Recognition: unknown
RSAT: Structured Attribution Makes Small Language Models Faithful Table Reasoners
Pith reviewed 2026-05-09 20:23 UTC · model grok-4.3
The pith
Training small language models to output reasoning with built-in cell citations raises faithfulness 3.7 times over standard fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
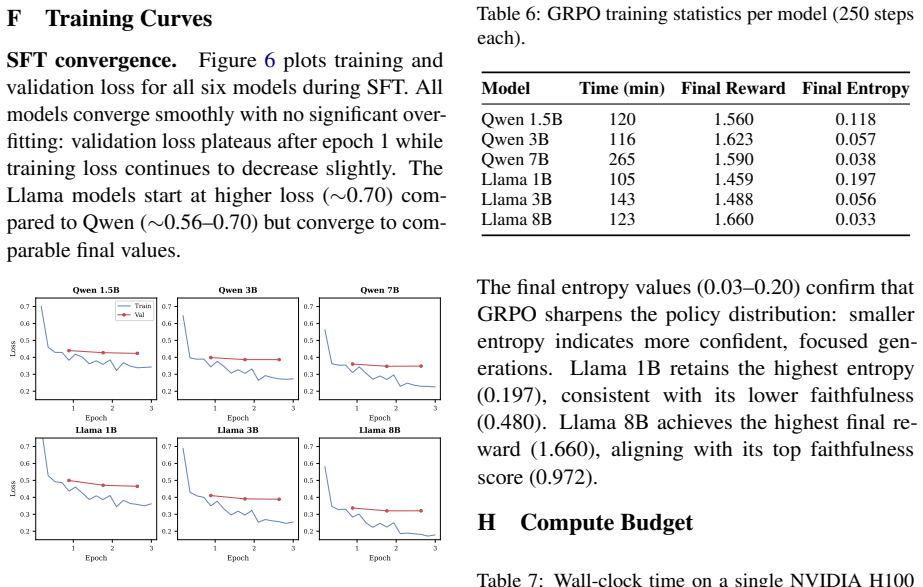
RSAT trains models to generate structured reasoning traces that cite specific table cells and optimizes them so that each reasoning step is faithful to the evidence in those cells. Across six models from the Qwen 2.5 and Llama 3 families, the method raises faithfulness from 0.224 to 0.826 while reaching 0.992 citation validity. Post-hoc attribution after ordinary fine-tuning succeeds in producing valid formats less than 13 percent of the time, and removing the faithfulness component of the reward drops faithfulness to 0.03.
What carries the argument
RSAT, a two-phase procedure that first uses supervised fine-tuning to teach structured JSON output containing cell citations, then applies GRPO to maximize a composite reward that includes NLI-based faithfulness, citation validity, and parsimony.
If this is right
- Small models from multiple families can be made to produce table reasoning whose every step is traceable to specific evidence cells.
- Attribution must be learned jointly with reasoning; retrofitting citations afterward fails to produce valid structured output.
- The faithfulness reward is the dominant driver of gains; its removal collapses performance.
- The same training pattern works for models ranging from 1B to 8B parameters without family-specific changes.
Where Pith is reading between the lines
- The same integrated-attribution training could be tested on other tasks that require grounding in external data, such as spreadsheet formulas or database queries.
- If the method generalizes, production table-question systems could expose the cited cells to users for direct verification instead of relying on model self-reports.
- Future experiments could measure whether the structured format itself improves downstream accuracy on multi-hop table questions even when faithfulness rewards are held constant.
Load-bearing premise
The NLI-based faithfulness reward correctly identifies whether each reasoning step is genuinely supported by the cited table cells rather than merely overlapping with their text.
What would settle it
A side-by-side human audit that checks whether every cited cell actually entails the corresponding reasoning step in RSAT outputs, and whether the same steps would hold without those exact citations, would falsify the claim if the human scores show no improvement over baselines.
Figures






read the original abstract
When a language model answers a table question, users have no way to verify which cells informed which reasoning steps. We introduce RSAT, a method that trains small language models (SLMs, 1-8B) to produce step-by-step reasoning with cell-level citations grounded in table evidence. Phase 1 (SFT) teaches a structured JSON output format from verified reasoning traces. Phase 2 (GRPO) optimizes a composite reward centered on NLI-based faithfulness, alongside citation validity and parsimony. Across six models from two families-Qwen 2.5 (1.5B/3B/7B) and Llama 3 (1B/3B/8B)-RSAT improves faithfulness 3.7$\times$ over SFT alone (0.224$\rightarrow$0.826), with near-perfect citation validity (0.992). Post-hoc attribution collapses below 13% format success, confirming that attribution must be integrated into reasoning, not retrofitted. Ablations show the faithfulness reward is essential: removing it drops faithfulness from 0.97 to 0.03.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RSAT, a two-phase training method for small language models (1-8B parameters from Qwen 2.5 and Llama 3 families) to produce step-by-step reasoning with cell-level citations for table question answering. Phase 1 applies SFT on verified reasoning traces to teach a structured JSON output format; Phase 2 uses GRPO to optimize a composite reward centered on NLI-based faithfulness, citation validity, and parsimony. The central claims are a 3.7× faithfulness improvement over SFT alone (0.224→0.826), near-perfect citation validity (0.992), failure of post-hoc attribution (<13% format success), and the necessity of the faithfulness reward (ablation drop from 0.97 to 0.03).
Significance. If the results hold, the work demonstrates that integrating structured attribution into the training process via SFT+GRPO can substantially improve faithfulness and interpretability for table reasoning in SLMs, outperforming post-hoc methods. The cross-family consistency and reward ablation provide useful evidence on training objectives for grounded generation, with potential applications in verifiable structured-data tasks.
major comments (3)
- The evaluation protocol is insufficiently specified: the abstract and results report faithfulness gains (0.224→0.826) and ablation values (0.97→0.03) without dataset details, error bars, full metrics definitions, or statistical tests. This undermines verification of the central claim of consistent 3.7× gains across six models.
- The NLI-based faithfulness reward (Phase 2) is load-bearing for the reported improvements, yet the manuscript provides no validation that it measures genuine cell-level evidence grounding rather than superficial textual overlap or plausible reasoning steps. Without targeted analysis or human evaluation of whether cited cells are actually consulted, the SFT+GRPO gains and post-hoc collapse could reflect format learning instead.
- Phase 1 relies on verified reasoning traces for SFT, but no details are given on the verification process, how cell-level accuracy was ensured, or checks for systematic biases in those traces. Any such bias would propagate through the GRPO stage and affect the faithfulness metric.
minor comments (2)
- The abstract states 'near-perfect citation validity (0.992)' without defining the precise criteria or computation method for citation validity.
- Clarify the apparent discrepancy between the main faithfulness score (0.826) and the ablation reference value (0.97); they may reflect different evaluation conditions or metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: The evaluation protocol is insufficiently specified: the abstract and results report faithfulness gains (0.224→0.826) and ablation values (0.97→0.03) without dataset details, error bars, full metrics definitions, or statistical tests. This undermines verification of the central claim of consistent 3.7× gains across six models.
Authors: We agree that the evaluation protocol requires more detailed specification to allow full verification of our claims. In the revised manuscript, we will add comprehensive details on the datasets used, including their sources, sizes, and splits. We will provide precise mathematical definitions for all metrics, including the faithfulness score based on NLI. Additionally, we will report error bars (standard deviations over multiple seeds) and conduct statistical tests (e.g., Wilcoxon signed-rank tests) to confirm the significance of the 3.7× improvement across the six models from both families. These additions will be placed in the Experiments and Appendix sections. revision: yes
-
Referee: The NLI-based faithfulness reward (Phase 2) is load-bearing for the reported improvements, yet the manuscript provides no validation that it measures genuine cell-level evidence grounding rather than superficial textual overlap or plausible reasoning steps. Without targeted analysis or human evaluation of whether cited cells are actually consulted, the SFT+GRPO gains and post-hoc collapse could reflect format learning instead.
Authors: This is a valid concern regarding the validity of our NLI-based reward. While the reward combines NLI entailment with citation validity to encourage grounding, we did not include explicit validation against human judgments in the original submission. In the revision, we will incorporate a targeted analysis: we will sample outputs from the model and have them annotated by humans for whether the cited cells are indeed the ones used in the reasoning steps (as opposed to superficial matches). We will report the correlation between the automated NLI faithfulness score and human assessments. This will help demonstrate that the improvements are due to genuine attribution rather than mere format adherence. We will also discuss potential limitations of NLI in this context. revision: yes
-
Referee: Phase 1 relies on verified reasoning traces for SFT, but no details are given on the verification process, how cell-level accuracy was ensured, or checks for systematic biases in those traces. Any such bias would propagate through the GRPO stage and affect the faithfulness metric.
Authors: We acknowledge the need for transparency on the trace verification process. In the revised version, we will expand the Method section to describe in detail how the verified reasoning traces were created and validated. This includes: the protocol for ensuring cell-level accuracy (e.g., cross-checking each step against the table cells), the steps taken to avoid systematic biases (such as using diverse table domains and question types, and balancing positive/negative examples), and any automated or manual verification procedures employed. We will also discuss how this verification helps prevent bias propagation into the GRPO phase. revision: yes
Circularity Check
No circularity: training pipeline and metrics rely on external components
full rationale
The RSAT method consists of Phase-1 SFT on verified reasoning traces followed by Phase-2 GRPO optimization using a composite reward that includes an independent NLI model for faithfulness scoring against table content, plus citation validity and parsimony terms. All reported gains (e.g., 0.224 to 0.826 faithfulness) are measured against separate baselines such as plain SFT and post-hoc attribution methods; no result is obtained by fitting a parameter to a subset of the evaluation data and then relabeling it as a prediction. No equations are self-referential, no uniqueness theorems are imported from the authors' prior work, and no ansatz or renaming of known results occurs. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- composite reward weights
axioms (2)
- domain assumption NLI models reliably detect whether reasoning steps are supported by cited table cells
- domain assumption Verified reasoning traces used in SFT are accurate and unbiased
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
TaPas: Weakly supervised table parsing via pre-training , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[2]
arXiv preprint arXiv:2107.07653 , year=
TAPEX: Table pre-training via learning a neural SQL executor , author=. arXiv preprint arXiv:2107.07653 , year=
-
[3]
Compositional semantic parsing on semi-structured tables , author=. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[4]
Binding language models in symbolic languages , author=. arXiv preprint arXiv:2210.02875 , year=
-
[5]
Chain-of-table: Evolving tables in the reasoning chain for table understanding , author=. arXiv preprint arXiv:2401.04398 , year=
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
Understanding tables with intermediate pre-training , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
2020
-
[7]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
TaBERT: Pretraining for joint understanding of textual and tabular data , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[8]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning , author=. arXiv preprint arXiv:1709.00103 , year=
work page internal anchor Pith review arXiv
-
[9]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TaPERA: Enhancing faithfulness and interpretability in long-form table QA by content planning and execution-based reasoning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
ArXivabs/1909.02164(2019),https://api.semanticscholar.org/CorpusID: 1989173392
Tabfact: A large-scale dataset for table-based fact verification , author=. arXiv preprint arXiv:1909.02164 , year=
-
[11]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
PASTA: table-operations aware fact verification via sentence-table cloze pre-training , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
-
[12]
Joint verification and reranking for open fact checking over tables , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[13]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Program enhanced fact verification with verbalization and graph attention network , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[14]
The Twelfth International Conference on Learning Representations , year=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Enabling large language models to generate text with citations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[16]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Rarr: Researching and revising what language models say, using language models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
Computational Linguistics , volume=
Measuring attribution in natural language generation models , author=. Computational Linguistics , volume=
-
[18]
arXiv preprint arXiv:2212.08037 , year=
Attributed question answering: Evaluation and modeling for attributed large language models , author=. arXiv preprint arXiv:2212.08037 , year=
- [19]
-
[20]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[25]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2503.16219
Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't , author=. arXiv preprint arXiv:2503.16219 , year=
-
[27]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[28]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[31]
Transactions of the Association for Computational Linguistics , volume=
FeTaQA: Free-form table question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[32]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Deberta: Decoding-enhanced bert with disentangled attention , author=. arXiv preprint arXiv:2006.03654 , year=
work page internal anchor Pith review arXiv 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.