Recognition: unknown
OmniRobotHome: A Multi-Camera Platform for Real-Time Multiadic Human-Robot Interaction
Pith reviewed 2026-05-07 05:19 UTC · model grok-4.3
The pith
OmniRobotHome uses 48 synchronized cameras to deliver real-time 3D tracking of humans, objects, and robots in a shared home workspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
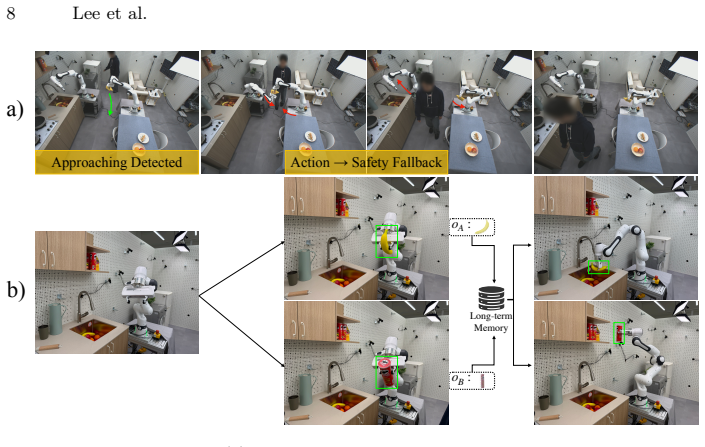
OmniRobotHome is the first room-scale residential platform that unifies wide-area real-time 3D human and object perception with coordinated multi-robot actuation in a shared world frame. The system instruments a natural home environment with 48 hardware-synchronized RGB cameras for markerless, occlusion-robust tracking of multiple humans and objects, temporally aligned with two Franka arms that act on live scene state. Continuous capture within this consistent frame further supports long-horizon human behavior modeling from accumulated trajectories. The platform makes the multiadic collaboration regime experimentally tractable, and real-time perception together with behavior memory each show
What carries the argument
The fixed array of 48 hardware-synchronized RGB cameras that supplies markerless 3D tracking of multiple humans and objects at room scale and aligns it in one shared world frame with multi-robot actuation.
If this is right
- Real-time perception from the camera array improves safety performance in shared human-robot environments.
- Accumulated trajectory data enables human behavior modeling that improves anticipatory robotic assistance.
- The unified shared-frame architecture makes concurrent multi-human multi-robot task experiments feasible without repeated calibration.
- Long-horizon capture supports data-driven study of interleaved subtasks that define realistic home collaboration.
Where Pith is reading between the lines
- The same camera array and shared frame could support testing of multi-agent planners that treat humans and robots symmetrically in one state estimate.
- Recorded trajectories might reveal repeatable spatial patterns between people and robots that could guide future home layout choices.
- Adding a small number of depth sensors at key occlusion points could test whether the current RGB-only setup is already near its robustness limit.
Load-bearing premise
That a fixed installation of 48 synchronized cameras will maintain accurate markerless 3D tracking of multiple dynamic agents during close-proximity interactions with frequent occlusions and rapid state changes.
What would settle it
A controlled multiadic task in which two humans and one robot exchange objects at arm's length and the system loses continuous track of at least one agent for more than a brief interval, preventing reliable robot response to live scene state.
Figures






read the original abstract
Human-robot collaboration has been studied primarily in dyadic or sequential settings. However, real homes require multiadic collaboration, where multiple humans and robots share a workspace, acting concurrently on interleaved subtasks with tight spatial and temporal coupling. This regime remains underexplored because close-proximity interaction between humans, robots, and objects creates persistent occlusion and rapid state changes, making reliable real-time 3D tracking the central bottleneck. No existing platform provides the real-time, occlusion-robust, room-scale perception needed to make this regime experimentally tractable. We present OmniRobotHome, the first room-scale residential platform that unifies wide-area real-time 3D human and object perception with coordinated multi-robot actuation in a shared world frame. The system instruments a natural home environment with 48 hardware-synchronized RGB cameras for markerless, occlusion-robust tracking of multiple humans and objects, temporally aligned with two Franka arms that act on live scene state. Continuous capture within this consistent frame further supports long-horizon human behavior modeling from accumulated trajectories. The platform makes the multiadic collaboration regime experimentally tractable. We focus on two central problems: safety in shared human-robot environments and human-anticipatory robotic assistance, and show that real-time perception and accumulated behavior memory each yield measurable gains in both.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniRobotHome, the first room-scale residential platform that integrates 48 hardware-synchronized RGB cameras for wide-area real-time 3D human and object perception with two Franka arms for coordinated multi-robot actuation in a shared world frame. It addresses the bottleneck of occlusion and rapid state changes in multiadic human-robot collaboration, enabling studies on safety and human-anticipatory assistance, claiming measurable gains from real-time perception and accumulated behavior memory.
Significance. This platform, if its tracking performance is validated, could be significant for the field by providing an experimental testbed for multiadic HRI scenarios that are currently underexplored due to perception limitations. The unified perception-actuation system in a natural home environment represents an engineering advance that could support long-horizon behavior modeling.
major comments (2)
- [Abstract] Abstract: The central claim that the platform yields 'measurable gains' in safety and anticipatory assistance lacks any supporting quantitative evidence, such as latency figures, tracking accuracy metrics (e.g., MPJPE for humans or pose error for objects), or results from validation experiments comparing with and without real-time perception.
- [Abstract] Abstract: The manuscript does not specify the concrete perception pipeline, including which multi-view 3D reconstruction or pose estimation algorithm is employed, nor does it report end-to-end latency or accuracy under the conditions of multiple concurrent humans, robots, and heavy occlusion.
minor comments (1)
- [Abstract] Abstract: The term 'multiadic' is used without definition or citation; a brief clarification or reference to prior usage would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract. We agree that the abstract would benefit from greater specificity regarding quantitative results and technical details of the perception pipeline. We will revise the abstract accordingly while ensuring the changes are supported by the quantitative evaluations and methods already present in the full manuscript. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the platform yields 'measurable gains' in safety and anticipatory assistance lacks any supporting quantitative evidence, such as latency figures, tracking accuracy metrics (e.g., MPJPE for humans or pose error for objects), or results from validation experiments comparing with and without real-time perception.
Authors: We appreciate this observation. The full manuscript reports quantitative validation results in the Experiments section, including end-to-end latency, MPJPE for human poses, object pose errors, and direct comparisons of safety (e.g., collision avoidance) and anticipatory assistance metrics with versus without real-time perception and accumulated behavior memory. To address the concern, we will revise the abstract to incorporate the key supporting metrics and comparative outcomes, making the claims of measurable gains explicit and evidence-based at the abstract level. revision: yes
-
Referee: [Abstract] Abstract: The manuscript does not specify the concrete perception pipeline, including which multi-view 3D reconstruction or pose estimation algorithm is employed, nor does it report end-to-end latency or accuracy under the conditions of multiple concurrent humans, robots, and heavy occlusion.
Authors: We agree that the abstract would be strengthened by including these details. The Methods section of the manuscript fully specifies the multi-view 3D reconstruction and pose estimation algorithm used for markerless, occlusion-robust tracking, along with end-to-end latency and accuracy metrics evaluated under multi-human, multi-robot, and heavy-occlusion conditions. We will revise the abstract to concisely describe the pipeline, name the algorithm, and report the relevant latency and accuracy figures for the stated operating conditions. revision: yes
Circularity Check
No circularity in platform description or claims
full rationale
The manuscript describes a hardware platform (48 synchronized RGB cameras + Franka arms in a shared world frame) whose central claims concern engineering integration for real-time multiadic HRI. No equations, derivations, fitted parameters, or first-principles predictions appear in the provided text. Claims about occlusion-robust tracking and measurable gains from perception/memory are presented as outcomes of the physical system rather than results that reduce by construction to their own inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are invoked. The work is self-contained as an engineering contribution whose assertions can be evaluated against external benchmarks (latency, accuracy, ablation studies) without tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Camera extrinsic and intrinsic calibration parameters
axioms (2)
- domain assumption Hardware synchronization of the 48 cameras provides sufficient temporal alignment for real-time 3D reconstruction
- domain assumption Markerless multi-view reconstruction remains reliable under persistent occlusion and close-proximity motion
Reference graph
Works this paper leans on
-
[1]
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Ho, D., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jang, E., Ruano, R.J., Jeffrey, K., Jesmonth, S., Joshi, N.J., Julian, R., Kalashnikov, D., Kuang, Y., Lee, K.H., Levine, S., Lu, Y., Luu, L., Parada, C., Pastor, P., Quiamba...
work page internal anchor Pith review doi:10.48550/arxiv.2204.01691 2022
-
[2]
Bhardwaj, M., Sundaralingam, B., Mousavian, A., Ratliff, N., Fox, D., Ramos, F., Boots, B.: STORM: An Integrated Framework for Fast Joint-Space Model- Predictive Control for Reactive Manipulation (Sep 2021).https://doi.org/10. 48550/arXiv.2104.13542
-
[3]
In: Robotics: Science and Systems (RSS) (2023)
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. In: Robotics: Science and Systems (RSS) (2023)
2023
-
[4]
In: Proceedings of the SIGCHI Conference on human factors in computing systems
Casiez, G., Roussel, N., Vogel, D.: 1€filter: a simple speed-based low-pass filter for noisy input in interactive systems. In: Proceedings of the SIGCHI Conference on human factors in computing systems. pp. 2527–2530 (2012)
2012
-
[5]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: Sam 3d: 3dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review arXiv 2025
-
[6]
Choi, S., Lee, K., Park, H.A., Oh, S.: A Nonparametric Motion Flow Model for Human Robot Cooperation (Sep 2017).https://doi.org/10.48550/arXiv.1709. 03211
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Dong, J., Jiang, W., Huang, Q., Bao, H., Zhou, X.: Fast and robust multi-person 3d pose estimation from multiple views. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7792–7801 (2019)
2019
-
[8]
In: 2015 IEEE International Conference on Robotics and Automation (ICRA)
Ewerton, M., Neumann, G., Lioutikov, R., Ben Amor, H., Peters, J., Maeda, G.: Learning multiple collaborative tasks with a mixture of Interaction Primitives. In: 2015 IEEE International Conference on Robotics and Automation (ICRA). pp. 1535–1542 (May 2015).https://doi.org/10.1109/ICRA.2015.7139393
-
[9]
Fang,H.S.,Fang,H.,Tang,Z.,Liu,J.,Wang,C.,Wang,J.,Zhu,H.,Lu,C.:RH20T: A Comprehensive Robotic Dataset for Learning Diverse Skills in One-Shot (Sep 2023).https://doi.org/10.48550/arXiv.2307.00595
-
[10]
In: Proceedings of The 8th Conference on Robot Learning
Fishman, A., Walsman, A., Bhardwaj, M., Yuan, W., Sundaralingam, B., Boots, B.,Fox, D.:Avoid Everything: Model-FreeCollision AvoidancewithExpert-Guided Fine-Tuning. In: Proceedings of The 8th Conference on Robot Learning. pp. 1925–
1925
-
[11]
Fu, Z., Zhao, T.Z., Finn, C.: Mobile ALOHA: Learning Bimanual Mobile Manip- ulation with Low-Cost Whole-Body Teleoperation (Jan 2024).https://doi.org/ 10.48550/arXiv.2401.02117
-
[12]
Garrido-Jurado, S., Muñoz-Salinas, R., Madrid-Cuevas, F., Marín-Jiménez, M.: Automatic generation and detection of highly reliable fiducial markers under oc- clusion. Pattern Recogn.47(6), 2280–2292 (2014).https://doi.org/10.1016/j. patcog.2014.01.005
work page doi:10.1016/j 2014
-
[13]
In: Proceedings OmniRobotHome17 of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings OmniRobotHome17 of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19383–19400 (2024)
2024
-
[14]
Grunerts Archiv fur Mathematik und Physik pp
Grunert, J.A.: Das pothenotische problem in erweiterter gestalt nebst bber seine anwendungen in der geodasie. Grunerts Archiv fur Mathematik und Physik pp. 238–248 (1841)
- [15]
-
[16]
Jenamani, R.K., Silver, T., Dodson, B., Tong, S., Song, A., Yang, Y., Liu, Z., Howe, B., Whitneck, A., Bhattacharjee, T.: FEAST: A Flexible Mealtime-Assistance System Towards In-the-Wild Personalization (Jun 2025).https://doi.org/10. 48550/arXiv.2506.14968
-
[17]
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K.: Rtm- pose: Real-time multi-person pose estimation based on mmpose. arXiv preprint arXiv:2303.07399 (2023)
-
[18]
Jin, S., Xu, L., Xu, J., Wang, C., Liu, W., Qian, C., Ouyang, W., Luo, P.: Whole- Body Human Pose Estimation in the Wild (Jul 2020).https://doi.org/10. 48550/arXiv.2007.11858
-
[19]
Joo, H., Simon, T., Li, X., Liu, H., Tan, L., Gui, L., Banerjee, S., Godisart, T., Nabbe, B., Matthews, I., Kanade, T., Nobuhara, S., Sheikh, Y.: Panoptic Studio: A Massively Multiview System for Social Interaction Capture (Dec 2016).https: //doi.org/10.48550/arXiv.1612.03153
-
[20]
K A, A., J, D.U., Subramaniam, U.: A Systematic Literature Review on Multi- Robot Task Allocation. ACM Comput. Surv.57(3), 68:1–68:28 (2024).https: //doi.org/10.1145/3700591
-
[21]
In: Conference on robot learning
Kalashnikov, D., Irpan, A., Pastor, P., Ibarz, J., Herzog, A., Jang, E., Quillen, D., Holly, E., Kalakrishnan, M., Vanhoucke, V., et al.: Scalable deep reinforcement learning for vision-based robotic manipulation. In: Conference on robot learning. pp. 651–673. PMLR (2018)
2018
-
[22]
Kedia, K., Bhardwaj, A., Dan, P., Choudhury, S.: InteRACT: Transformer Models for Human Intent Prediction Conditioned on Robot Actions (Jun 2024).https: //doi.org/10.48550/arXiv.2311.12943
-
[23]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., Fagan, P.D., Hejna, J., Itkina, M., Lepert, M., Ma, Y.J., Miller, P.T., Wu, J., Belkhale, S., Dass, S., Ha, H., Jain, A., Lee, A., Lee, Y., Memmel, M., Park, S., Radosavovic, I., Wang, K., Zhan, A., Black, K., Chi, C., Ha...
work page internal anchor Pith review doi:10.48550/arxiv.2403.12945 2025
-
[24]
Kim, H., Kim, C., Pan, M., Lee, K., Choi, S.: Learning-based Dynamic Robot-to- Human Handover (Feb 2025).https://doi.org/10.48550/arXiv.2502.12602 18 Lee et al
-
[25]
Kim, J., Kim, J., Na, J., Joo, H.: ParaHome: Parameterizing Everyday Home Activities Towards 3D Generative Modeling of Human-Object Interactions (Jan 2025).https://doi.org/10.48550/arXiv.2401.10232
-
[26]
In: International Conference on Machine Learning (2024)
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: OpenVLA: An open-source vision-language-action model. In: International Conference on Machine Learning (2024)
2024
-
[27]
Naval research logistics quarterly2(1-2), 83–97 (1955)
Kuhn, H.W.: The hungarian method for the assignment problem. Naval research logistics quarterly2(1-2), 83–97 (1955)
1955
-
[28]
Lai, M., Go, K., Li, Z., Kroger, T., Schaal, S., Allen, K., Scholz, J.: RoboBal- let: Planning for Multi-Robot Reaching with Graph Neural Networks and Re- inforcement Learning. Science Robotics10(106), eads1204 (Sep 2025).https: //doi.org/10.1126/scirobotics.ads1204
- [29]
-
[30]
In: European conference on computer vision
Li, Y., Yang, S., Liu, P., Zhang, S., Wang, Y., Wang, Z., Yang, W., Xia, S.T.: Simcc: A simple coordinate classification perspective for human pose estimation. In: European conference on computer vision. pp. 89–106. Springer (2022)
2022
-
[31]
arXiv preprint arXiv:2401.12202 (2024)
Liu, P., Orru, Y., Vakil, J., Paxton, C., Shafiullah, N.M.M., Pinto, L.: Ok-robot: What really matters in integrating open-knowledge models for robotics. arXiv preprint arXiv:2401.12202 (2024)
-
[32]
Lu, J., Huang, C.H.P., Bhattacharya, U., Huang, Q., Zhou, Y.: HUMOTO: A 4D Dataset of Mocap Human Object Interactions (Oct 2025).https://doi.org/10. 48550/arXiv.2504.10414
-
[33]
In: Proceedings of the IEEE/CVF international conference on computer vision
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: Archive of motion capture as surface shapes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5442–5451 (2019)
2019
-
[34]
In: European Conference on Computer Vision
Mao, W., Liu, M., Salzmann, M.: History repeats itself: Human motion prediction via motion attention. In: European Conference on Computer Vision. pp. 474–489. Springer (2020)
2020
-
[35]
In: Proceedings of the 2014 ACM/IEEE In- ternational Conference on Human-robot Interaction
Moon, Aj., Troniak, D.M., Gleeson, B., Pan, M.K., Zheng, M., Blumer, B.A., MacLean, K., Croft, E.A.: Meet me where i’m gazing: How shared attention gaze affects human-robot handover timing. In: Proceedings of the 2014 ACM/IEEE In- ternational Conference on Human-robot Interaction. pp. 334–341. ACM, Bielefeld Germany (Mar 2014).https://doi.org/10.1145/2559...
-
[36]
O’Neill, A., Rehman, A., Gupta, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., Tung, A., Bewley, A., Herzog, A., Irpan, A., Khazatsky, A., Rai, A., Gupta, A., Wang, A., Kolobov, A., Singh, A., Garg, A., Kembhavi, A., Xie, A., Brohan, A., Raffin, A., Sharma, A., Yavary, A., Jain, A., Balakrishna, A., Wa...
work page internal anchor Pith review doi:10.48550/arxiv.2310.08864 2025
-
[37]
IEEE Transactions on pattern analysis and machine intelligence21(8), 774–780 (1999)
Quan, L., Lan, Z.: Linear n-point camera pose determination. IEEE Transactions on pattern analysis and machine intelligence21(8), 774–780 (1999)
1999
-
[38]
Ratliff, N.D., Issac, J., Kappler, D., Birchfield, S., Fox, D.: Riemannian Motion Policies (Jul 2018).https://doi.org/10.48550/arXiv.1801.02854
-
[39]
In: European conference on computer vision
Salzmann, T., Ivanovic, B., Chakravarty, P., Pavone, M.: Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In: European conference on computer vision. pp. 683–700. Springer (2020)
2020
-
[40]
https://doi.org/10.48550/ARXIV.2509.25164
Sapkota, R., Cheppally, R.H., Sharda, A., Karkee, M.: Yolo26: key architectural enhancements and performance benchmarking for real-time object detection. arXiv preprint arXiv:2509.25164 (2025)
-
[41]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016)
2016
-
[42]
In: Conference on robot learning
Shridhar, M., Manuelli, L., Fox, D.: Cliport: What and where pathways for robotic manipulation. In: Conference on robot learning. pp. 894–906. PMLR (2022)
2022
-
[43]
https://doi.org/10.48550/arXiv.2505.10239
Solak, G., Lahr, G.J.G., Ozdamar, I., Ajoudani, A.: Context-aware collaborative pushing of heavy objects using skeleton-based intention prediction (May 2025). https://doi.org/10.48550/arXiv.2505.10239
-
[44]
In: Computer Vision – ECCV 2020: 16th Eu- 20 Lee et al
Taheri, O., Ghorbani, N., Black, M.J., Tzionas, D.: GRAB: A Dataset of Whole- Body Human Grasping of Objects. In: Computer Vision – ECCV 2020: 16th Eu- 20 Lee et al. ropean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV. pp. 581–600. Springer-Verlag, Berlin, Heidelberg (2020).https://doi.org/10.1007/ 978-3-030-58548-8_34
2020
-
[45]
Tsai, R., Lenz, R.: A new technique for fully autonomous and efficient 3D robotics hand/eye calibration. IEEE Transactions on Robotics and Automation5(3), 345– 358 (Jun 1989).https://doi.org/10.1109/70.34770
-
[46]
https://doi.org/10.48550/arXiv.2108.06038
Wang, C., Pérez-D’Arpino, C., Xu, D., Fei-Fei, L., Liu, C.K., Savarese, S.: Co- GAIL: Learning Diverse Strategies for Human-Robot Collaboration (Sep 2023). https://doi.org/10.48550/arXiv.2108.06038
-
[47]
Wang, H., Kedia, K., Ren, J., Abdullah, R., Bhardwaj, A., Chao, A., Chen, K.Y., Chin, N., Dan, P., Fan, X., Gonzalez-Pumariega, G., Kompella, A., Pace, M.A., Sharma, Y., Sun, X., Sunkara, N., Choudhury, S.: MOSAIC: Modular Foundation Models for Assistive and Interactive Cooking (Oct 2025).https://doi.org/10. 48550/arXiv.2402.18796
- [48]
-
[49]
CVPR (2026)
Wen, B., Dewan, S., Birchfield, S.: Fast-FoundationStereo: Real-time zero-shot stereo matching. CVPR (2026)
2026
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wen, B., Trepte, M., Aribido, J., Kautz, J., Gallo, O., Birchfield, S.: Foundation- stereo: Zero-shot stereo matching. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5249–5260 (2025)
2025
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wen, B., Yang, W., Kautz, J., Birchfield, S.: Foundationpose: Unified 6d pose esti- mation and tracking of novel objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17868–17879 (2024)
2024
-
[52]
Autonomous Robots47(8), 1087–1102 (2023)
Wu, J., Antonova, R., Kan, A., Lepert, M., Zeng, A., Song, S., Bohg, J., Rusinkiewicz,S.,Funkhouser,T.:Tidybot:Personalizedrobotassistancewithlarge language models. Autonomous Robots47(8), 1087–1102 (2023)
2023
-
[53]
Xia, G., Ghrairi, Z., Wuest, T., Hribernik, K., Heuermann, A., Liu, F., Liu, H., Thoben, K.D.: Towards Human Modeling for Human-Robot Collaboration and Digital Twins in Industrial Environments: Research Status, Prospects, and Chal- lenges. Robot. Comput.-Integr. Manuf.95(C) (2025).https://doi.org/10.1016/ j.rcim.2025.103043
-
[54]
In: Proceedings of 1995 IEEE International Conference on Robotics and Automation
Yamada, Y., Nagamatsu, S., Sato, Y.: Development of multi-arm robots for au- tomobile assembly. In: Proceedings of 1995 IEEE International Conference on Robotics and Automation. vol. 3, pp. 2224–2229 vol.3 (May 1995).https://doi. org/10.1109/ROBOT.1995.525592
-
[55]
Yang, J., Liu, J.J., Li, Y., Khaky, Y., Shaw, K., Pathak, D.: Deep Reactive Policy: Learning Reactive Manipulator Motion Planning for Dynamic Environments (Sep 2025).https://doi.org/10.48550/arXiv.2509.06953
-
[56]
In: Proceedings of the Thirty-Fourth International Joint Con- ference on Artificial Intelligence, pp
Ye, X., Liang, G., Wang, C., Li, L., Ke, P., Wang, R., Jia, B., Huang, G., Sun, Q., Zhou, S.: M4Bench. In: Proceedings of the Thirty-Fourth International Joint Con- ference on Artificial Intelligence, pp. 6848–6856. Guide Proceedings (Aug 2025). https://doi.org/10.24963/ijcai.2025/762
-
[57]
arXiv preprint arXiv:2507.22885 (2025)
Yi, B., Kim, C.M., Kerr, J., Wu, G., Feng, R., Zhang, A., Kulhanek, J., Choi, H., Ma, Y., Tancik, M., Kanazawa, A.: Viser: Imperative, web-based 3d visualization in python. arXiv preprint arXiv:2507.22885 (2025)
-
[58]
In: Conference on Robot Learning
Zeng,A.,Florence,P.,Tompson,J.,Welker,S.,Chien,J.,Attarian,M.,Armstrong, T., Krasin, I., Duong, D., Sindhwani, V., et al.: Transporter networks: Rearranging the visual world for robotic manipulation. In: Conference on Robot Learning. pp. 726–747. PMLR (2021) OmniRobotHome21
2021
-
[59]
Zhang, Z.: A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell.22(11), 1330–1334 (2000).https://doi.org/10.1109/34. 888718
work page doi:10.1109/34 2000
-
[60]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T.Z., Kumar, V., Levine, S., Finn, C.: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (Apr 2023).https://doi.org/10.48550/ arXiv.2304.13705 22 Lee et al. This supplement provides additional technical details on the system components, task pipelines, and evaluation methodology ofOmniRobotHome. Sec. A covers system details: the har...
work page internal anchor Pith review arXiv 2023
-
[61]
Do NOT use prior knowledge about these objects; base your an- swer solely on the provided examples
to localize persons with a confidence threshold of 0.5. To mitigate momen- tary occlusions, we employ a temporal carry-over mechanism that propagates the last valid bounding box for up to 3 frames with a confidence decay factor of 0.85. Detected person regions are cropped, affine-warped to384×288, and fed into an RTMPose [17] model (also TensorRT-accelera...
-
[62]
OmniRobotHome39
A 2x3 grid image showing six synchronized camera views of the scene. OmniRobotHome39
-
[63]
3D body keypoints (16 joints, world coordinates in meters)
-
[64]
reachable
A candidate object list (23 items). Your task is to infer what object the person most likely needs right now. Reason step by step: Step 1 – Reachability: Identify which candidates are physically present on the tabletop and reachable by the robot arm. List them. Step 2 – Activity: Examine all six viewpoints holistically. Describe the person’s current activ...
-
[65]
peach, 7
pear, 6. peach, 7. pringles can, 8. spam, 9. mustard bottle, 10. soup can, 11. cereal box, 12. ketchup bottle, 13. water bottle, 14. coffee mug, 15. cutting board, 16. kitchen knife, 17. spatula, 18. sponge,
-
[66]
salt shaker, 21
dish towel, 20. salt shaker, 21. pepper mill, 22. phone, 23. TV remote. Do NOT rely on generic priors. Ground every inference in the visual and geometric evidence provided
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.