation protocols for complex visual inputs.
major comments (3)
- [Dataset Construction] Dataset Construction section: All 534 images and associated QA pairs are drawn exclusively from peer-reviewed CS publications. This narrow domain (technical line plots, heatmaps, error bars) is load-bearing for the headline claims, as the reported 27.4% L-Accuracy drop and 5.39% prompting gain may be artifacts of CS-specific visual conventions rather than general multi-chart challenges; the manuscript provides no cross-domain validation or explicit discussion of this scope limitation.
- [Experiments and Results] Experiments and Results sections: No statistical significance tests, confidence intervals, or controls for confounding variables (e.g., question difficulty distribution between human-authored and MLM-generated subsets) are reported for the 27.4% and 5.39% differences. Without these, it is impossible to determine whether the accuracy gaps are robust or driven by imbalances in the 2,694 QA pairs.
- [Question Generation] Question Generation subsection: The methods used to create MLM-generated questions versus human-authored questions are not described in sufficient detail (e.g., prompting templates, filtering criteria, or inter-annotator agreement for human questions). This directly affects interpretability of the 27.4% drop, which is presented as a central finding.
minor comments (3)
- [Abstract / Evaluation Metrics] The abstract and introduction use 'L-Accuracy' without an explicit definition or equation on first use; add a clear definition in the evaluation metrics paragraph.
- [Results] Table or figure reporting per-model accuracies should include the total number of questions per category to allow readers to assess sample sizes behind the percentage differences.
- [Related Work] A small number of citations to prior single-chart QA benchmarks (e.g., ChartQA, PlotQA) are present but could be expanded with a dedicated related-work paragraph contrasting multi-chart vs. single-chart difficulties.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript accordingly to improve clarity, rigor, and transparency.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset Construction section: All 534 images and associated QA pairs are drawn exclusively from peer-reviewed CS publications. This narrow domain (technical line plots, heatmaps, error bars) is load-bearing for the headline claims, as the reported 27.4% L-Accuracy drop and 5.39% prompting gain may be artifacts of CS-specific visual conventions rather than general multi-chart challenges; the manuscript provides no cross-domain validation or explicit discussion of this scope limitation.
Authors: We acknowledge the dataset's exclusive sourcing from computer science publications, which was chosen to ensure high-quality, peer-reviewed multi-chart examples with authentic scientific complexity. This domain provides representative instances of the multi-chart reasoning challenges the benchmark targets. We agree that explicit discussion of scope was insufficient and have added a dedicated limitations paragraph addressing generalizability, potential domain-specific visual conventions, and directions for future cross-domain extensions. No new cross-domain data collection was feasible within the current study scope. revision: partial
-
Referee: [Experiments and Results] Experiments and Results sections: No statistical significance tests, confidence intervals, or controls for confounding variables (e.g., question difficulty distribution between human-authored and MLM-generated subsets) are reported for the 27.4% and 5.39% differences. Without these, it is impossible to determine whether the accuracy gaps are robust or driven by imbalances in the 2,694 QA pairs.
Authors: We agree that statistical tests and controls are necessary for robust interpretation of the reported differences. In the revised manuscript, we have added paired t-tests with confidence intervals for the 27.4% and 5.39% L-Accuracy gaps. We have also included additional breakdowns and matching controls for question difficulty, type, and length distributions between the human-authored and MLM-generated subsets to address potential confounds. revision: yes
-
Referee: [Question Generation] Question Generation subsection: The methods used to create MLM-generated questions versus human-authored questions are not described in sufficient detail (e.g., prompting templates, filtering criteria, or inter-annotator agreement for human questions). This directly affects interpretability of the 27.4% drop, which is presented as a central finding.
Authors: We have expanded the Question Generation subsection with the requested details: full prompting templates used for MLM-generated questions, explicit filtering criteria applied to both subsets, and inter-annotator agreement statistics (Cohen's kappa) for the human-authored questions. These additions directly support interpretability of the human vs. generated performance gap. revision: yes
Circularity Check
No circularity: empirical benchmark with independent measurements on new dataset
full rationale
The paper constructs PolyChartQA (534 images, 2694 QA pairs from CS publications) and reports direct accuracy measurements on nine MLMs, including the 27.4% L-Accuracy drop between human-authored and MLM-generated questions plus the 5.39% prompting gain. These are straightforward empirical observations on held-out test items with no equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that reduce the central claims to the inputs. The derivation chain (dataset curation followed by model evaluation) is self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
SynChart: Synthesizing Charts from Language Models , author=. 2024 , eprint=
2024
-
[2]
Omni-Chart-600 K : A Comprehensive Dataset of Chart Types for Chart Understanding
Wang, Shulei and Yang, Shuai and Lin, Wang and Guo, Zirun and Cai, Sihang and Huang, Hai and Wang, Ye and Chen, Jingyuan and Jin, Tao. Omni-Chart-600 K : A Comprehensive Dataset of Chart Types for Chart Understanding. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.226
-
[3]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
EvoChart: A Benchmark and a Self-Training Approach Towards Real-World Chart Understanding , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i4.32383 , number=
-
[4]
Kim, Dae Hyun and Hoque, Enamul and Agrawala, Maneesh , title =. 2020 , isbn =. doi:10.1145/3313831.3376467 , booktitle =
-
[5]
doi: 10.18653/v1/2022.findings-acl.177
Masry, Ahmed and Do, Xuan Long and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[6]
Hoque, E. and Kavehzadeh, P. and Masry, A. , title =. Computer Graphics Forum , volume =. doi:https://doi.org/10.1111/cgf.14573 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/cgf.14573 , year =
-
[7]
Reading and Reasoning over Chart Images for Evidence-based Automated Fact-Checking
Akhtar, Mubashara and Cocarascu, Oana and Simperl, Elena. Reading and Reasoning over Chart Images for Evidence-based Automated Fact-Checking. Findings of the Association for Computational Linguistics: EACL 2023. 2023. doi:10.18653/v1/2023.findings-eacl.30
-
[8]
Are Large Vision Language Models up to the Challenge of Chart Comprehension and Reasoning
Islam, Mohammed Saidul and Rahman, Raian and Masry, Ahmed and Laskar, Md Tahmid Rahman and Nayeem, Mir Tafseer and Hoque, Enamul. Are Large Vision Language Models up to the Challenge of Chart Comprehension and Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.191
-
[9]
M., Piccinno, F., Krichene, S., Pang, C., Lee, K., Joshi, M., Chen, W., Collier, N., and Altun, Y
Liu, Fangyu and Eisenschlos, Julian and Piccinno, Francesco and Krichene, Syrine and Pang, Chenxi and Lee, Kenton and Joshi, Mandar and Chen, Wenhu and Collier, Nigel and Altun, Yasemin. D e P lot: One-shot visual language reasoning by plot-to-table translation. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/202...
-
[10]
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day , url =
Li, Chunyuan and Wong, Cliff and Zhang, Sheng and Usuyama, Naoto and Liu, Haotian and Yang, Jianwei and Naumann, Tristan and Poon, Hoifung and Gao, Jianfeng , booktitle =. LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day , url =
-
[11]
Rotstein, Noam and Bensaid, David and Brody, Shaked and Ganz, Roy and Kimmel, Ron , booktitle =. 2024 , volume =. doi:10.1109/WACV57701.2024.00559 , url =
-
[12]
Generating Images with Multimodal Language Models , url =
Koh, Jing Yu and Fried, Daniel and Salakhutdinov, Russ R , booktitle =. Generating Images with Multimodal Language Models , url =
-
[13]
C hart G emma: Visual Instruction-tuning for Chart Reasoning in the Wild
Masry, Ahmed and Thakkar, Megh and Bajaj, Aayush and Kartha, Aaryaman and Hoque, Enamul and Joty, Shafiq. C hart G emma: Visual Instruction-tuning for Chart Reasoning in the Wild. Proceedings of the 31st International Conference on Computational Linguistics: Industry Track. 2025
2025
-
[14]
Zhang, Liang and Hu, Anwen and Xu, Haiyang and Yan, Ming and Xu, Yichen and Jin, Qin and Zhang, Ji and Huang, Fei. T iny C hart: Efficient Chart Understanding with Program-of-Thoughts Learning and Visual Token Merging. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.112
-
[15]
M ulti C hart QA : Benchmarking Vision-Language Models on Multi-Chart Problems
Zhu, Zifeng and Jia, Mengzhao and Zhang, Zhihan and Li, Lang and Jiang, Meng. M ulti C hart QA : Benchmarking Vision-Language Models on Multi-Chart Problems. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/...
-
[16]
DVQA: Understanding Data Visualizations via Question Answering , year=
Kafle, Kushal and Price, Brian and Cohen, Scott and Kanan, Christopher , booktitle=. DVQA: Understanding Data Visualizations via Question Answering , year=
-
[17]
LEAF-QA: Locate, Encode & Attend for Figure Question Answering , year=
Chaudhry, Ritwick and Shekhar, Sumit and Gupta, Utkarsh and Maneriker, Pranav and Bansal, Prann and Joshi, Ajay , booktitle=. LEAF-QA: Locate, Encode & Attend for Figure Question Answering , year=
-
[18]
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Figureqa: An annotated figure dataset for visual reasoning , author=. arXiv preprint arXiv:1710.07300 , year=. doi:10.48550/arXiv.1710.07300
-
[19]
and Kumar, Pratyush , booktitle=
Methani, Nitesh and Ganguly, Pritha and Khapra, Mitesh M. and Kumar, Pratyush , booktitle=. PlotQA: Reasoning over Scientific Plots , year=
-
[20]
MMC : Advancing multimodal chart understanding with large-scale instruction tuning
Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong. MMC : Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologi...
-
[21]
C hart I nstruct: Instruction Tuning for Chart Comprehension and Reasoning
Masry, Ahmed and Shahmohammadi, Mehrad and Parvez, Md Rizwan and Hoque, Enamul and Joty, Shafiq. C hart I nstruct: Instruction Tuning for Chart Comprehension and Reasoning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.619
-
[22]
2024 , eprint=
SBS Figures: Pre-training Figure QA from Stage-by-Stage Synthesized Images , author=. 2024 , eprint=
2024
-
[23]
Li, Zhuowan and Jasani, Bhavan and Tang, Peng and Ghadar, Shabnam , booktitle =. 2024 , volume =. doi:10.1109/CVPR52733.2024.01292 , url =
-
[24]
Unraveling the Truth: Do VLM s really Understand Charts? A Deep Dive into Consistency and Robustness
Mukhopadhyay, Srija and Qidwai, Adnan and Garimella, Aparna and Ramu, Pritika and Gupta, Vivek and Roth, Dan. Unraveling the Truth: Do VLM s really Understand Charts? A Deep Dive into Consistency and Robustness. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.973
-
[25]
U ni C hart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning
Masry, Ahmed and Kavehzadeh, Parsa and Do, Xuan Long and Hoque, Enamul and Joty, Shafiq. U ni C hart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.906
-
[26]
SIMPLOT : Enhancing Chart Question Answering by Distilling Essentials
Kim, Wonjoong and Park, Sangwu and In, Yeonjun and Han, Seokwon and Park, Chanyoung. SIMPLOT : Enhancing Chart Question Answering by Distilling Essentials. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.35
-
[27]
STL-CQA : Structure-based Transformers with Localization and Encoding for Chart Question Answering
Singh, Hrituraj and Shekhar, Sumit. STL-CQA : Structure-based Transformers with Localization and Encoding for Chart Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.264
-
[28]
Clark, Christopher and Divvala, Santosh , title =. 2016 , isbn =. doi:10.1145/2910896.2910904 , booktitle =
-
[29]
Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
Kantharaj, Shankar and Leong, Rixie Tiffany and Lin, Xiang and Masry, Ahmed and Thakkar, Megh and Hoque, Enamul and Joty, Shafiq. Chart-to-Text: A Large-Scale Benchmark for Chart Summarization. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.277
-
[30]
SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers , url =
Pramanick, Shraman and Chellappa, Rama and Venugopalan, Subhashini , booktitle =. SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers , url =
-
[31]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[32]
2019 , eprint=
The Effect of Visual Design in Image Classification , author=. 2019 , eprint=
2019
-
[33]
Beattie, Vivien and Jones, Michael John , title =. Abacus , volume =. doi:https://doi.org/10.1111/1467-6281.00104 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/1467-6281.00104 , year =
-
[34]
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs , url =
Wang, Zirui and Xia, Mengzhou and He, Luxi and Chen, Howard and Liu, Yitao and Zhu, Richard and Liang, Kaiqu and Wu, Xindi and Liu, Haotian and Malladi, Sadhika and Chevalier, Alexis and Arora, Sanjeev and Chen, Danqi , booktitle =. CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs , url =
-
[35]
2025 , eprint=
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models , author=. 2025 , eprint=
2025
-
[36]
A New Pipeline for Knowledge Graph Reasoning Enhanced by Large Language Models Without Fine-Tuning
Chen, Zhongwu and Bai, Long and Li, Zixuan and Huang, Zhen and Jin, Xiaolong and Dou, Yong. A New Pipeline for Knowledge Graph Reasoning Enhanced by Large Language Models Without Fine-Tuning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.81
-
[37]
Xing, Shangyu and Zhao, Fei and Wu, Zhen and An, Tuo and Chen, Weihao and Li, Chunhui and Zhang, Jianbing and Dai, Xinyu. EFUF : Efficient Fine-Grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.em...
-
[38]
``Thinking'' Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
Furniturewala, Shaz and Jandial, Surgan and Java, Abhinav and Banerjee, Pragyan and Shahid, Simra and Bhatia, Sumit and Jaidka, Kokil. ``Thinking'' Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.13
-
[39]
Rethinking Token Reduction for State Space Models
Zhan, Zheng and Wu, Yushu and Kong, Zhenglun and Yang, Changdi and Gong, Yifan and Shen, Xuan and Lin, Xue and Zhao, Pu and Wang, Yanzhi. Rethinking Token Reduction for State Space Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.100
-
[40]
Tahir, Ammar and Goyal, Prateesh and Marinos, Ilias and Evans, Mike and Mittal, Radhika , title =. 2024 , isbn =. doi:10.1145/3651890.3672267 , booktitle =
-
[41]
Proceedings of the 41st International Conference on Machine Learning , pages =
How Learning by Reconstruction Produces Uninformative Features For Perception , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[42]
doi: 10.18653/v1/2024.emnlp-main.78
Liu, Zihang and Hu, Yuanzhe and Pang, Tianyu and Zhou, Yefan and Ren, Pu and Yang, Yaoqing. Model Balancing Helps Low-data Training and Fine-tuning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.78
-
[43]
Wu, Cheng-Kuang and Tam, Zhi Rui and Wu, Chao-Chung and Lin, Chieh-Yen and Lee, Hung-yi and Chen, Yun-Nung. I Need Help! Evaluating LLM ' s Ability to Ask for Users' Support: A Case Study on Text-to- SQL Generation. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.131
-
[44]
Chart Question Answering from Real-World Analytical Narratives
Hutchinson, Maeve and Jianu, Radu and Slingsby, Aidan and Wood, Jo and Madhyastha, Pranava. Chart Question Answering from Real-World Analytical Narratives. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop). 2025. doi:10.18653/v1/2025.acl-srw.50
-
[45]
Enhanced Chart Understanding via Visual Language Pre-training on Plot Table Pairs
Zhou, Mingyang and Fung, Yi and Chen, Long and Thomas, Christopher and Ji, Heng and Chang, Shih-Fu. Enhanced Chart Understanding via Visual Language Pre-training on Plot Table Pairs. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.85
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Union Is Strength! Unite the Power of LLMs and MLLMs for Chart Question Answering , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i5.32584 , number=
-
[47]
Meng, Fanqing and Shao, Wenqi and Lu, Quanfeng and Gao, Peng and Zhang, Kaipeng and Qiao, Yu and Luo, Ping. C hart A ssistant: A Universal Chart Multimodal Language Model via Chart-to-Table Pre-training and Multitask Instruction Tuning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.463
-
[48]
S., Ahmed, M., Bajaj, A., Kabir, F., Kartha, A., Laskar, M
Masry, Ahmed and Islam, Mohammed Saidul and Ahmed, Mahir and Bajaj, Aayush and Kabir, Firoz and Kartha, Aaryaman and Laskar, Md Tahmid Rahman and Rahman, Mizanur and Rahman, Shadikur and Shahmohammadi, Mehrad and Thakkar, Megh and Parvez, Md Rizwan and Hoque, Enamul and Joty, Shafiq. C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Questi...
-
[49]
C hart I nsights: Evaluating Multimodal Large Language Models for Low-Level Chart Question Answering
Wu, Yifan and Yan, Lutao and Shen, Leixian and Wang, Yunhai and Tang, Nan and Luo, Yuyu. C hart I nsights: Evaluating Multimodal Large Language Models for Low-Level Chart Question Answering. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.710
-
[50]
M at C ha: Enhancing visual language pretraining with math reasoning and chart derendering
Liu, Fangyu and Piccinno, Francesco and Krichene, Syrine and Pang, Chenxi and Lee, Kenton and Joshi, Mandar and Altun, Yasemin and Collier, Nigel and Eisenschlos, Julian. M at C ha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volum...
-
[51]
D ecorate LM : Data Engineering through Corpus Rating, Tagging, and Editing with Language Models
Zhao, Ranchi and Thai, Zhen Leng and Zhang, Yifan and Hu, Shengding and Zhou, Jie and Ba, Yunqi and Cai, Jie and Liu, Zhiyuan and Sun, Maosong. D ecorate LM : Data Engineering through Corpus Rating, Tagging, and Editing with Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024....
-
[52]
LLM -Based Agent Society Investigation: Collaboration and Confrontation in Avalon Gameplay
Lan, Yihuai and Hu, Zhiqiang and Wang, Lei and Wang, Yang and Ye, Deheng and Zhao, Peilin and Lim, Ee-Peng and Xiong, Hui and Wang, Hao. LLM -Based Agent Society Investigation: Collaboration and Confrontation in Avalon Gameplay. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.7
-
[53]
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Shin, Sungbin and Park, Wonpyo and Lee, Jaeho and Lee, Namhoon. Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.68
-
[54]
Pan, Rangeet and Ibrahimzada, Ali Reza and Krishna, Rahul and Sankar, Divya and Wassi, Lambert Pouguem and Merler, Michele and Sobolev, Boris and Pavuluri, Raju and Sinha, Saurabh and Jabbarvand, Reyhaneh , title =. 2024 , isbn =. doi:10.1145/3597503.3639226 , booktitle =
-
[55]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
Garg, Roopal and Burns, Andrea and Karagol Ayan, Burcu and Bitton, Yonatan and Montgomery, Ceslee and Onoe, Yasumasa and Bunner, Andrew and Krishna, Ranjay and Baldridge, Jason Michael and Soricut, Radu. I mage I n W ords: Unlocking Hyper-Detailed Image Descriptions. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2...
-
[56]
A Diversity-Promoting Objective Function for Neural Conversation Models
Li, Jiwei and Galley, Michel and Brockett, Chris and Gao, Jianfeng and Dolan, Bill. A Diversity-Promoting Objective Function for Neural Conversation Models. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.18653/v1/N16-1014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.