Recognition: unknown
Odysseus: Scaling VLMs to 100+ Turn Decision-Making in Games via Reinforcement Learning
Pith reviewed 2026-05-09 20:19 UTC · model grok-4.3
The pith
Adapted reinforcement learning lets vision-language models handle 100+ turn decisions in games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
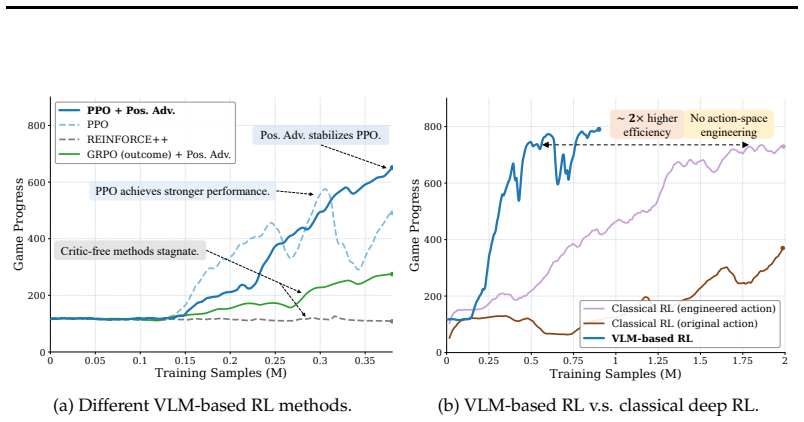
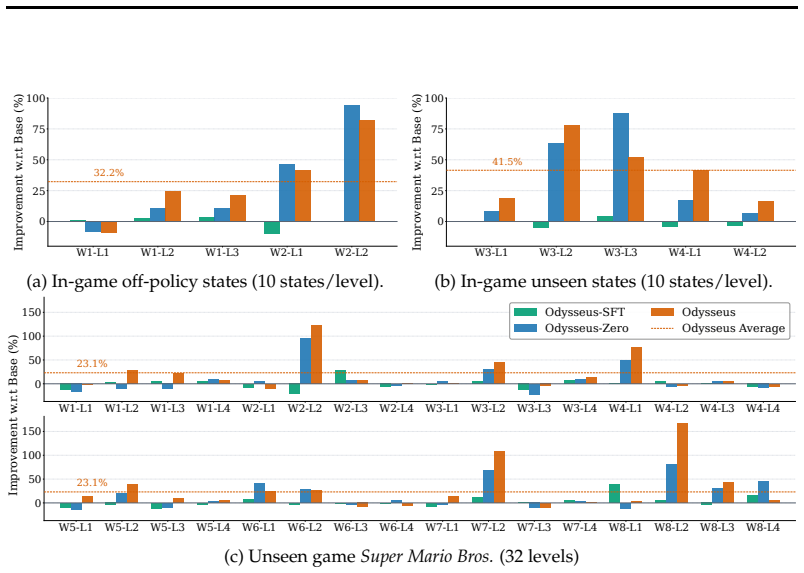
We introduce Odysseus, an open training framework for VLM agents. An adapted PPO variant with a lightweight turn-level critic substantially improves training stability and sample efficiency over critic-free baselines. Pretrained VLMs supply strong action priors that further boost efficiency and reduce manual action engineering. The resulting agents achieve substantial gains across multiple levels of Super Mario Land, at least three times the average game progress of frontier models, consistent improvements under in-game and cross-game generalization, and retention of general-domain capabilities.
What carries the argument
Adapted PPO with a lightweight turn-level critic, which stabilizes long-horizon RL training for VLMs and improves sample efficiency while using pretrained action priors.
If this is right
- Substantial performance gains across multiple levels of the game.
- At least three times the average game progress compared with frontier models.
- Consistent improvements in both in-game and cross-game generalization.
- Retention of general-domain capabilities after specialized training.
Where Pith is reading between the lines
- The same stability techniques may transfer to other long-horizon embodied tasks that combine vision and language.
- Open release of the framework could accelerate community experiments on scaling RL for VLMs beyond games.
- Further work could test whether the turn-level critic remains effective when horizons exceed several hundred steps.
Load-bearing premise
The reported performance gains and generalization come mainly from the adapted RL components and VLM priors rather than from unstated implementation choices, game-specific tuning, or evaluation details.
What would settle it
A direct head-to-head comparison on the same Super Mario Land levels that isolates the turn-level critic from critic-free methods and measures both final progress and training stability.
Figures








read the original abstract
Given the rapidly growing capabilities of vision-language models (VLMs), extending them to interactive decision-making tasks such as video games has emerged as a promising frontier. However, existing approaches either rely on large-scale supervised fine-tuning (SFT) on human trajectories or apply reinforcement learning (RL) only in relatively short-horizon settings (typically around 20--30 turns). In this work, we study RL-based training of VLMs for long-horizon decision-making in Super Mario Land, a visually grounded environment requiring 100+ turns of interaction with coordinated perception, reasoning, and action. We begin with a systematic investigation of key algorithmic components and propose an adapted variant of PPO with a lightweight turn-level critic, which substantially improves training stability and sample efficiency over critic-free methods such as GRPO and Reinforce++. We further show that pretrained VLMs provide strong action priors, significantly improving sample efficiency during RL training and reducing the need for manual design choices such as action engineering, compared to classical deep RL trained from scratch. Building on these insights, we introduce Odysseus, an open training framework for VLM agents, achieving substantial gains across multiple levels of the game and at least 3 times average game progresses than frontier models. Moreover, the trained models exhibit consistent improvements under both in-game and cross-game generalization settings, while maintaining general-domain capabilities. Overall, our results identify key ingredients for making RL stable and effective in long-horizon, multi-modal settings, and provide practical guidance for developing VLMs as embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Odysseus, an open training framework for vision-language model (VLM) agents performing long-horizon (100+ turn) decision-making in Super Mario Land. It systematically investigates RL components, proposes an adapted PPO variant with a lightweight turn-level critic for improved stability and sample efficiency over GRPO and Reinforce++, and leverages pretrained VLM action priors to reduce manual design. The framework is reported to deliver substantial gains across game levels, at least 3x average game progress relative to frontier models, plus in-game and cross-game generalization while preserving general-domain capabilities.
Significance. If the empirical claims hold under controlled conditions, the work would advance scaling of VLMs to embodied, long-horizon tasks by supplying an open framework, concrete guidance on stable multi-modal RL, and evidence that VLM priors aid efficiency. The open-source release and retention of general capabilities are explicit strengths that support reproducibility and broader applicability.
major comments (1)
- [Experimental results and ablations] The central attribution of the reported 3x game-progress gains, stability, and generalization to the adapted PPO (with turn-level critic) plus VLM priors requires explicit controlled ablations. Comparisons to GRPO, Reinforce++, and prompted frontier VLMs must hold the VLM backbone, action space, observation encoding, and reward formulation fixed; without such controls (detailed in the experimental section), it remains unclear whether the gains arise from the proposed algorithmic ingredients or from unablated implementation or evaluation choices.
minor comments (2)
- [Abstract] The abstract states 'substantial gains' and 'at least 3 times average game progresses' without any numerical values, baseline scores, or statistical details; including key quantitative results would make the summary self-contained.
- [Results] Clarify the precise definition and measurement of 'average game progresses' (e.g., levels completed, distance traveled, or normalized score) and how it is aggregated across levels and episodes.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [Experimental results and ablations] The central attribution of the reported 3x game-progress gains, stability, and generalization to the adapted PPO (with turn-level critic) plus VLM priors requires explicit controlled ablations. Comparisons to GRPO, Reinforce++, and prompted frontier VLMs must hold the VLM backbone, action space, observation encoding, and reward formulation fixed; without such controls (detailed in the experimental section), it remains unclear whether the gains arise from the proposed algorithmic ingredients or from unablated implementation or evaluation choices.
Authors: We agree that rigorous controls are necessary to attribute performance differences to specific algorithmic choices. The manuscript reports a systematic investigation of RL components with comparisons to GRPO and Reinforce++ as well as prompted frontier VLMs. To address the concern directly, we will revise the experimental section to include explicit ablation studies that hold the VLM backbone, action space, observation encoding, and reward formulation fixed for the RL-based methods (adapted PPO, GRPO, and Reinforce++). We will also add a detailed description of all implementation and evaluation choices. For prompted frontier VLMs, which use different closed-source backbones by definition, we will clarify that these serve as off-the-shelf baselines without RL training rather than controlled variants. These changes will make the source of the reported gains, stability improvements, and generalization clearer. revision: yes
Circularity Check
No significant circularity; empirical RL results grounded in external game interactions
full rationale
The paper describes an empirical training framework for VLM agents in Super Mario Land using an adapted PPO variant with a turn-level critic, pretrained VLM action priors, and comparisons to baselines such as GRPO, Reinforce++, and frontier models. Performance claims (e.g., 3x game progress, generalization) are evaluated via direct interaction with the external game environment rather than any internal derivation, fitted parameter renamed as prediction, or self-referential definition. No mathematical equations, uniqueness theorems, or ansatzes are presented that reduce to the paper's own inputs by construction. No load-bearing self-citations or renamings of known results appear in the abstract or described content. This is a standard empirical RL study whose central claims rest on observable training outcomes and external benchmarks, warranting a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
work page internal anchor Pith review arXiv
-
[3]
Soft Actor-Critic Algorithms and Applications
Soft actor-critic algorithms and applications , author=. arXiv preprint arXiv:1812.05905 , year=
work page internal anchor Pith review arXiv
-
[4]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[5]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review arXiv
-
[6]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
10 Auke Jan Ijspeert, Jun Nakanishi, Heiko Hoffmann, Peter Pastor, and Stefan Schaal
lmgame-Bench: How Good are LLMs at Playing Games? , author=. arXiv preprint arXiv:2505.15146 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Minedojo: Building open-ended embodied agents with internet-scale knowledge , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
2021 , url =
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre C\^ot\'e and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle =. 2021 , url =
2021
-
[12]
2020 , url =
Mohit Shridhar and Jesse Thomason and Daniel Gordon and Yonatan Bisk and Winson Han and Roozbeh Mottaghi and Luke Zettlemoyer and Dieter Fox , booktitle =. 2020 , url =
2020
-
[13]
Conference on robot learning , pages=
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning , author=. Conference on robot learning , pages=. 2020 , organization=
2020
-
[14]
Advances in Neural Information Processing Systems , volume=
Video pretraining (vpt): Learning to act by watching unlabeled online videos , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
A generalist agent , author=. arXiv preprint arXiv:2205.06175 , year=
work page internal anchor Pith review arXiv
-
[16]
Advances in neural information processing systems , volume=
Multi-game decision transformers , author=. Advances in neural information processing systems , volume=
-
[17]
Advances in neural information processing systems , volume=
Decision transformer: Reinforcement learning via sequence modeling , author=. Advances in neural information processing systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Offline reinforcement learning as one big sequence modeling problem , author=. Advances in neural information processing systems , volume=
-
[19]
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence , author=. arXiv preprint arXiv:2603.24621 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review arXiv 1912
-
[21]
arXiv preprint arXiv:1804.03720 , year=
Gotta Learn Fast: A New Benchmark for Generalization in RL , author=. arXiv preprint arXiv:1804.03720 , year=
-
[22]
arXiv preprint arXiv:1703.04908 , year=
Emergence of Grounded Compositional Language in Multi-Agent Populations , author=. arXiv preprint arXiv:1703.04908 , year=
-
[23]
International conference on machine learning , pages=
Benchmarking deep reinforcement learning for continuous control , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[24]
Journal of artificial intelligence research , volume=
The arcade learning environment: An evaluation platform for general agents , author=. Journal of artificial intelligence research , volume=
-
[25]
FightLadder : A benchmark for competitive multi-agent reinforcement learning
FightLadder: A benchmark for competitive multi-agent reinforcement learning , author=. arXiv preprint arXiv:2406.02081 , year=
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv e-prints , pages=
Reinforce++: A simple and efficient approach for aligning large language models , author=. arXiv e-prints , pages=
-
[28]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[31]
Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games
Orak: A foundational benchmark for training and evaluating llm agents on diverse video games , author=. arXiv preprint arXiv:2506.03610 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Videogamebench: Can vision-language models complete popular video games? , author=. arXiv preprint arXiv:2505.18134 , year=
-
[33]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Claude-3 Model Card , volume=
The claude 3 model family: Opus, sonnet, haiku , author=. Claude-3 Model Card , volume=
-
[35]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[37]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review arXiv
-
[38]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Gui agents: A survey , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[41]
Scaling instructable agents across many simulated worlds
Scaling instructable agents across many simulated worlds , author=. arXiv preprint arXiv:2404.10179 , year=
-
[42]
Sawyer, Daniel Slater, David Reichert, Davide Vercelli, Demis Hassabis, Drew A
Sima 2: A generalist embodied agent for virtual worlds , author=. arXiv preprint arXiv:2512.04797 , year=
-
[43]
PaLM-E: An Embodied Multimodal Language Model
Palm-e: An embodied multimodal language model , author=. arXiv preprint arXiv:2303.03378 , year=
work page internal anchor Pith review arXiv
-
[44]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[45]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
pi_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
work page internal anchor Pith review arXiv
-
[46]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Mle-bench: Evaluating machine learning agents on machine learning engineering , author=. arXiv preprint arXiv:2410.07095 , year=
-
[47]
NeurIPS Competition Track , year =
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale , author=. NeurIPS Competition Track , year =
-
[48]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[49]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Webvoyager: Building an end-to-end web agent with large multimodal models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Do As I Can and Not As I Say: Grounding Language in Robotic Affordances , author=. arXiv preprint arXiv:2204.01691 , year=
work page internal anchor Pith review arXiv
-
[51]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Voxposer: Composable 3d value maps for robotic manipulation with language models , author=. arXiv preprint arXiv:2307.05973 , year=
work page internal anchor Pith review arXiv
-
[52]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review arXiv
-
[53]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[54]
Gemini Robotics: Bringing AI into the Physical World
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
work page internal anchor Pith review arXiv
-
[55]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Rdt-1b: a diffusion foundation model for bimanual manipulation , author=. arXiv preprint arXiv:2410.07864 , year=
work page internal anchor Pith review arXiv
-
[56]
Game-tars: Pretrained foundation models for scalable generalist multimodal game agents , author=. arXiv preprint arXiv:2510.23691 , year=
-
[57]
2025 , month = aug, url =
Zhang, Joel , title =. 2025 , month = aug, url =
2025
-
[58]
Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds , author=. arXiv preprint arXiv:2511.08892 , year=
-
[59]
NitroGen: An open foundation model for generalist gaming agents, 2026
NitroGen: An Open Foundation Model for Generalist Gaming Agents , author=. arXiv preprint arXiv:2601.02427 , year=
-
[60]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[61]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[62]
nature , volume=
Grandmaster level in StarCraft II using multi-agent reinforcement learning , author=. nature , volume=. 2019 , publisher=
2019
-
[63]
International conference on machine learning , pages=
Agent57: Outperforming the atari human benchmark , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[64]
Advances in Neural Information Processing Systems , volume=
Embodiedgpt: Vision-language pre-training via embodied chain of thought , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
From multimodal llms to generalist embodied agents: Methods and lessons , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[66]
arXiv preprint arXiv:2505.22050 , year=
Reinforced reasoning for embodied planning , author=. arXiv preprint arXiv:2505.22050 , year=
-
[67]
Towards general computer control: A multimodal agent for red dead redemption ii as a case study
Cradle: Empowering foundation agents towards general computer control , author=. arXiv preprint arXiv:2403.03186 , year=
-
[68]
Advances in neural information processing systems , volume=
Fine-tuning large vision-language models as decision-making agents via reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[69]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
work page internal anchor Pith review arXiv 2010
-
[70]
arXiv preprint arXiv:2505.03792 , year=
Towards efficient online tuning of vlm agents via counterfactual soft reinforcement learning , author=. arXiv preprint arXiv:2505.03792 , year=
-
[71]
arXiv preprint arXiv:2301.03044 , year=
A survey on transformers in reinforcement learning , author=. arXiv preprint arXiv:2301.03044 , year=
-
[72]
arXiv preprint arXiv:2510.12693 , year=
Era: Transforming vlms into embodied agents via embodied prior learning and online reinforcement learning , author=. arXiv preprint arXiv:2510.12693 , year=
-
[73]
2025 , howpublished=
Claude Code , author=. 2025 , howpublished=
2025
-
[74]
G1: Bootstrapping perception and reasoning abilities of vision-language model via reinforcement learning , author=. arXiv preprint arXiv:2505.13426 , year=
-
[75]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[76]
Secrets of rlhf in large language models part i: Ppo.arXiv preprint arXiv:2307.04964, 2023
Secrets of rlhf in large language models part i: Ppo , author=. arXiv preprint arXiv:2307.04964 , year=
-
[77]
A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
A minimalist approach to llm reasoning: from rejection sampling to reinforce , author=. arXiv preprint arXiv:2504.11343 , year=
-
[78]
arXiv preprint arXiv:2505.18830 , year=
On the effect of negative gradient in group relative deep reinforcement optimization , author=. arXiv preprint arXiv:2505.18830 , year=
-
[79]
2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP) , pages=
PPO-CMA: Proximal policy optimization with covariance matrix adaptation , author=. 2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP) , pages=. 2020 , organization=
2020
-
[80]
arXiv preprint arXiv:2306.01460 , year=
Relu to the rescue: Improve your on-policy actor-critic with positive advantages , author=. arXiv preprint arXiv:2306.01460 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.