Recognition: unknown
Reliable Answers for Recurring Questions: Boosting Text-to-SQL Accuracy with Template Constrained Decoding
Pith reviewed 2026-05-07 07:30 UTC · model grok-4.3
The pith
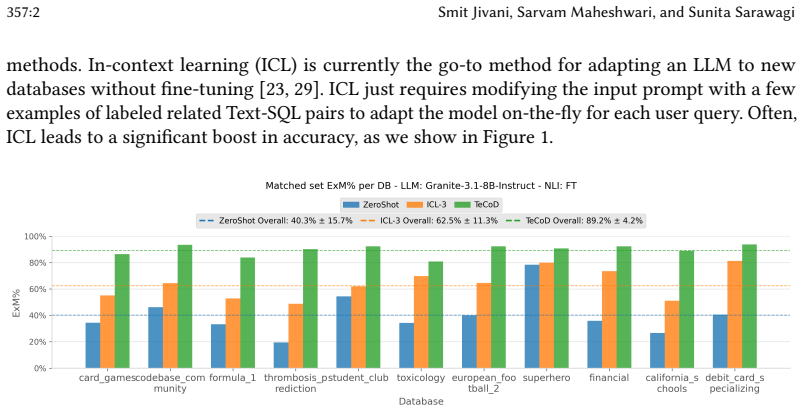
Template Constrained Decoding reuses historical query patterns to improve Text-to-SQL accuracy up to 36% over in-context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TeCoD converts historical NL-SQL pairs into reusable templates and uses a fine-tuned NLI model for robust template selection or rejection. It then enforces the chosen template during SQL generation through a novel partitioned strategy for grammar-constrained decoding that maintains syntactic validity and efficiency. The combined system achieves up to 36% higher execution accuracy than in-context learning and 2.2x lower latency on matched queries.
What carries the argument
The Template Constrained Decoding (TeCoD) framework, consisting of template extraction from labeled workloads, NLI-based selection, and partitioned grammar-constrained decoding to enforce template structure.
Load-bearing premise
Query patterns recur often enough in real-world labeled workloads for the template extraction and selection process to be effective and reliable.
What would settle it
Testing on a workload of entirely new query patterns with no overlap to the historical templates would determine if accuracy improvements persist or drop to baseline levels.
Figures



read the original abstract
Large language models (LLMs) have revolutionized Text-to-SQL generation, allowing users to query structured data using natural language with growing ease. Yet, real-world deployment remains challenging, especially in complex or unseen schemas, due to inconsistent accuracy and the risk of generating invalid SQL. We introduce Template Constrained Decoding (TeCoD), a system that addresses these limitations by harnessing the recurrence of query patterns in labeled workloads. TeCoD converts historical NL-SQL pairs into reusable templates and introduces a robust template selection module that uses a fine-tuned natural language inference model to match or reject queries efficiently. Once the template is selected, TeCoD enforces it during SQL generation through grammar-constrained decoding, implemented via a novel partitioned strategy that ensures both syntactic validity and efficiency. Together, these components yield up to 36% higher execution accuracy than in-context learning (ICL) and 2.2x lower latency on matched queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Template Constrained Decoding (TeCoD) to improve Text-to-SQL generation by extracting reusable templates from historical NL-SQL pairs, selecting them using a fine-tuned natural language inference (NLI) model, and enforcing them via a novel partitioned grammar-constrained decoding strategy. The authors report that this approach achieves up to 36% higher execution accuracy than standard in-context learning (ICL) and 2.2 times lower latency on matched queries.
Significance. If the reported gains hold under rigorous evaluation, the work could have practical significance for Text-to-SQL applications in domains with recurring query patterns, such as business intelligence tools. The combination of template reuse and constrained decoding addresses both accuracy and efficiency issues common in LLM-based SQL generation. However, the significance is tempered by the need for evidence that template matching occurs frequently enough in standard benchmarks and real-world workloads to justify the added complexity of the NLI selector and grammar constraints.
major comments (4)
- [Abstract] Abstract: The abstract states performance numbers ('up to 36% higher execution accuracy' and '2.2x lower latency') but does not reference the specific datasets, the fraction of queries for which templates match, or any ablation results. This omission makes it impossible to assess whether the improvements are broadly applicable or limited to a small matched subset.
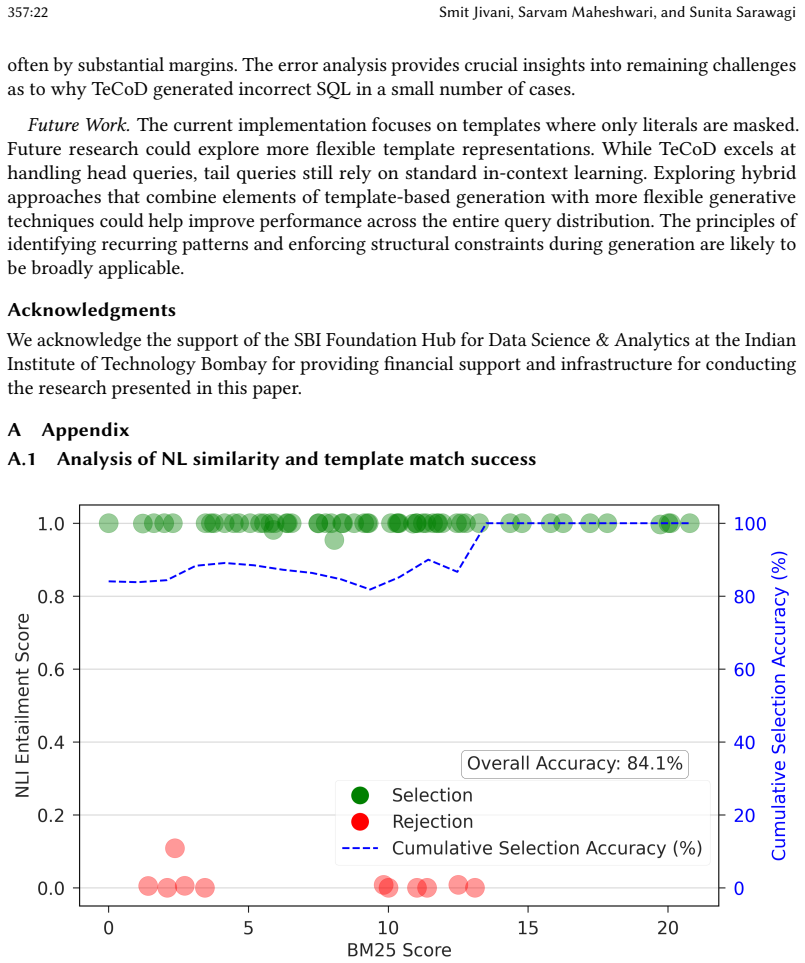
- [§3] §3 (Template Selection Module): The reliance on a fine-tuned NLI model for template selection is described, but no details are provided on the training data for the NLI model, its precision/recall on the target domain, or an ablation showing the impact of NLI errors on overall accuracy. This is load-bearing for the claim that the system reliably boosts accuracy.
- [§4] §4 (Experiments): No table or figure reports the template match rate on the evaluation sets (e.g., Spider or others), nor a breakdown of execution accuracy for matched vs. unmatched queries. Without this, the 'up to 36%' figure cannot be contextualized, and the practical utility remains unclear.
- [§3.3] §3.3 (Partitioned Grammar-Constrained Decoding): While the partitioned strategy is claimed to ensure syntactic validity and efficiency, there is no empirical verification or comparison to standard constrained decoding showing that semantic correctness is preserved when the LLM instantiates the template.
minor comments (2)
- [§2] §2: The notation used for defining templates (e.g., placeholders for entities) could benefit from a concrete example early in the section to improve readability.
- [References] References: Ensure that prior work on grammar-constrained decoding and NLI for query matching is cited comprehensively.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and constructive feedback. We believe the suggested revisions will strengthen the manuscript by providing necessary context and empirical support for our claims. We address each major comment below and outline the changes we will make in the revised version.
read point-by-point responses
-
Referee: [Abstract] The abstract states performance numbers ('up to 36% higher execution accuracy' and '2.2x lower latency') but does not reference the specific datasets, the fraction of queries for which templates match, or any ablation results. This omission makes it impossible to assess whether the improvements are broadly applicable or limited to a small matched subset.
Authors: We agree that the abstract should provide more context. In the revised version, we will update the abstract to name the datasets (Spider and domain-specific benchmarks), report observed template match rates, and reference key ablation results. The 'up to 36%' figure is the peak gain on matched queries; we will clarify this scope. revision: yes
-
Referee: [§3] The reliance on a fine-tuned NLI model for template selection is described, but no details are provided on the training data for the NLI model, its precision/recall on the target domain, or an ablation showing the impact of NLI errors on overall accuracy. This is load-bearing for the claim that the system reliably boosts accuracy.
Authors: We will expand §3 with details on the NLI training data (derived from historical NL-SQL pairs), report precision/recall on target domains, and add an ablation in the experiments section quantifying the effect of NLI errors on end-to-end accuracy. revision: yes
-
Referee: [§4] No table or figure reports the template match rate on the evaluation sets (e.g., Spider or others), nor a breakdown of execution accuracy for matched vs. unmatched queries. Without this, the 'up to 36%' figure cannot be contextualized, and the practical utility remains unclear.
Authors: We will add a table in §4 reporting template match rates on all evaluation sets and a breakdown of execution accuracy for matched versus unmatched queries. This will contextualize the gains and show match frequency in the benchmarks. revision: yes
-
Referee: [§3.3] While the partitioned strategy is claimed to ensure syntactic validity and efficiency, there is no empirical verification or comparison to standard constrained decoding showing that semantic correctness is preserved when the LLM instantiates the template.
Authors: We will add empirical verification and a direct comparison to standard constrained decoding in §3.3 and the experiments, confirming that semantic correctness (measured by execution accuracy) is preserved while latency improves. revision: yes
Circularity Check
No significant circularity; empirical gains rest on independent components
full rationale
The paper's core method extracts templates from historical NL-SQL pairs (standard data-driven preprocessing), selects via a separately fine-tuned NLI model, and applies partitioned grammar-constrained decoding. These steps are not defined in terms of the final execution-accuracy metric, nor do any claimed improvements reduce by construction to fitted parameters or self-citations within the paper. The reported deltas are presented as empirical measurements on evaluation sets rather than algebraic identities or renamed inputs. No load-bearing self-citation chains, ansatz smuggling, or uniqueness theorems appear in the derivation. The approach is self-contained against external benchmarks and does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Query patterns recur sufficiently in labeled workloads to support reusable templates.
Reference graph
Works this paper leans on
-
[1]
Abhijeet Awasthi, Ashutosh Sathe, and Sunita Sarawagi. 2022. Diverse Parallel Data Synthesis for Cross-Database Adaptation of Text-to-SQL Parsers
2022
-
[2]
rapidfuzz/RapidFuzz: Release 3.8.1
Max Bachmann. 2024.rapidfuzz/RapidFuzz: Release 3.8.1. doi:10.5281/zenodo.10938887
- [3]
-
[4]
Adithya Bhaskar, Tushar Tomar, Ashutosh Sathe, and Sunita Sarawagi. 2023. Benchmarking and Improving Text- to-SQL Generation under Ambiguity. InThe 2023 Conference on Empirical Methods in Natural Language Processing. https://openreview.net/forum?id=a0yFO9gKc5 Proc. ACM Manag. Data, Vol. 3, No. 6 (SIGMOD), Article 357. Publication date: December 2025. Reli...
2023
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[6]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805 [cs.CL] https://arxiv.org/abs/1810.04805
work page internal anchor Pith review arXiv 2019
-
[7]
Ju Fan, Zihui Gu, Songyue Zhang, Yuxin Zhang, Zui Chen, Lei Cao, Guoliang Li, Samuel Madden, Xiaoyong Du, and Nan Tang. 2024. Combining small language models and large language models for zero-shot NL2SQL.Proceedings of the VLDB Endowment17, 11 (2024), 2750–2763
2024
-
[8]
Han Fu, Chang Liu, Bin Wu, Feifei Li, Jian Tan, and Jianling Sun. 2023. Catsql: Towards real world natural language to sql applications.Proceedings of the VLDB Endowment16, 6 (2023), 1534–1547
2023
- [9]
-
[10]
Saibo Geng, Martin Josifoski, Maxime Peyrard, and Robert West. 2023. Grammar-Constrained Decoding for Structured NLP Tasks without Finetuning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore. https://aclanthology...
2023
-
[11]
Granite Team and IBM. 2024. Granite-3.1-8B-Instruct. https://huggingface.co/ibm-granite/granite-3.1-8b-instruct. https://huggingface.co/ibm-granite/granite-3.1-8b-instruct Model card release date: December 18, 2024
2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review arXiv 2024
-
[13]
Mayank Kothyari, Dhruva Dhingra, Sunita Sarawagi, and Soumen Chakrabarti. 2023. CRUSH4SQL: Collective Retrieval Using Schema Hallucination For Text2SQL. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 14054–1406...
-
[14]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models.arXiv preprint arXiv:2405.17428 (2024)
work page internal anchor Pith review arXiv 2024
- [15]
-
[16]
Fei Li and H. V. Jagadish. 2014. Constructing an interactive natural language interface for relational databases.Proc. VLDB Endow.8, 1 (Sept. 2014), 73–84. doi:10.14778/2735461.2735468
-
[17]
Haoyang Li, Jing Zhang, Cuiping Li, and Hong Chen. 2023. RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL.Proceedings of the AAAI Conference on Artificial Intelligence37, 11 (Jun. 2023), 13067–13075. doi:10.1609/aaai.v37i11.26535
- [18]
-
[19]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems36 (2024)
2024
-
[20]
Yunyao Li and Davood Rafiei. 2017. Natural Language Data Management and Interfaces: Recent Development and Open Challenges. InProceedings of the 2017 ACM International Conference on Management of Data (SIGMOD ’17). Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3035918.3054783
-
[21]
Yifu Liu, Yin Zhu, Yingqi Gao, Zhiling Luo, Xiaoxia Li, Xiaorong Shi, Yuntao Hong, Jinyang Gao, Yu Li, Bolin Ding, and Jingren Zhou. 2025. XiYan-SQL: A Novel Multi-Generator Framework For Text-to-SQL. (2025). arXiv:2507.04701 [cs.CL] https://arxiv.org/abs/2507.04701
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Toby Mao and contributors. [n. d.]. SQLGlot: Python SQL Parser, Transpiler, and Optimizer. https://github.com/ tobymao/sqlglot. Accessed: 2025-01-24
2025
-
[23]
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan Ö. Arik. 2024. CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL.ArXivabs/2410.01943 (2024). https://api.semanticscholar.org/CorpusID:273098638
- [24]
-
[25]
Abdul Quamar, Vasilis Efthymiou, Chuan Lei, and Fatma Özcan. 2022. Natural Language Interfaces to Data.Found. Trends Databases11, 4 (May 2022), 319–414
2022
-
[26]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.ArXivabs/1910.01108 (2019). Proc. ACM Manag. Data, Vol. 3, No. 6 (SIGMOD), Article 357. Publication date: December 2025. 357:26 Smit Jivani, Sarvam Maheshwari, and Sunita Sarawagi
work page internal anchor Pith review arXiv 2019
-
[27]
Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. 2021. PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
2021
-
[28]
Harshit Varma, Abhijeet Awasthi, and Sunita Sarawagi. 2023. Conditional Tree Matching for Inference-Time Adaptation of Tree Prediction Models
2023
- [29]
-
[30]
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. 2020. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 7567–7578
2020
-
[31]
Bailin Wang, Wenpeng Yin, Xi Victoria Lin, and Caiming Xiong. 2021. Learning to Synthesize Data for Semantic Parsing. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2760–2766
2021
-
[32]
Brandon T Willard and Rémi Louf. 2023. Efficient Guided Generation for LLMs.arXiv preprint arXiv:2307.09702(2023)
work page internal anchor Pith review arXiv 2023
-
[33]
Xiangjin Xie, Guangwei Xu, Lingyan Zhao, and Ruijie Guo. 2025. OpenSearch-SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Alignment.CoRRabs/2502.14913 (2025). arXiv:2502.14913 doi:10.48550/ARXIV. 2502.14913
work page internal anchor Pith review doi:10.48550/arxiv 2025
- [34]
-
[35]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 3911–3921
2018
-
[36]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2019. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. arXiv:1809.08887 [cs.CL]
work page Pith review arXiv 2019
- [37]
-
[38]
Hanchong Zhang, Ruisheng Cao, Lu Chen, Hongshen Xu, and Kai Yu. 2023. ACT-SQL: In-Context Learning for Text- to-SQL with Automatically-Generated Chain-of-Thought. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 3501–3532. doi:10...
-
[39]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025). Received April 2025; revised July 2025; accepted August 2025 Proc. ACM Manag...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.