Recognition: unknown
VUDA: Breaking CUDA-Vulkan Isolation for Spatial Sharing of Compute and Graphics on the Same GPU
Pith reviewed 2026-05-10 15:58 UTC · model grok-4.3
The pith
VUDA breaks CUDA-Vulkan isolation by redirecting channels and grafting page tables to enable spatial sharing of compute and graphics on one GPU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
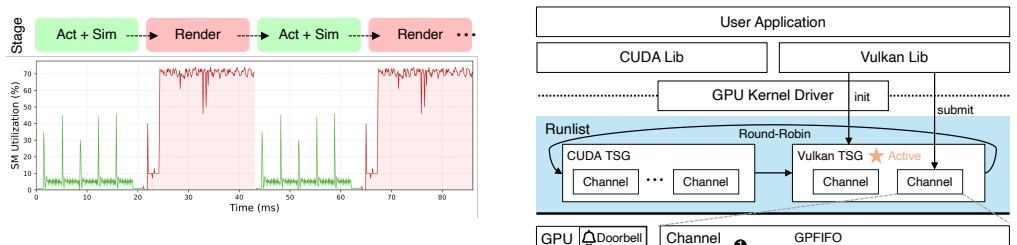
Although CUDA and Vulkan expose different programming abstractions, their execution paths converge to a common channel primitive at the driver and hardware level, and their virtual-address spaces are inherently disjoint. VUDA exploits these facts through channel redirection into Vulkan's scheduling domain and page-table grafting to unify address spaces, thereby allowing spatial parallelism between compute and graphics workloads while eliminating all data copying on the critical path.
What carries the argument
Channel redirection and page-table grafting that unify CUDA and Vulkan execution paths at the driver level.
If this is right
- Developers can annotate co-schedulable CUDA streams to run concurrently with Vulkan graphics without changing existing kernels.
- Compute and graphics workloads no longer occupy mutually exclusive time slices, raising overall GPU utilization.
- End-to-end latency drops for pipelines that alternate simulation and rendering phases.
- Throughput rises up to 85 percent relative to temporal-sharing baselines on representative embodied-AI tasks.
Where Pith is reading between the lines
- The same redirection-plus-grafting pattern could be applied to other pairs of compute and graphics APIs that share comparable low-level driver primitives.
- Unified scheduling across APIs might simplify future hardware designs that currently maintain separate scheduling domains.
- Mixed workloads on mobile or embedded GPUs could see similar utilization gains if the address-space disjointness property holds across those platforms.
Load-bearing premise
CUDA and Vulkan execution paths converge to a common channel primitive at the driver and hardware level with inherently disjoint virtual-address spaces.
What would settle it
Page-table merging that produces address conflicts or channel redirection that still forces exclusive time slices in hardware would show the spatial-sharing mechanism does not work safely without remapping.
Figures







read the original abstract
GPU-based simulation environments for embodied AI interleave physics simulation (CUDA) and photorealistic rendering (Vulkan) on a single device. We observe that two foundational scenarios -- simulation data generation and RL training -- can be naturally adapted to execute their simulation and rendering phases concurrently, presenting a significant opportunity to improve GPU utilization through spatial multiplexing. However, a fundamental obstacle we term execution isolation prevents this: CUDA and Vulkan create separate GPU contexts whose channels are bound to different scheduling groups, confining compute and graphics to mutually exclusive time slices. Existing spatial-sharing techniques are limited to the CUDA ecosystem, while temporal-sharing approaches underutilize available resources. This paper presents VUDA, a system that breaks execution isolation to enable spatial parallelism between CUDA compute and Vulkan graphics workloads. VUDA is built on two key observations: although CUDA and Vulkan expose different programming abstractions, their execution paths converge to a common channel primitive at the driver and hardware level; meanwhile, their virtual-address spaces are inherently disjoint, making safe page-table merging feasible without remapping. VUDA exposes a thin API for developers to annotate co-schedulable CUDA streams, and realizes spatial sharing through channel redirection into Vulkan's scheduling domain and page-table grafting to unify address spaces, eliminating all data copying on the critical path. Experiments on representative embodied-AI workloads show that VUDA delivers up to 85% higher throughput than temporal-sharing baselines, while improving GPU utilization and reducing end-to-end latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VUDA, a system that breaks CUDA-Vulkan execution isolation to enable spatial sharing of compute (CUDA) and graphics (Vulkan) workloads on a single GPU. It relies on two observations: execution paths converge to a common channel primitive at the driver/hardware level, and virtual-address spaces are inherently disjoint, allowing safe page-table grafting without remapping or data copies. VUDA exposes a thin annotation API for co-schedulable CUDA streams and redirects channels into Vulkan's domain. Experiments on embodied-AI workloads (simulation data generation and RL training) report up to 85% higher throughput than temporal-sharing baselines, along with improved GPU utilization and reduced end-to-end latency.
Significance. If the mechanism is correct and the performance results hold under scrutiny, VUDA would offer a practical way to improve GPU utilization in mixed compute-graphics pipelines common to embodied AI, robotics simulation, and RL training. The work identifies a concrete opportunity to leverage low-level driver convergence rather than remaining confined to single-API spatial sharing or inefficient temporal multiplexing.
major comments (2)
- [Abstract and §3] Abstract and §3 (mechanism description): The central claim that CUDA and Vulkan virtual-address spaces are 'inherently disjoint' and converge to a 'common channel primitive' is stated as an observation but receives no verification step, address-space audit, collision-handling logic, or fallback for driver/GPU/version-specific overlaps. This assumption is load-bearing for the correctness of page-table grafting; without it, the redirection could produce invalid mappings or silently fall back to serialization.
- [§5] §5 (evaluation): The headline result of 'up to 85% higher throughput' is presented without workload descriptions, hardware details, baseline implementations, number of runs, error bars, or ablation data isolating the contribution of spatial sharing. This absence makes the performance claim impossible to assess or reproduce from the manuscript.
minor comments (1)
- The term 'execution isolation' is introduced in the abstract without a concise definition or pointer to the relevant driver-level scheduling groups, which would aid readers outside the immediate GPU-systems community.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (mechanism description): The central claim that CUDA and Vulkan virtual-address spaces are 'inherently disjoint' and converge to a 'common channel primitive' is stated as an observation but receives no verification step, address-space audit, collision-handling logic, or fallback for driver/GPU/version-specific overlaps. This assumption is load-bearing for the correctness of page-table grafting; without it, the redirection could produce invalid mappings or silently fall back to serialization.
Authors: We appreciate the referee highlighting the need for explicit verification of this load-bearing assumption. The claims are grounded in our examination of driver source code, hardware specifications, and empirical testing across multiple driver versions, which showed convergence to shared channel primitives and disjoint virtual address spaces. To strengthen the manuscript, we will revise §3 to add a dedicated verification subsection. This will describe the address-space audit methodology, document any identified collision risks, and detail the implemented fallback to serialization when overlaps are detected. We believe this addition will address the correctness concerns without altering the core mechanism. revision: yes
-
Referee: [§5] §5 (evaluation): The headline result of 'up to 85% higher throughput' is presented without workload descriptions, hardware details, baseline implementations, number of runs, error bars, or ablation data isolating the contribution of spatial sharing. This absence makes the performance claim impossible to assess or reproduce from the manuscript.
Authors: We agree that the current presentation of results in §5 lacks sufficient detail for full assessment and reproducibility. In the revised manuscript we will expand the evaluation section to include complete workload descriptions for the embodied-AI simulation and RL tasks, exact hardware specifications (GPU models, driver versions), references or descriptions of the temporal-sharing baselines, the number of runs performed, error bars or confidence intervals, and ablation experiments that isolate the contributions of channel redirection and page-table grafting. These changes will make the 85% throughput improvement claim verifiable and reproducible. revision: yes
Circularity Check
No circularity: system design and empirical results stand independently of self-referential definitions or fitted inputs.
full rationale
The paper is a systems implementation work with no equations, no fitted parameters renamed as predictions, and no derivation chain that reduces to its own inputs. Key premises (convergence to a common channel primitive and inherently disjoint VA spaces) are presented as observations enabling the design, with throughput and utilization claims resting on described mechanisms plus experimental outcomes. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The contribution is self-contained as an engineering artifact evaluated against baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CUDA and Vulkan execution paths converge to a common channel primitive at the driver and hardware level
- domain assumption CUDA and Vulkan virtual-address spaces are inherently disjoint
Reference graph
Works this paper leans on
-
[1]
Introducing helix 02: Full-body autonomy, January 2026
Figure AI. Introducing helix 02: Full-body autonomy, January 2026. Accessed: 2026-05-01
2026
-
[2]
Parallel frame rendering: Trading responsiveness for energy on a mobile gpu
Jose-Maria Arnau, Joan-Manuel Parcerisa, and Polychronis Xekalakis. Parallel frame rendering: Trading responsiveness for energy on a mobile gpu. InProceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques, pages 83–92, 2013
2013
-
[3]
𝜋0: A vision-language-action flow model for general robot control, 2026
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xi- aoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. 𝜋0: A vi...
2026
-
[4]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonza- lez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Haus- man, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashn...
2023
-
[5]
Rt-1: Robotics transformer for real-world control at scale, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Haus- man, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla...
2023
-
[6]
Genie: Gener- ative interactive environments, 2024
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behba- hani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder ...
2024
-
[7]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. World- vla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong do- main randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Coppock, Brian Zhang, Eliot H
Patrick H. Coppock, Brian Zhang, Eliot H. Solomon, Vasilis Kypriotis, Leon Yang, Bikash Sharma, Dan Schatzberg, Todd C. Mowry, and Dimitrios Skarlatos. Lithos: An operating system for efficient machine learning on gpus. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 1–17, New York, NY, USA, 2025. Association...
2025
-
[10]
Kulkarni, and K
Aditya Dhakal, Sameer G. Kulkarni, and K. K. Ramakrishnan. GSLICE: controlled spatial sharing of gpus for a scalable inference platform. In Rodrigo Fonseca, Christina Delimitrou, and Beng Chin Ooi, editors, SoCC ’20: ACM Symposium on Cloud Computing, Virtual Event, USA, October 19-21, 2020, pages 492–506. ACM, 2020
2020
-
[11]
Boosting GPU virtualization performance with hybrid shadow page tables
Yaozu Dong, Mochi Xue, Xiao Zheng, Jiajun Wang, Zhengwei Qi, and Haibing Guan. Boosting GPU virtualization performance with hybrid shadow page tables. In Shan Lu and Erik Riedel, editors,Proceedings of the 2015 USENIX Annual Technical Conference, USENIX ATC 2015, July 8-10, Santa Clara, CA, USA, pages 517–528. USENIX Association, 2015
2015
-
[12]
Prefillonly: An inference engine for prefill- only workloads in large language model applications
Kuntai Du, Bowen Wang, Chen Zhang, Yiming Cheng, Qing Lan, Hejian Sang, Yihua Cheng, Jiayi Yao, Xiaoxuan Liu, Yifan Qiao, Ion Stoica, and Junchen Jiang. Prefillonly: An inference engine for prefill- only workloads in large language model applications. In Youjip Won, Youngjin Kwon, Ding Yuan, and Rebecca Isaacs, editors,Proceedings of the ACM SIGOPS 31st S...
2025
-
[13]
Bench- marking vulkan vs opengl rendering on low-power edge gpus
Oscar Ferraz, Paulo Menezes, Vítor Silva, and Gabriel Falcão. Bench- marking vulkan vs opengl rendering on low-power edge gpus. In International Conference on Graphics and Interaction, ICGI 2021, Porto, Portugal, November 4-5, 2021, pages 1–8. IEEE, 2021
2021
-
[14]
Helix: A vision-language-action model for humanoid robots
Figure AI. Helix: A vision-language-action model for humanoid robots. https://www.figure.ai/helix, 2025. Accessed: 2026-03-22
2025
-
[15]
Weaver: Efficient multi-llm serving with attention offloading
Shiwei Gao, Qing Wang, Shaoxun Zeng, Youyou Lu, and Jiwu Shu. Weaver: Efficient multi-llm serving with attention offloading. In Deniz Altinbüken and Ryan Stutsman, editors,Proceedings of the 2025 USENIX Annual Technical Conference, USENIX ATC 2025, Boston, MA, USA, July 7-9, 2025, pages 587–595. USENIX Association, 2025
2025
-
[16]
gvulkan: Scalable GPU pooling for pixel- grained rendering in ray tracing
Yicheng Gu, Yun Wang, Yunfan Sun, Yuxin Xiang, Xuyan Hu, Zheng- wei Qi, and Haibing Guan. gvulkan: Scalable GPU pooling for pixel- grained rendering in ray tracing. In Saurabh Bagchi and Yiying Zhang, editors,Proceedings of the 2024 USENIX Annual Technical Conference, USENIX ATC 2024, Santa Clara, CA, USA, July 10-12, 2024, pages 1151–
2024
-
[17]
USENIX Association, 2024
2024
-
[18]
Microsecond-scale preemption for concurrent GPU-accelerated DNN inferences
Mingcong Han, Hanze Zhang, Rong Chen, and Haibo Chen. Microsecond-scale preemption for concurrent GPU-accelerated DNN inferences. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 539–558, Carlsbad, CA, July 2022. USENIX Association
2022
-
[19]
Rossbach, and Emmett Witchel
Tyler Hunt, Zhipeng Jia, Vance Miller, Ariel Szekely, Yige Hu, Christo- pher J. Rossbach, and Emmett Witchel. Telekine: Secure computing with cloud GPUs. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), pages 817–833, Santa Clara, CA, February 2020. USENIX Association
2020
-
[20]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, Vedant Choudhary, Foster Collins, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Maitrayee Dhaka, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine...
2026
-
[21]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch...
2025
-
[22]
Zhennan Jiang, Shangqing Zhou, Yutong Jiang, Zefang Huang, Mingjie Wei, Yuhui Chen, Tianxing Zhou, Zhen Guo, Hao Lin, Quanlu Zhang, Yu Wang, Haoran Li, Chao Yu, and Dongbin Zhao. Wovr: World models as reliable simulators for post-training vla policies with rl. arXiv preprint arXiv:2602.13977, 2026
-
[23]
Prashanthi S. K, Kunal Kumar Sahoo, Amartya Ranjan Saikia, Pranav Gupta, Atharva Vinay Joshi, Priyanshu Pansari, and Yogesh Simmhan. Pagoda: An energy and time roofline study for DNN workloads on edge accelerators.CoRR, abs/2509.20189, 2025
-
[24]
Timegraph: GPU scheduling for real-time multi-tasking environments
Shinpei Kato, Karthik Lakshmanan, Ragunathan Rajkumar, and Yutaka Ishikawa. Timegraph: GPU scheduling for real-time multi-tasking environments. In Jason Nieh and Carl A. Waldspurger, editors,Pro- ceedings of the 2011 USENIX Annual Technical Conference, USENIX ATC 2011, Portland, OR, USA, June 15-17, 2011. USENIX Association, 2011
2011
-
[25]
Shinpei Kato, Michael McThrow, Carlos Maltzahn, and Scott A. Brandt. Gdev: First-class GPU resource management in the operating system. In Gernot Heiser and Wilson C. Hsieh, editors,Proceedings of the 2012 USENIX Annual Technical Conference, USENIX ATC 2012, Boston, MA, USA, June 13-15, 2012, pages 401–412. USENIX Association, 2012
2012
-
[26]
VK_NV_cuda_kernel_launch extension
Khronos Group. VK_NV_cuda_kernel_launch extension. https://docs.vulkan.org/refpages/latest/refpages/source/VK_ NV_cuda_kernel_launch.html, 2023. Vulkan API Reference. Accessed: 2026-03-22
2023
-
[27]
The vulkan graphics and compute api.https://www
Khronos Group. The vulkan graphics and compute api.https://www. vulkan.org/, 2026. Accessed: 2026-03-22
2026
-
[28]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision- language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R San- keti, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. In Pulkit Agrawal, Oliver Kroemer, and...
2025
-
[30]
Nikolopoulos, and Cheol-Ho Hong
Munkyu Lee, Sihoon Seong, Minki Kang, Jihyuk Lee, Gap-Joo Na, In- Geol Chun, Dimitrios S. Nikolopoulos, and Cheol-Ho Hong. Parvagpu: Efficient spatial GPU sharing for large-scale DNN inference in cloud environments. InProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, SC 2024, Atlanta, GA, USA, N...
2024
-
[31]
MISO: exploiting multi-instance GPU capability on multi- tenant GPU clusters
Baolin Li, Tirthak Patel, Siddharth Samsi, Vijay Gadepally, and Devesh Tiwari. MISO: exploiting multi-instance GPU capability on multi- tenant GPU clusters. In Ada Gavrilovska, Deniz Altinbüken, and Carsten Binnig, editors,Proceedings of the 13th Symposium on Cloud Computing, SoCC 2022, San Francisco, California, November 7-11, 2022, pages 173–189. ACM, 2022
2022
-
[32]
SimpleVLA-RL: Scaling VLA training via reinforcement learning
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Yang Zhaohui, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, Dehui Wang, Dingxiang Luo, Yuchen Fan, Youbang Sun, Jia Zeng, Jiangmiao Pang, Shanghang Zhang, Yu Wang, Yao Mu, Bowen Zhou, and Ning Ding. SimpleVLA-RL: Scaling VLA training via reinforcement learning. InThe Fourteenth Internationa...
2026
-
[33]
Bullet: Boosting GPU utilization for LLM serving via dynamic spatial-temporal orchestration
Zejia Lin, Hongxin Xu, Guanyi Chen, Zhiguang Chen, Yutong Lu, and Xianwei Zhang. Bullet: Boosting GPU utilization for LLM serving via dynamic spatial-temporal orchestration. In Benjamin C. Lee, Harry Xu, Mark Silberstein, and Bingyao Li, editors,Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Ope...
2026
-
[34]
Lufei Liu, Mohammadreza Saed, Yuan-Hsi Chou, Davit Grigoryan, Tyler Nowicki, and Tor M. Aamodt. Lumibench: A benchmark suite for hardware ray tracing. InIEEE International Symposium on Workload Characterization, IISWC 2023, Ghent, Belgium, October 1-3, 2023, pages 1–14. IEEE, 2023. 13
2023
-
[35]
Isaac gym: High performance gpu-based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur All- shire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning. InAdvances in Neu- ral Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2021
2021
-
[36]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Hei- den, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Li- onel Gulich, Yijie Guo, ...
work page internal anchor Pith review arXiv 2025
-
[37]
Kelvin K. W. Ng, Henri Maxime Demoulin, and Vincent Liu. Paella: Low-latency model serving with software-defined GPU scheduling. In Jason Flinn, Margo I. Seltzer, Peter Druschel, Antoine Kaufmann, and Jonathan Mace, editors,Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October 23-26, 2023, pages 595–610. ACM, 2023
2023
-
[38]
Cosmos world foundation model platform for physical ai, 2025
NVIDIA, :, Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Huff- man, Pooya Jannaty, ...
2025
-
[39]
GR00T N1: An open foundation model for generalist humanoid robots
NVIDIA, Johan Bjorck, Nikita Cherniadev Fernando Castañeda, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You L...
2025
-
[40]
CUDA green contexts.https: //docs.nvidia.com/cuda/cuda-programming-guide/04-special- topics/green-contexts.html, 2024
NVIDIA Corporation. CUDA green contexts.https: //docs.nvidia.com/cuda/cuda-programming-guide/04-special- topics/green-contexts.html, 2024. CUDA C++ Programming Guide. Accessed: 2026-03-22
2024
-
[41]
NVIDIA open GPU kernel modules.https:// github.com/NVIDIA/open-gpu-kernel-modules, 2024
NVIDIA Corporation. NVIDIA open GPU kernel modules.https:// github.com/NVIDIA/open-gpu-kernel-modules, 2024. Accessed: 2026- 03-22
2024
-
[42]
Cuda c++ programming guide.https://docs
NVIDIA Corporation. Cuda c++ programming guide.https://docs. nvidia.com/cuda/cuda-c-programming-guide/, 2026. Accessed: 2026- 03-22
2026
-
[43]
Multi-Instance GPU (MIG).https://docs.nvidia
NVIDIA Corporation. Multi-Instance GPU (MIG).https://docs.nvidia. com/datacenter/tesla/mig-user-guide/, 2026. Accessed: 2026-03-22
2026
-
[44]
Multi-Process Service (MPS).https://docs
NVIDIA Corporation. Multi-Process Service (MPS).https://docs. nvidia.com/deploy/mps/, 2026. Accessed: 2026-03-22
2026
-
[45]
CHOPIN: scalable graphics rendering in multi-gpu systems via parallel image composition
Xiaowei Ren and Mieszko Lis. CHOPIN: scalable graphics rendering in multi-gpu systems via parallel image composition. InIEEE Interna- tional Symposium on High-Performance Computer Architecture, HPCA 2021, Seoul, South Korea, February 27 - March 3, 2021, pages 709–722. IEEE, 2021
2021
-
[46]
Rossbach, Jon Currey, Mark Silberstein, Baishakhi Ray, and Emmett Witchel
Christopher J. Rossbach, Jon Currey, Mark Silberstein, Baishakhi Ray, and Emmett Witchel. Ptask: operating system abstractions to manage gpus as compute devices. In Ted Wobber and Peter Druschel, editors, Proceedings of the 23rd ACM Symposium on Operating Systems Prin- ciples 2011, SOSP 2011, Cascais, Portugal, October 23-26, 2011, pages 233–248. ACM, 2011
2011
-
[47]
Introducing gwm-1, December 2025
Runway. Introducing gwm-1, December 2025. Accessed: 2026-05-01
2025
-
[48]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9339–9347, 2019
2019
-
[49]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Embodied ai and the rise of humanoid robots.https://www.morganstanley.com/im/publication/insights/ articles/article_humanoid-robots_a4.pdf, 2026
Morgan Stanley. Embodied ai and the rise of humanoid robots.https://www.morganstanley.com/im/publication/insights/ articles/article_humanoid-robots_a4.pdf, 2026. Accessed: 2026-03-22
2026
-
[51]
Yusuke Suzuki, Shinpei Kato, Hiroshi Yamada, and Kenji Kono. Gpuvm: Why not virtualizing gpus at the hypervisor? In Garth Gibson and Nickolai Zeldovich, editors,Proceedings of the 2014 USENIX Annual Technical Conference, USENIX ATC 2014, Philadelphia, PA, USA, June 19-20, 2014, pages 109–120. USENIX Association, 2014
2014
-
[52]
Cheng Tan, Zhichao Li, Jian Zhang, Yu Cao, Sikai Qi, Zherui Liu, Yibo Zhu, and Chuanxiong Guo. Serving DNN models with multi-instance gpus: A case of the reconfigurable machine scheduling problem.CoRR, abs/2109.11067, 2021
-
[53]
Maniskill3: Gpu paral- lelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse kai Chan, Yuan Gao, Xuanlin Li, Tongzhou Mu, Nan Xiao, Arnav Gurha, Viswesh Na- gaswamy Rajesh, Yong Woo Choi, Yen-Ru Chen, Zhiao Huang, Roberto Calandra, Rui Chen, Shan Luo, and Hao Su. Maniskill3: Gpu paral- lelized robotics simulation a...
2025
-
[54]
Alex Hofer, Jan Humplik, Atil Iscen, Mithun George Jacob, Deepali Jain, Ryan Julian, Dmitry Kalashnikov, M
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean- Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, Steven Bohez, Konstantinos Bousmalis, Anthony Brohan, Thomas Buschmann, Arunkumar Byravan, Serkan Cabi, Ken Caluwaerts, Federico Casarini, Oscar Chang, Jose Enrique...
2025
-
[55]
Gen-1: Scaling embodied foundation models to mastery.Generalist AI Blog, 2026
Generalist AI Team. Gen-1: Scaling embodied foundation models to mastery.Generalist AI Blog, 2026. https://generalistai.com/blog/apr- 02-2026-GEN-1
2026
-
[56]
Tesla optimus: Humanoid robot.https://www.teslarati
Tesla, Inc. Tesla optimus: Humanoid robot.https://www.teslarati. com/tesla-optimus-job-listings/, 2025. Accessed: 2026-03-22
2025
-
[57]
A full GPU virtu- alization solution with mediated pass-through
Kun Tian, Yaozu Dong, and David Cowperthwaite. A full GPU virtu- alization solution with mediated pass-through. In Garth Gibson and Nickolai Zeldovich, editors,Proceedings of the 2014 USENIX Annual Technical Conference, USENIX ATC 2014, Philadelphia, PA, USA, June 19-20, 2014, pages 121–132. USENIX Association, 2014
2014
-
[58]
Unitree H1: Full-size humanoid robot.https://www
Unitree Robotics. Unitree H1: Full-size humanoid robot.https://www. unitree.com/h1, 2025. Accessed: 2026-03-22
2025
-
[59]
Characterizing network requirements for gpu api remot- ing in ai applications, 2024
Tianxia Wang, Zhuofu Chen, Xingda Wei, Jinyu Gu, Rong Chen, and Haibo Chen. Characterizing network requirements for gpu api remot- ing in ai applications, 2024
2024
-
[60]
Phoenixos: Concurrent os-level gpu checkpoint and restore with validated speculation
Xingda Wei, Zhuobin Huang, Tianle Sun, Yingyi Hao, Rong Chen, Mingcong Han, Jinyu Gu, and Haibo Chen. Phoenixos: Concurrent os-level gpu checkpoint and restore with validated speculation. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles, SOSP ’25, page 996–1013, New York, NY, USA, 2025. Association for Computing Machinery
2025
-
[61]
Phoenixos: Concurrent os-level GPU checkpoint and restore with validated speculation
Xingda Wei, Zhuobin Huang, Tianle Sun, Yingyi Hao, Rong Chen, Mingcong Han, Jinyu Gu, and Haibo Chen. Phoenixos: Concurrent os-level GPU checkpoint and restore with validated speculation. In Youjip Won, Youngjin Kwon, Ding Yuan, and Rebecca Isaacs, editors, Proceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles, SOSP 2025, Lotte Ho...
2025
-
[62]
Marble: A multimodal world model, November 2025
World Labs team. Marble: A multimodal world model, November 2025. Accessed: 2026-05-01
2025
-
[63]
Trans- parent GPU sharing in container clouds for deep learning workloads
Bingyang Wu, Zili Zhang, Zhihao Bai, Xuanzhe Liu, and Xin Jin. Trans- parent GPU sharing in container clouds for deep learning workloads. In20th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 23), pages 69–85, Boston, MA, April 2023. USENIX Association
2023
-
[64]
StreamBox: A lightweight GPU SandBox for serverless inference workflow
Hao Wu, Yue Yu, Junxiao Deng, Shadi Ibrahim, Song Wu, Hao Fan, Ziyue Cheng, and Hai Jin. StreamBox: A lightweight GPU SandBox for serverless inference workflow. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 59–73, Santa Clara, CA, July 2024. USENIX Association
2024
-
[65]
OS rendering service made parallel with out-of-order execution and in-order commit
Yuanpei Wu, Chao Xu, Yubin Xia, Yang Yu, Ming Fu, Binyu Zang, and Haibo Chen. OS rendering service made parallel with out-of-order execution and in-order commit. In Lidong Zhou and Yuanyuan Zhou, editors,19th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2025, Boston, MA, USA, July 7-9, 2025, pages 693–710. USENIX Association, 2025
2025
-
[66]
Chang, Leonidas J
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A simulated part- based interactive environment. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[67]
Aegaeon: Effective GPU pooling for concurrent LLM serving on the market
Yuxing Xiang, Xue Li, Kun Qian, Yufan Yang, Diwen Zhu, Wenyuan Yu, Ennan Zhai, Xuanzhe Liu, Xin Jin, and Jingren Zhou. Aegaeon: Effective GPU pooling for concurrent LLM serving on the market. In Youjip Won, Youngjin Kwon, Ding Yuan, and Rebecca Isaacs, ed- itors,Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP 2025, Lotte...
2025
-
[68]
Gandiva: In- trospective cluster scheduling for deep learning
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. Gandiva: In- trospective cluster scheduling for deep learning. In Andrea C. Arpaci- Dusseau and Geoff Voelker, editors,13th USENIX Symposium on Op- erating Systems Design and Imple...
2018
-
[69]
Antman: Dynamic scaling on GPU clusters for deep learning
Wencong Xiao, Shiru Ren, Yong Li, Yang Zhang, Pengyang Hou, Zhi Li, Yihui Feng, Wei Lin, and Yangqing Jia. Antman: Dynamic scaling on GPU clusters for deep learning. In14th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2020, Virtual Event, November 4-6, 2020, pages 533–548. USENIX Association, 2020
2020
-
[70]
igniter: Interference-aware GPU resource provision- ing for predictable DNN inference in the cloud.IEEE Trans
Fei Xu, Jianian Xu, Jiabin Chen, Li Chen, Ruitao Shang, Zhi Zhou, and Fangming Liu. igniter: Interference-aware GPU resource provision- ing for predictable DNN inference in the cloud.IEEE Trans. Parallel Distributed Syst., 34(3):812–827, 2023
2023
-
[71]
gscale: Scaling up GPU virtualization with dynamic sharing of graphics memory space
Mochi Xue, Kun Tian, Yaozu Dong, Jiacheng Ma, Jiajun Wang, Zheng- wei Qi, Bingsheng He, and Haibing Guan. gscale: Scaling up GPU virtualization with dynamic sharing of graphics memory space. In Ajay Gulati and Hakim Weatherspoon, editors,Proceedings of the 2016 USENIX Annual Technical Conference, USENIX ATC 2016, Denver, CO, USA, June 22-24, 2016, pages 5...
2016
-
[72]
Robochallenge: Large-scale real-robot evaluation of embodied policies, 2025
Adina Yakefu, Bin Xie, Chongyang Xu, Enwen Zhang, Erjin Zhou, Fan Jia, Haitao Yang, Haoqiang Fan, Haowei Zhang, Hongyang Peng, Jing Tan, Junwen Huang, Kai Liu, Kaixin Liu, Kefan Gu, Qinglun Zhang, Ruitao Zhang, Saike Huang, Shen Cheng, Shuaicheng Liu, Tiancai Wang, Tiezhen Wang, Wei Sun, Wenbin Tang, Yajun Wei, Yang Chen, Youqiang Gui, Yucheng Zhao, Yunch...
2025
-
[73]
Preba: A hardware/software co-design for multi-instance gpu based ai inference servers, 2024
Gwangoo Yeo, Jiin Kim, Yujeong Choi, and Minsoo Rhu. Preba: A hardware/software co-design for multi-instance gpu based ai inference servers, 2024
2024
-
[74]
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025
-
[75]
Matrix-game: Interactive world foundation model, 2025
Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Fei Kang, Biao Jiang, Zedong Gao, Eric Li, Yang Liu, and Yahui Zhou. Matrix-game: Interactive world foundation model, 2025
2025
-
[76]
SGDRC: software-defined dynamic resource control for concurrent DNN inference on NVIDIA gpus
Yongkang Zhang, Haoxuan Yu, Chenxia Han, Cheng Wang, Baotong Lu, Yunzhe Li, Zhifeng Jiang, Yang Li, Xiaowen Chu, and Huaicheng Li. SGDRC: software-defined dynamic resource control for concurrent DNN inference on NVIDIA gpus. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel 15 Programming, PPoPP 2025, Las Vegas,...
2025
-
[77]
Lau, Yuqi Wang, Yifan Xiong, and Bin Wang
Hanyu Zhao, Zhenhua Han, Zhi Yang, Quanlu Zhang, Fan Yang, Li- dong Zhou, Mao Yang, Francis C.M. Lau, Yuqi Wang, Yifan Xiong, and Bin Wang. HiveD: Sharing a GPU cluster for deep learning with guarantees. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 515–532. USENIX Association, November 2020
2020
-
[78]
Tally: Non- intrusive performance isolation for concurrent deep learning work- loads
Wei Zhao, Anand Jayarajan, and Gennady Pekhimenko. Tally: Non- intrusive performance isolation for concurrent deep learning work- loads. In Lieven Eeckhout, Georgios Smaragdakis, Kaitai Liang, Adrian Sampson, Martha A. Kim, and Christopher J. Rossbach, editors,Pro- ceedings of the 30th ACM International Conference on Architectural Support for Programming ...
2025
-
[79]
Muxflow: Efficient and safe gpu sharing in large-scale production deep learning clusters, 2023
Yihao Zhao, Xin Liu, Shufan Liu, Xiang Li, Yibo Zhu, Gang Huang, Xuanzhe Liu, and Xin Jin. Muxflow: Efficient and safe gpu sharing in large-scale production deep learning clusters, 2023
2023
-
[80]
Xian Zhou, Theophile Luo, Zhaoting Ren, Hao Li, Zhiao Luo, Jian’an Ye, Haoyu Liu, Jiangmiao Li, Zhiwei Zhong, He Wang, and Hao Su. Genesis: A generative and universal physics engine for robotics and beyond.arXiv preprint arXiv:2409.15824, 2024. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.