Recognition: unknown
RECAP: An End-to-End Platform for Capturing, Replaying, and Analyzing AI-Assisted Programming Interactions
Pith reviewed 2026-05-09 18:35 UTC · model grok-4.3
The pith
RECAP merges AI chat logs with fine-grained code edits into one replayable timeline to support analyses impossible from isolated data sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RECAP is an open-source platform that passively records AI chat sessions and fine-grained code edits inside VS Code without disrupting workflow, merges the streams into a unified timeline for interactive replay, and supplies an extensible analysis layer that includes modules for behavioral classification and AI reliance measurement.
What carries the argument
The unified timeline that links each AI prompt directly to the code edits it triggered and to the developer's subsequent accept, reject, or revise actions.
If this is right
- Analyses can classify developer behaviors using the full prompt-to-edit context rather than incomplete chat or git records alone.
- AI reliance can be quantified by tracking acceptance rates, modification frequency, and strategy evolution across an entire multi-week project.
- Researchers gain the ability to replay sessions interactively to inspect what developers tried and discarded at each step.
- New analysis modules can be added to the extensible layer without altering the underlying capture or replay mechanisms.
Where Pith is reading between the lines
- The same linked timeline could let tool designers identify common points where developers abandon AI suggestions and test interface changes to reduce those drop-offs.
- Longitudinal deployment across semesters or teams would make it possible to measure whether prompting skill improves with repeated use of the same AI assistant.
- Extending the platform to additional editors would allow direct comparison of interaction patterns between different development environments.
Load-bearing premise
Passive recording captures developer behavior exactly as it would occur without the tool present, and the linked data contains enough context for analysis modules to extract undistorted patterns.
What would settle it
A side-by-side comparison in which the same developers are observed by a human researcher while RECAP runs, checking whether recorded prompts, edits, and sequences match the observed actions and stated intentions.
Figures



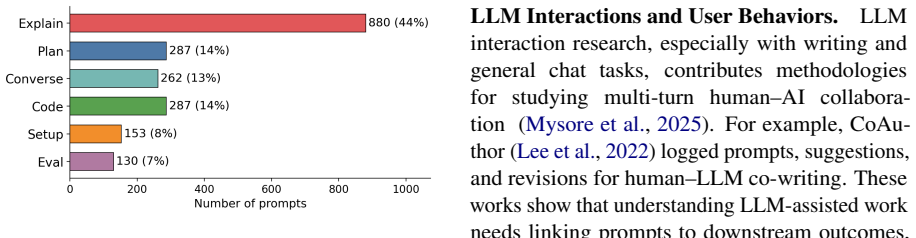
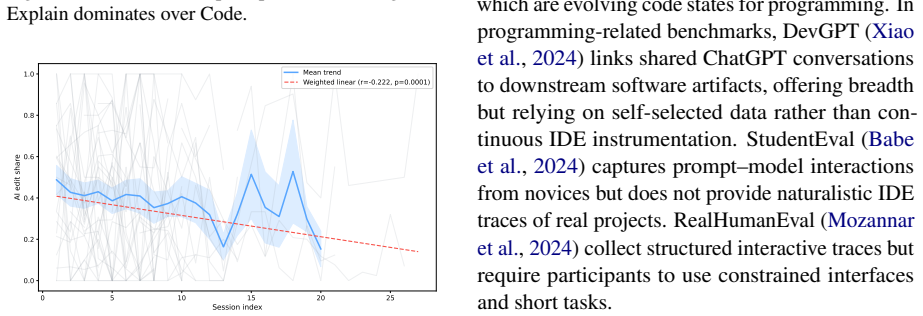


read the original abstract
Understanding how developers interact with AI coding assistants requires more than chat logs or git histories in isolation; it requires reconstructing the full context: which prompt led to which edit, what the developer tried and discarded, and how their strategy evolved over time. We present RECAP (Replay and Examine Captured AI Programming), an open-source platform that (1) passively records AI chat sessions and fine-grained code edits inside VS Code without disrupting the developer's workflow, (2) merges them into a unified timeline for interactive session replay, and (3) exposes an extensible analysis layer, with example modules for behavioral classification and AI reliance measurement. Deployed in a university software engineering course, RECAP captured 2,034 prompts and 8,239 code edits from 41 students across a multi-week project. We demonstrate how the platform's linked data and replay capabilities enable analyses of developer-AI interaction patterns that no single data source could support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RECAP, an open-source platform that passively captures AI chat sessions and fine-grained code edits inside VS Code, merges them into a unified timeline for interactive replay, and exposes an extensible analysis layer with example modules for behavioral classification and AI reliance measurement. Deployed in a university software engineering course, it captured 2,034 prompts and 8,239 code edits from 41 students; the central claim is that the linked data and replay capabilities enable analyses of developer-AI interaction patterns unattainable from any single data source in isolation.
Significance. A validated platform with demonstrated linkage between prompts and edits could meaningfully advance empirical work on AI-assisted programming by supporting timeline-based analyses that integrate chat context with code changes, discards, and strategy shifts. The open-source release and real deployment data are practical strengths that could facilitate replication and extension by other researchers.
major comments (2)
- [Abstract and analysis layer] Abstract and § on analysis modules: the claim that the platform enables analyses 'that no single data source could support' is not supported by any concrete worked example. The manuscript describes example modules for behavioral classification and AI reliance but supplies no specific result, pattern detected, or comparison against timestamp-aligned separate chat logs and edit histories showing that the explicit prompt-edit linkage (including discards and strategy shifts) is required to identify the pattern.
- [Deployment and evaluation] Deployment section: the reported figures (2,034 prompts, 8,239 edits from 41 students) are presented without any validation that the passive capture is complete, that no events were lost, or that the recording process does not alter developer behavior; this directly affects the soundness of the claimed new analyses.
minor comments (2)
- [Platform architecture] The description of the merging process into a unified timeline would benefit from additional technical detail on how timestamps and session boundaries are aligned across chat and edit streams.
- [Analysis layer] Clarify the exact scope and output format of the 'extensible analysis layer' so readers can assess how new modules would integrate with the replay timeline.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and analysis layer] Abstract and § on analysis modules: the claim that the platform enables analyses 'that no single data source could support' is not supported by any concrete worked example. The manuscript describes example modules for behavioral classification and AI reliance but supplies no specific result, pattern detected, or comparison against timestamp-aligned separate chat logs and edit histories showing that the explicit prompt-edit linkage (including discards and strategy shifts) is required to identify the pattern.
Authors: We agree that the manuscript would benefit from a concrete worked example to substantiate the claim. While the analysis layer is described with modules for behavioral classification and AI reliance measurement, and the abstract states that linked data enables new analyses, no specific pattern or comparison demonstrating the necessity of the unified timeline (e.g., detecting a discard followed by a strategy shift) is provided from the deployment data. In the revised manuscript, we will add a worked example in the analysis section, using anonymized data from the student sessions to illustrate a pattern identifiable only through explicit prompt-edit linkage and replay, with a direct comparison to what separate timestamp-aligned sources would miss. revision: yes
-
Referee: [Deployment and evaluation] Deployment section: the reported figures (2,034 prompts, 8,239 edits from 41 students) are presented without any validation that the passive capture is complete, that no events were lost, or that the recording process does not alter developer behavior; this directly affects the soundness of the claimed new analyses.
Authors: The referee is correct that the deployment section reports the event counts without explicit validation of completeness, data loss, or behavioral impact. The capture mechanism relies on passive VS Code extension hooks, which are intended to be non-intrusive, but we performed no controlled measurements or cross-checks (beyond basic logging) to confirm zero loss or no alteration. We will revise the deployment and evaluation sections to add a dedicated limitations paragraph discussing these issues, including potential failure modes (e.g., extension crashes or network drops for chat) and any indirect consistency checks feasible from the existing data. Full empirical validation would require new experiments outside the scope of the current deployment; we will frame this as a limitation and suggest it for future work rather than asserting soundness without evidence. revision: partial
Circularity Check
No circularity: direct system description without derivations or self-referential claims
full rationale
The paper is an engineering systems description of the RECAP platform. It contains no equations, fitted parameters, predictions, uniqueness theorems, or ansatzes. The central claim—that linked chat/edit data enables analyses impossible from isolated sources—is presented as a direct consequence of the platform's design and deployment (2,034 prompts, 8,239 edits), not derived from any prior result or self-citation chain. No load-bearing step reduces to its own inputs by construction. This is the expected non-finding for a non-theoretical implementation paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hannah McLean Babe, Sydney Nguyen, Yangtian Zi, Arjun Guha, Molly Q Feldman, and Carolyn Jane Anderson. 2024. Studenteval: A benchmark of student-written prompts for large language models of code. In Findings of the Association for Computational Linguistics: ACL 2024, pages 8452--8474
2024
-
[2]
Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages, 7(OOPSLA1):85--111
2023
-
[3]
Manaal Basha, Aimeê M Ribeiro, Jeena Javahar, Cleidson R B de Souza, and Gema Rodríguez-Pérez. 2025. https://doi.org/10.48550/arXiv.2510.11536 CodeWatcher : IDE telemetry data extraction tool for understanding coding interactions with LLMs . arXiv [cs.SE]
-
[4]
Joachim Baumann, Vishakh Padmakumar, Xiang Li, John Yang, Diyi Yang, and Sanmi Koyejo. 2026. https://doi.org/10.48550/arXiv.2604.20779 SWE -chat: Coding agent interactions from real users in the wild . arXiv [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.20779 2026
-
[5]
Christian Bird, Denae Ford, Thomas Zimmermann, Nicole Forsgren, Eirini Kalliamvakou, Travis Lowdermilk, and Idan Gazit. 2023. https://doi.org/10.1145/3582083 Taking flight with copilot: Early insights and opportunities of AI -powered pair-programming tools . Queueing Syst., 20(6):35--57
-
[6]
Neil Christopher Charles Brown, Michael Kölling, Davin McCall, and Ian Utting. 2014. https://doi.org/10.1145/2538862.2538924 Blackbox: a large scale repository of novice programmers' activity . In Proceedings of the 45th ACM technical symposium on Computer science education, New York, NY, USA. ACM
- [7]
-
[8]
Wayne Chi, Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, Chris Donahue, and Ameet Talwalkar. 2025. https://arxiv.org/abs/2502.09328 Copilot arena: A platform for code llm evaluation in the wild . Preprint, arXiv:2502.09328
-
[9]
Cursor . 2026. https://github.com/cursor/agent-trace agent-trace: A standard format for tracing AI -generated code
2026
-
[10]
Thomas Dohmke. 2023. GitHub copilot X : The AI -powered developer experience. https://github.blog/2023-03-22-github-copilot-x-the-ai-powered-developer-experience/. Accessed: 2023-9-5
2023
-
[11]
Hao He, Courtney Miller, Shyam Agarwal, Christian Kästner, and Bogdan Vasilescu. 2026. https://doi.org/10.48550/arXiv.2511.04427 Speed at the cost of quality: How cursor AI increases short-term velocity and long-term complexity in open-source projects . arXiv [cs.SE]
- [12]
-
[13]
Majeed Kazemitabaar, Runlong Ye, Xiaoning Wang, Austin Zachary Henley, Paul Denny, Michelle Craig, and Tovi Grossman. 2024. Codeaid: Evaluating a classroom deployment of an llm-based programming assistant that balances student and educator needs. In Proceedings of the 2024 chi conference on human factors in computing systems, pages 1--20
2024
-
[14]
Mina Lee, Percy Liang, and Qian Yang. 2022. https://doi.org/10.1145/3491102.3502030 CoAuthor : Designing a human- AI collaborative writing dataset for exploring language model capabilities . In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, number Article 388 in CHI '22, pages 1--19, New York, NY, USA. Association for Comput...
-
[15]
Qianou Ma, Kenneth R Koedinger, and Tongshuang Wu. 2026. https://doi.org/10.1145/3772318.3791283 Not everyone wins with LLM s: Behavioral patterns and pedagogical implications for AI literacy in programmatic data science . In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI '26, pages 1--22, New York, NY, USA. Association ...
-
[16]
Qianou Ma, Tongshuang Wu, and Kenneth Koedinger. 2023. https://doi.org/10.48550/arXiv.2306.05153 Is AI the better programming partner? human-human pair programming vs. human- AI pAIr programming . arXiv [cs.HC], pages 64--77
-
[17]
L Maaten and Geoffrey E Hinton. 2008. https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf Visualizing data using t- SNE . Journal of Machine Learning Research, 9(86):2579--2605
2008
-
[18]
Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. 2022. https://doi.org/10.48550/ARXIV.2210.14306 Reading between the lines: Modeling user behavior and costs in AI -assisted programming . ArXiv
-
[19]
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, and David Sontag. 2024. https://doi.org/10.48550/arXiv.2404.02806 The RealHumanEval : Evaluating large language models' abilities to support programmers . ArXiv, abs/2404.02806
-
[20]
Sheshera Mysore, Debarati Das, Hancheng Cao, and Bahareh Sarrafzadeh. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.852 Prototypical human- AI collaboration behaviors from LLM -assisted writing in the wild . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16830--16857, Stroudsburg, PA, USA. Association ...
-
[21]
Hyunchan Park, Youngpil Kim, Kyungwoon Lee, Soonheon Jin, Jinseok Kim, Yan Heo, Gyuho Kim, and Eunhye Kim. 2025. https://doi.org/10.3390/app151910403 CodeDive : A web-based IDE with real-time code activity monitoring for programming education . Appl. Sci. (Basel), 15(19):10403
-
[22]
Vo Thien Tri Pham and Caitlin Kelleher. 2025. https://doi.org/10.1016/j.cola.2024.101313 Code histories: Documenting development by recording code influences and changes in code . J. Comput. Lang., 82(101313):101313
-
[23]
Thomas W Price, David Hovemeyer, Kelly Rivers, Ge Gao, Austin Cory Bart, Ayaan M Kazerouni, Brett A Becker, Andrew Petersen, Luke Gusukuma, Stephen H Edwards, and David Babcock. 2020. https://doi.org/10.1145/3341525.3387373 ProgSnap2 : A flexible format for programming process data . In Proceedings of the 2020 ACM Conference on Innovation and Technology i...
-
[24]
Nils Reimers and Iryna Gurevych. 2019. http://arxiv.org/abs/1908.10084 Sentence-bert: Sentence embeddings using siamese bert-networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
work page internal anchor Pith review arXiv 2019
-
[25]
Agnia Sergeyuk, Eric Huang, Dariia Karaeva, Anastasiia Serova, Yaroslav Golubev, and Iftekhar Ahmed. 2026. https://doi.org/10.48550/arXiv.2601.10258 Evolving with AI : A longitudinal analysis of developer logs . arXiv [cs.SE]
-
[26]
Alex Tamkin, Miles McCain, Kunal Handa, Esin Durmus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, Michael Stern, Brian Clarke, Landon Goldberg, Theodore R Sumers, Jared Mueller, William McEachen, Wes Mitchell, Shan Carter, Jack Clark, and 2 others. 2024. https://arxiv.org/abs/2412.13678 Clio: Privacy-preserving ...
-
[27]
Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. 2022. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models
2022
-
[28]
Tao Xiao, Christoph Treude, Hideaki Hata, and Kenichi Matsumoto. 2024. https://doi.org/10.1145/3643991.3648400 DevGPT : Studying developer- ChatGPT conversations . In Proceedings of the 21st International Conference on Mining Software Repositories, pages 227--230, New York, NY, USA. ACM
-
[29]
Benjamin Xie, Jared Ordona Lim, Paul K D Pham, Min Li, and Amy J Ko. 2023. https://doi.org/10.1145/3568813.3600127 Developing novice programmers’ self-regulation skills with code replays . In Proceedings of the 2023 ACM Conference on International Computing Education Research V.1, pages 298--313, New York, NY, USA. ACM
-
[30]
Lisa Yan, Annie Hu, and Chris Piech. 2019. https://doi.org/10.1145/3287324.3287483 Pensieve: Feedback on coding process for novices . In Proceedings of the 50th ACM Technical Symposium on Computer Science Education, pages 253--259, New York, NY, USA. ACM
-
[31]
Ashley Ge Zhang, Yan-Ru Jhou, Yinuo Yang, Shamita Rao, Maryam Arab, Yan Chen, and Steve Oney. 2026. https://doi.org/10.48550/arXiv.2601.20085 Editrail: Understanding AI usage by visualizing student- AI interaction in code . arXiv [cs.HC]
-
[32]
Ziqian Zhong, Shashwat Saxena, and Aditi Raghunathan. 2026. https://hodoscope.dev/blog/announcement.html Hodoscope: Unsupervised behavior discovery in ai agents
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.