Recognition: 2 theorem links
· Lean TheoremRPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Pith reviewed 2026-05-16 14:41 UTC · model grok-4.3
The pith
Even the strongest models achieve only 68.2 percent correctness-completeness on a new benchmark for understanding research papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
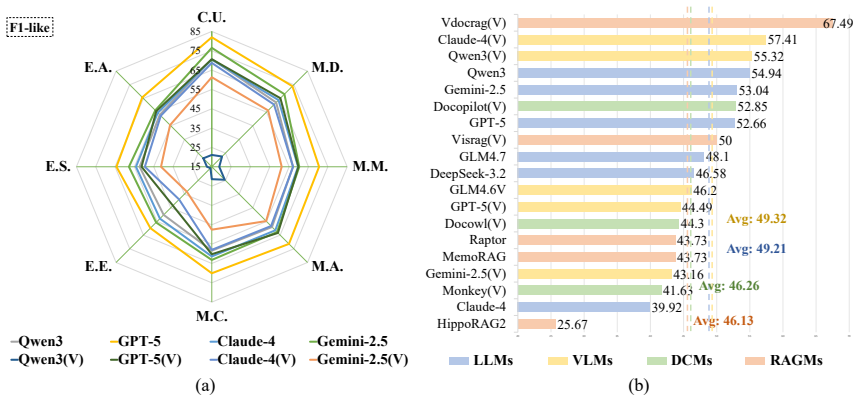
RPC-Bench supplies 15K human-verified QA pairs from real review-rebuttal exchanges together with a taxonomy that follows the scientific research flow and an LLM-as-a-Judge framework that scores models on both correctness-completeness and conciseness, demonstrating that even the strongest current models fall well short of reliable research-paper understanding.
What carries the argument
The fine-grained taxonomy aligned with the scientific research flow that organizes questions into why, what, and how categories drawn from review-rebuttal exchanges.
If this is right
- Models must improve at handling specialized scientific discourse, figures, and tables.
- Review-rebuttal exchanges can serve as a scalable source for high-quality, realistic QA data.
- Conciseness-adjusted scoring reveals a persistent trade-off between completeness and brevity that current models do not resolve.
Where Pith is reading between the lines
- The benchmark could be extended beyond computer science to test whether the same performance gaps appear in physics, biology, or other domains.
- Training data that includes reviewer comments might help models anticipate common points of confusion in scientific writing.
- The drop after conciseness adjustment suggests future work could focus on architectures that jointly optimize for both completeness and brevity.
Load-bearing premise
That QA pairs extracted from review-rebuttal exchanges form a representative and unbiased sample of the comprehension challenges present in the broader scientific literature.
What would settle it
Re-running the same evaluation protocol on QA pairs drawn from a different source such as direct reader questions on arXiv preprints or post-publication comments and finding that model scores remain comparably low would support the benchmark's claim.
Figures













read the original abstract
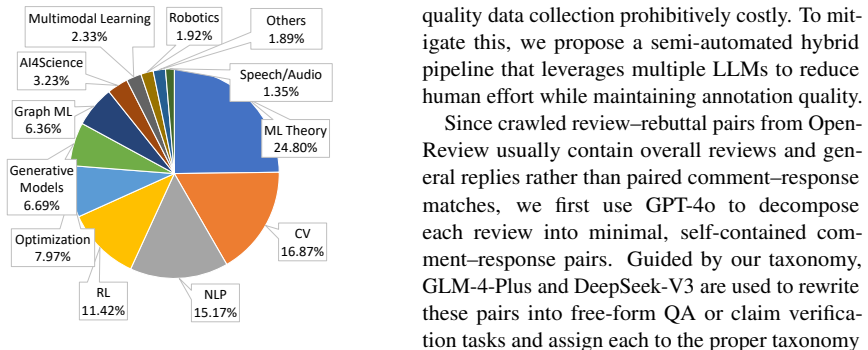
Understanding research papers remains challenging for foundation models due to specialized scientific discourse and complex figures and tables, yet existing benchmarks offer limited fine-grained evaluation at scale. To address this gap, we introduce RPC-Bench, a large-scale question-answering benchmark built from review-rebuttal exchanges of high-quality computer science papers, containing 15K human-verified QA pairs. We design a fine-grained taxonomy aligned with the scientific research flow to assess models' ability to understand and answer why, what, and how questions in scholarly contexts. We also define an elaborate LLM-human interaction annotation framework to support large-scale labeling and quality control. Following the LLM-as-a-Judge paradigm, we develop a scalable framework that evaluates models on correctness-completeness and conciseness, with high agreement to human judgment. Experiments reveal that even the strongest models (GPT-5) achieve only 68.2% correctness-completeness, dropping to 37.46% after conciseness adjustment, highlighting substantial gaps in precise academic paper understanding. Our code and data are available at https://rpc-bench.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RPC-Bench, a benchmark of 15K human-verified QA pairs extracted from review-rebuttal exchanges in high-quality CS papers. It defines a fine-grained taxonomy aligned with the scientific research flow for evaluating models on why/what/how questions, and applies an LLM-as-Judge protocol (with claimed high human agreement) to measure correctness-completeness and conciseness. Experiments show even GPT-5 reaches only 68.2% correctness-completeness, falling to 37.46% after conciseness adjustment, which the authors interpret as evidence of substantial gaps in precise scholarly paper understanding.
Significance. If the sampling frame is shown to be representative, RPC-Bench would offer a useful large-scale, fine-grained resource for diagnosing and improving foundation-model performance on authentic scientific discourse, going beyond existing benchmarks by tying questions to review-driven challenges and providing an open code/data release.
major comments (3)
- [§3] §3 (Data Construction): The headline claim of substantial gaps in paper comprehension rests on the 15K QA pairs being representative of typical scholarly reading demands. Extraction from review-rebuttal threads likely over-samples clarification/critique questions while under-sampling straightforward method or result-interpretation questions; the manuscript must include a control comparison (e.g., randomly sampled questions from the same papers) to rule out sampling-frame artifacts.
- [§5] §5 (Evaluation): The drop from 68.2% correctness-completeness to 37.46% after conciseness adjustment is central to the reported result, yet the precise definition, weighting, and computation of the conciseness term are not specified; without an explicit formula or pseudocode, the adjusted metric cannot be interpreted or reproduced.
- [§4] §4 (Annotation Framework): The reliability of the human-verified labels and the LLM-as-Judge protocol is load-bearing for all reported scores, but inter-annotator agreement statistics (e.g., Cohen’s kappa or percentage agreement), verifier count, and any post-hoc filtering criteria are not provided; these details are required to confirm that the 15K pairs constitute a high-quality benchmark.
minor comments (2)
- [Abstract] Abstract: the phrase 'high agreement to human judgment' should be quantified (e.g., '92% agreement, κ=0.81') so readers can immediately gauge reliability.
- [§2] §2 (Related Work): the contrast with prior scientific QA benchmarks could be sharpened by adding a table that directly compares scale, taxonomy granularity, and source distribution.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each of the major comments below and will make the necessary revisions to improve the clarity and rigor of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Data Construction): The headline claim of substantial gaps in paper comprehension rests on the 15K QA pairs being representative of typical scholarly reading demands. Extraction from review-rebuttal threads likely over-samples clarification/critique questions while under-sampling straightforward method or result-interpretation questions; the manuscript must include a control comparison (e.g., randomly sampled questions from the same papers) to rule out sampling-frame artifacts.
Authors: We acknowledge the referee's concern regarding potential sampling bias in our data construction. Our benchmark is specifically designed to capture the types of questions that arise during the peer review process, which we believe represent key challenges in research paper comprehension. However, to directly address the issue of representativeness, we will add a control comparison using randomly sampled questions from the same set of papers in the revised manuscript. This will allow us to quantify any differences and strengthen the claim. revision: yes
-
Referee: [§5] §5 (Evaluation): The drop from 68.2% correctness-completeness to 37.46% after conciseness adjustment is central to the reported result, yet the precise definition, weighting, and computation of the conciseness term are not specified; without an explicit formula or pseudocode, the adjusted metric cannot be interpreted or reproduced.
Authors: We apologize for not providing sufficient detail on the conciseness adjustment in the original submission. In the revised manuscript, we will include an explicit formula and pseudocode for computing the conciseness term and the adjusted metric. The conciseness score penalizes overly verbose responses while maintaining the correctness-completeness evaluation. revision: yes
-
Referee: [§4] §4 (Annotation Framework): The reliability of the human-verified labels and the LLM-as-Judge protocol is load-bearing for all reported scores, but inter-annotator agreement statistics (e.g., Cohen’s kappa or percentage agreement), verifier count, and any post-hoc filtering criteria are not provided; these details are required to confirm that the 15K pairs constitute a high-quality benchmark.
Authors: We agree that these details are essential for establishing the quality of the benchmark. We will include inter-annotator agreement statistics (such as Cohen’s kappa and percentage agreement), the number of verifiers involved, and the post-hoc filtering criteria in the revised version of §4. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces RPC-Bench as a data-collection and evaluation pipeline: it extracts 15K QA pairs from review-rebuttal threads, applies a taxonomy aligned with research flow, and uses an LLM-as-a-Judge framework whose outputs are validated against human judgments. No equations, parameter fitting, or self-citation chains appear in the provided text. Performance numbers (68.2% correctness-completeness, 37.46% after conciseness) are direct measurements on the constructed benchmark rather than quantities derived from the benchmark itself by construction. The work is therefore self-contained against external human labels and contains no load-bearing steps that reduce to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Review-rebuttal exchanges contain representative why-what-how questions that reflect genuine paper comprehension challenges
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce RPC-Bench, a large-scale question-answering benchmark built from review-rebuttal exchanges... 15K human-verified QA pairs... fine-grained taxonomy aligned with the scientific research flow
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
F1-like = (1 + β²) × (Correctness × Completeness) / (β² × Correctness + Completeness); Informativeness = F1-like × Conciseness
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
AutoResearchBench is a new benchmark showing top AI agents achieve under 10% success on complex scientific literature discovery tasks that demand deep comprehension and open-ended search.
Reference graph
Works this paper leans on
-
[1]
Wayne C Booth, Gregory G Colomb, and Joseph M Williams
Peerqa: A scientific question answer- ing dataset from peer reviews.arXiv preprint arXiv:2502.13668. Wayne C Booth, Gregory G Colomb, and Joseph M Williams. 2009.The craft of research. University of Chicago press. Yelin Chen, Fanjin Zhang, and Jie Tang. 2025. Small language model makes an effective long text extractor. InProceedings of the AAAI Conference...
-
[2]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Chatglm: A family of large language mod- els from glm-130b to glm-4 all tools.Preprint, arXiv:2406.12793. Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryu- taro Tanno, and 1 others. 2025. Towards an ai co- scientist.arXiv preprint arXiv:2502.18864. Bernal Jiménez ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
mplug-docowl 1.5: Unified structure learning for ocr-free document understanding
mplug-docowl2: High-resolution compress- ing for ocr-free multi-page document understanding. Preprint, arXiv:2409.03420. Jiajie Jin, Yutao Zhu, Zhicheng Dou, Guanting Dong, Xinyu Yang, Chenghao Zhang, Tong Zhao, Zhao Yang, and Ji-Rong Wen. 2025. Flashrag: A modular toolkit for efficient retrieval-augmented generation research. InCompanion Proceedings of t...
-
[4]
Raptor: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations. Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. 2025. Agent laboratory: Using llm agents as research assis- tants.Preprint, arXiv:250...
-
[5]
The environment source code. 2. A natural language task description. Monkey:Yes, the success/fitness function can be used to initialize the Eureka reward search process. MemoRAG:Yes, the success/fitness function can be used to initialize the Eureka reward search process. Example 8 (Experimental Analysis): Question:What are the major errors identified in t...
work page 2021
-
[6]
Split combined questions into finer sub- questions for clarity but merge them if they cannot stand alone meaningfully
-
[7]
Ensure the completeness and consistency of the extracted QA pairs
-
[8]
Use content from the extra_rebuttal to enhance or clarify answers when applicable and relevant to the question
-
[9]
Ensure that the rebuttal content is fully utilized in the answers, forming comprehensive and clear QA pairs that correspond to the questions posed
-
[10]
Use your judgment to label each QA pair as' multimodal-related'if it either explicitly poses questions about the figures and tables in the paper or implicitly requires the content of these figures and tables to answer the question
-
[11]
The answers should be as comprehensive as possible, retaining any relevant content such as "references" that can assist in addressing the questions
-
[12]
Operation of multihead RSA modules
Use the original content from the review, rebuttal, and extra_rebuttal to construct the QA pairs, avoiding unnecessary modifications to the original text. 21 Figure 8: Screenshot of the Annotation Interface 1 Figure 9: Screenshot of the Annotation Interface 2 Input: review: It is novel enough to combine the advantages of two famous models (Transformer , R...
-
[13]
Block-Recurrent Transformer (BRT) [1] has been adopted as another baseline model for the NLP experiment in Section 4.3, and its results are presented as follows. | | BRT | RSA- BRT | | --------------------------- | ---------- | ---------- | | Enwik8 | 1.0746 | **1.0683** | | Text8 | 1.1652 | **1.1625** | 23 Figure 12: Screenshot of the Review Interface 2 ...
-
[14]
(1) A scaling experiment is conducted for RSA- BRT v/s BRT on Enwik8 dataset
Two additional experiments for Section 4.4 have been conducted during the second discussion phase, which are detailed in the responses to Reviewers mvWh and Zrmk. (1) A scaling experiment is conducted for RSA- BRT v/s BRT on Enwik8 dataset. The results are shown as follows. | # layers | 8 | | 10 | | 12 | | 14 | | | ------------------- | ---------- | -----...
-
[15]
Hutchins, D., Schlag, I., Wu, Y., Dyer, E., and Neyshabur, B. (2022). Block-recurrent transformers. In Advances in Neural Information Processing Systems. Output: [ { "question": "I think the draft would become better if there is a more complete explanation and figures about the self- attention with recurrence (RSA) operation.", "answer": "Thank you for th...
work page 2022
-
[16]
In the meanwhile, we have also reorganized the whole Section 3 to better explain the proposed RSA. Specifically, for a single head RSA, we have devoted a paragraph right after equation (4) to detail the different types of REMs i.e. $\\mathbf{ P}$ in the paper. For your easy reference, we have listed the multihead RSA operation below: Procedure for the Mul...
work page 2023
-
[17]
Extract the Question (Q): Reformulate the reviewer feedback into a clear, precise, and standalone question. Ensure the question: Includes all necessary context from both the review and rebuttal (e.g., clarify vague references such as "this figure" or "the results"). Is phrased in neutral and objective language, avoiding subjective or opinionated terms
-
[18]
Ensure the answer: Directly addresses the reformulated question
Extract the Answer (A): Reformulate the author's rebuttal into a concise, objective, and standalone answer. Ensure the answer: Directly addresses the reformulated question. Is based strictly on the rebuttal content. Avoid additional interpretations, subjective language, or opinions
-
[19]
Classify the Question: Classify the question into a precise subcategory based on its intent using the schema below (see categories below). Categories:
-
[20]
Concept Understanding [What]: Clarifies or explains key concepts, terminology, theoretical viewpoints, or information conveyed in figures, tables, or formulas
-
[21]
Methods 2.1. Method Disambiguation [What]: Clarifies methodological details to resolve misunderstandings or ambiguities, ensuring an accurate grasp of proposed approaches. 2.2. Method Mechanics [How]: Questions about the implementation or function of methodological workflow or components, such as the effect of specific modules in models. 2.3. Motivation A...
-
[22]
Experiments 3.1. Experimental Exposition [What]: Describes experimental outcomes, infers how modifications or variations could impact results or conclusions, and addresses reasoning tasks such as calculation, counting, or comparative analysis. 3.2. Experimental Setup [How]: About the design, configuration, and execution of experiments. 3.3. Experimental A...
-
[23]
Claim Verification : Binary classification tasks that assess the correctness of claims, hypotheses, or experimental conclusions. Output Format: Provide the processed data for each review-rebuttal pair in the following JSON format: [ { "review": "Original reviewer feedback", "rebuttal": "Original author rebuttal", "Q": "Generated question", "A": "Generated...
-
[24]
The answer must be professional, precise, concise, and clearly presented
-
[25]
All statements in your answer must be exclusively derived from the paper's content and directly relevant to the question, avoiding any information or claims not supported by the paper
-
[26]
The total length of your response must not exceed 3000 characters (including spaces). Question: {question} Paper: {content} Claim verification: You are an academic judgment specialist assigned to classify the following statement as strictly'True'or'False'based exclusively on the content of the provided research paper. Carefully read and analyze the entire...
-
[27]
The answer should deliver key content clearly, without excessive length or verbosity
Conciseness: Evaluate whether the predicted answer is brief and to the point, avoiding unnecessary repetition or irrelevant information. The answer should deliver key content clearly, without excessive length or verbosity. </Evaluation-Characteristics> <Rating-Scale> For each evaluation characteristic, assign a quality score between 0.00 (very bad) and 5....
-
[28]
Conciseness 0.00-1.00 (Very bad): The predicted answer is verbose or contains substantial irrelevant/ redundant information, making it unclear or unfocused. 1.01-2.00 (Bad): The predicted answer includes some redundancy or unnecessary details, affecting clarity. 2.01-3.00 (Moderate): The predicted answer is generally clear but could benefit from further c...
-
[29]
Correctness: Assess the proportion of content from the reference answer that is accurately reflected in the predicted answer . This is analogous to precision-focus on the accuracy and fidelity of included information, ensuring no distortions or misrepresentations. </Evaluation-Characteristics> <Rating-Scale> For each evaluation characteristic, assign a qu...
-
[30]
Correctness 0.00-1.00 (Very bad): The predicted answer consistently misrepresents or distorts the content of the reference answer, with substantial factual errors. 1.01-2.00 (Bad): The predicted answer contains multiple inaccuracies or significant misinterpretations relative to the reference answer. 2.01-3.00 (Moderate): The predicted answer accurately in...
-
[31]
Completeness: Assess the proportion of information in the predicted answer that overlaps with the reference answer. This is analogous to recall-consider whether the predicted answer adequately covers all major points and details provided by the reference answer, and does not omit essential content. </Evaluation-Characteristics> <Rating-Scale> For each eva...
-
[32]
Completeness 0.00-1.00 (Very bad): The predicted answer fails to include most of the key content from the reference answer, omitting essential points or details. 1.01-2.00 (Bad): The predicted answer is missing several important aspects found in the reference answer. 2.01-3.00 (Moderate): The predicted answer includes a moderate portion of the relevant co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.