Recognition: unknown
AgentV-RL: Scaling Reward Modeling with Agentic Verifier
Pith reviewed 2026-05-10 08:30 UTC · model grok-4.3
The pith
AgentV-RL introduces bidirectional forward-backward agents and RL-driven tool use to improve LLM verifiers, with a 4B model beating prior outcome reward models by 25.2%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
our 4B variant surpasses state-of-the-art ORMs by 25.2%, positioning it as a promising paradigm for agentic reward modeling.
Load-bearing premise
That the bidirectional forward-backward agent process combined with RL will reliably reduce false positives and error propagation in complex domains without introducing new failure modes from agent coordination or tool misuse.
Figures



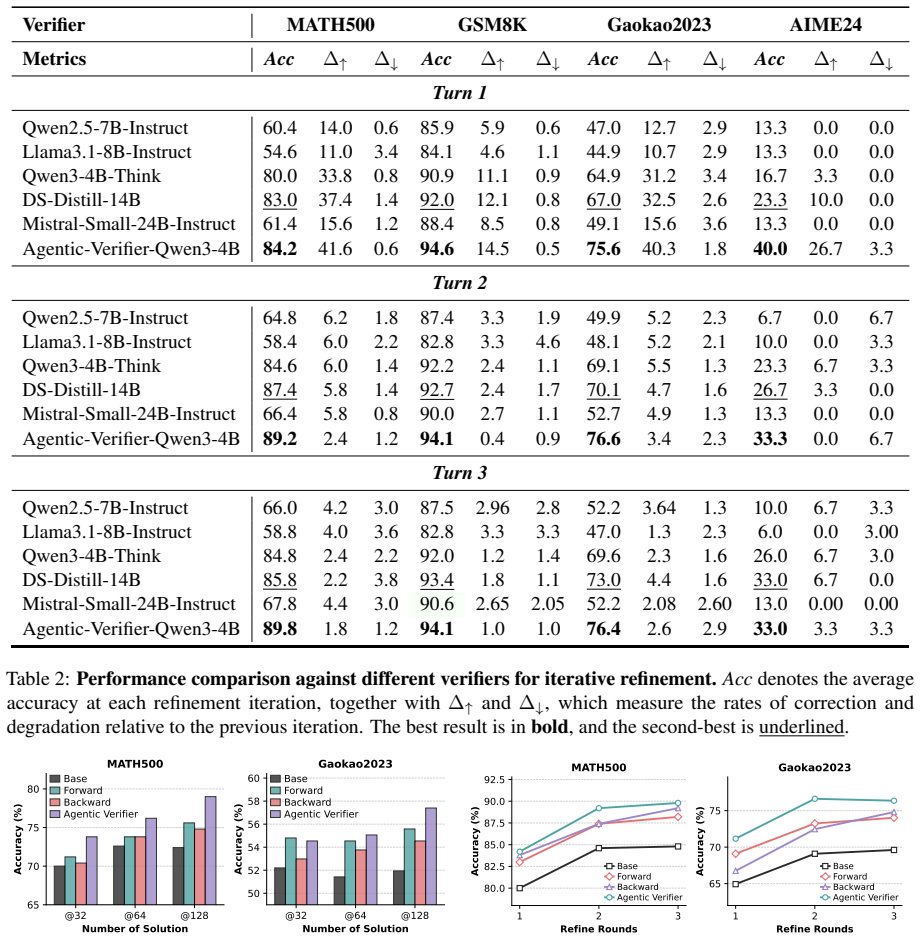
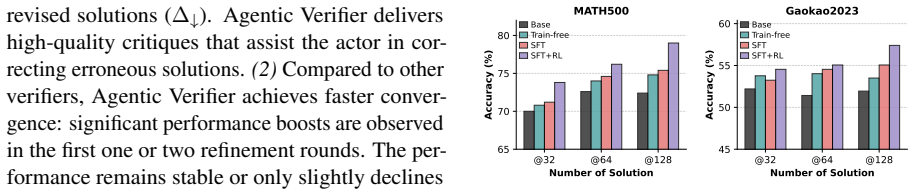

read the original abstract
Verifiers have been demonstrated to enhance LLM reasoning via test-time scaling (TTS). Yet, they face significant challenges in complex domains. Error propagation from incorrect intermediate reasoning can lead to false positives for seemingly plausible solutions, while lacking external grounding makes verifiers unreliable on computation or knowledge-intensive tasks. To address these challenges, we propose Agentic Verifier, a framework that transforms reward modeling into a multi-turn, tool-augmented deliberative process. We introduce complementary forward and backward agents: one traces solutions from premises to conclusions, while the other re-checks conclusions against their underlying premises. This bidirectional process enables a comprehensive, reliable, and interpretable assessment of solutions. To facilitate practical deployment, we propose AgentV-RL. Through proactive exploration and reinforcement learning, the verifier autonomously interleaves tool-use with internal reasoning. Extensive experiments show that Agentic Verifier yields consistent performance gains under both parallel and sequential TTS. Notably, our 4B variant surpasses state-of-the-art ORMs by 25.2%, positioning it as a promising paradigm for agentic reward modeling.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Agentic Verifier
no independent evidence
-
Forward agent
no independent evidence
-
Backward agent
no independent evidence
-
AgentV-RL
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Entropy Polarity in Reinforcement Fine-Tuning: Direction, Asymmetry, and Control
Entropy polarity from a first-order entropy change approximation enables Polarity-Aware Policy Optimization (PAPO) that preserves complementary polarity branches and outperforms baselines on math and agentic RL fine-t...
-
AutoPyVerifier: Learning Compact Executable Verifiers for Large Language Model Outputs
AutoPyVerifier learns compact sets of executable Python verifiers from labeled LLM outputs via LLM synthesis and DAG search, improving objective prediction by up to 55 F1 points and downstream LLM accuracy by up to 17 points.
Reference graph
Works this paper leans on
-
[1]
Training verifiers to solve math word prob- lems.CoRR, abs/2110.14168. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, and 6 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit re- wards.Preprint, arXiv:2502.01456. Google DeepMind. 2025. Advanced version of gem- ini with deep think officially achieves gold-medal standard at the international mathematical olympiad. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao ...
work page internal anchor Pith review arXiv 2025
-
[3]
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Guanting Dong, Licheng Bao, Zhongyuan Wang, Kangzhi Zhao, Xiaoxi Li, Jiajie Jin, Jinghan Yang, Hangyu Mao, Fuzheng Zhang, Kun Gai, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. 2025a. Agentic entropy-balanced policy optimiza- tion.CoRR...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2507.01352 , year=
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxi- ang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. 2025a. Skywork-reward-v2: Scaling preference ...
-
[5]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: an open-source LLM reinforcement learning system at scale.CoRR, abs/2503.14476. Lifan Yuan, Wendi Li, Huayu Chen, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Free process rewards without process labels. InForty-second International Conference on Ma- chine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025. OpenReview.net. Jiazheng Zhang, Wenqing Jing, Zizhuo Zhang, Zhiheng Xi, Shihan Dou, Rongxiang Weng, Jiahuan Li, Jin- gang Wang, Mingxu Chai, Shibo Hong, Tao Gui, and Qi Zhang. 2025a. Two minds bett...
-
[7]
write a concise verification text that inspects the given solution step-by-step (do not re-solve unless a single local derivation is trivially needed)
-
[8]
decide whether the solution correctly solves the problem
-
[9]
output a boolean verdict. You must prioritize checking the original solution via paper checks: legality of algebraic steps, substitution mentally for proposed roots, domain and edge cases, theorem prerequisites, and consistency of the final statement with intermediate steps. Do NOT produce a fresh full solution when the provided reasoning is wrong or inco...
-
[10]
Restate the step you are verifying and reason carefully about it
-
[11]
Check whether this step is logically consistent with all previously verified steps
-
[12]
The system will execute it and return the results for you to continue in the next turn
If a calculation or detailed check is needed, output a <python>...</python> block after reasoning and stop your response. The system will execute it and return the results for you to continue in the next turn. **Rules for <python> blocks:** - Use only necessary imports and print() statements for outputs. - Do not use OS commands, file I/O, input(), or net...
2025
-
[13]
if r is a root, then 1 13r is also a root
GSM8K and Gaokao2023 are not included in any declared source dataset. While MATH appears in Light-R1 (a component of AReaL-boba-106k), it explicitly removes MATH500 from training. There- fore, we do not find direct overlap between the re- ported evaluation benchmarks and the training data used in this work. D Case Study This section presents representativ...
-
[14]
As a result, later deductions (including the step that introduces a denominator asserted to be 0) do not follow from valid polynomial identities
For P(x) =x 10+(13x−1) 10, the coeffi- cients imply the sum of roots is 10·139 1+1310 ̸= 0. As a result, later deductions (including the step that introduces a denominator asserted to be 0) do not follow from valid polynomial identities. Since the key structural claims fail, the final conclusion0is not supported. </review> <answer>false</answer> D.3 Backw...
-
[15]
If the final value is correct, then the solution must have obtained correct values ofa and b
For this to be justified, several dependencies must hold in reverse order. If the final value is correct, then the solution must have obtained correct values ofa and b. Those values must satisfy a valid coefficient- matching system. And that system must come from a correct expansion of (3t2 + 5t+a)(4t 2 +bt−2). So the backward checks are: (1) expansion co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.