Recognition: unknown
Why AI Harms Can't Be Fixed One Identity at a Time: What 5300 Incident Reports Reveal About Intersectionality
Pith reviewed 2026-05-08 01:23 UTC · model grok-4.3
The pith
AI harms arise from intersections of identity categories rather than isolated ones, with specific combinations amplifying harm up to three times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
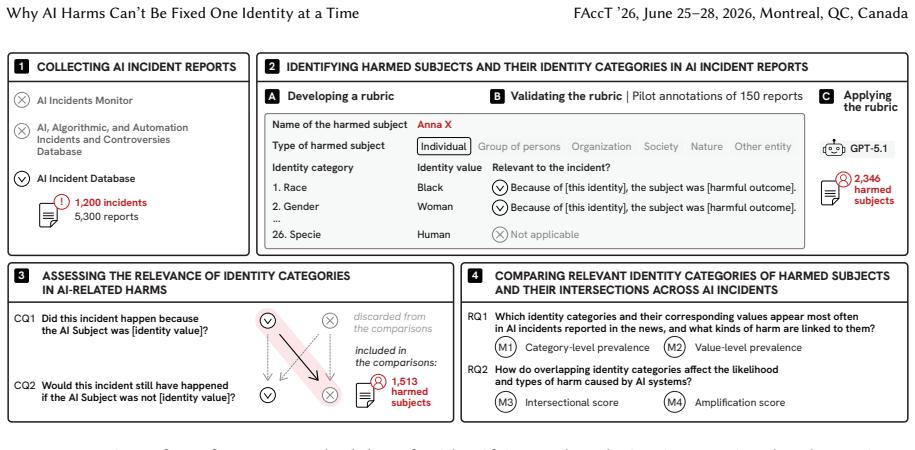
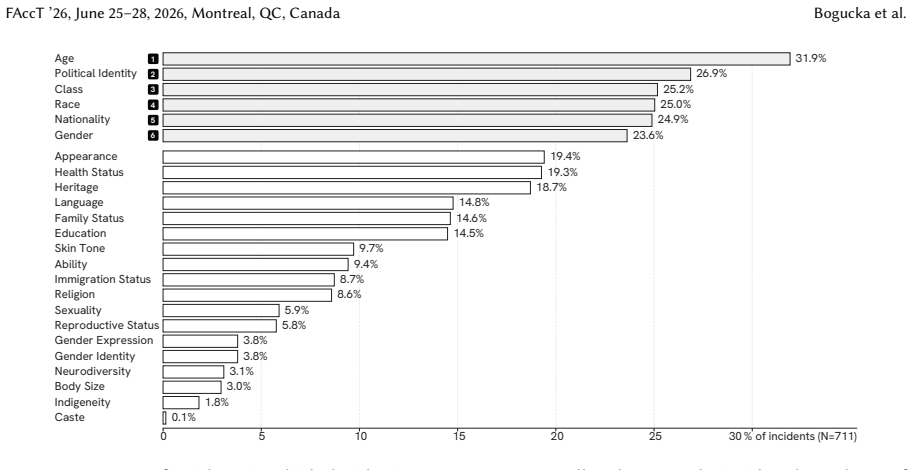
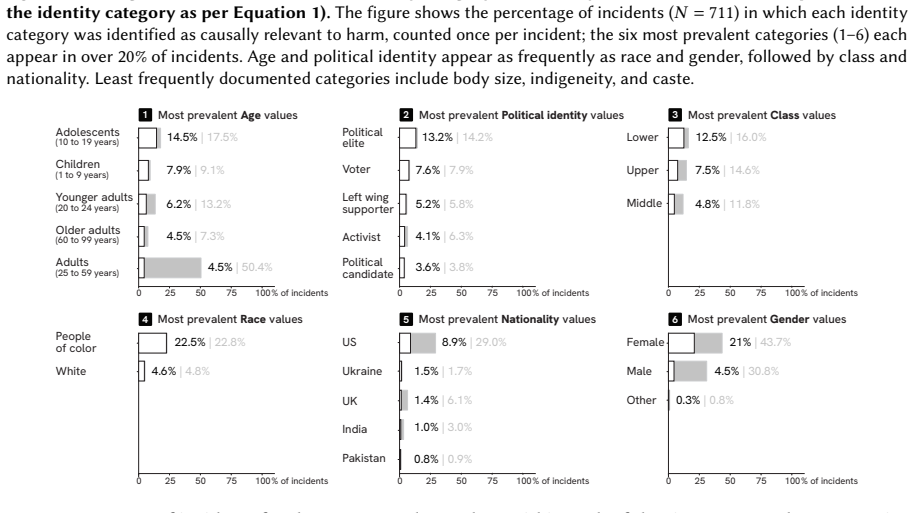
Using a large language model to apply a structured rubric to 5,300 reports from 1,200 documented incidents in the AI Incident Database, the authors identify 1,513 harmed subjects and demonstrate that AI harms do not occur one identity category at a time. At the level of individual categories, age and political identity occur at rates comparable to race and gender. At the level of intersecting categories, harm is amplified up to three times at specific intersections including adolescent girls, lower-class people of color, and upper-class political elites. The authors conclude that intersectionality should be a core component of AI risk assessment to more accurately capture how harms are both
What carries the argument
Structured rubric applied by large language model to extract harmed subjects and their intersecting identity categories from incident reports.
Load-bearing premise
The large language model applies the structured rubric to correctly identify harmed subjects and their identity categories at 98 percent accuracy, and the 1,200 incidents in the database represent AI harms in general.
What would settle it
A human audit of a random sample of the 5,300 reports that finds rubric accuracy below 90 percent for identifying intersections, or a new collection of AI harm incidents in which the reported amplification at the named intersections does not appear.
Figures




read the original abstract
AI risk assessment is the primary tool for identifying harms caused by AI systems. These include intersectional harms, which arise from the interaction between identity categories (e.g., class and skin tone) and which do not occur, or occur differently, when those categories are considered separately. Yet existing AI risk assessments are still built around isolated identity categories, and when intersections are considered, they focus almost exclusively on race and gender. Drawing on a large-scale analysis of documented AI incidents, we show that AI harms do not occur one identity category at a time. Using a structured rubric applied with a Large Language Model (LLM), we analyze 5,300 reports from 1,200 documented incidents in the AI Incident Database, the most curated source of incident data. From these reports, we identify 1,513 harmed subjects and their associated identity categories, achieving 98% accuracy. At the level of individual categories, we find that age and political identity appear in documented AI harms at rates comparable to race and gender. At the level of intersecting categories, harm is amplified up to three times at specific intersections: adolescent girls, lower-class people of color, and upper-class political elites. We argue that intersectionality should be a core component of AI risk assessment to more accurately capture how harms are produced and distributed across social groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 5,300 reports from 1,200 incidents in the AI Incident Database using an LLM-applied structured rubric to identify 1,513 harmed subjects and their identity categories. It claims 98% accuracy in this process and argues that AI harms are not isolated to single identity categories; instead, age and political identity appear at rates comparable to race and gender, with specific intersections (adolescent girls, lower-class people of color, upper-class political elites) showing harm amplification up to three times. The authors conclude that intersectionality must be central to AI risk assessment.
Significance. If the empirical findings hold after methodological validation, the work would provide a large-scale, data-driven case for shifting AI risk assessment from single-category to intersectional frameworks, using the scale of 5,300 reports and 1,200 incidents as a strength. It highlights under-examined categories like age and political identity and offers concrete examples of amplified harms at intersections, which could inform more accurate harm distribution models in the field.
major comments (3)
- [Methods] Methods section on LLM rubric application: The 98% accuracy claim for identifying harmed subjects and intersecting identity categories lacks any reported details on rubric design, LLM prompting strategy, validation set size, inter-rater agreement (especially for ambiguous cases like class or political identity), or error analysis. This directly underpins the extraction of the 1,513 subjects and all downstream amplification claims, so the absence of these elements makes the quantitative results difficult to evaluate.
- [Results] Results section on intersectional amplification: The statement that 'harm is amplified up to three times' at specific intersections (adolescent girls, lower-class people of color, upper-class political elites) does not specify the baseline single-category rates, the exact formula or statistical test used for the multiplier, or how intersection counts were computed from the 5,300 reports. Without this, it is impossible to determine whether the factor reflects true patterns or artifacts of tagging or sampling.
- [Discussion] Discussion or Limitations section on database representativeness: The analysis treats the 1,200 incidents as a basis for general claims about AI harms, but provides no assessment of selection biases (e.g., media attention or reporting favoring certain demographics), which could produce the observed rates for age, political identity, and intersections without reflecting underlying harm distributions.
minor comments (2)
- [Results] The abstract and results would benefit from a table summarizing single-category frequencies versus intersection frequencies to make the 'comparable to race and gender' and 'up to three times' claims easier to verify at a glance.
- [Methods] Notation for identity categories (e.g., how 'lower-class' or 'political elites' are operationalized in the rubric) is introduced without a dedicated definitions subsection, which could lead to ambiguity in replication.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us strengthen the transparency and rigor of our work. We address each major comment point by point below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Methods] Methods section on LLM rubric application: The 98% accuracy claim for identifying harmed subjects and intersecting identity categories lacks any reported details on rubric design, LLM prompting strategy, validation set size, inter-rater agreement (especially for ambiguous cases like class or political identity), or error analysis. This directly underpins the extraction of the 1,513 subjects and all downstream amplification claims, so the absence of these elements makes the quantitative results difficult to evaluate.
Authors: We agree that these methodological details are critical for evaluating the reliability of our quantitative results. In the revised manuscript, we have expanded the Methods section to provide a complete description of the structured rubric (including explicit definitions and decision rules for each identity category and harmed-subject identification), the LLM prompting strategy (model version, temperature, few-shot examples, and chain-of-thought instructions), the validation set (150 randomly sampled reports independently annotated by two human coders), inter-rater agreement (overall Cohen’s κ = 0.85; κ = 0.68 for class and political identity), and a full error analysis (primarily edge cases in political-identity tagging). The reported 98% accuracy is the agreement rate between the LLM and the human consensus on this validation set. These additions directly address the referee’s concerns and allow readers to assess the robustness of the 1,513-subject extraction. revision: yes
-
Referee: [Results] Results section on intersectional amplification: The statement that 'harm is amplified up to three times' at specific intersections (adolescent girls, lower-class people of color, upper-class political elites) does not specify the baseline single-category rates, the exact formula or statistical test used for the multiplier, or how intersection counts were computed from the 5,300 reports. Without this, it is impossible to determine whether the factor reflects true patterns or artifacts of tagging or sampling.
Authors: We appreciate the need for full transparency on the amplification calculations. We have revised the Results section to report the single-category baseline rates (race: 24%, gender: 27%, age: 19%, political identity: 16%, class: 12% of the 1,513 subjects). The amplification factor is defined as the ratio of observed intersection frequency to the frequency expected under independence (product of marginal probabilities). We applied a chi-squared test of independence (all reported amplifications significant at p < 0.05) and computed intersection counts via multi-label tagging of each subject across the 5,300 reports. For example, the adolescent-girls intersection shows a 2.9× amplification. A supplementary table now lists all multipliers with 95% confidence intervals. These clarifications demonstrate that the reported factors reflect the underlying data patterns rather than tagging or sampling artifacts. revision: yes
-
Referee: [Discussion] Discussion or Limitations section on database representativeness: The analysis treats the 1,200 incidents as a basis for general claims about AI harms, but provides no assessment of selection biases (e.g., media attention or reporting favoring certain demographics), which could produce the observed rates for age, political identity, and intersections without reflecting underlying harm distributions.
Authors: We agree that an explicit discussion of selection biases is warranted. We have added a dedicated paragraph to the Limitations section that acknowledges the AI Incident Database’s reliance on publicly reported incidents, which may be influenced by media attention and reporting biases that favor high-visibility demographics (e.g., political elites or certain racial groups). We note that these biases could affect the observed rates for age, political identity, and specific intersections. At the same time, we emphasize that the database remains the most comprehensive curated source of AI incidents and that our findings serve as an empirical foundation for incorporating intersectionality into risk assessment. We also recommend triangulation with additional data sources in future work. This revision appropriately qualifies the generalizability of our claims. revision: yes
Circularity Check
No circularity: purely observational analysis of external database
full rationale
The paper conducts an empirical study by applying an LLM-based rubric to reports from the external AI Incident Database. No equations, derivations, fitted parameters, or predictions are present. Claims about intersectional amplification are direct counts and ratios from the extracted data, not reductions to self-defined inputs or self-citation chains. The 98% accuracy figure is an external validation claim (not shown to loop back), and database selection effects are acknowledged as limitations rather than hidden assumptions. This matches the default expectation of non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The AI Incident Database and its 5,300 reports provide a sufficiently complete and unbiased record of real AI harms and the identity categories of affected individuals.
Reference graph
Works this paper leans on
-
[1]
2023.Reporting on Artificial Intelligence: A Handbook for Journalism Educators
Charlie Beckett, Edward Finn, Fredrik Heintz, Frederic Heymans, Suren Jayasuriya, Sayash Kapoor, Santosh Kumar Biswal, Arvind Narayanan, Agnes Stenbom, and Jenny Wiik (Eds.). 2023.Reporting on Artificial Intelligence: A Handbook for Journalism Educators. UNESCO. https://doi.org/10.58338/HSMK8605 Partial contributors: Jenny Bergenmar, Ammina Kothari, Bernh...
-
[2]
Avinash Agarwal and Manisha J. Nene. 2024. Standardised Schema and Taxonomy for AI Incident Databases in Critical Digital Infrastructure. InIEEE Pune Section International Conference (PuneCon). 1–6. doi:10.1109/PuneCon63413.2024.10895867
-
[3]
2014.Incident 9: NY City School Teacher Evaluation Algorithm Contested
AI Incident Database. 2014.Incident 9: NY City School Teacher Evaluation Algorithm Contested. AI Incident Database. https:// incidentdatabase.ai/cite/9/
2014
-
[4]
2015.Incident 263: YouTube Recommendations Implicated in Political Radicalization of User
AI Incident Database. 2015.Incident 263: YouTube Recommendations Implicated in Political Radicalization of User. AI Incident Database. https://incidentdatabase.ai/cite/263/
2015
-
[5]
2016.Incident 40: COMPAS Algorithm Reportedly Performs Poorly in Crime Recidivism Prediction
AI Incident Database. 2016.Incident 40: COMPAS Algorithm Reportedly Performs Poorly in Crime Recidivism Prediction. AI Incident Database. https://incidentdatabase.ai/cite/40/
2016
-
[6]
2016.Incident 6: Microsoft’s TayBot Allegedly Posts Racist, Sexist, and Anti-Semitic Content to Twitter
AI Incident Database. 2016.Incident 6: Microsoft’s TayBot Allegedly Posts Racist, Sexist, and Anti-Semitic Content to Twitter. AI Incident Database. https://incidentdatabase.ai/cite/6/
2016
-
[7]
2017.Incident 13: High-Toxicity Assessed on Text Involving Women and Minority Groups
AI Incident Database. 2017.Incident 13: High-Toxicity Assessed on Text Involving Women and Minority Groups. AI Incident Database. https://incidentdatabase.ai/cite/13/
2017
-
[8]
2017.Incident 167: Researchers’ Homosexual-Men Detection Model Denounced as a Threat to LGBTQ People’s Safety and Privacy
AI Incident Database. 2017.Incident 167: Researchers’ Homosexual-Men Detection Model Denounced as a Threat to LGBTQ People’s Safety and Privacy. AI Incident Database. https://incidentdatabase.ai/cite/167/
2017
-
[9]
2018.Incident 188: Argentinian City Government Deployed Teenage-Pregnancy Predictive Algorithm Using Invasive Demographic Data
AI Incident Database. 2018.Incident 188: Argentinian City Government Deployed Teenage-Pregnancy Predictive Algorithm Using Invasive Demographic Data. AI Incident Database. https://incidentdatabase.ai/cite/188
2018
-
[10]
2018.Incident 396: Transgender Uber Drivers Mistakenly Kicked off App for Appearance Change during Gender Transitions
AI Incident Database. 2018.Incident 396: Transgender Uber Drivers Mistakenly Kicked off App for Appearance Change during Gender Transitions. AI Incident Database. https://incidentdatabase.ai/cite/396/
2018
-
[11]
2019.Incident 288: New Jersey Police Wrongful Arrested Innocent Black Man via FRT
AI Incident Database. 2019.Incident 288: New Jersey Police Wrongful Arrested Innocent Black Man via FRT. AI Incident Database. https://incidentdatabase.ai/cite/288/
2019
-
[12]
2020.Incident 101: Dutch Families Wrongfully Accused of Tax Fraud Due to Discriminatory Algorithm
AI Incident Database. 2020.Incident 101: Dutch Families Wrongfully Accused of Tax Fraud Due to Discriminatory Algorithm. AI Incident Database. https://incidentdatabase.ai/cite/101/
2020
-
[13]
AI Incident Database. 2020.Incident 244: Colorado Police’s Automated License Plate Reader (ALPR) Matched a Family’s Minivan’s Plate to That of a Stolen Vehicle Allegedly, Resulting in Detainment at Gunpoint. AI Incident Database. https://incidentdatabase.ai/cite/244/
2020
-
[14]
2020.Incident 335: UK Visa Streamline Algorithm Allegedly Discriminated Based on Nationality
AI Incident Database. 2020.Incident 335: UK Visa Streamline Algorithm Allegedly Discriminated Based on Nationality. AI Incident Database. https://incidentdatabase.ai/cite/335/
2020
-
[15]
2020.Incident 74: Detroit Police Wrongfully Arrested Black Man Due To Faulty FRT
AI Incident Database. 2020.Incident 74: Detroit Police Wrongfully Arrested Black Man Due To Faulty FRT. AI Incident Database. https://incidentdatabase.ai/cite/74/
2020
-
[16]
2022.Incident 202: A Korean Politician Employed Deepfake as Campaign Representative
AI Incident Database. 2022.Incident 202: A Korean Politician Employed Deepfake as Campaign Representative. AI Incident Database. https://incidentdatabase.ai/cite/202/
2022
-
[17]
2022.Incident 300: TikTok’s “For You” Algorithm Allegedly Abused by Online Personality to Promote Anti-Women Hate
AI Incident Database. 2022.Incident 300: TikTok’s “For You” Algorithm Allegedly Abused by Online Personality to Promote Anti-Women Hate. AI Incident Database. https://incidentdatabase.ai/cite/300/
2022
-
[18]
2022.Incident 314: Stable Diffusion Abused by 4chan Users to Deepfake Celebrity Porn
AI Incident Database. 2022.Incident 314: Stable Diffusion Abused by 4chan Users to Deepfake Celebrity Porn. AI Incident Database. https://incidentdatabase.ai/cite/314/
2022
-
[19]
2022.Incident 431: Robbers Accessed Drugged Gay Men’s Bank Accounts Using Their Phones’ Facial Recognition
AI Incident Database. 2022.Incident 431: Robbers Accessed Drugged Gay Men’s Bank Accounts Using Their Phones’ Facial Recognition. AI Incident Database. https://incidentdatabase.ai/cite/431/
2022
-
[20]
2023.Incident 592: Facial Recognition Misidentifies Pregnant Woman Leading to False Arrest in Detroit
AI Incident Database. 2023.Incident 592: Facial Recognition Misidentifies Pregnant Woman Leading to False Arrest in Detroit. AI Incident Database. https://incidentdatabase.ai/cite/592/
2023
-
[21]
2023.Incident 610: Deepfake Technology Was Used to Generate Naked Pictures of Underage Girls in Spanish Town
AI Incident Database. 2023.Incident 610: Deepfake Technology Was Used to Generate Naked Pictures of Underage Girls in Spanish Town. AI Incident Database. https://incidentdatabase.ai/cite/610/
2023
-
[22]
2024.Incident 650: AI-Generated Images of Trump with Black Voters Spread as Disinformation Before U.S
AI Incident Database. 2024.Incident 650: AI-Generated Images of Trump with Black Voters Spread as Disinformation Before U.S. Primary Elections. AI Incident Database. https://incidentdatabase.ai/cite/650/
2024
-
[23]
Lavender
AI Incident Database. 2024.Incident 672: “Lavender”’ and “The Gospel”’ AI Systems Reportedly Used in Gaza Targeting Operations with Civilian Harm Allegations. AI Incident Database. https://incidentdatabase.ai/cite/672/
2024
-
[24]
2024.Incident 717: Fake AI-Generated Law Firms Sent Fake DMCA Notices to Increase SEO
AI Incident Database. 2024.Incident 717: Fake AI-Generated Law Firms Sent Fake DMCA Notices to Increase SEO. AI Incident Database. https://incidentdatabase.ai/cite/717/
2024
-
[25]
2024.Incident 862: Purportedly AI-Generated Video Allegedly Depicts Martin Luther King Jr
AI Incident Database. 2024.Incident 862: Purportedly AI-Generated Video Allegedly Depicts Martin Luther King Jr. Supporting Donald Trump. AI Incident Database. https://incidentdatabase.ai/cite/862/ FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Bogucka et al
2024
-
[26]
2024.Incident 874: 1 in 6 Congresswomen Have Reportedly Been Targeted by AI-Generated Nonconsensual Intimate Imagery
AI Incident Database. 2024.Incident 874: 1 in 6 Congresswomen Have Reportedly Been Targeted by AI-Generated Nonconsensual Intimate Imagery. AI Incident Database. https://incidentdatabase.ai/cite/874/
2024
-
[27]
2024.Incident 904: Kate Isaacs, Advocate Against Image-Based Abuse, Reports Being Deepfaked
AI Incident Database. 2024.Incident 904: Kate Isaacs, Advocate Against Image-Based Abuse, Reports Being Deepfaked. AI Incident Database. https://incidentdatabase.ai/cite/904/
2024
-
[28]
2024.Incident 924: Alleged Deepfake Scam Uses BBC Presenter Naga Munchetty’s Image to Promote Fraudulent Investment Scheme
AI Incident Database. 2024.Incident 924: Alleged Deepfake Scam Uses BBC Presenter Naga Munchetty’s Image to Promote Fraudulent Investment Scheme. AI Incident Database. https://incidentdatabase.ai/cite/924/
2024
-
[29]
2024.Incident 972: Russian Influence Operation Allegedly Uses AI to Create Fake Kamala Harris Campaign Website and Rhino-Hunting Hoax
AI Incident Database. 2024.Incident 972: Russian Influence Operation Allegedly Uses AI to Create Fake Kamala Harris Campaign Website and Rhino-Hunting Hoax. AI Incident Database. https://incidentdatabase.ai/cite/972/
2024
-
[30]
2025.Incident 1075: New Orleans Police Reportedly Used Real-Time Facial Recognition Alerts Supplied by Project NOLA Despite Local Ordinance
AI Incident Database. 2025.Incident 1075: New Orleans Police Reportedly Used Real-Time Facial Recognition Alerts Supplied by Project NOLA Despite Local Ordinance. AI Incident Database. https://incidentdatabase.ai/cite/1075/
2025
-
[31]
2025.Incident 1077: FBI Reports Ongoing Vishing and Smishing Campaign Allegedly Targeting Government Officials Using Purportedly AI-Generated Voices
AI Incident Database. 2025.Incident 1077: FBI Reports Ongoing Vishing and Smishing Campaign Allegedly Targeting Government Officials Using Purportedly AI-Generated Voices. AI Incident Database. https://incidentdatabase.ai/cite/1077/
2025
-
[32]
2025.Incident 1144: xAI Allegedly Operates Unpermitted Methane Turbines in Memphis to Power Supercomputer Colossus to Train Grok
AI Incident Database. 2025.Incident 1144: xAI Allegedly Operates Unpermitted Methane Turbines in Memphis to Power Supercomputer Colossus to Train Grok. AI Incident Database. https://incidentdatabase.ai/cite/1144/
2025
-
[33]
2025.Incident 980: AI-Generated Songs Allegedly Imitating Céline Dion Circulate Online Without Authorization
AI Incident Database. 2025.Incident 980: AI-Generated Songs Allegedly Imitating Céline Dion Circulate Online Without Authorization. AI Incident Database. https://incidentdatabase.ai/cite/980/
2025
-
[34]
2025.AI, Algorithmic, and Automation Incidents and Controversies
AI Now Institute. 2025.AI, Algorithmic, and Automation Incidents and Controversies. https://www.aiaaic.org/aiaaic-repository/ai- algorithmic-and-automation-incidents Accessed: 2025-09-01
2025
-
[35]
Ames, Janet Go, Joseph ’Jofish’ Kaye, and Mirjana Spasojevic
Morgan G. Ames, Janet Go, Joseph ’Jofish’ Kaye, and Mirjana Spasojevic. 2011. Understanding Technology Choices and Values Through Social Class. InProceedings of the ACM Conference on Computer Supported Cooperative Work (CSCW). Association for Computing Machinery, New York, NY, USA, 55–64. doi:10.1145/1958824.1958834
-
[36]
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. 2016. Machine Bias. There’s Software Used Across the Country to Predict Future Criminals. And It’s Biased Against Blacks. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal- sentencing. ProPublica
2016
-
[37]
Jeffrey Basoah, Jay L. Cunningham, Erica Adams, Alisha Bose, Aditi Jain, Kaustubh Yadav, Zhengyang Yang, Katharina Reinecke, and Daniela Rosner. 2025. Should AI Mimic People? Understanding AI-Supported Writing Technology Among Black Users.Proceedings of the ACM on Human-Computer Interaction9, 7 (2025), 51 pages. doi:10.1145/3757423
-
[38]
Greta R. Bauer, Siobhan M. Churchill, Mayuri Mahendran, Chantel Walwyn, Daniel Lizotte, and Alma Angelica Villa-Rueda. 2021. Intersectionality In Quantitative Research: A Systematic Review Of Its Emergence And Applications Of Theory And Methods.SSM - Population Health14 (2021), 100798. doi:10.1016/j.ssmph.2021.100798
-
[39]
2019.Race After Technology: Abolitionist Tools for the New Jim Code
Ruha Benjamin. 2019.Race After Technology: Abolitionist Tools for the New Jim Code. Polity Press
2019
-
[40]
Brown, Johnathan Flowers, Anthony Ventresque, and Christopher L
Abeba Birhane, Elayne Ruane, Thomas Laurent, Matthew S. Brown, Johnathan Flowers, Anthony Ventresque, and Christopher L. Dancy
-
[41]
Elizabeth Kumar, Aaron Horowitz, and Andrew D
The Forgotten Margins of AI Ethics. InProceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT). Association for Computing Machinery, 948–958. doi:10.1145/3531146.3533157
-
[42]
Edyta Bogucka, Sanja Šćepanović, and Daniele Quercia. 2024. Atlas of AI Risks: Enhancing Public Understanding of AI Risks.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing (HCOMP)12, 1 (2024), 33–43. doi:10.1609/hcomp.v12i1.31598
-
[43]
Avtar Brah and Ann Phoenix. 2004. Ain’t I a Woman? Revisiting Intersectionality.Journal of International Women’s Studies5, 3 (2004), 75–86. https://vc.bridgew.edu/jiws/vol5/iss3/8
2004
-
[44]
2023.Suspicion Machine Methodology
Justin-Casimir Braun, Eva Constantaras, Aung Htet, Gabriel Geiger, Dhruv Mehrotra, and Daniel Howden. 2023.Suspicion Machine Methodology. https://www.lighthousereports.com/methodology/suspicion-machine/
2023
-
[45]
Virginia Braun and Victoria Clarke. 2006. Using Thematic Analysis in Psychology.Qualitative Research in Psychology3, 2 (2006), 77–101. doi:10.1191/1478088706qp063oa
-
[46]
Joy Buolamwini and Timnit Gebru. 2018. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. In Proceedings of the Conference on Fairness, Accountability and Transparency (FAT), Sorelle A. Friedler and Christo Wilson (Eds.), Vol. 81. PMLR, 77–91. https://proceedings.mlr.press/v81/buolamwini18a.html
2018
-
[47]
Dasom Choi. 2025. Designing Inclusive AI Interaction for Neurodiversity. InCompanion Publication of the ACM Conference on Computer- Supported Cooperative Work and Social Computing (CSCW). Association for Computing Machinery, 31–34. doi:10.1145/3715070.3747338
-
[48]
2023.Inside the Suspicion Machine
Eva Constantaras, Gabriel Geiger, Justin-Casimir Braun, Dhruv Mehrotra, and Aung Htet. 2023.Inside the Suspicion Machine. https: //www.wired.com/story/welfare-state-algorithms/
2023
-
[49]
Kimberle Crenshaw. 1991. Mapping the Margins: Intersectionality, Identity Politics, and Violence Against Women of Color.Stanford Law Review43, 6 (1991), 1241. doi:10.2307/1229039
-
[50]
CSET. 2024. AI Harm Taxonomy for AIID. https://incidentdatabase.ai/taxonomy/csetv1. Accessed: 2026-03-20
2024
-
[51]
Julia De Miguel Velázquez, Sanja Šćepanović, Andrés Gvirtz, and Daniele Quercia. 2024. Decoding Real-World Artificial Intelligence Incidents.Computer57, 11 (2024), 71–81. doi:10.1109/MC.2024.3432492
-
[52]
2018.Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor
Virginia Eubanks. 2018.Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor. St. Martin’s Press. Why AI Harms Can’t Be Fixed One Identity at a Time FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
2018
- [53]
-
[54]
Maya Goodwill, Roy Bendor, and Mieke van der Bijl-Brouwer. 2021. Beyond Good Intentions: Towards a Power Literacy Framework for Service Designers.International Journal of Design15, 3 (2021), 45–59
2021
-
[55]
Bossert, Yip Fai Tse, and Peter Singer
Thilo Hagendorff, Leonie N. Bossert, Yip Fai Tse, and Peter Singer. 2022. Speciesist Bias In AI: How AI Applications Perpetuate Discrimination And Unfair Outcomes Against Animals.AI and Ethics3, 3 (2022), 717–734. doi:10.1007/s43681-022-00199-9
-
[56]
Patricia Hill Collins. 2002.Black Feminist Thought. Routledge. doi:10.4324/9780203900055
-
[57]
Anna Lauren Hoffmann. 2019. Where Fairness Fails: Data, Algorithms, And The Limits Of Antidiscrimination Discourse. InInformation, Communication & Society, Vol. 22. Taylor & Francis, 900–915
2019
-
[58]
Hans Hofmann. 1994. Statlog (German Credit Data). https://archive.ics.uci.edu/dataset/144. doi:10.24432/C5NC77
-
[59]
Cara Hunter and Anna Moore. 2025. ‘It Was Extremely Pornographic’: Cara Hunter On The Deepfake Video That Nearly Ended Her Political Career.The Guardian(01 Dec. 2025). https://www.theguardian.com/society/ng-interactive/2025/dec/01/it-was-extremely- pornographic-cara-hunter-on-the-deepfake-video-that-nearly-ended-her-political-career Accessed: 2026-01-13
2025
-
[60]
Nadia Karizat, Dan Delmonaco, Motahhare Eslami, and Nazanin Andalibi. 2021. Algorithmic Folk Theories and Identity: How TikTok Users Co-Produce Knowledge of Identity and Engage in Algorithmic Resistance.Proceedings of the ACM on Human-Computer Interaction 5, Article 305 (2021), 44 pages. doi:10.1145/3476046
-
[61]
Ron Kohavi and Barry Becker. 1996. UCI Adult Data Set. https://archive.ics.uci.edu/ml/datasets/adult. https://archive.ics.uci.edu/ml/ datasets/adult UCI Machine Learning Repository
1996
-
[62]
Paola Lopez. 2024. More Than the Sum of its Parts: Susceptibility to Algorithmic Disadvantage as a Conceptual Framework. In Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT). Association for Computing Machinery, 909–919. doi:10.1145/3630106.3658944
-
[63]
Leslie McCall. 2005. The Complexity of Intersectionality.Signs: Journal of Women in Culture and Society30, 3 (2005), 1771–1800. doi:10.1086/426800
-
[64]
Nora McDonald, Sarita Schoenebeck, and Andrea Forte. 2019. Reliability and Inter-Rater Reliability in Qualitative Research: Norms and Guidelines for CSCW and HCI Practice.Proceedings of the ACM on Human-Computer Interaction3 (2019). doi:10.1145/3359174
-
[65]
1994.Qualitative Data Analysis: A Methods Sourcebook
Matthew Miles and Michael Huberman. 1994.Qualitative Data Analysis: A Methods Sourcebook. Sage
1994
-
[66]
Gustavo Moreira, Edyta Paulina Bogucka, Marios Constantinides, and Daniele Quercia. 2025. The Hall of AI Fears and Hopes: Comparing the Views of AI Influencers and those of Members of the U.S. Public Through an Interactive Platform. InProceedings of the ACM Conference on Human Factors in Computing Systems (CHI). Association for Computing Machinery, Articl...
-
[67]
Jennifer C. Nash. 2019.Black Feminism Reimagined: After Intersectionality. Duke University Press. doi:10.1215/9781478002253
-
[68]
2018.Algorithms of Oppression: How Search Engines Reinforce Racism
Safiya Umoja Noble. 2018.Algorithms of Oppression: How Search Engines Reinforce Racism. NYU Press
2018
-
[69]
2025.OECD AI Incidents Monitor
Organisation for Economic Co-operation and Development. 2025.OECD AI Incidents Monitor. https://oecd.ai/en/incidents Accessed: 2025-09-01
2025
-
[70]
Jaspar Pahl, Ines Rieger, Anna Möller, Thomas Wittenberg, and Ute Schmid. 2022. Female, White, 27? Bias Evaluation on Data and Algorithms for Affect Recognition in Faces. InProceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT). Association for Computing Machinery, 973–987. doi:10.1145/3531146.3533159
-
[71]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act). http://data.europa.eu/eli/ reg/2024/1689/oj
2024
-
[72]
K. M. Pauly. 1996. Describing the Emperor’s New Clothes: Three Myths of Education (In)Equality. InThe Gender Question in Education: Theory, Pedagogy and Politics, Ann Diller et al. (Eds.). Westview Press, Boulder, CO
1996
-
[73]
Uwe Peters. 2022. Algorithmic Political Bias in Artificial Intelligence Systems.Philosophy and Technology35, 2 (2022). doi:10.1007/s13347- 022-00512-8
- [74]
-
[75]
Joanna Redden, Lina Dencik, and Harry Warne. 2020. Datafied Child Welfare Services: Unpacking Politics, Economics And Power.Policy Studies41, 5 (2020), 507–526. doi:10.1080/01442872.2020.1724928
-
[76]
2025.AI Incident Database
Responsible AI Collaborative. 2025.AI Incident Database. https://incidentdatabase.ai/ Accessed: 2025-09-01
2025
-
[77]
2024.AI Elections Tracker
Rest of World Staff. 2024.AI Elections Tracker. https://restofworld.org/2024/elections-ai-tracker/ Accessed: 2026-01-13
2024
-
[78]
Isabel Richards, Claire Benn, and Miri Zilka. 2025. From Incidents to Insights: Patterns of Responsibility Following AI Harms. In Proceedings of the ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO). Association for Computing Machinery, 151–169. doi:10.1145/3757887.3763018
-
[79]
2015.The Coding Manual for Qualitative Researchers
Johnny Saldaña. 2015.The Coding Manual for Qualitative Researchers. Sage
2015
-
[80]
Princess Sampson, Ro Encarnacion, and Danaë Metaxa. 2023. Representation, Self-Determination, and Refusal: Queer People’s Experiences with Targeted Advertising. InProceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT). Association for FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Bogucka et al. Computing Machinery, 171...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.