Recognition: unknown
Thinking in Text and Images: Interleaved Vision--Language Reasoning Traces for Long-Horizon Robot Manipulation
Pith reviewed 2026-05-09 19:47 UTC · model grok-4.3
The pith
A single multimodal transformer generates a full-horizon trace of alternating text subgoals and visual keyframes to guide closed-loop robot actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a single native multimodal transformer self-generates an explicit intermediate representation called the interleaved vision-language reasoning trace from the initial observation and instruction. This trace alternates textual subgoals with visual keyframes across the entire task horizon. The cached trace then conditions a closed-loop action decoder together with the original instruction and the current observation, producing coherent and geometrically grounded actions over long sequences.
What carries the argument
The interleaved vision-language reasoning trace: an explicit representation that alternates textual subgoals with visual keyframes over the full task horizon to supply both causal order and spatial constraints.
If this is right
- The full interleaved trace raises LIBERO-Long success from 37.7 percent without traces to 92.4 percent.
- Text-only traces reach 62.0 percent and vision-only traces reach 68.4 percent on the same benchmark, confirming both modalities are required.
- The trace tolerates masked content and moderate execution drift but degrades when the global plan becomes stale or incorrect.
Where Pith is reading between the lines
- The cached global trace implies that continuous replanning at every step is unnecessary once an initial semantic-geometric plan is formed.
- The method's gains under visual distribution shift suggest the explicit trace helps separate planning from low-level perception.
- The pseudo-supervision pipeline indicates that existing demonstration datasets can be retrofitted for interleaved training without new manual annotation.
Load-bearing premise
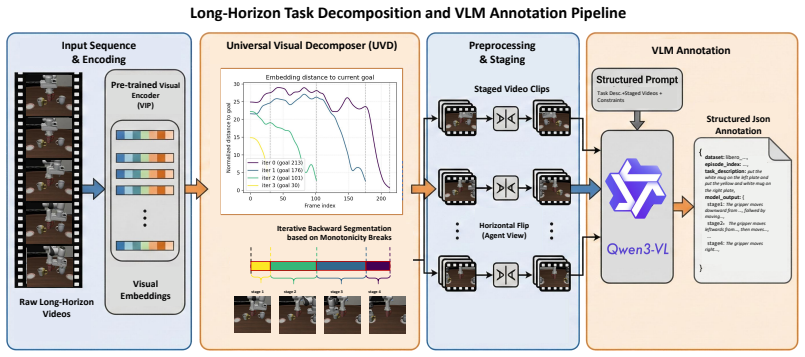
Segmenting robot demonstrations into stages and captioning each stage with a vision-language model automatically yields consistent, high-quality interleaved traces that are sufficient to train effective planning.
What would settle it
If success rates on the long-horizon benchmarks drop to the no-trace level when the model is given traces generated by a weaker captioning process that introduces inconsistent subgoals or mismatched keyframes, the claim that the trace supplies useful global guidance would be falsified.
Figures




read the original abstract
Long-horizon robotic manipulation requires plans that are both logically coherent and geometrically grounded. Existing Vision-Language-Action policies usually hide planning in latent states or expose only one modality: text-only chain-of-thought encodes causal order but misses spatial constraints, while visual prediction provides geometric cues but often remains local and semantically underconstrained. We introduce Interleaved Vision--Language Reasoning (IVLR), a policy framework built around \trace{}, an explicit intermediate representation that alternates textual subgoals with visual keyframes over the full task horizon. At test time, a single native multimodal transformer self-generates this global semantic-geometric trace from the initial observation and instruction, caches it, and conditions a closed-loop action decoder on the trace, original instruction, and current observation. Because standard robot datasets lack such traces, we construct pseudo-supervision by temporally segmenting demonstrations and captioning each stage with a vision-language model. Across simulated benchmarks for long-horizon manipulation and visual distribution shift, \method{} reaches 95.5\% average success on LIBERO, including 92.4\% on LIBERO-Long, and 59.4\% overall success on SimplerEnv-WidowX. Ablations show that both modalities are necessary: without traces, LIBERO-Long success drops to 37.7\%; text-only and vision-only traces reach 62.0\% and 68.4\%, while the full interleaved trace reaches 92.4\%. Stress tests with execution perturbations and masked trace content show moderate degradation, suggesting that the trace can tolerate local corruption and moderate execution drift, but remains limited under stale or incorrect global plans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Interleaved Vision-Language Reasoning (IVLR) traces as an explicit intermediate representation that alternates textual subgoals with visual keyframes over the full task horizon for long-horizon robot manipulation. A single native multimodal transformer self-generates this global semantic-geometric trace from the initial observation and instruction, caches it, and conditions a closed-loop action decoder on the trace, original instruction, and current observation. Pseudo-supervision is constructed by temporally segmenting demonstrations and captioning each stage with an off-the-shelf vision-language model. The approach reports 95.5% average success on LIBERO (including 92.4% on LIBERO-Long) and 59.4% on SimplerEnv-WidowX, with ablations showing drops to 37.7% without traces, 62.0% for text-only, and 68.4% for vision-only on LIBERO-Long, plus stress tests on perturbations and masked content.
Significance. If the generated traces prove to be both semantically coherent and geometrically accurate, the framework could meaningfully advance explicit multimodal planning in vision-language-action policies by separating global reasoning from closed-loop control. The ablations confirming necessity of both modalities and the stress tests demonstrating tolerance to local corruption are positive elements that strengthen the empirical case; the single-transformer architecture for trace generation is also a clean design choice.
major comments (2)
- [Abstract] Abstract: the central performance claims (92.4% on LIBERO-Long, 95.5% average on LIBERO) rest on the assumption that VLM-generated captions of temporally segmented demonstrations produce traces with sufficient geometric precision and cross-stage consistency, yet no human evaluation, geometric error metrics, or fidelity analysis against ground-truth plans is reported; this directly affects whether the gains reflect genuine interleaved reasoning or simply better feature extraction.
- [Abstract] Abstract and results sections: success rates are presented without error bars, standard deviations, or the number of evaluation seeds/runs, and no details on the training procedure, optimizer, or hyper-parameters for the multimodal transformer are supplied, which weakens confidence in the reliability of the reported ablation deltas.
minor comments (2)
- [Abstract] The notation for the trace representation (denoted as trace) and method name should be introduced with an explicit definition or equation on first appearance rather than relying on the abstract alone.
- Consider including a qualitative figure or table showing an example full interleaved trace (text + keyframes) alongside the corresponding robot trajectory to illustrate the representation's structure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and address each major comment below. We commit to revisions that improve the manuscript's rigor without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (92.4% on LIBERO-Long, 95.5% average on LIBERO) rest on the assumption that VLM-generated captions of temporally segmented demonstrations produce traces with sufficient geometric precision and cross-stage consistency, yet no human evaluation, geometric error metrics, or fidelity analysis against ground-truth plans is reported; this directly affects whether the gains reflect genuine interleaved reasoning or simply better feature extraction.
Authors: We agree that direct fidelity analysis would strengthen the interpretation. Ground-truth plans are unavailable in the LIBERO and SimplerEnv datasets, precluding quantitative geometric error metrics against oracle plans. However, the ablations (drops to 37.7% without traces, 62.0% text-only, 68.4% vision-only) and stress tests already indicate that the interleaved structure contributes beyond generic feature extraction. In revision we will add: qualitative trace visualizations, VLM-based cross-stage consistency checks on generated keyframes, and a human coherence rating study on a 50-example subset. revision: partial
-
Referee: [Abstract] Abstract and results sections: success rates are presented without error bars, standard deviations, or the number of evaluation seeds/runs, and no details on the training procedure, optimizer, or hyper-parameters for the multimodal transformer are supplied, which weakens confidence in the reliability of the reported ablation deltas.
Authors: We acknowledge the omission of statistical details and training specifications. In the revised manuscript we will report standard deviations and error bars computed over 5 evaluation seeds, explicitly state the number of runs, and provide complete training details including the optimizer (AdamW), learning rate, batch size, number of epochs, and key hyperparameters for both the multimodal trace generator and the action decoder. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical architecture and training procedure for generating interleaved vision-language traces via a multimodal transformer. Pseudo-supervision is created externally by segmenting demonstrations and applying VLM captioning; this is a data-generation step, not a fitted parameter or self-referential definition. No equations appear in the provided text, and no results are shown to reduce to inputs by construction. Performance is reported on external benchmarks (LIBERO, SimplerEnv) with ablations that isolate modality contributions. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- ad hoc to paper Temporally segmented demonstrations captioned by an off-the-shelf VLM yield training targets that are sufficiently accurate and consistent for learning effective traces
- domain assumption A native multimodal transformer can self-generate a globally consistent semantic-geometric trace from a single initial observation and instruction
invented entities (1)
-
Interleaved Vision-Language Reasoning trace
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Y evgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Y evgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Y u, Hangjie Y uan, Y uming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Jiayi Chen, Wenxuan Song, Pengxiang Ding, Ziyang Zhou, Han Zhao, Feilong Tang, Donglin Wang, and Haoang Li. Unified diffusion vla: Vision-language-action model via joint discrete denoising diffusion process. arXiv preprint arXiv:2511.01718, 2025
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research , 44(10–11):1684–1704, 2025
2025
-
[8]
Vla-0: Building state-of-the-art vlas with zero modification.arXiv preprint arXiv:2510.13054, 2025
Ankit Goyal, Hugo Hadfield, Xuning Y ang, V alts Blukis, and Fabio Ramos. Vla-0: Building state-of-the-art vlas with zero modification. arXiv preprint arXiv:2510.13054, 2025
-
[9]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Y ucheng Hu, Y anjiang Guo, Pengchao Wang, Xiaoyu Chen, Y en-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
Grounded decoding: Guiding text genera- tion with grounded models for embodied agents
Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Y ao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, et al. Grounded decoding: Guiding text genera- tion with grounded models for embodied agents. Advances in Neural Information Processing Systems, 36:59636–59661, 2023
2023
-
[11]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Y uquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space. arXiv preprint arXiv:2508.07917, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Onetwovla: A unified vision-language-action model with adaptive reasoning
Fanqi Lin, Ruiqian Nai, Yingdong Hu, Jiacheng Y ou, Junming Zhao, and Y ang Gao. Onet- wovla: A unified vision-language-action model with adaptive reasoning. arXiv preprint arXiv:2505.11917, 2025
-
[16]
Libero: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Y uke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36:44776–44791, 2023. 10
2023
-
[17]
Towards generalist robot policies: What matters in building vision-language-action models
Huaping Liu, Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, and Hanbo Zhang. Towards generalist robot policies: What matters in building vision-language-action models. Manuscript, 2025
2025
-
[18]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language- action models. arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Delin Qu, Haoming Song, Qizhi Chen, Zhaoqing Chen, Xianqiang Gao, Xinyi Y e, Qi Lv, Modi Shi, Guanghui Ren, Cheng Ruan, et al. Eo-1: Interleaved vision-text-action pretraining for general robot control. arXiv preprint arXiv:2508.21112, 2025
-
[21]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Y uanqi Y ao, Xinyi Y e, Y an Ding, Zhigang Wang, Ji- aY uan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for vision-language-action model. arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review arXiv 2025
- [22]
-
[23]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Y u, Haiming Zhao, Jianxiao Y ang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
Y uqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Y untao Chen, Xin- long Wang, and Zhaoxiang Zhang. Unified vision-language-action model. arXiv preprint arXiv:2506.19850, 2025
-
[25]
Junjie Wen, Minjie Zhu, Jiaming Liu, Zhiyuan Liu, Yicun Y ang, Linfeng Zhang, Shanghang Zhang, Yichen Zhu, and Yi Xu. dvla: Diffusion vision-language-action model with multimodal chain-of-thought. arXiv preprint arXiv:2509.25681, 2025
-
[26]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Y uchao Gu, Zhijie Chen, Zhenheng Y ang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. In International Conference on Learning Representations, 2025
2025
-
[27]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Y ang, and Mike Zheng Shou. Show-o2: Improved native unified mul- timodal models. arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Robotic control via embodied chain-of-thought reasoning,
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning. arXiv preprint arXiv:2407.08693 , 2024
-
[30]
Universal visual decomposer: Long-horizon manipulation made easy
Zichen Zhang, Y unshuang Li, Osbert Bastani, Abhishek Gupta, Dinesh Jayaraman, Y echeng Ja- son Ma, and Luca Weihs. Universal visual decomposer: Long-horizon manipulation made easy. In IEEE International Conference on Robotics and Automation, pages 6973–6980. IEEE, 2024
2024
-
[31]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Y ao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Y echeng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1702–1713, 2025
2025
-
[32]
Transfusion: Predict the next to- ken and diffuse images with one multi-modal model
Chunting Zhou, Lili Y u, Arun Babu, Kushal Tirumala, Michihiro Y asunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next to- ken and diffuse images with one multi-modal model. In International Conference on Learning Representations, 2025. 11
2025
-
[33]
stage_id
Brianna Zitkovich, Tianhe Y u, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models trans- fer web knowledge to robotic control. In Conference on Robot Learning , pages 2165–2183. PMLR, 2023. A Pseudo-trace annotation details The pseudo-trace pipeline takes a demonstration...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.