Recognition: unknown
PivotMerge: Bridging Heterogeneous Multimodal Pre-training via Post-Alignment Model Merging
Pith reviewed 2026-05-10 07:00 UTC · model grok-4.3
The pith
PivotMerge integrates cross-modal projectors from separate multimodal pre-training runs by separating shared alignment patterns from domain conflicts and weighting layers by their individual contributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
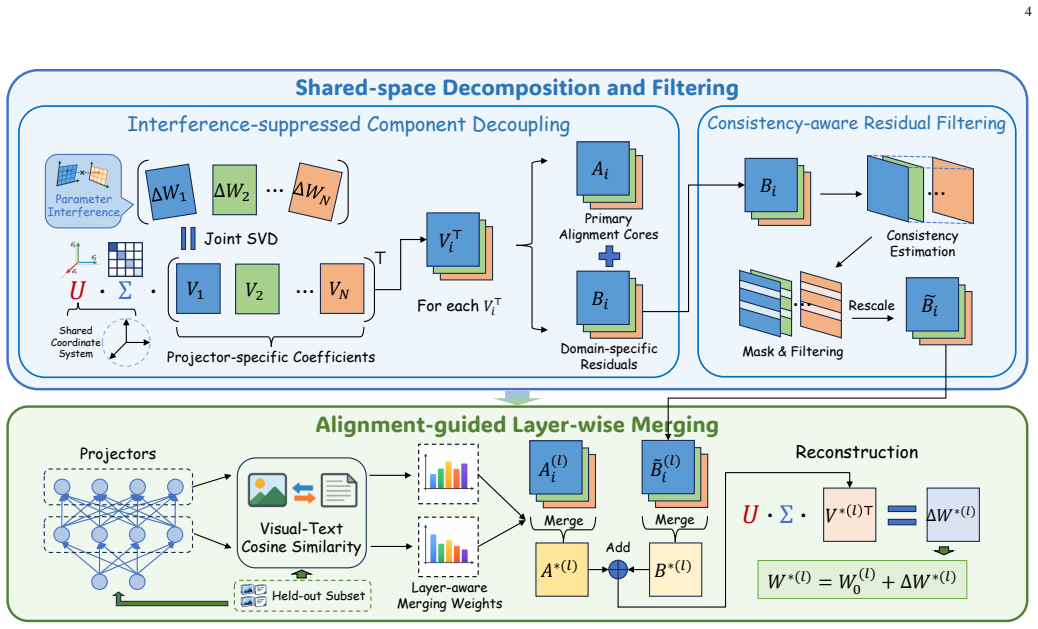
The central claim is that post-alignment merging of cross-modal projectors succeeds when Shared-space Decomposition and Filtering first isolates common alignment directions while removing domain-specific conflicts, and Alignment-guided Layer-wise Merging then applies distinct weights to each layer according to its measured contribution to cross-modal alignment; this procedure resolves the two identified challenges and yields consistent gains across multiple CC12M-derived evaluation scenarios on standard vision-language benchmarks.
What carries the argument
PivotMerge, a two-stage merging procedure for cross-modal projectors that first decomposes parameters into shared versus domain-specific components and filters conflicting directions, then assigns merging coefficients per layer based on each layer's alignment contribution.
If this is right
- Complementary alignment capabilities learned from separate pre-training distributions can be unified into one projector without joint retraining.
- Layer-specific weighting improves the merged model's ability to leverage the strongest alignment signals from each source.
- The merged model outperforms both the source experts and standard merging methods on downstream multimodal tasks.
- The same decomposition-plus-filtering step suppresses parameter conflicts that otherwise degrade performance during merging.
Where Pith is reading between the lines
- The same filtering of conflicting directions could be applied when merging more than two projectors by repeating the shared-space step across pairs.
- Measuring alignment contribution per layer might serve as a general diagnostic for deciding which parts of any projector deserve higher weight in other merging tasks.
- If the shared-space decomposition proves stable, it could reduce the need to store full copies of multiple expert projectors before merging.
Load-bearing premise
The two identified problems of cross-domain parameter interference and unequal layer contributions to alignment are the main reasons ordinary merging methods fail to combine projectors trained on different datasets.
What would settle it
If, on the same CC12M-based post-alignment scenarios, a simple averaging merge or an existing baseline achieves equal or higher scores on multimodal benchmarks such as VQA or captioning than PivotMerge, the necessity of the decomposition and layer-weighting steps would be refuted.
Figures





read the original abstract
Multimodal Large Language Models (MLLMs) rely on multimodal pre-training over diverse data sources, where different datasets often induce complementary cross-modal alignment capabilities. Model merging provides a cost-effective mechanism for integrating multiple expert MLLMs with complementary strengths into a unified model. However, existing model merging research mainly focuses on post-finetuning scenarios, leaving the pre-training stage largely unexplored. We argue that the core of MLLM pre-training lies in establishing effective cross-modal alignment, which bridges visual and textual representations into a unified semantic space. Motivated by this insight, we introduce the post-alignment merging task, which aims to integrate cross-modal alignment capabilities learned from heterogeneous multimodal pre-training. This setting introduces two key challenges: cross-domain parameter interference, where parameter updates learned from different data distributions conflict during merging, and layer-wise alignment contribution disparity, where different layers and projectors contribute unevenly to cross-modal alignment. To address them, we propose \textbf{PivotMerge}, a post-alignment merging framework for cross-modal projectors. PivotMerge incorporates two key components: Shared-space Decomposition and Filtering, which disentangles shared alignment patterns from domain-specific variations and suppresses conflicting directions, and Alignment-guided Layer-wise Merging, which assigns layer-specific merging weights based on differing alignment contributions. We construct systematic CC12M-based post-alignment merging scenarios for evaluation. Extensive experiments on multiple multimodal benchmarks show that PivotMerge consistently outperforms existing baselines, demonstrating its effectiveness and generalization ability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PivotMerge, a post-alignment model merging framework for integrating cross-modal projectors trained on heterogeneous multimodal data. It identifies two challenges—cross-domain parameter interference and layer-wise alignment contribution disparity—and proposes Shared-space Decomposition and Filtering plus Alignment-guided Layer-wise Merging to address them. Evaluation uses constructed CC12M-based post-alignment scenarios, with claims of consistent outperformance over baselines on multiple multimodal benchmarks.
Significance. If the central claims hold, PivotMerge offers a practical, training-free way to combine complementary alignment capabilities from diverse pre-training corpora into unified MLLMs, reducing the need for costly joint pre-training. The approach is motivated by concrete pre-training realities and could generalize to other projector-based architectures, but its impact hinges on whether the reported gains reflect genuine robustness to real distributional mismatch rather than artifacts of the synthetic evaluation construction.
major comments (2)
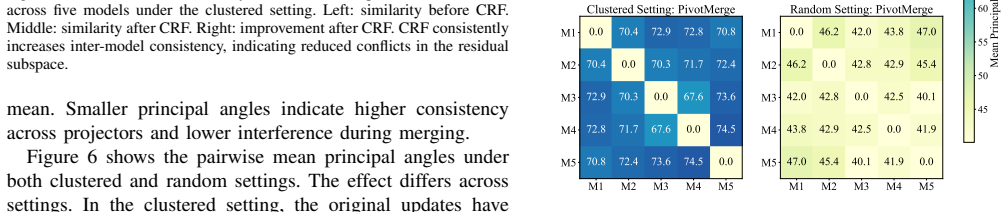
- [§4] §4 (Evaluation setup): The post-alignment merging scenarios are derived from a single CC12M corpus via simulated domain splits; this construction risks under-representing the scale of parameter interference and layer-wise disparity that arise from genuinely disjoint real-world sources (e.g., LAION, Conceptual Captions, SBU). If the induced conflicts differ materially from those in heterogeneous pre-training, the outperformance claims become tied to an artificial testbed rather than a general solution.
- [Abstract, §3] Abstract and §3 (Method): The two proposed components (Shared-space Decomposition and Filtering; Alignment-guided Layer-wise Merging) are presented as directly targeting the stated challenges, yet no ablation isolates their individual contributions to the final merged projector, nor are the decomposition hyperparameters or layer-wise weight assignment rules shown to be robust across different projector architectures.
minor comments (2)
- [Abstract] Abstract: The claim of 'consistent outperformance' is stated without any quantitative metrics, baseline names, or statistical significance details; these should be summarized even at the abstract level to allow immediate assessment of effect sizes.
- Notation: The paper introduces 'pivot' and 'shared-space' concepts without an explicit diagram or pseudocode showing how the decomposition projects parameters into the shared space before filtering; a figure would clarify the pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation setup): The post-alignment merging scenarios are derived from a single CC12M corpus via simulated domain splits; this construction risks under-representing the scale of parameter interference and layer-wise disparity that arise from genuinely disjoint real-world sources (e.g., LAION, Conceptual Captions, SBU). If the induced conflicts differ materially from those in heterogeneous pre-training, the outperformance claims become tied to an artificial testbed rather than a general solution.
Authors: We acknowledge that the CC12M-based simulated splits provide a controlled testbed that may not fully capture the scale of interference from truly disjoint real-world corpora. This design choice enabled systematic, reproducible isolation of the two core challenges without confounding variables from disparate data pipelines. In the revised manuscript we will add an explicit limitations subsection that compares the induced domain shifts to those expected from sources such as LAION and discusses how the observed gains may translate. We will also include at least one additional merging scenario drawn from publicly available heterogeneous data where feasible. revision: partial
-
Referee: [Abstract, §3] Abstract and §3 (Method): The two proposed components (Shared-space Decomposition and Filtering; Alignment-guided Layer-wise Merging) are presented as directly targeting the stated challenges, yet no ablation isolates their individual contributions to the final merged projector, nor are the decomposition hyperparameters or layer-wise weight assignment rules shown to be robust across different projector architectures.
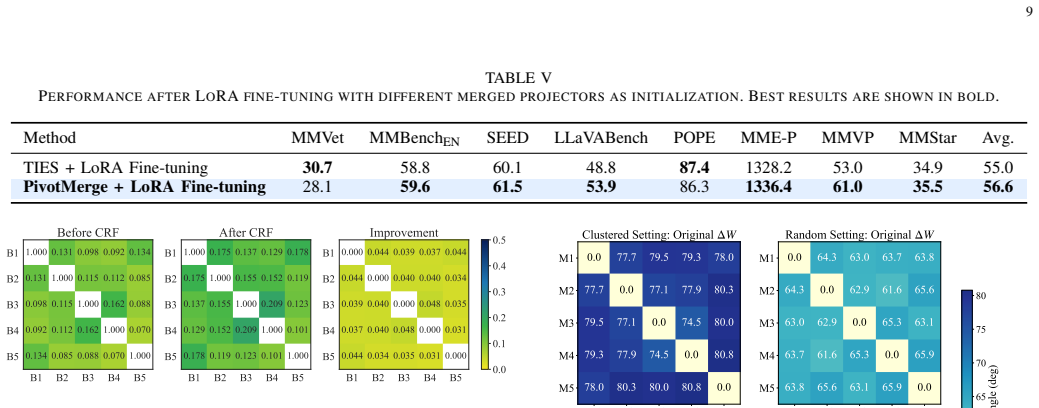
Authors: We agree that isolating the contribution of each component and verifying hyperparameter robustness are necessary. The revised experiments section will contain a dedicated ablation study that evaluates performance with Shared-space Decomposition and Filtering disabled, with Alignment-guided Layer-wise Merging disabled, and with the full PivotMerge pipeline. We will further report sensitivity results for the decomposition rank and filtering threshold, and will test the layer-wise weight assignment on at least one additional projector architecture to demonstrate robustness. revision: yes
Circularity Check
No circularity: method components are algorithmically defined from stated challenges, independent of evaluation construction
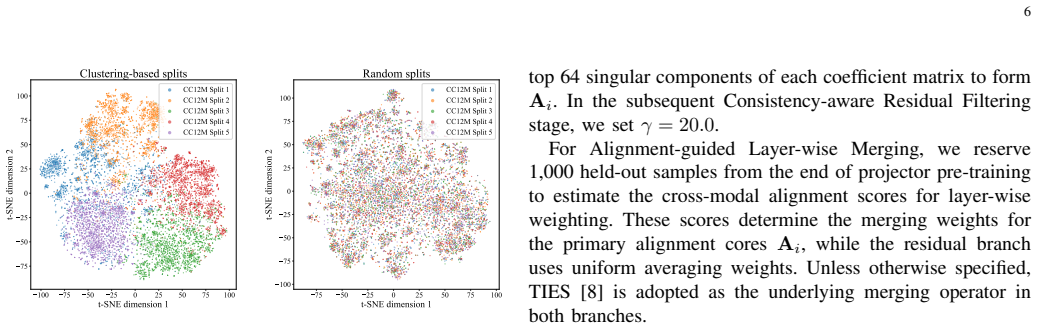
full rationale
The paper's core derivation proceeds from conceptual identification of two challenges (cross-domain parameter interference and layer-wise alignment contribution disparity) in post-alignment merging of cross-modal projectors. It then specifies two concrete algorithmic components—Shared-space Decomposition and Filtering (disentangling shared patterns and suppressing conflicts) and Alignment-guided Layer-wise Merging (assigning layer-specific weights)—without any equations or procedures that fit parameters to the CC12M scenarios or rename experimental outcomes as predictions. The CC12M-based scenarios are introduced only for subsequent evaluation, not as inputs that define or force the merging rules. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided text. The derivation chain therefore remains self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- layer-wise merging weights
- decomposition hyperparameters
axioms (2)
- domain assumption Different multimodal datasets induce complementary cross-modal alignment capabilities.
- domain assumption The core of MLLM pre-training lies in establishing effective cross-modal alignment.
Reference graph
Works this paper leans on
-
[1]
Loss surfaces, mode connectivity, and fast ensembling of dnns,
T. Garipov, P. Izmailov, D. Podoprikhin, D. P. Vetrov, and A. G. Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,” Advances in neural information processing systems, vol. 31, 2018
2018
-
[2]
Essentially no barriers in neural network energy landscape,
F. Draxler, K. Veschgini, M. Salmhofer, and F. Hamprecht, “Essentially no barriers in neural network energy landscape,” inInternational con- ference on machine learning. PMLR, 2018, pp. 1309–1318
2018
-
[3]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith et al., “Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,” inInternational conference on machine learning. PMLR, 2022, pp. 23 965–23 998
2022
-
[4]
Fusing finetuned models for better pretraining,
L. Choshen, E. Venezian, N. Slonim, and Y . Katz, “Fusing finetuned models for better pretraining,”arXiv preprint arXiv:2204.03044, 2022. 10
-
[5]
Adamerging: Adaptive model merging for multi-task learning.arXiv preprint arXiv:2310.02575,
E. Yang, Z. Wang, L. Shen, S. Liu, G. Guo, X. Wang, and D. Tao, “Adamerging: Adaptive model merging for multi-task learning,”arXiv preprint arXiv:2310.02575, 2023
-
[6]
arXiv preprint arXiv:2305.03053 , year=
G. Stoica, D. Bolya, J. Bjorner, P. Ramesh, T. Hearn, and J. Hoffman, “Zipit! merging models from different tasks without training,”arXiv preprint arXiv:2305.03053, 2023
-
[7]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Hajishirzi, and A. Farhadi, “Editing models with task arithmetic,” arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review arXiv 2022
-
[8]
Ties- merging: Resolving interference when merging models,
P. Yadav, D. Tam, L. Choshen, C. A. Raffel, and M. Bansal, “Ties- merging: Resolving interference when merging models,”Advances in Neural Information Processing Systems, vol. 36, pp. 7093–7115, 2023
2023
-
[9]
Task arithmetic in the tangent space: Improved editing of pre-trained models,
G. Ortiz-Jimenez, A. Favero, and P. Frossard, “Task arithmetic in the tangent space: Improved editing of pre-trained models,”Advances in Neural Information Processing Systems, vol. 36, pp. 66 727–66 754, 2023
2023
-
[10]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892– 34 916, 2023
2023
-
[11]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[12]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,”arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,”Advances in neural information processing systems, vol. 36, pp. 49 250–49 267, 2023
2023
-
[14]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
F. Li, R. Zhang, H. Zhang, Y . Zhang, B. Li, W. Li, Z. Ma, and C. Li, “Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models,”arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multi- modal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
An empirical study of multimodal model merging,
Y .-L. Sung, L. Li, K. Lin, Z. Gan, M. Bansal, and L. Wang, “An empirical study of multimodal model merging,”arXiv preprint arXiv:2304.14933, 2023
-
[18]
M. Shukor, C. Dancette, A. Rame, and M. Cord, “Unival: Unified model for image, video, audio and language tasks,”arXiv preprint arXiv:2307.16184, 2023
-
[19]
Model composition for multimodal large language models,
C. Chen, Y . Du, Z. Fang, Z. Wang, F. Luo, P. Li, M. Yan, J. Zhang, F. Huang, M. Sunet al., “Model composition for multimodal large language models,”arXiv preprint arXiv:2402.12750, 2024
-
[20]
Enhancing perception capabilities of multimodal llms with training-free fusion,
Z. Chen, J. Hu, Z. Deng, Y . Wang, B. Zhuang, and M. Tan, “Enhancing perception capabilities of multimodal llms with training-free fusion,” arXiv preprint arXiv:2412.01289, 2024
-
[21]
Y . Wei, R. Cheng, W. Jin, E. Yang, L. Shen, L. Hou, S. Du, C. Yuan, X. Cao, and D. Tao, “Unifying multimodal large language model capabilities and modalities via model merging,”arXiv preprint arXiv:2505.19892, 2025
-
[22]
Adamms: Model merging for heterogeneous multimodal large language models with unsupervised coefficient opti- mization,
Y . Du, X. Wang, C. Chen, J. Ye, Y . Wang, P. Li, M. Yan, J. Zhang, F. Huang, Z. Suiet al., “Adamms: Model merging for heterogeneous multimodal large language models with unsupervised coefficient opti- mization,” inProceedings of the Computer Vision and Pattern Recogni- tion Conference, 2025, pp. 9413–9422
2025
-
[23]
Robustmerge: Parameter-efficient model merging for mllms with direction robustness,
F. Zeng, H. Guo, F. Zhu, L. Shen, and H. Tang, “Robustmerge: Parameter-efficient model merging for mllms with direction robustness,” inThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems, 2025
2025
-
[24]
Uq- merge: Uncertainty guided multimodal large language model merging,
H. Qu, X. Zhao, J. Peng, K. Lee, B. Dariush, and T. Chen, “Uq- merge: Uncertainty guided multimodal large language model merging,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 1401–1417
2025
-
[25]
Where and what matters: Sensitivity-aware task vectors for many-shot multimodal in-context learning,
Z. Ma, C. Gou, Y . Hu, Y . Wang, B. Zhuang, and J. Cai, “Where and what matters: Sensitivity-aware task vectors for many-shot multimodal in-context learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 10, 2026, pp. 7892–7900
2026
-
[26]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liuet al., “Expanding performance boundaries of open- source multimodal models with model, data, and test-time scaling,” arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
Language models are super mario: Absorbing abilities from homologous models as a free lunch,
L. Yu, B. Yu, H. Yu, F. Huang, and Y . Li, “Language models are super mario: Absorbing abilities from homologous models as a free lunch,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[28]
K., Hayase, J., and Srinivasa, S
S. K. Ainsworth, J. Hayase, and S. Srinivasa, “Git re-basin: Merg- ing models modulo permutation symmetries, 2023,”URL https://arxiv. org/abs/2209.04836, 2022
-
[29]
Model merging with svd to tie the knots.arXiv preprint arXiv:2410.19735, 2024
G. Stoica, P. Ramesh, B. Ecsedi, L. Choshen, and J. Hoffman, “Model merging with svd to tie the knots,”arXiv preprint arXiv:2410.19735, 2024
-
[30]
Knowledge fusion of large language models, 2024
F. Wan, X. Huang, D. Cai, X. Quan, W. Bi, and S. Shi, “Knowledge fusion of large language models,”arXiv preprint arXiv:2401.10491, 2024
-
[31]
Fusechat: Knowl- edge fusion of chat models,
F. Wan, L. Zhong, Z. Yang, R. Chen, and X. Quan, “Fusechat: Knowl- edge fusion of chat models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 21 629– 21 653
2025
-
[32]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[33]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 26 296–26 306
2024
-
[34]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[35]
Vicuna: An open-source chatbot impressing gpt- 4 with 90%* chatgpt quality,
W.-L. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalez, I. Stoica, and E. P. Xing, “Vicuna: An open-source chatbot impressing gpt- 4 with 90%* chatgpt quality,” March 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[36]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts,
S. Changpinyo, P. Sharma, N. Ding, and R. Soricut, “Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3558–3568
2021
-
[37]
Visualizing data using t-sne
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of machine learning research, vol. 9, no. 11, 2008
2008
-
[38]
No task left behind: Isotropic model merging with common and task-specific subspaces,
D. Marczak, S. Magistri, S. Cygert, B. Twardowski, A. D. Bagdanov, and J. Van De Weijer, “No task left behind: Isotropic model merging with common and task-specific subspaces,”arXiv preprint arXiv:2502.04959, 2025
-
[39]
Task singular vectors: Reducing task interference in model merging,
A. A. Gargiulo, D. Crisostomi, M. S. Bucarelli, S. Scardapane, F. Sil- vestri, and E. Rodola, “Task singular vectors: Reducing task interference in model merging,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 18 695–18 705
2025
-
[40]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang, “Mm-vet: Evaluating large multimodal models for integrated capabilities,”arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Mmbench: Is your multi-modal model an all-around player?
Y . Liu, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liuet al., “Mmbench: Is your multi-modal model an all-around player?” inEuropean conference on computer vision. Springer, 2024, pp. 216–233
2024
-
[42]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
B. Li, R. Wang, G. Wang, Y . Ge, Y . Ge, and Y . Shan, “Seed-bench: Benchmarking multimodal llms with generative comprehension,”arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review arXiv 2023
-
[43]
Evaluating object hallucination in large vision-language models,
Y . Li, Y . Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 292–305
2023
-
[44]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sunet al., “Mme: A comprehensive evaluation benchmark for multimodal large language models,”arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review arXiv 2023
-
[45]
Eyes wide shut? exploring the visual shortcomings of multimodal llms,
S. Tong, Z. Liu, Y . Zhai, Y . Ma, Y . LeCun, and S. Xie, “Eyes wide shut? exploring the visual shortcomings of multimodal llms,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9568–9578
2024
-
[46]
Are we on the right way for evaluating large vision-language models?
L. Chen, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, J. Wang, Y . Qiao, D. Linet al., “Are we on the right way for evaluating large vision-language models?”Advances in Neural Information Processing Systems, vol. 37, pp. 27 056–27 087, 2024
2024
-
[47]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models,
H. Duan, J. Yang, Y . Qiao, X. Fang, L. Chen, Y . Liu, X. Dong, Y . Zang, P. Zhang, J. Wanget al., “Vlmevalkit: An open-source toolkit for evaluating large multi-modality models,” inProceedings of the 32nd ACM international conference on multimedia, 2024, pp. 11 198–11 201. 11 APPENDIXA IMPLEMENTATIONDETAILS A. Models We follow the default pre-training se...
2024
-
[48]
in all experiments. Under both the clustered and random settings, the projector is trained for one epoch with a batch size of 256, a learning rate of1×10 −3, cosine learning rate decay, a warmup ratio of 0.03, and a weight decay of 0. We use the AdamW optimizer and DeepSpeed ZeRO-2 for distributed training. B. Benchmarks The dataset sizes and task focuses...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.