Recognition: 2 theorem links
· Lean TheoremDeepTutor: Towards Agentic Personalized Tutoring
Pith reviewed 2026-05-12 00:59 UTC · model grok-4.3
The pith
DeepTutor shows that an agentic framework combining static knowledge with dynamic learner memory can deliver personalized tutoring and boost reasoning in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
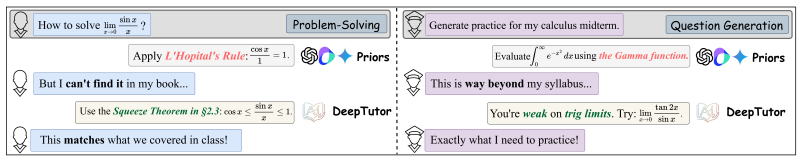
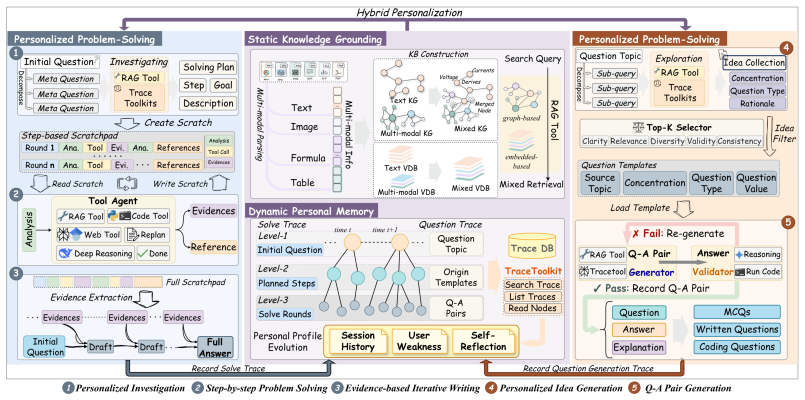
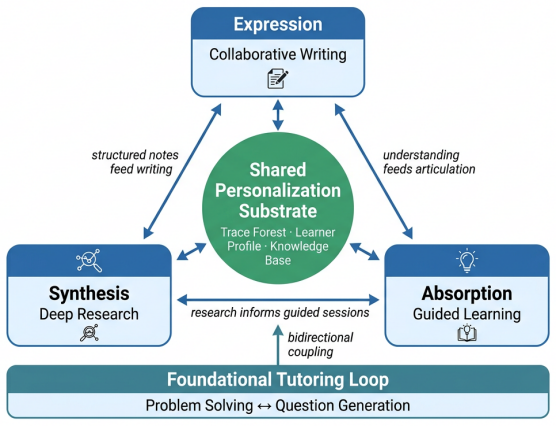
DeepTutor is a fully open-source agentic framework that unifies citation-grounded problem tutoring with difficulty-calibrated question generation. A hybrid personalization engine couples static knowledge grounding with dynamic learner memory, continuously adapting each interaction to the student's evolving needs. The same substrate extends to adaptive learning workflows, interactive books, and proactive multi-channel tutoring agents. Evaluations on TutorBench using an LLM-based first-person interactive protocol with a profile-driven student simulator, plus complementary benchmarks, show average gains of 10.8 percent on personalized metrics and 29.4 percent on general agentic reasoning across
What carries the argument
The hybrid personalization engine that couples static knowledge grounding with dynamic learner memory to adapt every tutoring interaction to the individual student's evolving profile.
If this is right
- The framework can be extended directly to adaptive learning workflows, interactive books, and proactive multi-channel tutoring agents without new core components.
- Personalized metrics improve by 10.8 percent on average while general agentic reasoning strengthens by 29.4 percent across five different backbone models.
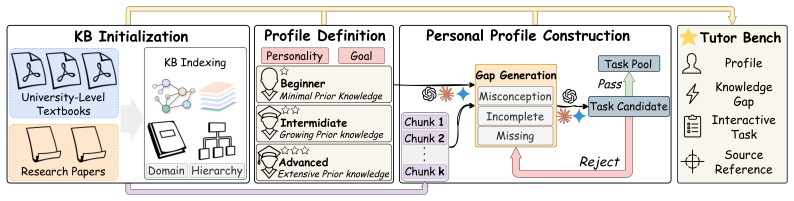
- TutorBench supplies an interactive benchmark grounded in university curricula across five domains for consistent evaluation of personalization.
- Ablation studies and human-alignment checks confirm the framework remains robust when individual components are removed or varied.
Where Pith is reading between the lines
- If the personalization engine scales, schools could deploy consistent one-on-one guidance for large numbers of students without proportional increases in human tutor time.
- The same hybrid memory approach could transfer to other sequential decision domains such as medical case training or technical skill acquisition.
- Combining the dynamic memory with external sensors for real-time learner state would create a testable next version of the engine.
Load-bearing premise
The assumption that an LLM-based interactive evaluation using a profile-driven student simulator accurately measures real-world tutoring effectiveness and actual learning gains.
What would settle it
A study in which real students complete the same TutorBench tasks with DeepTutor versus non-personalized tutoring and show no difference in post-test scores or retention after one week.
Figures



read the original abstract
Education is one of the most promising real-world applications for Large Language Models (LLMs). However, current LLMs rely on static pre-training knowledge and lack adaptation to individual learners, while existing RAG systems fall short in delivering personalized, guided feedback. To bridge this gap, we present DeepTutor, a fully open-source agentic framework that unifies citation-grounded problem tutoring with difficulty-calibrated question generation. A hybrid personalization engine couples static knowledge grounding with dynamic learner memory, continuously adapting each interaction to the student's evolving needs. The same personalization substrate further extends to adaptive learning workflows, interactive books, and proactive multi-channel tutoring agents. To evaluate personalized tutoring, we introduce TutorBench, an interactive benchmark incorporating customized learner profiles grounded in university-level curricula across five domains. We further propose an LLM-based first-person interactive evaluation protocol that conducts assessments via a profile-driven student simulator. Complementary evaluations on established benchmarks, supported by human-alignment and ablation studies, confirm the framework's robustness and general utility. Results show that DeepTutor improves personalized metrics by 10.8\% on average and strengthens general agentic reasoning across five backbone models by 29.4\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeepTutor, a fully open-source agentic LLM framework for personalized tutoring that combines citation-grounded problem solving with difficulty-calibrated question generation and a hybrid personalization engine using static knowledge grounding plus dynamic learner memory. It proposes TutorBench, an interactive benchmark with university-level learner profiles across five domains, and an LLM-based first-person evaluation protocol that employs a profile-driven student simulator. Complementary results on established benchmarks with human-alignment and ablation studies are reported, along with quantitative claims of 10.8% average gains on personalized metrics and 29.4% strengthening of general agentic reasoning across five backbone models.
Significance. If the evaluation protocol and simulator were shown to track real human learning gains, the work would offer a practical open-source substrate for adaptive tutoring systems and multi-channel agents, with credit due for releasing the full framework, extending personalization to interactive books and proactive agents, and testing across multiple backbones. The current reliance on an unvalidated closed-loop simulator, however, substantially limits the strength of the central claims.
major comments (3)
- [Abstract] Abstract: the claim of 10.8% average improvement on personalized metrics is presented without defining the metrics themselves, without naming the baselines used for comparison, and without reporting statistical details such as variance, number of trials, or significance tests.
- [Abstract] Abstract and evaluation protocol description: the LLM-based first-person interactive evaluation that relies on the profile-driven student simulator is asserted to measure tutoring effectiveness, yet the text states that human-alignment and ablation studies are provided only for established benchmarks, not for the novel TutorBench interactions or simulator outputs; no correlation with real pre/post-test human learning gains is shown.
- [Abstract] Evaluation section (implied by abstract claims): the reported 29.4% lift in agentic reasoning across five backbone models is computed inside the same LLM-simulator loop; if the simulator and tutor share model families or training data, the measured gains may partly reflect self-consistency rather than independent pedagogical improvement, and no cross-model ablation isolating this risk is described.
minor comments (1)
- [Abstract] The abstract refers to 'personalized metrics' and 'general agentic reasoning' without a forward reference to the precise definitions or tables that contain them.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We address each major comment point by point below, with clear indications of revisions made to the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 10.8% average improvement on personalized metrics is presented without defining the metrics themselves, without naming the baselines used for comparison, and without reporting statistical details such as variance, number of trials, or significance tests.
Authors: We agree that the abstract would benefit from greater precision on this point. In the revised manuscript we have updated the abstract to briefly define the personalized metrics (learner engagement, knowledge retention, and adaptation accuracy), name the primary baselines (vanilla LLM tutors and standard RAG systems), and direct readers to the main text for the full statistical reporting, including variance across trials, number of runs, and significance tests. revision: yes
-
Referee: [Abstract] Abstract and evaluation protocol description: the LLM-based first-person interactive evaluation that relies on the profile-driven student simulator is asserted to measure tutoring effectiveness, yet the text states that human-alignment and ablation studies are provided only for established benchmarks, not for the novel TutorBench interactions or simulator outputs; no correlation with real pre/post-test human learning gains is shown.
Authors: The manuscript already states that human-alignment and ablation studies apply to established benchmarks. For TutorBench we employ the profile-driven simulator to support scalable, interactive evaluation. We have expanded the evaluation section with additional details on the simulator's design and its grounding in realistic university-level learner profiles. We acknowledge that direct correlation with real pre/post-test human learning gains is not shown; this limitation is now explicitly noted in the revised limitations section, with human validation identified as future work. revision: partial
-
Referee: [Abstract] Evaluation section (implied by abstract claims): the reported 29.4% lift in agentic reasoning across five backbone models is computed inside the same LLM-simulator loop; if the simulator and tutor share model families or training data, the measured gains may partly reflect self-consistency rather than independent pedagogical improvement, and no cross-model ablation isolating this risk is described.
Authors: The 29.4% figure is the average improvement in agentic reasoning metrics obtained when DeepTutor is instantiated with each of five distinct backbone models, measured against non-agentic baselines for the same models. The simulator operates as an independent profile-driven component. We have added clarifying text in the evaluation section emphasizing the diversity of model families used for the tutor and the separation from the simulator, which supports that the observed gains arise from the framework rather than model-specific consistency effects. revision: partial
- Demonstrating direct correlation between the LLM-simulator outputs and real pre/post-test human learning gains, as no such human-subject studies were performed in this work.
Circularity Check
No significant circularity; empirical results on new benchmark do not reduce to inputs by construction
full rationale
The paper introduces DeepTutor and TutorBench, then reports measured improvements (10.8% personalized metrics, 29.4% agentic reasoning) obtained by running the system inside its own LLM-based student simulator and evaluator. These are empirical outcomes on a novel protocol rather than a derivation that reduces by equation or definition to the framework's own parameters. Complementary results on established benchmarks plus human-alignment and ablation studies are cited as independent checks. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the central claims remain falsifiable against external human outcomes even if the simulator's correlation with real learning gains is unshown here.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based first-person interactive evaluation protocol accurately reflects real student learning outcomes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid personalization engine that couples static knowledge grounding with dynamic multi-resolution memory, distilling interaction history into a continuously evolving learner profile
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
first-person interactive evaluation protocol that conducts assessments via a profile-driven student simulator
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
ECNUClaw: A Learner-Profiled Intelligent Study Companion Framework for K-12 Personalized Education
ECNUClaw is an open-source framework that maintains a five-dimension learner profile from student dialogues and adapts an AI companion's responses in real time using guidance intensity, encouragement, and Bloom's taxo...
Reference graph
Works this paper leans on
-
[1]
NEVER display knowledge listed as "unknown"
-
[2]
It’s okay to rephrase imperfectly
When the tutor teaches something new, try to rephrase it in your own words. It’s okay to rephrase imperfectly
-
[3]
If the tutor asks "do you understand?", be honest based on whether the explanation addressed your confusion
-
[4]
Keep responses concise: 1-4 sentences typically
-
[5]
Stay consistent with your personality throughout
-
[6]
You may ask follow-up questions or request examples
-
[7]
I think the Poynting vector always points in the direction of wave propagation
When you feel you’ve understood, PREFER asking for a practice problem before ending. 22 # Ending the conversation (ONLY when done) Use [ACTION: task_complete] ONLY if ALL conditions are true: - You are explicitly done. - You have zero remaining questions. - You are NOT requesting anything else. - Your message is a natural closing/goodbye. Listing 1: Stude...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.