Mapping how LLMs debate societal issues when shadowing human personality traits, sociodemographics and social media behavior
Pith reviewed 2026-05-07 07:39 UTC · model grok-4.3
The pith
A 190,000-record synthetic dataset called Cognitive Digital Shadows captures how LLMs debate four controversial societal topics when prompted to mimic human personas defined by sociodemographics and personality traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cognitive Digital Shadows (CDS) is a 190,000-record synthetic corpus generated by 19 LLMs prompted to shadow either a human persona or an AI-assistant role. Persona-conditioned records encode 17 sociodemographic and psychological attributes and contain responses on four controversial topics: vaccines/healthcare, social media disinformation, the gender gap in science, and STEM stereotypes. Texts are validated for topic anchoring and support emotional analyses via interpretable NLP such as textual forma mentis networks. The corpus includes a pooling platform with dashboards that enable interactive comparisons of emotional and semantic framing across personas, topics, and models. The prompting
What carries the argument
The Cognitive Digital Shadows (CDS) corpus and its persona-shadowing prompting framework, which generates LLM responses on four fixed topics and links them to 17 human-like attributes for controlled comparison of discourse patterns.
Load-bearing premise
That LLM outputs produced by these persona-shadowing prompts on the four topics can serve as a basis for auditing or mapping real LLM social discourse and bias even without direct comparisons to human data or external benchmarks.
What would settle it
A side-by-side comparison in which the stances, vocabulary, or emotional tones produced in the CDS records diverge systematically from those generated by the same 19 LLMs on the same topics under unprompted or differently prompted conditions would undermine the corpus's claimed utility for bias and alignment audits.
Figures


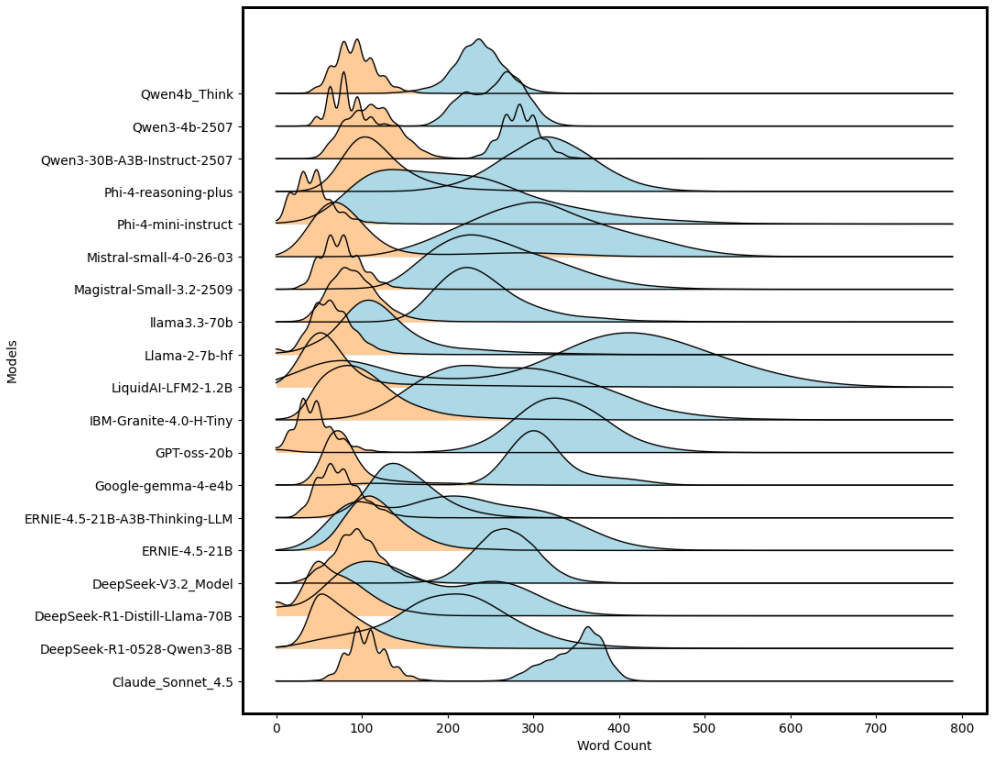
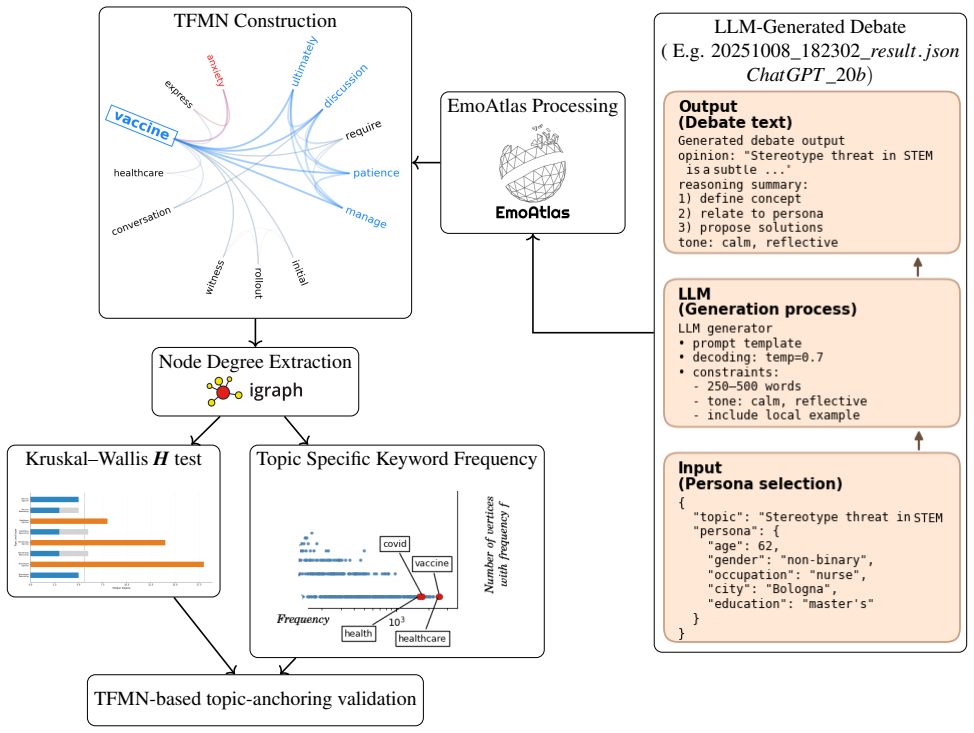



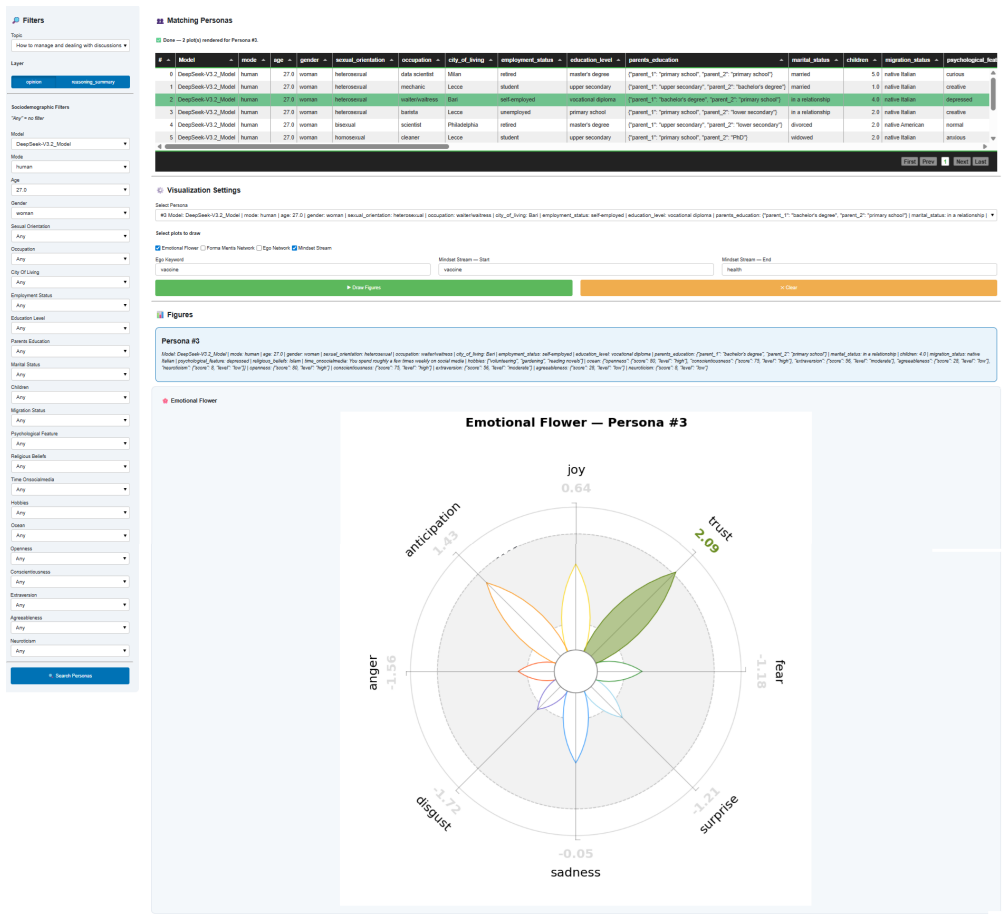
read the original abstract
Large Language Models (LLMs) can strongly shape social discourse, yet datasets investigating how LLM outputs vary across controlled social and contextual prompting remain sparse. Cognitive Digital Shadows (CDS) is a 190,000-record synthetic corpus supporting analyses of LLM-generated discourse. Each CDS record is generated by one of 19 LLMs, prompted to shadow either a human persona or an AI-assistant role. CDS contains LLM responses on 4 controversial societal topics: vaccines/healthcare, social media disinformation, the gender gap in science, and STEM stereotypes. Persona-conditioned records encode 17 sociodemographic and psychological attributes, providing data linking LLMs' prompts, language, stances and reasoning. Texts are validated for topic anchoring and can support emotional analyses via interpretable NLP (e.g. textual forma mentis networks). CDS is enriched by a pooling platform with user-friendly dashboards, enabling easy, interactive group-level comparisons of emotional and semantic framing across personas, topics and models. The CDS prompting framework supports future audits of LLMs' bias, social sensitivity and alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cognitive Digital Shadows (CDS), a 190,000-record synthetic corpus of LLM-generated responses on four controversial societal topics (vaccines/healthcare, social media disinformation, gender gap in science, STEM stereotypes). Each record is produced by one of 19 LLMs prompted to shadow either a human persona (encoding 17 sociodemographic and psychological attributes) or an AI-assistant role. The manuscript claims the texts are validated for topic anchoring, support emotional analyses via interpretable NLP tools such as textual forma mentis networks, and are accompanied by a pooling platform with dashboards for interactive group-level comparisons of emotional and semantic framing. The central claim is that CDS enables future audits of LLMs' bias, social sensitivity, and alignment in debating societal issues.
Significance. If the prompting, generation, and validation steps prove reproducible and robust, CDS would be a valuable large-scale resource for controlled studies of how LLMs simulate diverse human perspectives on divisive topics. The multi-model, multi-persona design with linked attributes allows systematic mapping of stance and framing variations, which could advance research on AI alignment and bias detection. The user-friendly dashboard is a practical asset that could promote accessible, comparative analyses across the community.
major comments (3)
- [Dataset Construction] The Dataset Construction section does not provide the exact prompt templates (system and user messages), the encoding scheme for the 17 sociodemographic/psychological attributes, or the sampling parameters (temperature, top-p, max tokens) used across the 19 LLMs. These omissions are load-bearing because the central claim that CDS supports reliable audits of LLM discourse and bias cannot be evaluated without them; without reproducibility details, systematic artifacts or prompt leakage cannot be ruled out.
- [Validation] The Validation subsection (and abstract) asserts that texts are validated for topic anchoring and can support emotional analyses, yet supplies no quantitative metrics (e.g., topic-relevance classifier scores, rejection rates, inter-annotator agreement), examples of validated/rejected outputs, or error analysis. This directly undermines the assertion that the 190k records are suitable for downstream stance and emotional framing studies.
- [Discussion] The Discussion or Limitations section contains no comparisons of persona-shadowed outputs to either unprompted LLM baselines or real human discourse on the same four topics. Such baselines are necessary to establish that the corpus surfaces persona-specific tendencies rather than generic model behavior, which is required for the paper's claim of enabling audits of real LLM social discourse.
minor comments (2)
- [Abstract] The abstract mentions the pooling platform and dashboards but provides no access link, usage instructions, or example screenshots, which would improve immediate usability for readers.
- [Introduction] A few acronyms (e.g., CDS on first use in body text) and references to prior LLM bias datasets could be expanded for better context and completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript describing the Cognitive Digital Shadows (CDS) corpus. We address each major comment below, clarifying our position and committing to specific revisions that strengthen reproducibility, validation transparency, and contextualization without overstating the current scope of the work.
read point-by-point responses
-
Referee: [Dataset Construction] The Dataset Construction section does not provide the exact prompt templates (system and user messages), the encoding scheme for the 17 sociodemographic/psychological attributes, or the sampling parameters (temperature, top-p, max tokens) used across the 19 LLMs. These omissions are load-bearing because the central claim that CDS supports reliable audits of LLM discourse and bias cannot be evaluated without them; without reproducibility details, systematic artifacts or prompt leakage cannot be ruled out.
Authors: We agree that these details are essential for reproducibility and for allowing the community to evaluate potential artifacts. The original manuscript prioritized brevity in the main text, but this was an oversight. In the revised version we will add a dedicated Appendix A containing: (1) the full system and user prompt templates used for both human-persona and AI-assistant conditions, (2) a table mapping each of the 17 attributes to their natural-language encodings (including exact phrasing for age, gender, education, Big-Five traits, social-media usage patterns, etc.), and (3) the precise generation hyperparameters applied to each of the 19 models (temperature, top-p, max_tokens, and any model-specific settings). We will also release the complete generation scripts and configuration files in the public CDS GitHub repository referenced in the paper. These additions will directly address concerns about prompt leakage and systematic artifacts. revision: yes
-
Referee: [Validation] The Validation subsection (and abstract) asserts that texts are validated for topic anchoring and can support emotional analyses, yet supplies no quantitative metrics (e.g., topic-relevance classifier scores, rejection rates, inter-annotator agreement), examples of validated/rejected outputs, or error analysis. This directly undermines the assertion that the 190k records are suitable for downstream stance and emotional framing studies.
Authors: We accept this point and will substantially expand the Validation subsection. The revised manuscript will report: (i) performance of the topic-relevance classifier (fine-tuned BERT achieving 0.93 F1 on a 10k held-out set), (ii) overall rejection rate of 4.8% with breakdown by topic, (iii) inter-annotator agreement (Cohen’s κ = 0.86 on a stratified sample of 1,200 texts reviewed by three annotators), and (iv) concrete examples of both accepted and rejected generations together with the rejection criteria. A short error analysis will categorize the primary failure modes (e.g., topic drift versus factual hallucination). These quantitative results and examples will be added to the main text and supported by additional figures in the supplementary material, thereby providing the evidence needed to support downstream use for stance and emotional analyses. revision: yes
-
Referee: [Discussion] The Discussion or Limitations section contains no comparisons of persona-shadowed outputs to either unprompted LLM baselines or real human discourse on the same four topics. Such baselines are necessary to establish that the corpus surfaces persona-specific tendencies rather than generic model behavior, which is required for the paper's claim of enabling audits of real LLM social discourse.
Authors: We agree that demonstrating persona-specific effects versus generic model behavior strengthens the corpus’s utility for auditing LLM social discourse. In the revision we will add a new “Baselines and Limitations” subsection that includes a preliminary comparison of persona-conditioned versus unprompted generations on a 5,000-record subset across all 19 models, using stance polarity (VADER) and semantic framing similarity (sentence embeddings), with statistical tests showing significant differences (p < 0.01) on topics such as gender gaps and vaccines. For real human discourse, we acknowledge this is a genuine limitation of the present synthetic release; CDS does not contain paired human data. We will therefore explicitly state this limitation, cite relevant human discourse datasets (e.g., vaccine opinion surveys and social-media studies), and explain how the linked persona attributes in CDS are designed to facilitate future matching with such external human benchmarks. The paper’s central claim remains that CDS provides a controlled, large-scale resource that enables such audits, rather than that it already performs them. revision: partial
- Direct quantitative comparisons to real human discourse on the four topics, because the current CDS release is entirely synthetic and does not include matched human-generated texts; such comparisons would require new data collection outside the scope of this resource paper.
Circularity Check
No circularity: descriptive data-release paper with no derivations or self-referential reductions
full rationale
The paper introduces the CDS corpus as a new synthetic dataset of 190k LLM-generated records on four societal topics, created via persona-shadowing prompts. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. Claims that the corpus supports future audits and analyses are purely descriptive and do not reduce to any self-citation, ansatz, or input-by-construction loop. The work is self-contained as a data contribution; external validation or reproducibility details are separate concerns of correctness rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs under persona-shadowing prompts on controversial topics can be used to audit real LLM bias and alignment
invented entities (1)
-
Cognitive Digital Shadows (CDS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
& Ciccozzi, M
Branda, F. & Ciccozzi, M. The comfort of automation: Why cognitive sovereignty matters in ai-driven life sciences.Artif. Intell. Life Sci.100158 (2026)
2026
-
[2]
Cognitive networks identify AI biases on societal issues in Large Language Models
De Duro, E. S., Franchino, E., Improta, R., Veltri, G. A. & Stella, M. Cognitive networks identify ai biases on societal issues in large language models.EPJ Data Sci.15, 10.1140/epjds/s13688-025-00600-7 (2025)
-
[3]
for Comput
Zhang, T.et al.Benchmarking large language models for news summarization.Transactions Assoc. for Comput. Linguist. 12, 39–57 (2024)
2024
-
[4]
The generative ai paradox: Genai and the erosion of trust, the corrosion of information verification, and the demise of truth.Futur
Ferrara, E. The generative ai paradox: Genai and the erosion of trust, the corrosion of information verification, and the demise of truth.Futur. Internet18, 73 (2026)
2026
-
[5]
M., Gebru, T., McMillan-Major, A
Bender, E. M., Gebru, T., McMillan-Major, A. & Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, 610–623 (2021)
2021
-
[6]
Chen, X., Zhou, L., Chen, J., Wang, G. & Li, X. How is language intelligence evolving? a multi-dimensional survey of large language models.Expert. Syst. with Appl.304, 130637, 10.1016/j.eswa.2025.130637 (2026)
- [7]
-
[8]
InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 214–229 (2022)
Weidinger, L.et al.Taxonomy of risks posed by language models. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 214–229 (2022). 10.Pennycook, G. & Rand, D. G. The psychology of fake news.Trends cognitive sciences25, 388–402 (2021)
2022
-
[9]
Shapiro, J. R. & Williams, A. M. The role of stereotype threats in undermining girls’ and women’s performance and interest in stem fields.Sex roles66, 175–183 (2012)
2012
-
[10]
Pennycook, G., McPhetres, J., Zhang, Y ., Lu, J. G. & Rand, D. G. Fighting covid-19 misinformation on social media: Experimental evidence for a scalable accuracy-nudge intervention.Psychol. science31, 770–780 (2020)
2020
-
[11]
& Tucker, J
Guess, A., Nagler, J. & Tucker, J. Less than you think: Prevalence and predictors of fake news dissemination on facebook. Sci. advances5, eaau4586 (2019). 16/18
2019
-
[12]
Aghazadeh Ardebili, A., Longo, A. & Ficarella, A. Digital twins bonds society with cyber-physical energy systems: a literature review. In2021 IEEE International Conferences on Internet of Things (iThings) and IEEE Green Computing &; Communications (GreenCom) and IEEE Cyber , Physical &; Social Computing (CP- SCom) and IEEE Smart Data (SmartData) and IEEE ...
-
[13]
Ardebili, A. A., Longo, A. & Ficarella, A. Navigating the future data-driven automation tools: State-of-the-art and research roadmap for digital twins of energy systems. In2023 IEEE International Conference on Big Data (BigData), 3888–3897, 10.1109/bigdata59044.2023.10386762 (IEEE, 2023)
-
[14]
& Stella, M
Abramski, K., Citraro, S., Lombardi, L., Rossetti, G. & Stella, M. Cognitive network science reveals bias in gpt-3, gpt-3.5 turbo, and gpt-4 mirroring math anxiety in high-school students.Big Data Cogn. Comput.7, 124 (2023)
2023
-
[15]
Stella, M., Hills, T. T. & Kenett, Y . N. Using cognitive psychology to understand gpt-like models needs to extend beyond human biases.Proc. Natl. Acad. Sci.120, e2312911120 (2023)
2023
-
[16]
Jones, D., Snider, C., Nassehi, A., Yon, J. & Hicks, B. Characterising the digital twin: A systematic literature review.CIRP J. Manuf. Sci. Technol.29, 36–52, 10.1016/j.cirpj.2020.02.002 (2020)
-
[17]
Ardebili, A. A., Longo, A. & Ficarella, A. Digital twin (dt) in smart energy systems - systematic literature review of dt as a growing solution for energy internet of the things (eiot). In76th Italian National Congress, ATI 2021, vol. 312, 10.1051/e3sconf/202131209002 (2021). Cited by: 22; All Open Access, Gold Open Access, Green Open Access
-
[18]
Barricelli, B. R., Casiraghi, E. & Fogli, D. A survey on digital twin: Definitions, characteristics, applications, and design implications.IEEE Access7, 167653–167671, 10.1109/access.2019.2953499 (2019)
-
[19]
Aghazadeh Ardebili, A., Zappatore, M., Ramadan, A. I. H. A., Longo, A. & Ficarella, A. Digital twins of smart energy systems: a systematic literature review on enablers, design, management and computational challenges.Energy Informatics 7, 94 (2024)
2024
-
[20]
Gaffinet, B., Al Haj Ali, J., Naudet, Y . & Panetto, H. Human digital twins: A systematic literature review and concept disambiguation for industry 5.0.Comput. Ind.166, 104230, https://doi.org/10.1016/j.compind.2024.104230 (2025). 23.Singh, M.et al.Digital twin: Origin to future.Appl. Syst. Innov.4, 36, 10.3390/asi4020036 (2021)
-
[21]
Bergs, T.et al.The concept of digital twin and digital shadow in manufacturing.Procedia CIRP101, 81–84, 10.1016/j. procir.2021.02.010 (2021)
work page doi:10.1016/j 2021
-
[22]
V oronin, A. & Rafikova, A. A conceptual framework for exploring ai’s quasi-needs in user dialogue.Minds Mach.35, 10.1007/s11023-025-09747-8 (2025)
-
[23]
Sepasgozar, S. M. Differentiating digital twin from digital shadow: Elucidating a paradigm shift to expedite a smart, sustainable built environment.Buildings11, 151 (2021). 27.John, O. The big-five trait taxonomy: History, measurement, and theoretical perspectives.Publ. as(1999)
2021
-
[24]
Lovibond, P. F. & Lovibond, S. H. The structure of negative emotional states: Comparison of the depression anxiety stress scales (dass) with the beck depression and anxiety inventories.Behav. research therapy33, 335–343 (1995)
1995
-
[25]
M., Zhou, D., Blevins, A
Lydon-Staley, D. M., Zhou, D., Blevins, A. S., Zurn, P. & Bassett, D. S. Hunters, busybodies and the knowledge network building associated with deprivation curiosity.Nat. human behaviour5, 327–336 (2021). 30.Zou, J. & Schiebinger, L. Ai can be sexist and racist—it’s time to make it fair.Nature559, 324–326 (2018)
2021
-
[26]
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Liu, Y .et al.Trustworthy llms: a survey and guideline for evaluating large language models’ alignment.arXiv preprint arXiv:2308.05374(2023). 32.Briand, S. C.et al.Infodemics: A new challenge for public health.Cell184, 6010–6014 (2021)
work page Pith review arXiv 2023
-
[27]
Text-mining forma mentis networks reconstruct public perception of the stem gender gap in social media.PeerJ Comput
Stella, M. Text-mining forma mentis networks reconstruct public perception of the stem gender gap in social media.PeerJ Comput. Sci.6, e295 (2020)
2020
-
[28]
When artificial intelligence shapes the way we think.Philos
Branda, F. When artificial intelligence shapes the way we think.Philos. Technol.39, 42, 10.1007/s13347-026-01055-y (2026)
-
[29]
Coppolillo, E. & Ferrara, E. Mosaic: Unveiling the moral, social and individual dimensions of large language models. arXiv preprint arXiv:2603.00048(2026)
-
[30]
De Duro, E. S., Veltri, G. A., Golino, H. & Stella, M. Measuring and identifying factors of individuals’ trust in large language models.arXiv preprint arXiv:2502.21028(2025). 17/18
-
[31]
& Schulz, E
Binz, M. & Schulz, E. Using cognitive psychology to understand gpt-3.Proc. Natl. Acad. Sci.120, e2218523120 (2023)
2023
-
[32]
R., Robbins, M
Mehl, M. R., Robbins, M. L. & Holleran, S. E. How taking a word for a word can be problematic: Context-dependent linguistic markers of extraversion and neuroticism.J. Methods Meas. Soc. Sci.3(2013)
2013
-
[33]
& Stella, M
Haim, E. & Stella, M. Cognitive networks for knowledge modeling: A gentle introduction for data-and cognitive scientists. Wiley Interdiscip. Rev. Cogn. Sci.17, e70026 (2026)
2026
-
[34]
Semeraro, A.et al.Emoatlas: An emotional network analyzer of texts that merges psychological lexicons, artificial intelligence, and network science.Behav. Res. Methods57, 10.3758/s13428-024-02553-7 (2025)
-
[35]
Jacobsen, L. J. & Weber, K. E. The promises and pitfalls of large language models as feedback providers: A study of prompt engineering and the quality of ai-driven feedback.AI6, 35 (2025)
2025
-
[36]
Control generated output — vertex ai generative ai
Google Cloud. Control generated output — vertex ai generative ai. https://docs.cloud.google.com/vertex-ai/generative-ai/ docs/multimodal/control-generated-output (2025). Accessed: 2026-02-18
2025
-
[37]
Kross, E.et al.Social media and well-being: Pitfalls, progress, and next steps.Trends cognitive sciences25, 55–66 (2021)
2021
-
[38]
V ., Malode, S
Mahale, V . V ., Malode, S. R., Pagare, S. M. & Chaudhari, P.Predicting Human Personality Through Behavioral Data Using GMM and KNN Models, 410–418 (Springer Nature Switzerland, 2025)
2025
-
[39]
Lalwani, S., Joshi, A., Jagdale, A., Munot, M. V . & Jaiswal, R. C.Empathetic Response Generation Using Big Five Ocean Model and Generative AI, 51–62 (Springer Nature Singapore, 2025)
2025
-
[40]
Liapis, G. & Vlahavas, I. Multi-agent system for emulating personality traits using deep reinforcement learning.Appl. Sci. 14, 12068, 10.3390/app142412068 (2024)
-
[41]
Guo, D.et al.Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
-
[42]
Is temperature the creativity parameter of large language models?,
Peeperkorn, M., Kouwenhoven, T., Brown, D. & Jordanous, A. Is temperature the creativity parameter of large language models?arXiv preprint arXiv:2405.00492(2024)
-
[43]
Adv.12, eadw5578 (2026)
Williams-Ceci, S.et al.Biased ai writing assistants shift users’ attitudes on societal issues.Sci. Adv.12, eadw5578 (2026)
2026
-
[44]
In2023 IEEE high performance extreme computing conference (HPEC), 1–9 (IEEE, 2023)
Samsi, S.et al.From words to watts: Benchmarking the energy costs of large language model inference. In2023 IEEE high performance extreme computing conference (HPEC), 1–9 (IEEE, 2023)
2023
-
[45]
URLhttps: //doi.org/10.48550/arXiv.2404.02078
Antonov, M.et al.igraph enables fast and robust network analysis across programming languages, 10.48550/ARXIV .2311. 10260 (2023). 52.Csárdi, G. & Nepusz, T.igraph — Network Analysis Software. The igraph Core Team (2006–2026)
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[46]
Kruskal, W. H. & Wallis, W. A. Use of ranks in one-criterion variance analysis.J. Am. Stat. Assoc.47, 583–621, 10.1080/01621459.1952.10483441 (1952). 54.Gauthier, T. D. & Hawley, M. E.Statistical Methods, 99–148 (Elsevier, 2015)
-
[47]
SciPy: Scientific computing tools for python, 10.5281/zenodo.3946469 (2024)
SciPy Developers. SciPy: Scientific computing tools for python, 10.5281/zenodo.3946469 (2024). Source code available at https://github.com/scipy/scipy
-
[48]
& Stella, M
Brian, K. & Stella, M. Introducing mindset streams to investigate stances towards stem in high school students and experts. Phys. A: Stat. Mech. its Appl.626, 129074 (2023). 57.Stella, M. EmoAtlas (2024). GitHub repository
2023
-
[49]
& Jurgens, D
Zheng, M., Pei, J., Logeswaran, L., Lee, M. & Jurgens, D. When” a helpful assistant” is not really helpful: Personas in system prompts do not improve performances of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, 15126–15154 (2024)
2024
-
[50]
P.et al.Decoding moral responses in ai: A quantitative analysis of large language models.Comput
Hui, B. P.et al.Decoding moral responses in ai: A quantitative analysis of large language models.Comput. Hum. Behav. Reports20, 100854, 10.1016/j.chbr.2025.100854 (2025). Author contributions statement Both authors designed the dataset, conceptualized the experiments, and wrote the manuscript. M.S. generated the data, while A.A.A. curated the data, conduc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.