Recognition: unknown
Oracle Noise: Faster Semantic Spherical Alignment for Interpretable Latent Optimization
Pith reviewed 2026-05-08 06:53 UTC · model grok-4.3
The pith
Updating initial noise along a hypersphere preserves the Gaussian distribution and speeds up prompt alignment in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
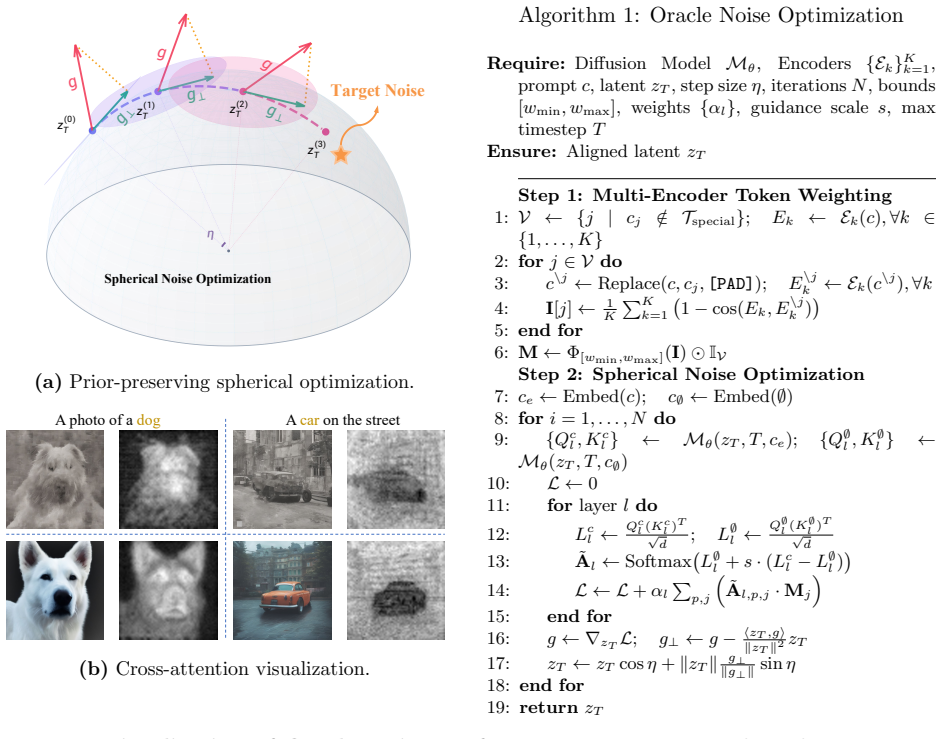
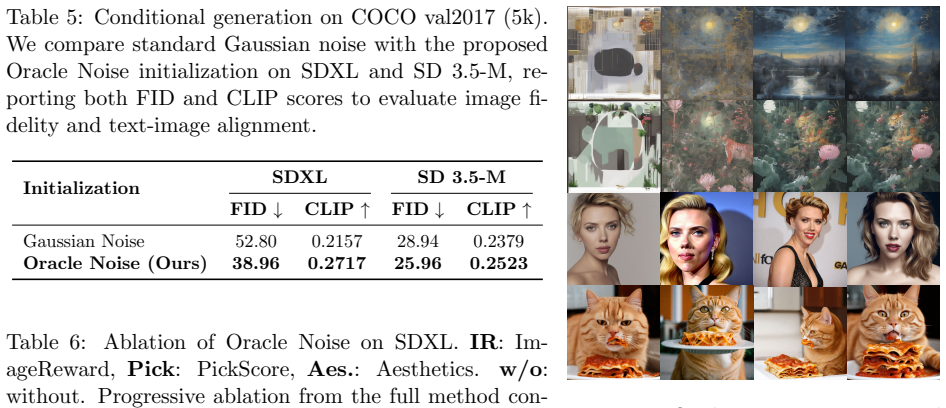
Oracle Noise reframes noise initialization as semantic optimization strictly confined to a Riemannian hypersphere. Spherical updates mathematically hold the noise norm constant, thereby preserving the standard Gaussian prior and eliminating inflation-induced artifacts. Direct selection of high-impact prompt words routes the optimization without external parsers or black-box reward models.
What carries the argument
The Riemannian hypersphere constraint on noise vectors, which enforces constant norm during updates to keep the Gaussian distribution intact while allowing larger steps.
If this is right
- Convergence occurs inside a strict 2-second budget.
- Euclidean-induced degradation such as color over-saturation is eliminated.
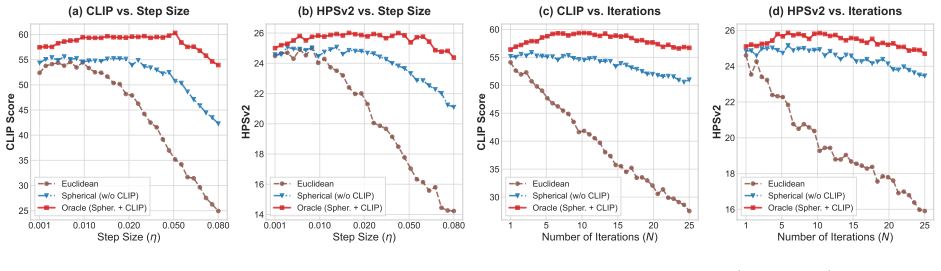
- Human preference scores on HPSv2 and ImageReward improve.
- CLIP-based semantic alignment rises while sample diversity is maintained.
Where Pith is reading between the lines
- The same constant-norm spherical update rule could be applied to other latent spaces in generative models where distribution shift is a problem.
- Direct word-impact selection may reduce reliance on large external models for prompt engineering in general.
Load-bearing premise
Selecting the most impactful structural words directly from the prompt is sufficient to route optimization energy without external parsers or reward-hacking failures.
What would settle it
Run the spherical optimizer and check whether the noise vector norm remains exactly constant across iterations while Euclidean baselines show inflation and corresponding artifacts.
Figures


read the original abstract
Text-to-image diffusion models have achieved remarkable generative capabilities, yet accurately aligning complex textual prompts with synthesized layouts remains an ongoing challenge. In these models, the initial Gaussian noise acts as a critical structural seed dictating the macroscopic layout. Recent online optimization and search methods attempt to refine this noise to enhance text-image alignment. However, relying on unconstrained Euclidean gradient ascent mathematically inflates the latent norm and destroys the standard Gaussian prior, causing severe visual artifacts like color over-saturation. Furthermore, these methods suffer from inefficient semantic routing and easily fall into the ``reward hacking'' trap of external proxy models. To address these intertwined bottlenecks, we propose Oracle Noise, a zero-shot framework reframing noise initialization as semantic-driven optimization strictly confined to a Riemannian hypersphere. Instead of relying on complex external parsers, we directly identify the most impactful structural words in the prompt to efficiently route optimization energy. By updating the noise strictly along a spherical path, we mathematically preserve the original Gaussian distribution. This geometric constraint eliminates norm inflation and unlocks aggressive step sizes for rapid convergence. Extensive experiments demonstrate that Oracle Noise significantly accelerates semantic alignment and achieves superior aesthetics without black-box models. It completely mitigates Euclidean-induced degradation, establishing state-of-the-art performance across human preference metrics (e.g., HPSv2, ImageReward), semantic alignment (CLIP Score), and sample diversity, all within a strict 2-second optimization budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Oracle Noise, a zero-shot framework that reframes initial noise optimization in text-to-image diffusion models as semantic-driven updates strictly on a Riemannian hypersphere. It claims this geometrically preserves the original Gaussian distribution (eliminating norm inflation and artifacts), directly identifies high-impact prompt words without external parsers, enables aggressive step sizes, and yields superior results on human preference (HPSv2, ImageReward), semantic alignment (CLIP Score), and diversity metrics within a 2-second budget.
Significance. If the spherical preservation property can be rigorously shown and the reported gains hold under ablations, the work would supply a principled, interpretable alternative to unconstrained Euclidean latent optimization, potentially reducing artifacts and reward-hacking issues in diffusion-based generation while remaining computationally lightweight.
major comments (2)
- [Abstract] Abstract: The load-bearing claim that 'updating the noise strictly along a spherical path, we mathematically preserve the original Gaussian distribution' is not supported by standard properties of the hypersphere. A sample from N(0,I) has independent chi-distributed norm and uniform direction; fixing the norm per trajectory while applying semantic gradient steps on the sphere yields the original norm marginal but a non-uniform directional distribution, violating isotropy. A derivation or proof addressing this distinction is required in the methods or theory section.
- [Experimental Results] Experimental Results: The abstract asserts state-of-the-art performance on HPSv2, ImageReward, and CLIP Score with diversity gains, yet provides no baseline comparisons, ablation on the structural-word identification step, sample counts, or statistical tests. Without these, it is impossible to isolate the contribution of the spherical constraint from other implementation details.
minor comments (2)
- [Abstract] The abstract refers to 'interpretable latent optimization' and 'Oracle Noise' without defining the source of interpretability or the meaning of 'Oracle' in the framework name.
- Ensure acronyms (HPSv2, CLIP) are expanded on first use and that the 2-second budget is contextualized against wall-clock times of competing methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify both the theoretical framing and experimental rigor of our work. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that 'updating the noise strictly along a spherical path, we mathematically preserve the original Gaussian distribution' is not supported by standard properties of the hypersphere. A sample from N(0,I) has independent chi-distributed norm and uniform direction; fixing the norm per trajectory while applying semantic gradient steps on the sphere yields the original norm marginal but a non-uniform directional distribution, violating isotropy. A derivation or proof addressing this distinction is required in the methods or theory section.
Authors: We appreciate the referee's precise mathematical observation. The original phrasing in the abstract was intended to highlight that spherical updates keep each noise vector's Euclidean norm fixed to its initial chi-distributed value, thereby eliminating the norm inflation and resulting artifacts that arise under unconstrained Euclidean ascent. However, we agree that this does not preserve the full isotropic Gaussian distribution, as the directional component becomes non-uniform under semantic guidance. In the revised manuscript we will (i) replace the claim with a more accurate statement that the method preserves the per-sample norm marginal while optimizing direction on the hypersphere, (ii) add a short derivation in the Methods section showing that any update tangent to the sphere of radius ||x_0|| leaves ||x|| invariant, and (iii) explicitly note the distinction between norm preservation and full distributional invariance. These changes directly address the isotropy concern. revision: yes
-
Referee: [Experimental Results] Experimental Results: The abstract asserts state-of-the-art performance on HPSv2, ImageReward, and CLIP Score with diversity gains, yet provides no baseline comparisons, ablation on the structural-word identification step, sample counts, or statistical tests. Without these, it is impossible to isolate the contribution of the spherical constraint from other implementation details.
Authors: We concur that the current presentation does not sufficiently isolate the spherical constraint's contribution. In the revised experimental section we will add: (1) direct quantitative comparisons against the Euclidean optimization baseline using identical optimization budgets and prompts, (2) an ablation that disables the structural-word identification step while retaining spherical updates, (3) the exact number of evaluation samples and prompts used for each metric, and (4) statistical significance measures (e.g., 95% confidence intervals or paired t-tests) for the reported gains on HPSv2, ImageReward, CLIP Score, and diversity. These additions will allow readers to attribute performance differences more clearly to the Riemannian constraint. revision: yes
Circularity Check
No circularity in the derivation chain
full rationale
The paper's core geometric claim rests on standard properties of the hypersphere and Gaussian distributions applied to noise updates, without any reduction of results to inputs by construction. No equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text that would make the preservation statement tautological. The structural word identification and spherical constraint are introduced as direct methodological choices rather than derived from prior self-referential steps, leaving the derivation self-contained against external geometric benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Noise updates confined to the Riemannian hypersphere preserve the original Gaussian distribution.
invented entities (1)
-
Oracle Noise framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A noise is worth diffusion guidance, 2024
Donghoon Ahn, Jiwon Kang, Sanghyun Lee, Jaewon Min, Minjae Kim, Wooseok Jang, Hy- oungwon Cho, Sayak Paul, SeonHwa Kim, Eunju Cha, Kyong Hwan Jin, and Seungryong Kim. A noise is worth diffusion guidance, 2024. URLhttps://arxiv.org/abs/2412.03895
-
[2]
Sato: Stable text-to-motion framework
Wenshuo chen, Hongru Xiao, Erhang Zhang, Lijie Hu, Lei Wang, Mengyuan Liu, and Chen Chen. Sato: Stable text-to-motion framework. InProceedings of the 32nd ACM Inter- national Conference on Multimedia, MM ’24, page 6989–6997. ACM, October 2024. doi: 10.1145/3664647.3681034. URLhttp://dx.doi.org/10.1145/3664647.3681034
-
[3]
Wenshuo Chen, Haosen Li, Shaofeng Liang, Lei Wang, Haozhe Jia, Kaishen Yuan, Jieming Wu, Bowen Tian, and Yutao Yue. Polaris: Projection-orthogonal least squares for robust and adaptive inversion in diffusion models, 2025. URLhttps://arxiv.org/abs/2512.00369
-
[4]
Ant: Adaptive neural temporal- aware text-to-motion model
Wenshuo Chen, Kuimou Yu, Jia Haozhe, Kaishen Yuan, Zexu Huang, Bowen Tian, Songning Lai, Hongru Xiao, Erhang Zhang, Lei Wang, and Yutao Yue. Ant: Adaptive neural temporal- 19 aware text-to-motion model. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 9852–9861. ACM, October 2025. doi: 10.1145/3746027.3755168. URLhttp://d...
-
[5]
Hyper- spherical variational auto-encoders.arXiv preprint arXiv:1804.00891, 2018
Tim R. Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M. Tomczak. Hy- perspherical variational auto-encoders, 2022. URLhttps://arxiv.org/abs/1804.00891
-
[6]
Harmonizing geometry and uncertainty: Diffusion with hyperspheres, 2025
Muskan Dosi, Chiranjeev Chiranjeev, Kartik Thakral, Mayank Vatsa, and Richa Singh. Harmonizing geometry and uncertainty: Diffusion with hyperspheres, 2025. URL https://arxiv.org/abs/2506.10576
-
[7]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨ uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rom- bach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URL https://arxiv.org/abs/...
work page internal anchor Pith review arXiv 2024
-
[8]
Reno: Enhancing one-step text-to-image models through reward-based noise optimization,
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. Reno: Enhancing one-step text-to-image models through reward-based noise optimization,
- [9]
-
[10]
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning, 2023. URLhttps://arxiv.org/abs/2210.02410
-
[11]
GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, 2023
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment, 2023. URL https://arxiv.org/abs/2310.11513
-
[12]
Vbench: Comprehensive benchmark suite for video generative models
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffusion models via initial noise optimization. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9380–9389, 2024. doi: 10.1109/CVPR52733.2024.00896
-
[13]
Initno: Boosting text-to-image diffusion models via initial noise optimization, 2024
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffusion models via initial noise optimization, 2024. URL https://arxiv.org/abs/2404.04650
-
[14]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control, 2022. URL https://arxiv.org/abs/2208.01626
work page internal anchor Pith review arXiv 2022
-
[15]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. URL https://arxiv.org/abs/2207.12598
work page internal anchor Pith review arXiv 2022
-
[16]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020. URLhttps://arxiv.org/abs/2006.11239
work page internal anchor Pith review arXiv 2020
-
[17]
Blue noise for diffusion models, 2024
Xingchang Huang, Corentin Sala¨ un, Cristina Vasconcelos, Christian Theobalt, Cen- giz ¨Oztireli, and Gurprit Singh. Blue noise for diffusion models, 2024. URL https://arxiv.org/abs/2402.04930. 20
-
[18]
Physics-informed representation alignment for sparse radio-map reconstruction, 2025
Haozhe Jia, Wenshuo Chen, Zhihui Huang, Lei Wang, Hongru Xiao, Nanqian Jia, Keming Wu, Songning Lai, Bowen Tian, and Yutao Yue. Physics-informed representation alignment for sparse radio-map reconstruction, 2025. URLhttps://arxiv.org/abs/2501.19160
-
[19]
Antithetic noise in diffusion models, 2026
Jing Jia, Sifan Liu, Bowen Song, Wei Yuan, Liyue Shen, and Guanyang Wang. Antithetic noise in diffusion models, 2026. URLhttps://arxiv.org/abs/2506.06185
-
[20]
Pick-a-pic: An open dataset of user preferences for text-to-image generation, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation, 2023. URL https://arxiv.org/abs/2305.01569
-
[21]
Reinforced attention learning, 2026
Bangzheng Li, Jianmo Ni, Chen Qu, Ian Miao, Liu Yang, Xingyu Fu, Muhao Chen, and Derek Zhiyuan Cheng. Reinforced attention learning, 2026. URL https://arxiv.org/abs/2602.04884
-
[22]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Doll´ ar. Microsoft coco: Com- mon objects in context, 2015. URLhttps://arxiv.org/abs/1405.0312
work page internal anchor Pith review arXiv 2015
-
[23]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review arXiv 2023
-
[24]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022. URLhttps://arxiv.org/abs/2209.03003
work page internal anchor Pith review arXiv 2022
-
[25]
Inference-time scaling for diffusion models beyond scaling denoising steps,
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, and Saining Xie. Inference- time scaling for diffusion models beyond scaling denoising steps, 2025. URL https://arxiv.org/abs/2501.09732
-
[26]
Mang Ning, Mingxiao Li, Jianlin Su, Haozhe Jia, Lanmiao Liu, Martin Beneˇ s, Wenshuo Chen, Albert Ali Salah, and Itir Onal Ertugrul. Dctdiff: Intriguing properties of image generative modeling in the dct space, 2025. URLhttps://arxiv.org/abs/2412.15032
-
[27]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https://arxiv.org/abs/2212.09748
work page internal anchor Pith review arXiv 2023
-
[28]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨ uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review arXiv 2023
-
[29]
arXiv preprint arXiv:2407.14041 , year=
Zipeng Qi, Lichen Bai, Haoyi Xiong, and Zeke Xie. Not all noises are created equally:diffusion noise selection and optimization, 2024. URLhttps://arxiv.org/abs/2407.14041
-
[30]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review arXiv 2021
-
[31]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Om- mer. High-resolution image synthesis with latent diffusion models, 2022. URL https://arxiv.org/abs/2112.10752. 21
work page Pith review arXiv 2022
-
[32]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems, 35:36479–36494, 2022
2022
-
[33]
arXiv preprint arXiv:2311.17042 (2023)
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation, 2023. URLhttps://arxiv.org/abs/2311.17042
-
[34]
LAION-5B: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmar- czyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text model...
work page internal anchor Pith review arXiv 2022
-
[35]
pytorch-fid: FID Score for PyTorch
Maximilian Seitzer. pytorch-fid: FID Score for PyTorch. https://github.com/mseitzer/pytorch-fid, August 2020. Version 0.3.0
2020
-
[36]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URLhttps://arxiv.org/abs/2010.02502
work page internal anchor Pith review arXiv 2022
-
[37]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021. URLhttps://arxiv.org/abs/2011.13456
work page internal anchor Pith review arXiv 2021
- [38]
-
[39]
Zeroth-order optimization meets human feedback: Provable learning via ranking oracles, 2024
Zhiwei Tang, Dmitry Rybin, and Tsung-Hui Chang. Zeroth-order optimization meets human feedback: Provable learning via ranking oracles, 2024. URL https://arxiv.org/abs/2303.03751
-
[40]
Plug-and-play diffusion features for text-driven image-to-image translation, 2022
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation, 2022. URLhttps://arxiv.org/abs/2211.12572
-
[41]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv.org/abs/1706.03762
work page internal anchor Pith review arXiv 2023
-
[42]
Cambridge Series in Statistical and Probabilistic Mathematics
Roman Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2018
2018
-
[43]
The silent as- sistant: Noisequery as implicit guidance for goal-driven image generation, 2025
Ruoyu Wang, Huayang Huang, Ye Zhu, Olga Russakovsky, and Yu Wu. The silent as- sistant: Noisequery as implicit guidance for goal-driven image generation, 2025. URL https://arxiv.org/abs/2412.05101
-
[44]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text- to-image synthesis.arXiv preprint arXiv:2306.09341, 2023. 22
work page internal anchor Pith review arXiv 2023
-
[45]
Imagereward: Learning and evaluating human preferences for text-to-image generation,
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation,
- [46]
-
[47]
Co- emogen: Towards semantically-coherent and scalable emotional image content generation,
Kaishen Yuan, Yuting Zhang, Shang Gao, Yijie Zhu, Wenshuo Chen, and Yutao Yue. Co- emogen: Towards semantically-coherent and scalable emotional image content generation,
- [48]
-
[49]
Golden noise for diffusion models: A learning framework
Zikai Zhou, Shitong Shao, Lichen Bai, Shufei Zhang, Zhiqiang Xu, Bo Han, and Zeke Xie. Golden noise for diffusion models: A learning framework, 2025. URL https://arxiv.org/abs/2411.09502. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.