Recognition: 2 theorem links
· Lean Theorem3D Generation for Embodied AI and Robotic Simulation: A Survey
Pith reviewed 2026-05-11 01:53 UTC · model grok-4.3
The pith
3D generation supports embodied AI by acting as data generator, environment builder, and sim-to-real bridge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
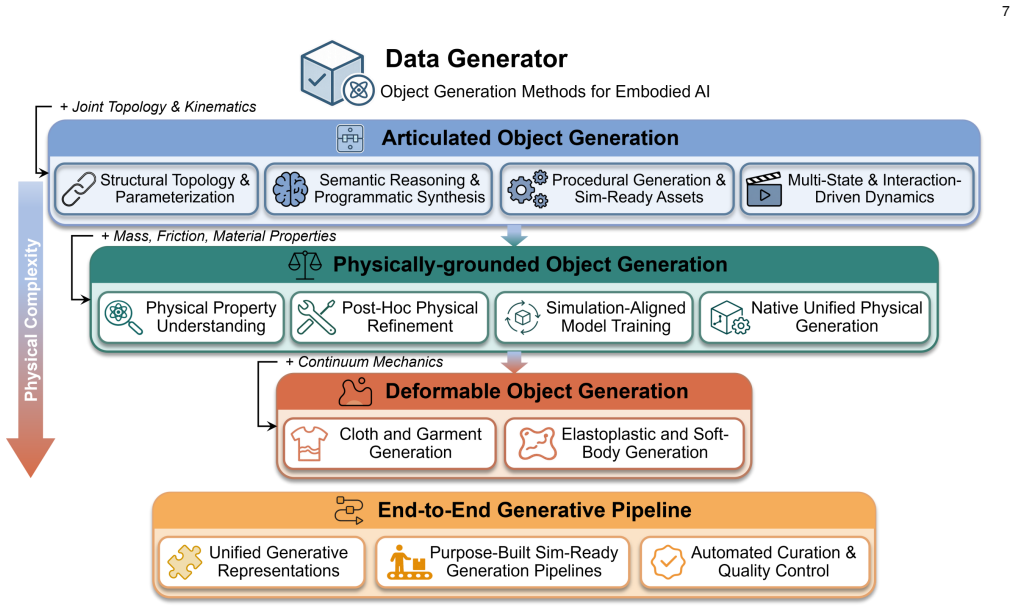
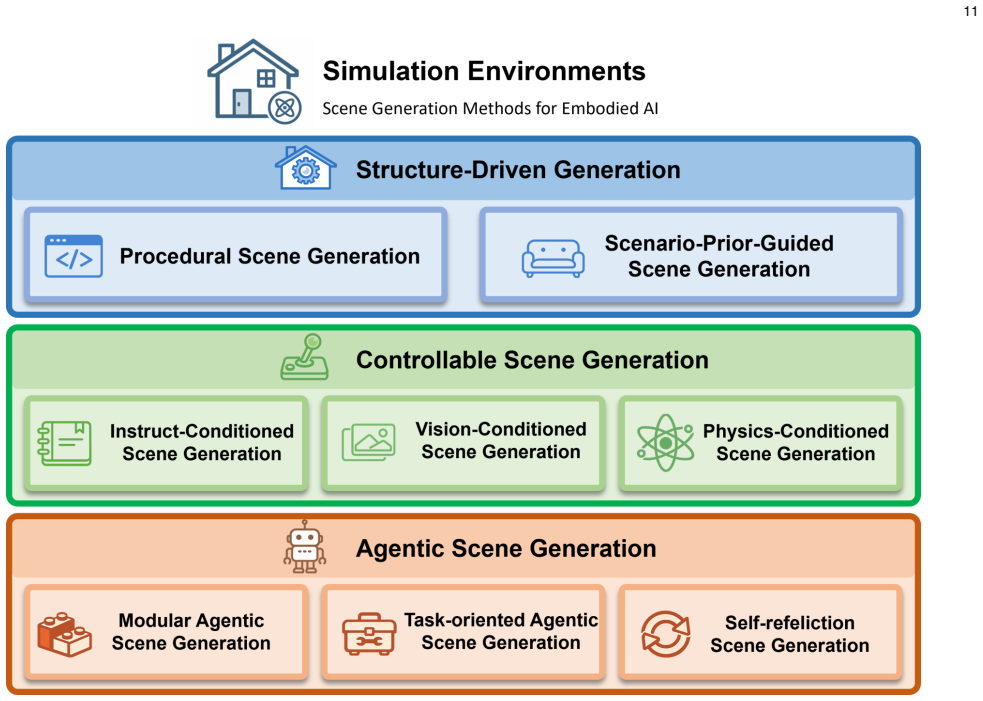
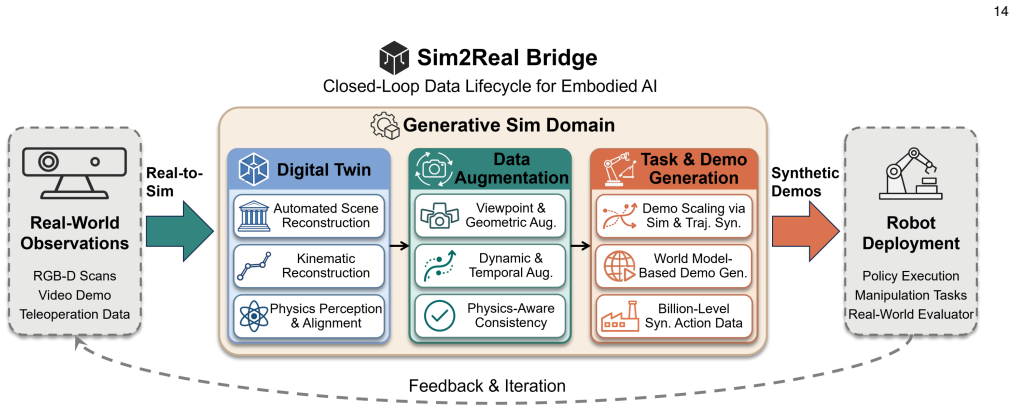
The paper claims that 3D generation contributes to embodied AI and robotic simulation through three distinct roles. In the Data Generator role it produces articulated, physically grounded, and deformable objects ready for interaction. In the Simulation Environments role it creates controllable, structure-aware, and agentic scenes that support task execution. In the Sim2Real Bridge role it enables digital-twin reconstruction, data augmentation, and synthetic demonstrations that aid real-world transfer. The literature is shown to be moving from emphasis on visual realism toward interaction readiness, while four main bottlenecks—limited physical annotations, the gap between geometric quality, a
What carries the argument
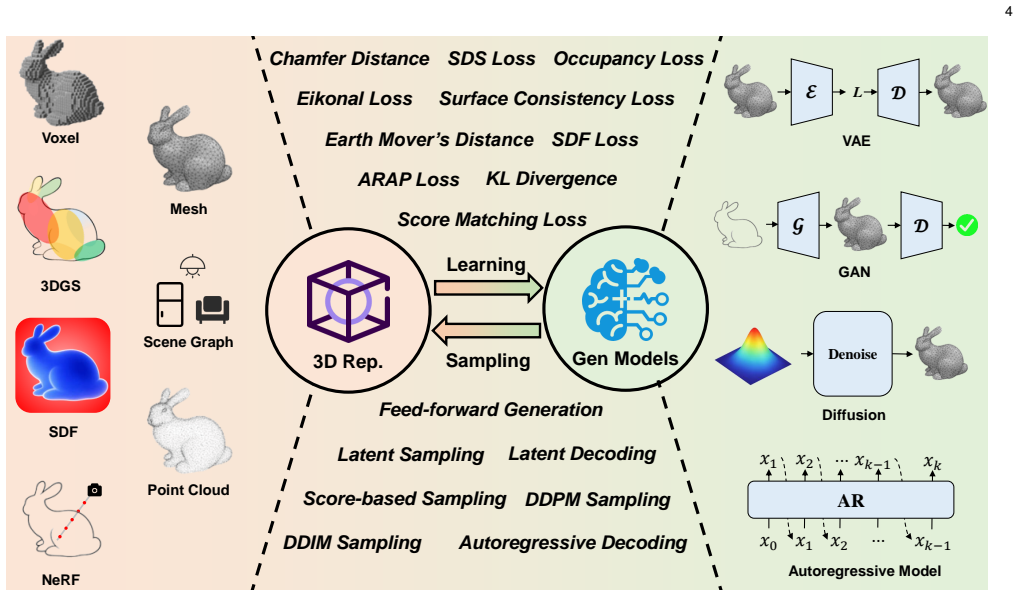
The three-role taxonomy (Data Generator, Simulation Environments, Sim2Real Bridge) used to classify existing 3D generation methods according to their contribution to embodied systems.
If this is right
- Future 3D generators must incorporate kinematic and material properties as first-class outputs rather than post-processing steps.
- Standardized benchmarks that measure interaction success and physical validity will be needed to replace current fragmented evaluation practices.
- Closing the physical-validity gap will directly improve the reliability of simulation-trained policies when transferred to real robots.
- Progress on physical annotations will accelerate the creation of large-scale, reusable asset libraries for embodied training.
Where Pith is reading between the lines
- The three-role structure could be used to design end-to-end pipelines that generate assets, scenes, and transfer data within a single consistent framework.
- Methods that jointly model geometry and dynamics may become central once physical validity is treated as a core requirement.
- The identified bottlenecks point to opportunities for hybrid approaches that combine generative models with physics engines or learned dynamics.
- Addressing the sim-to-real divide in 3D content could reduce the amount of real-world data needed for fine-tuning robot policies.
Load-bearing premise
That the reviewed methods can be exhaustively and unambiguously grouped into the three proposed roles and that the four listed bottlenecks are the central obstacles preventing 3D generation from supporting embodied intelligence.
What would settle it
A follow-up review that identifies a substantial body of 3D generation work for robotics that cannot be placed in any of the three roles, or a controlled experiment showing that visual realism alone produces successful sim-to-real robot deployment without physical annotations or validity checks.
Figures







read the original abstract
Embodied AI and robotic systems increasingly depend on scalable, diverse, and physically grounded 3D content for simulation-based training and real-world deployment. While 3D generative modeling has advanced rapidly, embodied applications impose requirements far beyond visual realism: generated objects must carry kinematic structure and material properties, scenes must support interaction and task execution, and the resulting content must bridge the gap between simulation and reality. This survey reviews 3D generation for embodied AI and organizes the literature around three roles that 3D generation plays in embodied systems. In Data Generator, 3D generation produces simulation-ready objects and assets, including articulated, physically grounded, and deformable content for downstream interaction; in Simulation Environments, it constructs interactive and task-oriented worlds, spanning structure-aware, controllable, and agentic scene generation; and in Sim2Real Bridge, it supports digital twin reconstruction, data augmentation, and synthetic demonstrations for downstream robot learning and real-world transfer. We also show that the field is shifting from visual realism toward interaction readiness, and we identify the main bottlenecks, including limited physical annotations, the gap between geometric quality and physical validity, fragmented evaluation, and the persistent sim-to-real divide, that must be addressed for 3D generation to become a dependable foundation for embodied intelligence. Our project page is at https://3dgen4robot.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey of 3D generative modeling for embodied AI and robotic simulation. It organizes the literature around three roles that 3D generation plays: Data Generator (producing articulated, physically grounded, and deformable assets for interaction), Simulation Environments (constructing structure-aware, controllable, and agentic interactive scenes), and Sim2Real Bridge (supporting digital-twin reconstruction, data augmentation, and synthetic demonstrations for robot learning). The authors argue that the field is shifting from visual realism toward interaction readiness and identify four main bottlenecks: limited physical annotations, the gap between geometric quality and physical validity, fragmented evaluation, and the persistent sim-to-real divide.
Significance. If the taxonomy is shown to be comprehensive and the cited works representative, the survey would provide a useful organizing framework for researchers at the intersection of 3D generation and robotics. The explicit mapping of generation techniques to embodied requirements and the forward-looking discussion of bottlenecks could help focus community efforts on interaction-ready content rather than purely visual fidelity.
major comments (2)
- [Section 2 (Taxonomy Overview)] The central taxonomy partitions the literature into three roles, but the manuscript does not explicitly address potential overlaps (e.g., a single method that simultaneously generates assets and constructs scenes). Without a clear discussion of boundary cases or a supplementary table mapping representative papers to roles, the claim that the three roles provide a complete organizational lens remains difficult to evaluate.
- [Section 6 (Trends and Bottlenecks)] The assertion that the field is shifting toward interaction readiness is presented as an observed trend, yet the supporting evidence consists only of qualitative descriptions of selected papers rather than a systematic count or temporal analysis of publications emphasizing physical properties versus visual quality. This weakens the load-bearing claim that the community has moved beyond visual realism.
minor comments (3)
- [Abstract and Conclusion] The project page is referenced but not described in the text; a short paragraph summarizing the resources (e.g., categorized paper lists or code links) would increase utility.
- [Section 3.2] Terminology such as 'agentic scene generation' and 'physically grounded' is used without a concise definition or reference to a prior survey that established the terms.
- [Section 3.1] Several recent works on physics-informed neural representations (e.g., those incorporating material parameters directly into generative models) appear under-cited in the Data Generator section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment of our survey. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Section 2 (Taxonomy Overview)] The central taxonomy partitions the literature into three roles, but the manuscript does not explicitly address potential overlaps (e.g., a single method that simultaneously generates assets and constructs scenes). Without a clear discussion of boundary cases or a supplementary table mapping representative papers to roles, the claim that the three roles provide a complete organizational lens remains difficult to evaluate.
Authors: We acknowledge that the current presentation of the taxonomy does not explicitly discuss overlaps or boundary cases between the three roles. In the revised manuscript, we will add a dedicated paragraph in Section 2 that addresses potential overlaps, such as methods whose primary contribution is asset generation but that also enable scene construction, and we will include a supplementary table mapping representative papers to their primary (and, where applicable, secondary) roles. This will clarify the organizational lens without altering the core taxonomy. revision: yes
-
Referee: [Section 6 (Trends and Bottlenecks)] The assertion that the field is shifting toward interaction readiness is presented as an observed trend, yet the supporting evidence consists only of qualitative descriptions of selected papers rather than a systematic count or temporal analysis of publications emphasizing physical properties versus visual quality. This weakens the load-bearing claim that the community has moved beyond visual realism.
Authors: The trend toward interaction readiness is synthesized from the body of work reviewed in the survey, where we observe an increasing emphasis on physical properties, kinematic structure, and task-level interaction in more recent contributions. We agree that a quantitative bibliometric count would provide additional rigor; however, performing a comprehensive temporal analysis of all publications in the field lies outside the scope of this survey. In the revision, we will strengthen Section 6 by adding a structured temporal discussion with explicit year-based examples and a simple categorization count drawn from the papers already included, to better substantiate the observed shift while remaining within the survey format. revision: partial
Circularity Check
No significant circularity: descriptive survey framework
full rationale
This is a literature review paper that organizes existing work on 3D generation into three descriptive roles (Data Generator, Simulation Environments, Sim2Real Bridge) and notes trends and bottlenecks. No mathematical derivations, equations, fitted parameters, predictions, or uniqueness theorems are present. The central organizational claim is presented as a lens for reviewing literature rather than a derived result, with no self-citation chains or reductions of claims to the paper's own inputs. The analysis is self-contained against external benchmarks in the surveyed field.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThis survey reviews 3D generation for embodied AI and organizes the literature around three roles... Data Generator... Simulation Environments... Sim2Real Bridge... shifting from visual realism toward interaction readiness
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearsimulation readiness... Geometric validity... Physical parameterization... Kinematic executability... Simulator compatibility
Reference graph
Works this paper leans on
-
[1]
Align- ing cyber space with physical world: A comprehensive survey on embodied ai,
Y. Liu, W. Chen, Y. Bai, X. Liang, G. Li, W. Gao, and L. Lin, “Align- ing cyber space with physical world: A comprehensive survey on embodied ai,”IEEE/ASME Transactions on Mechatronics, 2025
work page 2025
-
[2]
A survey: Learning embodied intelligence from physical simulators and world models,
X. Long, Q. Zhao, K. Zhang, Z. Zhang, D. Wang, Y. Liu, Z. Shu, Y. Lu, S. Wang, X. Weiet al., “A survey: Learning embodied intelligence from physical simulators and world models,”arXiv preprint arXiv:2507.00917, 2025
-
[3]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
work page 2025
-
[4]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine- grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P . Xu, T. Xiao, F. Xia, J. Wu, P . Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inCoRL. PMLR, 2023, pp. 2165–2183
work page 2023
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P . Sanketiet al., “Openvla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision- language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim, C. Finn, and P . Liang, “Fine-tuning vision-language- action models: Optimizing speed and success,”arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dha- balia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusaiet al., “π0.5: a vision-language-action model with open-world gener- alization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
S. Tao, F. Xiang, A. Shukla, Y. Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y. Liu, T.-k. Chanet al., “Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,”arXiv preprint arXiv:2410.00425, 2024
-
[11]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y. Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handaet al., “Isaac gym: High performance gpu-based physics simulation for robot learning,”arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review arXiv 2021
-
[12]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y. Liu, Z. Li, Q. Liang, X. Lin, Y. Ge, Z. Guet al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
L. Le, J. Xie, W. Liang, H.-J. Wang, Y. Yang, Y. J. Ma, K. Vedder, A. Krishna, D. Jayaraman, and E. Eaton, “Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model,” inICLR, 2025
work page 2025
-
[14]
Urdf-anything: Constructing articulated objects with 3d multimodal language model,
Z. Li, X. Bai, J. Zhang, Z. Wu, C. Xu, Y. Li, C. Hou, and S. Zhang, “Urdf-anything: Constructing articulated objects with 3d multimodal language model,”arXiv preprint arXiv:2511.00940, 2025
-
[15]
X. Li, C. Yu, W. Du, Y. Jiang, T. Xie, Y. Chen, Y. Yang, and C. Jiang, “Dress-1-to-3: Single image to simulation-ready 3d outfit with diffusion prior and differentiable physics,”ACM TOG, vol. 44, no. 4, pp. 1–16, 2025
work page 2025
-
[16]
Garmentlab: A unified simulation and benchmark for garment manipulation,
H. Lu, R. Wu, Y. Li, S. Li, Z. Zhu, C. Ning, Y. Shen, L. Luo, Y. Chen, and H. Dong, “Garmentlab: A unified simulation and benchmark for garment manipulation,”NeurIPS, vol. 37, pp. 11 866–11 903, 2024
work page 2024
-
[17]
Physcene: Physically interactable 3d scene synthesis for embodied ai,
Y. Yang, B. Jia, P . Zhi, and S. Huang, “Physcene: Physically interactable 3d scene synthesis for embodied ai,” inCVPR, 2024, pp. 16 262–16 272
work page 2024
-
[18]
arXiv preprint arXiv:2401.17807 (2024)
X. Li, Q. Zhang, D. Kang, W. Cheng, Y. Gao, J. Zhang, Z. Liang, J. Liao, Y.-P . Cao, and Y. Shan, “Advances in 3d generation: A survey,”arXiv preprint arXiv:2401.17807, 2024
-
[19]
Recent advances in 3d object and scene generation: A survey,
X. Tang, R. Li, and X. Fan, “Recent advances in 3d object and scene generation: A survey,”arXiv preprint arXiv:2504.11734, 2025
-
[20]
Diffusion models for 3d generation: A survey,
C. Wang, H.-Y. Peng, Y.-T. Liu, J. Gu, and S.-M. Hu, “Diffusion models for 3d generation: A survey,”Computational Visual Media, vol. 11, no. 1, pp. 1–28, 2025. 22
work page 2025
-
[21]
Physx-3d: Physical- grounded 3d asset generation,
Z. Cao, Z. Chen, L. Pan, and Z. Liu, “Physx-3d: Physical- grounded 3d asset generation,”arXiv preprint arXiv:2507.12465, 2025
-
[22]
Nap: Neural 3d articulated object prior,
J. Lei, C. Deng, W. B. Shen, L. J. Guibas, and K. Daniilidis, “Nap: Neural 3d articulated object prior,”NeurIPS, vol. 36, pp. 31 878– 31 894, 2023
work page 2023
-
[23]
Cage: Con- trollable articulation generation,
J. Liu, H. I. I. Tam, A. Mahdavi-Amiri, and M. Savva, “Cage: Con- trollable articulation generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 880–17 889
work page 2024
-
[24]
arXiv preprint arXiv:2505.05474 (2025)
B. Wen, H. Xie, Z. Chen, F. Hong, and Z. Liu, “3d scene genera- tion: A survey,”arXiv preprint arXiv:2505.05474, 2025
-
[25]
arXiv preprint arXiv:2506.10600 (2025)
X. Wang, L. Liu, Y. Cao, R. Wu, W. Qin, D. Wang, W. Sui, and Z. Su, “Embodiedgen: Towards a generative 3d world engine for embodied intelligence,”arXiv preprint arXiv:2506.10600, 2025
-
[26]
Seed3d 1.0: From images to high-fidelity simulation- ready 3d assets,
B. Seed, “Seed3d 1.0: From images to high-fidelity simulation- ready 3d assets,” 2025
work page 2025
-
[27]
K. Zhang, P . Yun, J. Cen, J. Cai, D. Zhu, H. Yuan, C. Zhao, T. Feng, M. Y. Wang, Q. Chenet al., “Generative artificial intelligence in robotic manipulation: A survey,”arXiv preprint arXiv:2503.03464, 2025
-
[28]
Structure-from-motion revis- ited,
J. L. Sch ¨onberger and J.-M. Frahm, “Structure-from-motion revis- ited,” inCVPR, 2016, pp. 4104–4113
work page 2016
-
[29]
Graph-to- 3d: End-to-end generation and manipulation of 3d scenes using scene graphs,
H. Dhamo, F. Manhardt, N. Navab, and F. Tombari, “Graph-to- 3d: End-to-end generation and manipulation of 3d scenes using scene graphs,” inICCV, 2021, pp. 16 352–16 361
work page 2021
-
[30]
Deepsdf: Learning continuous signed distance functions for shape representation,
J. J. Park, P . Florence, J. Straub, R. Newcombe, and S. Lovegrove, “Deepsdf: Learning continuous signed distance functions for shape representation,” inCVPR, 2019, pp. 165–174
work page 2019
-
[31]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P . Srinivasan, M. Tancik, J. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” inECCV, 2020
work page 2020
-
[32]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakiset al., “3d gaussian splatting for real-time radiance field rendering.”ACM TOG, vol. 42, no. 4, pp. 139–1, 2023
work page 2023
-
[33]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics,
T. Xie, Z. Zong, Y. Qiu, X. Li, Y. Feng, Y. Yang, and C. Jiang, “Physgaussian: Physics-integrated 3d gaussians for generative dynamics,” inCVPR, 2024, pp. 4389–4398
work page 2024
-
[34]
Structured 3d latents for scalable and versatile 3d generation,
J. Xiang, Z. Lv, S. Xu, Y. Deng, R. Wang, B. Zhang, D. Chen, X. Tong, and J. Yang, “Structured 3d latents for scalable and versatile 3d generation,” inCVPR, 2025, pp. 21 469–21 480
work page 2025
-
[35]
Learn- ing representations and generative models for 3d point clouds,
P . Achlioptas, O. Diamanti, I. Mitliagkas, and L. Guibas, “Learn- ing representations and generative models for 3d point clouds,” inICML. PMLR, 2018, pp. 40–49
work page 2018
-
[36]
Variational autoencoders for deforming 3d mesh models,
Q. Tan, L. Gao, Y.-K. Lai, and S. Xia, “Variational autoencoders for deforming 3d mesh models,” inCVPR, 2018, pp. 5841–5850
work page 2018
-
[37]
Mesh variational autoencoders with edge contraction pooling,
Y.-J. Yuan, Y.-K. Lai, J. Yang, Q. Duan, H. Fu, and L. Gao, “Mesh variational autoencoders with edge contraction pooling,” inCVPR Workshop, 2020, pp. 274–275
work page 2020
-
[38]
Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling,
J. Wu, C. Zhang, T. Xue, W. T. Freeman, and J. B. Tenenbaum, “Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling,” inNeurIPS, vol. 29, 2016
work page 2016
-
[39]
Sdf-stylegan: implicit sdf-based stylegan for 3d shape generation,
X. Zheng, Y. Liu, P . Wang, and X. Tong, “Sdf-stylegan: implicit sdf-based stylegan for 3d shape generation,” inComputer Graphics Forum, vol. 41, no. 5. Wiley Online Library, 2022, pp. 52–63
work page 2022
-
[40]
Graf: Gen- erative radiance fields for 3d-aware image synthesis,
K. Schwarz, Y. Liao, M. Niemeyer, and A. Geiger, “Graf: Gen- erative radiance fields for 3d-aware image synthesis,”NeurIPS, vol. 33, pp. 20 154–20 166, 2020
work page 2020
-
[41]
pi-gan: Periodic implicit generative adversarial networks for 3d- aware image synthesis,
E. R. Chan, M. Monteiro, P . Kellnhofer, J. Wu, and G. Wetzstein, “pi-gan: Periodic implicit generative adversarial networks for 3d- aware image synthesis,” inCVPR, 2021, pp. 5799–5809
work page 2021
-
[42]
3d shape generation and completion through point-voxel diffusion,
L. Zhou, Y. Du, and J. Wu, “3d shape generation and completion through point-voxel diffusion,” inICCV, 2021, pp. 5826–5835
work page 2021
-
[43]
Lion: Latent point diffusion models for 3d shape genera- tion,
A. Vahdat, F. Williams, Z. Gojcic, O. Litany, S. Fidler, K. Kreis et al., “Lion: Latent point diffusion models for 3d shape genera- tion,”NeurIPS, vol. 35, pp. 10 021–10 039, 2022
work page 2022
-
[44]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,
B. Zhang, J. Tang, M. Niessner, and P . Wonka, “3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,”ACM TOG, vol. 42, no. 4, pp. 1–16, 2023
work page 2023
-
[45]
Dreamfusion: Text-to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text-to-3d using 2d diffusion,” inICLR, 2023
work page 2023
-
[46]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Atiss: Autoregressive transformers for indoor scene synthesis,
D. Paschalidou, A. Kar, M. Shugrina, K. Kreis, A. Geiger, and S. Fidler, “Atiss: Autoregressive transformers for indoor scene synthesis,” inNeurIPS, vol. 34, 2021, pp. 12 013–12 026
work page 2021
-
[48]
J. Zhang, F. Xiong, G. Wang, and M. Xu, “G3pt: unleash the power of autoregressive modeling in 3d generation via cross- scale querying transformer,” inIJCAI, 2025, pp. 2350–2358
work page 2025
-
[49]
Magicarticulate: Make your 3d models articulation-ready,
C. Song, J. Zhang, X. Li, F. Yang, Y. Chen, Z. Xu, J. H. Liew, X. Guo, F. Liu, J. Fenget al., “Magicarticulate: Make your 3d models articulation-ready,” inCVPR, 2025, pp. 15 998–16 007
work page 2025
-
[50]
Urdf-anything+: Autoregressive articulated 3d models gener- ation for physical simulation,
Z. Wu, Y. Xin, C. Hou, M. Chen, Y. Lyu, J. Zhang, and S. Zhang, “Urdf-anything+: Autoregressive articulated 3d models gener- ation for physical simulation,”arXiv preprint arXiv:2603.14010, 2026
-
[51]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 5026–5033
work page 2012
-
[52]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Maliket al., “Habitat: A platform for embodied ai research,” inICCV, 2019, pp. 9339–9347
work page 2019
-
[53]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Her- rasti, M. Deitke, K. Ehsani, D. Gordon, Y. Zhuet al., “Ai2- thor: An interactive 3d environment for visual ai,”arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review arXiv 2017
-
[54]
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation,
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın- Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sunet al., “Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation,” inCoRL. PMLR, 2023, pp. 80–93
work page 2023
-
[55]
Pybullet, a python module for physics simulation for games, robotics and machine learning,
E. Coumans and Y. Bai, “Pybullet, a python module for physics simulation for games, robotics and machine learning,” http:// pybullet.org, 2016–2021
work page 2016
-
[56]
Genesis: A generative and universal physics engine for robotics and beyond,
G. Authors, “Genesis: A generative and universal physics engine for robotics and beyond,” December 2024. [Online]. Available: https://github.com/Genesis-Embodied-AI/Genesis
work page 2024
-
[57]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P . Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” inIROS. IEEE, 2017, pp. 23–30
work page 2017
-
[58]
B. Mehta, M. Diaz, F. Golemo, C. J. Pal, and L. Paull, “Active domain randomization,” inCoRL. PMLR, 2020, pp. 1162–1176
work page 2020
-
[59]
Bayessim: adaptive domain randomization via probabilistic inference for robotics simula- tors,
F. Ramos, R. C. Possas, and D. Fox, “Bayessim: adaptive domain randomization via probabilistic inference for robotics simula- tors,”arXiv preprint arXiv:1906.01728, 2019
-
[60]
Closing the sim-to-real loop: Adapting simulation randomization with real world experience,
Y. Chebotar, A. Handa, V . Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox, “Closing the sim-to-real loop: Adapting simulation randomization with real world experience,” inIEEE ICRA. IEEE, 2019, pp. 8973–8979
work page 2019
-
[61]
S. James, P . Wohlhart, M. Kalakrishnan, D. Kalashnikov, A. Irpan, J. Ibarz, S. Levine, R. Hadsell, and K. Bousmalis, “Sim-to-real via sim-to-sim: Data-efficient robotic grasping via randomized- to-canonical adaptation networks,” inCVPR, 2019, pp. 12 627– 12 637
work page 2019
-
[62]
Robogsim: A real2sim2real robotic gaus- sian splatting simulator,
X. Li, J. Li, Z. Zhang, R. Zhang, F. Jia, T. Wang, H. Fan, K.-K. Tseng, and R. Wang, “Robogsim: A real2sim2real robotic gaus- sian splatting simulator,”arXiv preprint arXiv:2411.11839, 2024
-
[63]
Exogs: A 4d real-to-sim-to-real frame- work for scalable manipulation data collection,
Y. Wang, R. Zhang, M. Li, H. Shi, J. Wang, D. Li, J. Ren, W. Liu, W. Wang, and H.-S. Fang, “Exogs: A 4d real-to-sim-to-real frame- work for scalable manipulation data collection,”arXiv preprint arXiv:2601.18629, 2026
-
[64]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, p. 440, 2018
work page internal anchor Pith review arXiv 2018
-
[65]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y. Fang, F. Hu, S. Huang, K. Kundalia, Y.-C. Linet al., “Dreamgen: Unlocking general- ization in robot learning through video world models,”arXiv preprint arXiv:2505.12705, 2025
-
[66]
Roboscape: Physics-informed embodied world model, 2025
Y. Shang, X. Zhang, Y. Tang, L. Jin, C. Gao, W. Wu, and Y. Li, “Roboscape: Physics-informed embodied world model,”arXiv preprint arXiv:2506.23135, 2025
-
[67]
Urdformer: A pipeline for con- structing articulated simulation environments from real-world images,
Z. Chen, A. Walsman, M. Memmel, K. Mo, A. Fang, K. Vemuri, A. Wu, D. Fox, and A. Gupta, “Urdformer: A pipeline for con- structing articulated simulation environments from real-world images,”arXiv preprint arXiv:2405.11656, 2024
-
[68]
Singapo: Single image controlled generation of articulated parts in objects,
J. Liu, D. Iliash, A. X. Chang, M. Savva, and A. M. Amiri, “Singapo: Single image controlled generation of articulated parts in objects,” inICLR, 2025
work page 2025
-
[69]
Real2code: Recon- struct articulated objects via code generation,
Z. Mandi, Y. Weng, D. Bauer, and S. Song, “Real2code: Recon- struct articulated objects via code generation,” inICLR, 2025
work page 2025
-
[70]
Meshart: Generating ar- ticulated meshes with structure-guided transformers,
D. Gao, Y. Siddiqui, L. Li, and A. Dai, “Meshart: Generating ar- ticulated meshes with structure-guided transformers,” inCVPR, 2025, pp. 618–627. 23
work page 2025
-
[71]
Partrm: Modeling part-level dynamics with large cross-state reconstruction model,
M. Gao, Y. Pan, H.-a. Gao, Z. Zhang, W. Li, H. Dong, H. Tang, L. Yi, and H. Zhao, “Partrm: Modeling part-level dynamics with large cross-state reconstruction model,” inCVPR, 2025, pp. 7004– 7014
work page 2025
-
[72]
Artformer: Controllable generation of diverse 3d articulated objects,
J. Su, Y. Feng, Z. Li, J. Song, Y. He, B. Ren, and B. Xu, “Artformer: Controllable generation of diverse 3d articulated objects,” in CVPR, 2025, pp. 1894–1904
work page 2025
-
[73]
Artiworld: Llm-driven articulation of 3d objects in scenes,
Y. Yang, L. Xie, Z. Luo, Z. Zhao, T. Ding, M. Gao, and F. Zheng, “Artiworld: Llm-driven articulation of 3d objects in scenes,” arXiv preprint arXiv:2511.12977, 2025
-
[74]
Articulate anymesh: Open-vocabulary 3d articu- lated objects modeling,
X. Qiu, J. Yang, Y. Wang, Z. Chen, Y. Wang, T.-H. Wang, Z. Xian, and C. Gan, “Articulate anymesh: Open-vocabulary 3d articu- lated objects modeling,”arXiv preprint arXiv:2502.02590, 2025
-
[75]
Articulate that object part (atop): 3d part articulation via text and motion personaliza- tion,
A. Vora, S. Nag, K. Wang, and H. Zhang, “Articulate that object part (atop): 3d part articulation via text and motion personaliza- tion,”arXiv preprint arXiv:2502.07278, 2025
-
[76]
Artilatent: Realistic articu- lated 3d object generation via structured latents,
H. Chen, Y. Lan, Y. Chen, and X. Pan, “Artilatent: Realistic articu- lated 3d object generation via structured latents,” inSIGGRAPH Asia, 2025, pp. 1–11
work page 2025
-
[77]
Artgen: Conditional generative modeling of ar- ticulated objects in arbitrary part-level states,
H. Wang, X. Yuan, F. Zhang, R. Jian, Y. Zhu, X. Qiao, and Y. Huang, “Artgen: Conditional generative modeling of ar- ticulated objects in arbitrary part-level states,”arXiv preprint arXiv:2512.12395, 2025
-
[78]
Dreamart: Generating interactable articulated objects from a single image,
R. Lu, Y. Liu, J. Tang, J. Ni, Y. Wang, D. Wan, G. Zeng, Y. Chen, and S. Huang, “Dreamart: Generating interactable articulated objects from a single image,”arXiv preprint arXiv:2507.05763, 2025
-
[79]
Gaot: Generating articulated objects through text-guided diffusion models,
H. Sun, L. Fan, D. Di, and S. Liu, “Gaot: Generating articulated objects through text-guided diffusion models,” inACM MM Asia, 2025, pp. 1–7
work page 2025
-
[80]
Kinematify: Open-vocabulary synthesis of high-dof articulated objects,
J. Wang, D. Wang, J. Hu, Q. Zhang, J. Yu, and L. Xu, “Kinematify: Open-vocabulary synthesis of high-dof articulated objects,”arXiv preprint arXiv:2511.01294, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.