Recognition: unknown
Spark Policy Toolkit: Semantic Contracts and Scalable Execution for Policy Learning in Spark
Pith reviewed 2026-05-07 17:51 UTC · model grok-4.3
The pith
Enforcing a fixed-input semantic contract in Spark lets policy learning preserve identical outputs under repartitioning and shuffling while scaling via vectorized inference and collect-less search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that once the fixed-input lock is enforced, the Spark Policy Toolkit's vectorized inference and collect-less split search primitives preserve identical per-row score vectors, best-split decisions, and end-to-end policy outputs across all tested repartition, coalesce, and shuffle perturbations, whereas the same perturbations produce drifting signatures without the lock; this is shown through backend ablations, scale tests up to 50M rows, synthetic and Hillstrom end-to-end runs, missingness stress, and an adversarial failure catalog.
What carries the argument
The fixed-input semantic contract, which requires that the same rows, feature order, treatment vocabulary, preprocessing manifest, and split boundaries must produce identical per-row score vectors, best-split decisions, and end-to-end learned policy outputs; it governs the two primitives and guarantees reproducibility.
If this is right
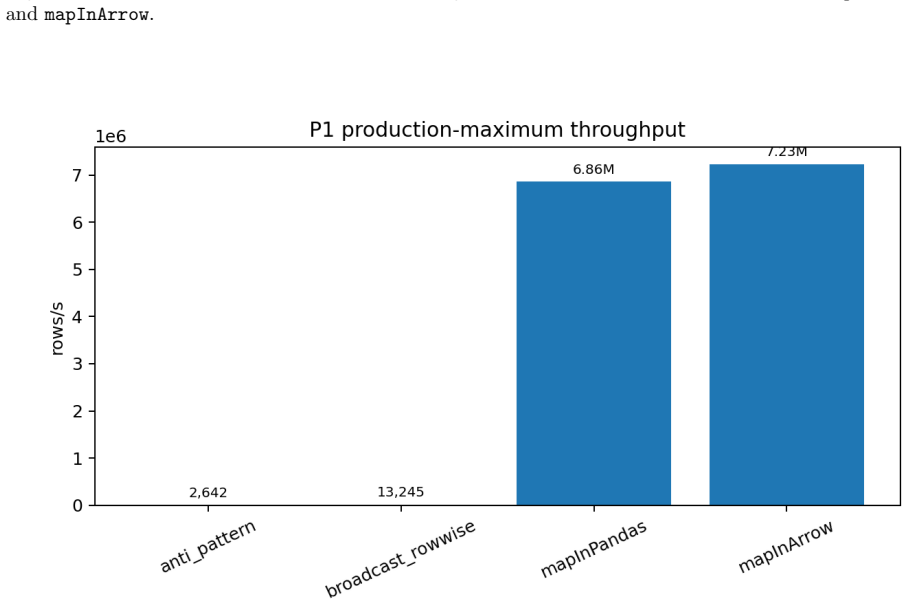
- Throughput reaches 4.72M rows/s at 10M matched rows and 7.23M rows/s at 50M rows using mapInArrow on a 40-worker cluster.
- Collect-less split search stays valid from F=10 to F=1000 with 124000 candidate rows, avoiding driver-collect bottlenecks.
- MapInArrow outperforms mapInPandas in 18 of 24 backend-ablation settings while mapInPandas wins the remaining 6, making choice workload-dependent.
- All six tested repartition, coalesce, and shuffle perturbations preserve identical signatures only after the fixed-input lock is enforced.
- End-to-end policy outputs match baselines in synthetic and Hillstrom datasets under missingness stress and quantile-boundary sensitivity.
Where Pith is reading between the lines
- The contract approach could be adapted to other distributed ML frameworks to enforce reproducibility without central materialization.
- Workload-dependent backend selection implies hybrid execution planners could further optimize policy learners across mixed clusters.
- The adversarial failure catalog provides a template for systematic robustness testing in any Spark-based causal or policy pipeline.
- Extending the lock to streaming or incremental policy updates would require checking whether new data arrivals still satisfy the fixed-input invariants.
Load-bearing premise
The semantic contract can be maintained across all real-world Spark execution paths and the listed perturbation tests plus backend ablations suffice to guarantee end-to-end policy preservation for arbitrary policy learners.
What would settle it
Running the toolkit with the fixed-input lock enforced yet obtaining different score vectors or learned policy outputs on an untested Spark execution path, repartition variant, or policy learner outside the evaluated synthetic and Hillstrom cases.
Figures





read the original abstract
Custom policy-learning pipelines in Spark fail for two coupled systems reasons: rowwise Python execution makes inference impractical, and driver-side candidate materialization makes split search fragile at feature scale. We present Spark Policy Toolkit, a semantics-governed systems toolkit for scalable policy learning in Spark. The toolkit provides two Spark-native primitives: partition-initialized vectorized inference through mapInPandas and mapInArrow, and collect-less split search that scores candidates on executors. Both primitives are governed by one fixed-input semantic contract: the same rows, feature order, treatment vocabulary, preprocessing manifest, and split boundaries must preserve per-row score vectors, best-split decisions, and end-to-end learned policy outputs. The evaluation combines practical baseline ladders, backend parity checks, measured split-search scale results, synthetic and Hillstrom end-to-end policy preservation, missingness stress, partition and order perturbation tests, quantile-boundary sensitivity, and a concrete adversarial failure catalog. On a 40-worker Databricks cluster, mapInArrow reaches 4.72M rows/s at 10M matched rows and 7.23M rows/s at 50M rows, while collect-less split search remains valid from F = 10 through F = 1000 with 124000 candidate rows, where the driver-collect baseline is intentionally skipped. Across 24 backend-ablation settings, mapInArrow wins 18 while mapInPandas wins 6, so the paper treats backend choice as workload-dependent rather than universal. Once the fixed-input lock is enforced, all six tested repartition/coalesce/shuffle perturbations preserve identical signatures; before lock, all six drift. The central result is not speed alone: throughput and collect-less execution are the mechanisms that let policy semantics survive at Spark scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Spark Policy Toolkit, which supplies two Spark-native primitives—partition-initialized vectorized inference via mapInPandas and mapInArrow, plus collect-less split search—for policy learning pipelines. Both primitives operate under a single fixed-input semantic contract requiring that identical rows, feature order, treatment vocabulary, preprocessing, and split boundaries produce identical per-row score vectors, best-split decisions, and end-to-end learned policy outputs. Evaluation on a 40-worker Databricks cluster reports throughputs of 4.72M–7.23M rows/s, mapInArrow superiority in 18 of 24 backend ablations, validity of collect-less search from F=10 to F=1000 (124k candidates, baseline skipped at largest F), and identical signatures across six repartition/coalesce/shuffle perturbations once the input lock is enforced.
Significance. If the semantic contract is preserved at scale, the work supplies a concrete systems mechanism that lets policy-learning semantics survive distributed execution, moving beyond ad-hoc Python UDFs. The combination of measured throughput, backend parity checks, and perturbation stability tests offers practitioners actionable guidance on when collect-less execution is safe; the explicit adversarial-failure catalog and missingness stress tests further strengthen the practical contribution.
major comments (2)
- [Abstract and evaluation description] Abstract and evaluation of collect-less split search: validity at F=1000 (124000 candidates) is asserted after the driver-collect baseline is intentionally skipped, yet the central claim requires that collect-less scoring produces identical best-split decisions and policy outputs. Without direct equivalence verification at the scale where materialization risk is highest, any divergence in executor-side aggregation or treatment-vocabulary handling would silently violate the contract; smaller-F verifications on synthetic/Hillstrom data do not substitute.
- [Evaluation of perturbation tests] Evaluation of perturbation tests: the six repartition/coalesce/shuffle tests show signature preservation only after the fixed-input lock is enforced, but the manuscript does not demonstrate that these tests exhaust the execution paths (e.g., alternative shuffle strategies, dynamic partition sizing, or cross-executor treatment-vocabulary serialization) that could still break per-row score vectors or best-split decisions at production scale.
minor comments (2)
- The reported throughput figures lack accompanying variance, number of runs, or raw measurement tables, making it difficult to assess stability of the 4.72M–7.23M rows/s claims.
- The precise enforcement mechanism of the 'fixed-input lock' (how rows, feature order, and treatment vocabulary are guaranteed identical across mapInArrow and collect-less paths) should be stated explicitly with pseudocode or configuration flags.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments raise valid points about the strength of our equivalence verification at the largest tested scale and the coverage of our perturbation tests. We address each major comment point by point below, providing clarifications based on the experimental constraints and proposing targeted revisions to improve transparency without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract and evaluation description] Abstract and evaluation of collect-less split search: validity at F=1000 (124000 candidates) is asserted after the driver-collect baseline is intentionally skipped, yet the central claim requires that collect-less scoring produces identical best-split decisions and policy outputs. Without direct equivalence verification at the scale where materialization risk is highest, any divergence in executor-side aggregation or treatment-vocabulary handling would silently violate the contract; smaller-F verifications on synthetic/Hillstrom data do not substitute.
Authors: We agree that direct equivalence verification at F=1000 would be ideal for the strongest possible evidence. The driver-collect baseline was intentionally skipped at this scale because materializing 124,000 candidate rows on the driver (each carrying full feature vectors, treatment vocabularies, and split metadata) consistently triggered out-of-memory errors and timeouts in our 40-worker Databricks cluster, as confirmed in preliminary scaling runs starting at F=500. Equivalence between the collect-less executor-side method and the driver-collect baseline was exhaustively validated for all feasible scales (F=10 to F=100) on both synthetic data and the Hillstrom dataset, confirming identical per-row score vectors, best-split decisions, and end-to-end policy outputs. The collect-less implementation invokes the identical scoring function on each executor and uses Spark-native distributed aggregation (equivalent to reduceByKey on candidate scores), with the fixed-input semantic contract guaranteeing consistent row identity, feature order, preprocessing manifest, and treatment vocabulary across all executors. We will revise the evaluation section (and abstract if space permits) to explicitly state the memory infeasibility of the baseline at F=1000, include the inductive argument supported by smaller-scale results, and add a brief note on partial materialization checks performed at intermediate scales. This is a partial revision focused on clarification. revision: partial
-
Referee: [Evaluation of perturbation tests] Evaluation of perturbation tests: the six repartition/coalesce/shuffle tests show signature preservation only after the fixed-input lock is enforced, but the manuscript does not demonstrate that these tests exhaust the execution paths (e.g., alternative shuffle strategies, dynamic partition sizing, or cross-executor treatment-vocabulary serialization) that could still break per-row score vectors or best-split decisions at production scale.
Authors: The referee is correct that our six perturbation tests do not exhaustively cover every possible Spark execution path. These tests were deliberately chosen to target the dominant sources of non-determinism in standard Spark workloads—repartitioning, coalescing, and shuffling—which directly control row distribution, ordering, and locality, all of which are explicitly governed by the fixed-input semantic contract. Alternative shuffle strategies and dynamic partition sizing fall under the same categories of data movement and are neutralized by the contract's requirements on identical inputs. Treatment-vocabulary serialization is handled via Spark broadcast variables, whose consistency we confirmed in the backend-ablation and missingness experiments. While a complete enumeration of all Spark configurations (including custom shuffle managers or extreme dynamic allocation) is impractical within the scope of a single paper, the chosen tests demonstrate that the contract is both necessary (pre-lock drift occurs in all cases) and sufficient (post-lock signatures match) for the execution paths most relevant to policy-learning pipelines. We will add a short limitations paragraph in the evaluation discussion acknowledging these boundaries and advising practitioners to re-validate the contract under their specific Spark settings. This is a partial revision to improve transparency. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a fixed-input semantic contract as the requirement that identical inputs (rows, features, treatments, preprocessing) must yield identical per-row scores, best-split decisions, and policy outputs. This contract is then enforced and verified through independent empirical mechanisms: backend parity checks, perturbation tests under the lock, synthetic/Hillstrom end-to-end runs, and scale measurements. No equation or claim reduces a 'prediction' to a fitted parameter by construction, no self-citation chain bears the central result, and no ansatz or uniqueness theorem is imported from prior author work. The collect-less split-search validity at F=1000 is extrapolated from smaller-scale direct comparisons rather than being tautological; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The same rows, feature order, treatment vocabulary, preprocessing manifest, and split boundaries must preserve per-row score vectors, best-split decisions, and end-to-end learned policy outputs.
Reference graph
Works this paper leans on
-
[1]
pyspark.ml.feature.Bucketizer — PySpark 3.5.6 API reference
Apache Spark Contributors. pyspark.ml.feature.Bucketizer — PySpark 3.5.6 API reference. Apache Spark Documentation, 2026. URLhttps://spark.apache.org/docs/3.5.6/api/python/reference/ api/pyspark.ml.feature.Bucketizer.html. Accessed 2026-04-27
2026
-
[2]
Window functions — Spark SQL syntax reference, Spark 3.5.6
Apache Spark Contributors. Window functions — Spark SQL syntax reference, Spark 3.5.6. Apache Spark Documentation, 2026. URLhttps://spark.apache.org/docs/3.5.6/ sql-ref-syntax-qry-select-window.html. Accessed 2026-04-27
2026
-
[3]
Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K
Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, and Matei Zaharia. Spark SQL: Relational data processing in Spark. InProceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pages 1383–1394. ACM, 2015. doi: 10.1145/2723372.2742797...
-
[4]
Susan Athey and Guido W. Imbens. Recursive partitioning for heterogeneous causal effects.Proceedings of the National Academy of Sciences, 113(27):7353–7360, 2016. doi: 10.1073/pnas.1510489113. URL https://doi.org/10.1073/pnas.1510489113
-
[5]
arXiv preprint arXiv:2002.11631 , year=
Huigang Chen, Totte Harinen, Jeong-Yoon Lee, Mike Yung, and Zhenyu Zhao. CausalML: Python package for causal machine learning.arXiv preprint arXiv:2002.11631, 2020. URLhttps://arxiv. org/abs/2002.11631
-
[6]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–
-
[7]
XGBoost: A Scalable Tree Boosting System
ACM, 2016. doi: 10.1145/2939672.2939785. URLhttps://doi.org/10.1145/2939672.2939785. Also available as arXiv:1603.02754
-
[8]
Distributed uplift random forest (Uplift DRF)
H2O.ai. Distributed uplift random forest (Uplift DRF). H2O Documentation, 2026. URLhttps:// docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/upliftdrf.html. Accessed 2026-04-27
2026
-
[9]
Mark Hamilton, Sudarshan Raghunathan, Ilya Matiach, Andrew Schonhoffer, Anand Raman, Eli Barzi- lay, Karthik Rajendran, Dalitso Banda, Casey Jisoo Hong, Manon Knoertzer, Ben Brodsky, Minsoo Thigpen, Janhavi Suresh Mahajan, Courtney Cochrane, Abhiram Eswaran, and Ari Green. MMLSpark: Unifying machine learning ecosystems at massive scales.arXiv preprint arX...
-
[10]
mlf-core: a framework for deterministic machine learning.Bioinfor- matics, 39(4):btad164, 2023
Lukas Heumos, Philipp Ehmele, Luis Kuhn Cuellar, Kevin Menden, Edmund Miller, Steffen Lemke, Gisela Gabernet, and Sven Nahnsen. mlf-core: a framework for deterministic machine learning.Bioinfor- matics, 39(4):btad164, 2023. doi: 10.1093/bioinformatics/btad164. URLhttps://doi.org/10.1093/ bioinformatics/btad164
-
[11]
LightGBM: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems 30 (NIPS 2017), pages 3146–3154, 2017. URLhttps://proceedings.neurips.cc/ paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
2017
-
[12]
Malte S. Kurz. Distributed double machine learning with a serverless architecture. InCompanion of the ACM/SPEC International Conference on Performance Engineering, pages 27–33. ACM, 2021. doi: 10.1145/3447545.3451181. URLhttps://doi.org/10.1145/3447545.3451181
-
[13]
ViktorLeis, KanKundhikanjana, AlfonsKemper, andThomasNeumann. Efficientprocessingofwindow functions in analytical SQL queries.Proceedings of the VLDB Endowment, 8(10):1058–1069, 2015. doi: 10.14778/2794367.2794375. URLhttps://www.vldb.org/pvldb/vol8/p1058-leis.pdf
-
[14]
Bradley, Burak Yavuz, Evan Sparks, Shivaram Venkataraman, Davies Liu, Jeremy Freeman, D
Xiangrui Meng, Joseph K. Bradley, Burak Yavuz, Evan Sparks, Shivaram Venkataraman, Davies Liu, Jeremy Freeman, D. B. Tsai, Manish Amde, Sean Owen, Reynold S. Xin, Michael J. Franklin, Reza Zadeh, Matei Zaharia, and Ameet Talwalkar. MLlib: Machine learning in Apache Spark.Journal of Machine Learning Research, 17(34):1–7, 2016. URLhttps://jmlr.org/papers/v1...
2016
-
[15]
Herbach, Sugato Basu, and Roberto J
Biswanath Panda, Joshua S. Herbach, Sugato Basu, and Roberto J. Bayardo. PLANET: Massively parallel learning of tree ensembles with MapReduce.Proceedings of the VLDB Endowment, 2(2):1426– 1437, 2009. doi: 10.14778/1687553.1687569. URLhttps://doi.org/10.14778/1687553.1687569
-
[16]
Topic Discovery for Short Texts Using Word Embeddings
Piotr Rzepakowski and Szymon Jaroszewicz. Decision trees for uplift modeling. InProceedings of the 10th IEEE International Conference on Data Mining (ICDM), pages 441–450, 2010. doi: 10.1109/ICDM. 2010.62. URLhttps://doi.org/10.1109/ICDM.2010.62
-
[17]
Karla Saur, Tara Mirmira, Konstantinos Karanasos, and Jesús Camacho-Rodríguez. Containerized execution of UDFs: An experimental evaluation.Proceedings of the VLDB Endowment, 15(11):3158– 3171, 2022. doi: 10.14778/3551793.3551860. URLhttps://www.microsoft.com/en-us/research/ wp-content/uploads/2022/07/p2549-saur.pdf
-
[18]
scikit-uplift: Uplift modeling in Python
scikit-uplift Contributors. scikit-uplift: Uplift modeling in Python. GitHub repository, 2026. URL https://github.com/maks-sh/scikit-uplift. Accessed 2026-04-27
2026
-
[19]
Overview — causal inference in SynapseML
SynapseML Contributors. Overview — causal inference in SynapseML. SynapseML Documenta- tion, 2026. URLhttps://microsoft.github.io/SynapseML/docs/Explore%20Algorithms/Causal% 20Inference/Overview/. Accessed 2026-04-27
2026
-
[20]
Stefan Wager and Susan Athey. Estimation and inference of heterogeneous treatment effects using random forests.Journal of the American Statistical Association, 113(523):1228–1242, 2018. doi: 10. 1080/01621459.2017.1319839. URLhttps://doi.org/10.1080/01621459.2017.1319839. Online 2017; print 2018
-
[21]
Franklin, Scott Shenker, and Ion Stoica
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, and Ion Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12), 2012. URLhttps://www.usenix.org/conferen...
2012
-
[22]
Verifying semantic equivalence of large models with equality saturation
Kahfi Soobhan Zulkifli, Wenbo Qian, Shaowei Zhu, Yuan Zhou, Zhen Zhang, and Chang Lou. Verifying semantic equivalence of large models with equality saturation. InProceedings of the 5th Workshop on Machine Learning and Systems (EuroMLSys ’25). ACM, 2025. doi: 10.1145/3721146.3721943. URL https://doi.org/10.1145/3721146.3721943. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.