Recognition: unknown
Online Self-Calibration Against Hallucination in Vision-Language Models
Pith reviewed 2026-05-09 20:16 UTC · model grok-4.3
The pith
Vision-language models can self-calibrate against hallucinations by exploiting their own generative-discriminative accuracy gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By identifying a Generative-Discriminative Gap where LVLMs verify facts more accurately than they generate descriptions, OSCAR builds preference pairs using Monte Carlo Tree Search and a Dual-Granularity Reward Mechanism to enable online Direct Preference Optimization that reduces hallucinations while enhancing overall multimodal performance.
What carries the argument
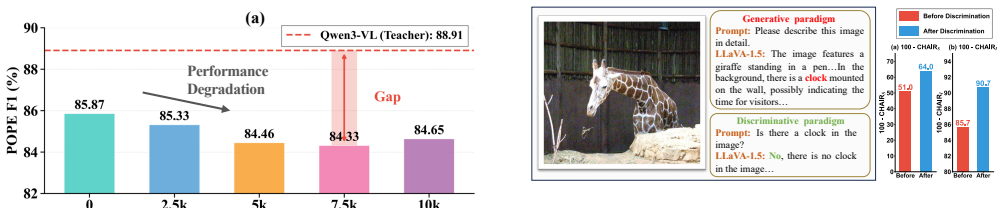
The Generative-Discriminative Gap that supplies reliable internal self-supervision for constructing preference data in the OSCAR framework.
If this is right
- OSCAR reaches state-of-the-art results on standard hallucination evaluation benchmarks.
- It simultaneously boosts performance on general multimodal understanding tasks.
- The method operates entirely online without distilling from stronger external models.
- It avoids forcing the model to align with details it cannot yet perceive.
- Preference data is generated iteratively by the model itself during training.
Where Pith is reading between the lines
- This approach may extend to correcting other types of model inconsistencies by finding similar internal capability gaps.
- Self-supervised preference alignment could reduce reliance on proprietary large models for fine-tuning smaller ones.
- Similar gaps might be exploitable in text-only or audio models for self-improvement.
- Long-term, repeated application could lead to models that iteratively improve their perceptual accuracy autonomously.
Load-bearing premise
The difference in accuracy between generating and verifying answers gives trustworthy self-supervision that genuinely enhances perception instead of creating new guessing strategies.
What would settle it
Running OSCAR on a model and then testing it on images where the discriminative checks used in training no longer reduce hallucination rates would falsify the claim that the method produces real perceptual gains.
Figures




read the original abstract
Large Vision-Language Models (LVLMs) often suffer from hallucinations, generating descriptions that include visual details absent from the input image. Recent preference alignment methods typically rely on supervision distilled from stronger models such as GPT. However, this offline paradigm introduces a Supervision-Perception Mismatch: the student model is forced to align with fine-grained details beyond its perceptual capacity, learning to guess rather than to see. To obtain reliable self-supervision for online learning, we identify a Generative-Discriminative Gap within LVLMs, where models exhibit higher accuracy on discriminative verification than open-ended generation. Leveraging this capability, we propose \textbf{O}nline \textbf{S}elf-\textbf{CA}lib\textbf{R}ation (OSCAR), a framework that integrates Monte Carlo Tree Search with a Dual-Granularity Reward Mechanism to construct preference data and iteratively refines the model via Direct Preference Optimization. Extensive experiments demonstrate that OSCAR achieves state-of-the-art performance on hallucination benchmarks while improving general multimodal capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OSCAR, an online self-calibration framework for Large Vision-Language Models (LVLMs) to reduce hallucinations. It exploits an observed Generative-Discriminative Gap to construct preference pairs via Monte Carlo Tree Search (MCTS) combined with a Dual-Granularity Reward Mechanism, then applies Direct Preference Optimization (DPO) iteratively. The central claim is that this avoids the Supervision-Perception Mismatch of offline methods relying on stronger models like GPT, yielding state-of-the-art results on hallucination benchmarks while also improving general multimodal capabilities.
Significance. If the empirical results are robust, OSCAR provides a self-supervised alternative to external distillation for preference alignment in multimodal models. This could meaningfully advance reliable perception in LVLMs by turning internal model discrepancies into training signals, with potential benefits for both hallucination mitigation and broader capabilities.
major comments (2)
- [§4] §4 (Experiments): The manuscript asserts state-of-the-art performance on hallucination benchmarks and improvements in general multimodal capabilities, yet provides no explicit list of baselines, exact metrics (e.g., CHAIR, POPE, or others), data splits, number of runs, or statistical tests. This absence prevents verification of the SOTA claim and leaves the central empirical outcome unassessable.
- [§3.3] §3.3 (Preference Data Construction): The Dual-Granularity Reward is presented as leveraging the Generative-Discriminative Gap for reliable self-supervision, but the paper does not quantify how the gap is measured per sample or demonstrate that it consistently yields perception improvements rather than altered guessing patterns; this assumption is load-bearing for the online learning pipeline.
minor comments (3)
- [Abstract / §1] The abstract and §1 could more precisely define the Generative-Discriminative Gap with a short formal statement or example before describing its use in MCTS.
- [Figure 2] Figure 2 (method overview) would benefit from clearer labeling of the reward computation steps and how MCTS nodes map to preference pairs.
- [§3] Notation for the reward function r(·) and the DPO loss should be introduced with an equation in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The manuscript asserts state-of-the-art performance on hallucination benchmarks and improvements in general multimodal capabilities, yet provides no explicit list of baselines, exact metrics (e.g., CHAIR, POPE, or others), data splits, number of runs, or statistical tests. This absence prevents verification of the SOTA claim and leaves the central empirical outcome unassessable.
Authors: We agree that the experimental section would benefit from greater explicitness to allow full verification. In the revised manuscript, we will add a new subsection in §4 that lists all baselines with citations, provides exact metric definitions and computation details (including CHAIR, POPE, and any others), specifies the evaluation data splits, reports the number of runs (we conducted three independent runs with different random seeds), and includes statistical significance tests (e.g., paired t-tests with p-values). The performance numbers in the current tables remain unchanged, but this addition will make the SOTA claims directly verifiable without altering the core results. revision: yes
-
Referee: [§3.3] §3.3 (Preference Data Construction): The Dual-Granularity Reward is presented as leveraging the Generative-Discriminative Gap for reliable self-supervision, but the paper does not quantify how the gap is measured per sample or demonstrate that it consistently yields perception improvements rather than altered guessing patterns; this assumption is load-bearing for the online learning pipeline.
Authors: We appreciate this observation on the load-bearing assumption. The gap is operationalized by scoring generated responses against discriminative verification accuracy on the same image-question pairs. In the revision, we will expand §3.3 with a quantitative per-sample analysis (including average gap statistics across the dataset and a histogram of gap values) and new ablation experiments. These will compare OSCAR against variants using random or non-gap-based preferences, showing consistent gains on held-out visual grounding and perception metrics that indicate improved perception rather than guessing. This will be presented via additional tables and discussion to directly address the concern. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's framework begins with an empirical observation of the Generative-Discriminative Gap (higher accuracy on verification than generation), uses this to construct online preference data via MCTS and Dual-Granularity Reward, and applies DPO for iterative refinement. This sequence relies on external benchmarks for validation and does not reduce any claimed result to a fitted parameter, self-defined quantity, or self-citation chain by construction. No equations or steps equate outputs to inputs tautologically; the gap is treated as an observed capability rather than a derived theorem, and performance gains are presented as experimental outcomes rather than forced by the method's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LVLMs exhibit a reliable Generative-Discriminative Gap that can be leveraged for self-supervision
Reference graph
Works this paper leans on
-
[1]
[Achiamet al., 2023 ] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
[Baiet al., 2023 ] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Hallucination of Multimodal Large Language Models: A Survey
[Baiet al., 2024 ] Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930,
work page internal anchor Pith review arXiv 2024
-
[4]
Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing sys- tems, 36:49250–49267,
[Daiet al., 2023 ] Wenliang Dai, Junnan Li, Dongxu Li, An- thony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing sys- tems, 36:49250–49267,
2023
-
[5]
S-grpo: Early exit via reinforcement learning in reasoning models,
[Daiet al., 2025 ] Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models,
2025
-
[6]
Enhancing large vision language mod- els with self-training on image comprehension.Advances in Neural Information Processing Systems, 37:131369– 131397,
[Denget al., 2024 ] Yihe Deng, Pan Lu, Fan Yin, Ziniu Hu, Sheng Shen, Quanquan Gu, James Y Zou, Kai-Wei Chang, and Wei Wang. Enhancing large vision language mod- els with self-training on image comprehension.Advances in Neural Information Processing Systems, 37:131369– 131397,
2024
-
[7]
Detecting and preventing hallucinations in large vi- sion language models
[Gunjalet al., 2024 ] Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and preventing hallucinations in large vi- sion language models. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 38, pages 18135– 18143,
2024
-
[8]
Reason- ing with language model is planning with world model
[Haoet al., 2023 ] Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reason- ing with language model is planning with world model. In Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 8154–8173,
2023
-
[9]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
[Huet al., 2022 ] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
2022
-
[10]
[Huet al., 2024 ] Chi Hu, Yimin Hu, Hang Cao, Tong Xiao, and Jingbo Zhu. Teaching language models to self- improve by learning from language feedback.arXiv preprint arXiv:2406.07168,
-
[11]
Large language models can self-improve
[Huanget al., 2023 ] Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 1051–1068,
2023
-
[12]
Opera: Alleviating hal- lucination in multi-modal large language models via over- trust penalty and retrospection-allocation
[Huanget al., 2024 ] Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hal- lucination in multi-modal large language models via over- trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 134...
2024
-
[13]
Mitigating object hallucinations in large vision- language models through visual contrastive decoding
[Lenget al., 2024 ] Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision- language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882,
2024
-
[14]
Think&cite: Improving attributed text generation with self-guided tree search and progress reward modeling
[Li and Ng, 2025] Junyi Li and Hwee Tou Ng. Think&cite: Improving attributed text generation with self-guided tree search and progress reward modeling. InProceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 9928– 9942,
2025
-
[15]
Silkie: Preference distillation for large visual language models
[Liet al., 2023a ] Lei Li, Zhihui Xie, Mukai Li, Shunian Chen, Peiyi Wang, Liang Chen, Yazheng Yang, Benyou Wang, and Lingpeng Kong. Silkie: Preference distil- lation for large visual language models.arXiv preprint arXiv:2312.10665,
-
[16]
Evaluating Object Hallucination in Large Vision-Language Models
[Liet al., 2023b ] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating ob- ject hallucination in large vision-language models.arXiv preprint arXiv:2305.10355,
work page internal anchor Pith review arXiv
-
[17]
Chatsop: An sop-guided mcts planning framework for controllable llm dialogue agents
[Liet al., 2025 ] Zhigen Li, Jianxiang Peng, Yanmeng Wang, Yong Cao, Tianhao Shen, Minghui Zhang, Linxi Su, Shang Wu, Yihang Wu, Yuqian Wang, et al. Chatsop: An sop-guided mcts planning framework for controllable llm dialogue agents. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Vol- ume 1: Long Papers), page...
2025
-
[18]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
[Liuet al., 2023b ] Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. Mitigating hallu- cination in large multi-modal models via robust instruction tuning.arXiv preprint arXiv:2306.14565,
work page internal anchor Pith review arXiv
-
[19]
A Survey on Hallucination in Large Vision-Language Models
[Liuet al., 2024 ] Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucina- tion in large vision-language models.arXiv preprint arXiv:2402.00253,
work page internal anchor Pith review arXiv 2024
-
[20]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
[Luet al., 2024 ] Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv 2024
-
[21]
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
[Rafailovet al., 2023 ] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
2023
-
[22]
A survey of hallucination in large foundation models
[Rawteet al., 2023 ] Vipula Rawte, Amit Sheth, and Amitava Das. A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922,
-
[23]
Object Hallucination in Image Captioning
[Rohrbachet al., 2018 ] Anna Rohrbach, Lisa Anne Hen- dricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning.arXiv preprint arXiv:1809.02156,
work page Pith review arXiv 2018
-
[24]
Multi-armed bandits with episode context.Annals of Mathematics and Artifi- cial Intelligence, 61(3):203–230,
[Rosin, 2011] Christopher D Rosin. Multi-armed bandits with episode context.Annals of Mathematics and Artifi- cial Intelligence, 61(3):203–230,
2011
-
[25]
Check it again:progressive visual question answering via visual entailment
[Siet al., 2021 ] Qingyi Si, Zheng Lin, Ming yu Zheng, Peng Fu, and Weiping Wang. Check it again:progressive visual question answering via visual entailment. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conferenc...
2021
-
[26]
[Siet al., 2022a ] Qingyi Si, Yuanxin Liu, Fandong Meng, Zheng Lin, Peng Fu, Yanan Cao, Weiping Wang, and Jie Zhou
Association for Computational Linguistics. [Siet al., 2022a ] Qingyi Si, Yuanxin Liu, Fandong Meng, Zheng Lin, Peng Fu, Yanan Cao, Weiping Wang, and Jie Zhou. Towards robust visual question answering: Mak- ing the most of biased samples via contrastive learning. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, edi- tors,Findings of the Association for ...
2022
-
[27]
[Siet al., 2022b ] Qingyi Si, Fandong Meng, Mingyu Zheng, Zheng Lin, Yuanxin Liu, Peng Fu, Yanan Cao, Weip- ing Wang, and Jie Zhou
Association for Computational Linguistics. [Siet al., 2022b ] Qingyi Si, Fandong Meng, Mingyu Zheng, Zheng Lin, Yuanxin Liu, Peng Fu, Yanan Cao, Weip- ing Wang, and Jie Zhou. Language prior is not the only shortcut: A benchmark for shortcut learning in VQA. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, edi- tors,Findings of the Association for Compu...
2022
-
[28]
[Siet al., 2023 ] Qingyi Si, Yuchen Mo, Zheng Lin, Huishan Ji, and Weiping Wang
Association for Computational Linguistics. [Siet al., 2023 ] Qingyi Si, Yuchen Mo, Zheng Lin, Huishan Ji, and Weiping Wang. Combo of thinking and observ- ing for outside-knowledge VQA. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Pa...
2023
-
[29]
Association for Computational Linguistics. [Silveret al., 2016 ] David Silver, Aja Huang, Chris J Maddi- son, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Pan- neershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489,
2016
-
[30]
Aligning large multimodal models with factually aug- mented rlhf
[Sunet al., 2024 ] Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually aug- mented rlhf. InFindings of the Association for Computa- tional Linguistics: ACL 2024, pages 13088–13110,
2024
-
[31]
[Sunet al., 2025 ] Yutao Sun, Mingshuai Chen, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, and Jianwei Yin. The self-improvement paradox: Can language models boot- strap reasoning capabilities without external scaffolding? arXiv preprint arXiv:2502.13441,
-
[32]
Oc- topus: Alleviating hallucination via dynamic contrastive decoding
[Suoet al., 2025 ] Wei Suo, Lijun Zhang, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. Oc- topus: Alleviating hallucination via dynamic contrastive decoding. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 29904–29914,
2025
-
[33]
Toward self-improvement of llms via imagination, search- ing, and criticizing.Advances in Neural Information Pro- cessing Systems, 37:52723–52748,
[Tianet al., 2024 ] Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Lei Han, Haitao Mi, and Dong Yu. Toward self-improvement of llms via imagination, search- ing, and criticizing.Advances in Neural Information Pro- cessing Systems, 37:52723–52748,
2024
-
[34]
An llm-free multi-dimensional benchmark for mllms hallucination evaluation.CoRR,
[Wanget al., 2023 ] Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Ming Yan, Ji Zhang, and Jitao Sang. An llm-free multi-dimensional benchmark for mllms hallucination evaluation.CoRR,
2023
-
[35]
Enhancing visual-language modality alignment in large vision language models via self-improvement
[Wanget al., 2025 ] Xiyao Wang, Jiuhai Chen, Zhaoyang Wang, Yuhang Zhou, Yiyang Zhou, Huaxiu Yao, Tianyi Zhou, Tom Goldstein, Parminder Bhatia, Taha Kass-Hout, et al. Enhancing visual-language modality alignment in large vision language models via self-improvement. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 268–282,
2025
-
[36]
[Xieet al., 2024a ] Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning.arXiv preprint arXiv:2405.00451,
-
[37]
[Xieet al., 2024b ] Yuxi Xie, Guanzhen Li, Xiao Xu, and Min-Yen Kan. V-dpo: Mitigating hallucination in large vi- sion language models via vision-guided direct preference optimization.arXiv preprint arXiv:2411.02712,
-
[38]
[Yanget al., 2025a ] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Weights-rotated prefer- ence optimization for large language models
[Yanget al., 2025b ] Chenxu Yang, Ruipeng Jia, Mingyu Zheng, Naibin Gu, Zheng Lin, Siyuan Chen, Weichong Yin, Hua Wu, and Weiping Wang. Weights-rotated prefer- ence optimization for large language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer- ence on Empirical Methods in ...
2025
-
[40]
System 1&2 synergy via dynamic model interpolation.arXiv preprint arXiv:2601.21414,
[Yanget al., 2026b ] Chenxu Yang, Qingyi Si, Chong Tian, Xiyu Liu, Dingyu Yao, Chuanyu Qin, Zheng Lin, Weiping Wang, and Jiaqi Wang. System 1&2 synergy via dynamic model interpolation.arXiv preprint arXiv:2601.21414,
-
[41]
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration
[Yeet al., 2024 ] Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, and Fei Huang. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. InProceed- ings of the ieee/cvf conference on computer vision and pat- tern recognition, pages 13040–13051,
2024
-
[42]
Woodpecker: Hallucination correction for multimodal large language models.Science China Information Sciences, 67(12):220105,
[Yinet al., 2024 ] Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. Woodpecker: Hallucination correction for multimodal large language models.Science China Information Sciences, 67(12):220105,
2024
-
[43]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
[Yuet al., 2023 ] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multi- modal models for integrated capabilities.arXiv preprint arXiv:2308.02490,
work page internal anchor Pith review arXiv 2023
-
[44]
Self-rewarding language models
[Yuanet al., 2024 ] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self-rewarding language models. In Forty-first International Conference on Machine Learning,
2024
-
[45]
[Zhanget al., 2024 ] Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b.arXiv preprint arXiv:2406.07394,
-
[46]
arXiv preprint arXiv:2402.11411 , year=
[Zhouet al., 2024 ] Yiyang Zhou, Chenhang Cui, Rafael Rafailov, Chelsea Finn, and Huaxiu Yao. Aligning modal- ities in vision large language models via preference fine- tuning.arXiv preprint arXiv:2402.11411,
-
[47]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
[Zhuet al., 2023 ] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xi- ang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large lan- guage models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.