Recognition: unknown
AutoPyVerifier: Learning Compact Executable Verifiers for Large Language Model Outputs
Pith reviewed 2026-05-08 11:28 UTC · model grok-4.3
The pith
AutoPyVerifier discovers compact sets of Python verifiers that approximate target objectives like output correctness by searching combinations of LLM-synthesized candidates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoPyVerifier synthesizes candidate Python verifier functions with an LLM and then navigates a directed acyclic graph whose nodes represent individual verifiers and whose edges represent dependencies, selecting a compact subset whose collective satisfaction best approximates the labeled target objective on a development set.
What carries the argument
DAG search over LLM-synthesized Python verifier candidates, which enumerates and scores combinations to isolate a minimal executable set that matches the target objective.
Load-bearing premise
A labeled development set of LLM outputs must exist for the target objective, and the DAG search must be able to locate a compact, generalizable collection of verifiers from the synthesized candidates.
What would settle it
On a fresh held-out set of LLM outputs with the same target labels, the discovered verifier set predicts the labels no better than the original LLM verifier or than chance.
Figures



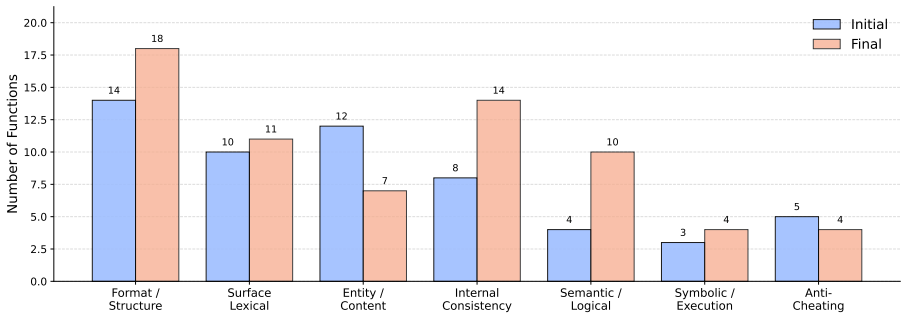


read the original abstract
Verification is becoming central to both reinforcement-learning-based training and inference-time control of large language models (LLMs). Yet current verifiers face a fundamental trade-off: LLM-based verifiers are expressive but hard to control and prone to error, while deterministic executable verifiers are reliable and interpretable but often limited in capability. We study the following question: given a development set of LLM outputs and labels for a target objective, such as correctness, can we automatically induce a minimal set of Python verifiers whose joint satisfaction closely matches that objective? We propose AutoPyVerifier, a framework that uses an LLM to synthesize candidate verifier functions and then refines them through search over a directed acyclic graph (DAG). By navigating the DAG, AutoPyVerifier systematically explores the space of deterministic executable verifiers and selects a compact verifier set whose joint satisfaction best approximates the target objective. Across mathematical reasoning, coding, function calling, and instruction-following benchmarks for several state-of-the-art LLMs, AutoPyVerifier improves target-objective prediction by up to 55.0 F1 points over the initial LLM-generated verifier sets. Additional analyses show that the most useful verification targets vary by benchmark and model, and that the DAG-based search shifts the learned verifier sets toward more structural and semantically grounded checks. We further show that exposing the discovered verifier set to an LLM as an external tool improves downstream accuracy by up to 17.0 points. We release our code
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoPyVerifier, a framework that uses an LLM to synthesize candidate Python verifier functions for LLM outputs (e.g., on correctness) and then applies DAG search over these candidates to select a compact set whose joint satisfaction best matches target labels on a development set. It claims up to 55 F1 point gains in target-objective prediction over initial LLM-generated verifiers across mathematical reasoning, coding, function calling, and instruction-following benchmarks for multiple LLMs, plus up to 17 point improvements in downstream LLM accuracy when the discovered verifiers are exposed as external tools. The work also analyzes variation in useful verification targets and shifts toward structural checks, and releases code.
Significance. If the central claims hold under proper held-out evaluation, the method offers a practical bridge between expressive but unreliable LLM verifiers and reliable but limited deterministic ones, with potential impact on RL-based training and inference-time control of LLMs. The code release supports reproducibility and is a clear strength. The downstream tool-use results provide indirect utility evidence, but overall significance hinges on demonstrating that the compact verifier sets generalize beyond the data used for selection.
major comments (2)
- [Experimental results and evaluation protocol] Evaluation protocol for the headline 55 F1 claim: the DAG search directly optimizes verifier selection to match target labels on the development set. The manuscript must explicitly state (in the experimental setup and results sections) whether the reported F1 scores for target-objective prediction are computed on a held-out test partition disjoint from this development set. If F1 is measured on the same data, the gain is expected by construction and does not establish generalizability of the compact verifier sets. This is load-bearing for the central claim.
- [Downstream task experiments] Downstream accuracy results: the up to 17 point improvement when exposing the verifier set as an LLM tool is reported, but the manuscript should detail the integration mechanism, control conditions (e.g., number of tools, prompt formatting), and whether the improvement is measured on the same benchmarks or new held-out instances. Without these, it is difficult to attribute gains specifically to the discovered verifiers versus other factors.
minor comments (3)
- [Abstract and §1] The abstract and introduction could more clearly distinguish the development set (used for synthesis and DAG search) from any test sets used for final reporting.
- [Method] Notation for the DAG nodes, edges, and joint satisfaction function should be defined more explicitly with an equation or pseudocode early in the method section.
- [Results tables] Tables reporting per-benchmark and per-model F1 scores would benefit from including the number of verifiers in the selected set and a baseline of random or empty verifier sets for context.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment below and describe the revisions we will make to improve clarity and strengthen the evaluation.
read point-by-point responses
-
Referee: [Experimental results and evaluation protocol] Evaluation protocol for the headline 55 F1 claim: the DAG search directly optimizes verifier selection to match target labels on the development set. The manuscript must explicitly state (in the experimental setup and results sections) whether the reported F1 scores for target-objective prediction are computed on a held-out test partition disjoint from this development set. If F1 is measured on the same data, the gain is expected by construction and does not establish generalizability of the compact verifier sets. This is load-bearing for the central claim.
Authors: We agree that this point is load-bearing and that the current manuscript does not explicitly state the evaluation split. The reported F1 scores are computed on the same development set used for DAG search, which shows that the search can recover compact verifier sets approximating the target labels but does not demonstrate generalization. We will revise the experimental setup and results sections to clearly describe the data partitioning and add held-out test-set F1 results (using a disjoint partition) to support claims of generalizability. revision: yes
-
Referee: [Downstream task experiments] Downstream accuracy results: the up to 17 point improvement when exposing the verifier set as an LLM tool is reported, but the manuscript should detail the integration mechanism, control conditions (e.g., number of tools, prompt formatting), and whether the improvement is measured on the same benchmarks or new held-out instances. Without these, it is difficult to attribute gains specifically to the discovered verifiers versus other factors.
Authors: We will expand the downstream experiments section to describe the exact integration mechanism (how verifier functions are registered and called as tools), the prompt templates used, and control conditions that hold the number of tools and overall prompt structure constant. We will also clarify whether accuracy gains are measured on held-out instances or the same benchmark splits and report additional controls to isolate the contribution of the discovered verifiers. revision: yes
Circularity Check
DAG search optimizes verifier selection directly against dev-set labels, rendering F1 gains in target-objective prediction expected by construction
specific steps
-
fitted input called prediction
[Abstract]
"We propose AutoPyVerifier, a framework that uses an LLM to synthesize candidate verifier functions and then refines them through search over a directed acyclic graph (DAG). By navigating the DAG, AutoPyVerifier systematically explores the space of deterministic executable verifiers and selects a compact verifier set whose joint satisfaction best approximates the target objective. Across mathematical reasoning, coding, function calling, and instruction-following benchmarks for several state-of-the-art LLMs, AutoPyVerifier improves target-objective prediction by up to 55.0 F1 points over the in"
The DAG search is defined to choose the verifier set that best approximates the target objective on the development set. Reporting an F1 improvement in 'target-objective prediction' over the initial LLM-generated sets therefore measures the success of the optimization itself on the data used for selection, rather than an independent prediction on held-out outputs.
full rationale
The framework synthesizes candidates then explicitly searches the DAG to select the compact set whose joint satisfaction best matches the target labels on the given development set. The reported up to 55 F1 improvement in target-objective prediction is therefore the direct outcome of this optimization when evaluated on the same data used for selection. While the downstream accuracy lift (using verifiers as tools) supplies independent evidence of utility, the primary prediction claim reduces to a fitted result. No self-citations or other patterns identified.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A labeled development set of LLM outputs for the target objective is available
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [3]
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review arXiv 2025
- [5]
-
[6]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, and 1 others. 2024. A survey on llm-as-a-judge. The Innovation
2024
-
[7]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633--638
2025
-
[8]
Beyond oracle: Verifier-supervision for instruction hierarchy in reasoning and instruction-tuned llms
Sian-Yao Huang, Li-Hsien Chang, Che-Yu Lin, and Cheng-Lin Yang. Beyond oracle: Verifier-supervision for instruction hierarchy in reasoning and instruction-tuned llms. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[9]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974
work page internal anchor Pith review arXiv 2024
-
[10]
Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. 2024. When can llms actually correct their own mistakes? a critical survey of self-correction of llms. Transactions of the Association for Computational Linguistics, 12:1417--1440
2024
- [11]
- [12]
-
[13]
Yukyung Lee, Joonghoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, and Najoung Kim. 2025 b . Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15782--15809
2025
- [14]
-
[15]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. In The twelfth international conference on learning representations
2023
- [16]
-
[17]
Zhiyuan Ma, Jiayu Liu, Xianzhen Luo, Zhenya Huang, Qingfu Zhu, and Wanxiang Che. 2025. Advancing tool-augmented large language models via meta-verification and reflection learning. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pages 2078--2089
2025
-
[18]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and 1 others. 2023. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems, 36:46534--46594
2023
- [19]
-
[20]
Yu Pei, Yongping Du, and Xingnan Jin. 2025. Fover: First-order logic verification for natural language reasoning. Transactions of the Association for Computational Linguistics, 13:1340--1359
2025
- [21]
- [22]
-
[23]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 others. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314
work page internal anchor Pith review arXiv 2024
- [25]
-
[26]
Bosi Wen, Pei Ke, Xiaotao Gu, Lindong Wu, Hao Huang, Jinfeng Zhou, Wenchuang Li, Binxin Hu, Wendy Gao, Jiaxin Xu, and 1 others. 2024. Benchmarking complex instruction-following with multiple constraints composition. Advances in Neural Information Processing Systems, 37:137610--137645
2024
-
[27]
Jialin Yang, Dongfu Jiang, Lipeng He, Sherman Siu, Yuxuan Zhang, Disen Liao, Zhuofeng Li, Huaye Zeng, Yiming Jia, Haozhe Wang, and 1 others. 2025. Structeval: Benchmarking llms' capabilities to generate structural outputs. arXiv preprint arXiv:2505.20139
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations
2022
-
[29]
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. 2026 a . Memskill: Learning and evolving memory skills for self-evolving agents. arXiv preprint arXiv:2602.02474
work page internal anchor Pith review arXiv 2026
-
[30]
Jiazheng Zhang, Ziche Fu, Zhiheng Xi, Wenqing Jing, Mingxu Chai, Wei He, Guoqiang Zhang, Chenghao Fan, Chenxin An, Wenxiang Chen, and 1 others. 2026 b . Agentv-rl: Scaling reward modeling with agentic verifier. arXiv preprint arXiv:2604.16004
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, and 1 others. 2025 a . Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618
work page internal anchor Pith review arXiv 2025
-
[32]
Tao Zhang, Chenglin Zhu, Yanjun Shen, Wenjing Luo, Yan Zhang, Hao Liang, Fan Yang, Mingan Lin, Yujing Qiao, Weipeng Chen, and 1 others. 2025 b . Cfbench: A comprehensive constraints-following benchmark for llms. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32926--32944
2025
- [33]
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.