Recognition: unknown
VoxAfford: Multi-Scale Voxel-Token Fusion for Open-Vocabulary 3D Affordance Detection
Pith reviewed 2026-05-09 15:24 UTC · model grok-4.3
The pith
Injecting multi-scale voxel features from a frozen 3D VQVAE into MLLM output tokens supplies missing spatial information for accurate open-vocabulary 3D affordance detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VoxAfford bypasses the spatial poverty of autoregressively generated MLLM output tokens by injecting multi-scale geometric features from a frozen pre-trained 3D VQVAE encoder into those tokens after generation. Each token serves as a query that retrieves relevant voxel patterns at its paired scale via cross-attention, with a learned compatibility gate regulating injection strength. The enhanced tokens are aggregated into a spatially-aware affordance prompt through semantic-conditioned attention and propagated together with per-point features to yield the output segmentation mask.
What carries the argument
Multi-scale voxel-token fusion, in which each affordance output token acts as a cross-attention query to retrieve geometric patterns from its corresponding voxel scale of a frozen 3D VQVAE, regulated by a learned compatibility gate.
If this is right
- The method reaches state-of-the-art mIoU scores with an approximately 8 percent improvement on open-vocabulary 3D affordance benchmarks.
- Real-robot trials confirm zero-shot transfer of the learned masks to previously unseen objects.
- The compatibility gate permits selective injection so that semantic content from the language model is preserved while geometric detail is added.
- The same enhanced tokens can be aggregated via semantic-conditioned attention before being decoded with per-point features.
Where Pith is reading between the lines
- The same post-generation cross-attention pattern could be tested on other 3D vision-language tasks where autoregressive models must produce spatially precise outputs.
- Replacing the frozen VQVAE with an end-to-end trainable encoder might reveal whether the current performance ceiling is limited by the frozen representation.
- Extending the multi-scale injection to temporal sequences of point clouds could support affordance detection in dynamic scenes.
Load-bearing premise
That the autoregressive generation of MLLM output tokens leaves them semantically rich but spatially impoverished, and that cross-attention to multi-scale features from a frozen 3D VQVAE can reliably supply the missing spatial neighborhood relations needed for 3D localization.
What would settle it
An ablation that removes or randomizes the voxel-feature injection while keeping all other components identical and still reports comparable mIoU would show that the claimed spatial enrichment is not required for the reported gains.
Figures



read the original abstract
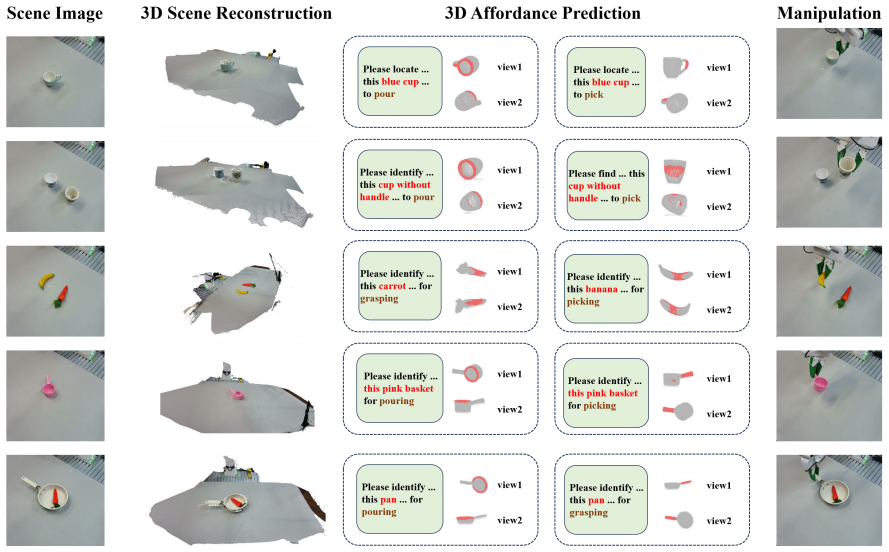
Open-vocabulary 3D affordance detection requires localizing interaction regions on point clouds given novel affordance descriptions. Recent methods extend multimodal large language models (MLLMs) with special output tokens that are decoded into segmentation masks. However, these tokens are produced through autoregressive generation, which models sequential dependencies rather than spatial neighborhood relations, leaving them semantically rich but spatially impoverished for 3D localization. We propose Voxel-enhanced Affordance detection (VoxAfford), which bypasses this bottleneck by injecting multi-scale geometric features from a frozen pre-trained 3D VQVAE encoder into the output tokens after generation. Each output token uses its affordance semantics as a query to retrieve relevant geometric patterns from its paired voxel scale via cross-attention, with a learned compatibility gate controlling the injection strength. The enhanced tokens are then aggregated into a spatially-aware affordance prompt through semantic-conditioned attention and propagated alongside per-point features to generate the final mask. Experiments on open-vocabulary affordance detection tasks show that VoxAfford achieves state-of-the-art performance with approximately an 8% improvement in mIoU, and real robot experiments confirm zero-shot transfer to novel objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VoxAfford for open-vocabulary 3D affordance detection on point clouds. It posits that autoregressive MLLM output tokens are semantically rich but spatially impoverished, and addresses this by injecting multi-scale geometric features from a frozen pre-trained 3D VQVAE encoder into the tokens post-generation. Each token uses its affordance semantics as a query in cross-attention to retrieve patterns from the corresponding voxel scale, modulated by a learned compatibility gate; the enhanced tokens are then aggregated via semantic-conditioned attention and propagated with per-point features to produce the final mask. The authors claim state-of-the-art performance with an approximately 8% mIoU gain and successful zero-shot transfer to novel objects in real-robot experiments.
Significance. If the experimental claims hold under rigorous validation, the approach demonstrates a viable route to augmenting the spatial deficiencies of autoregressive MLLM tokens with structured 3D geometric priors while keeping the VQVAE frozen, which supports efficiency. The zero-shot robot transfer provides a concrete test of open-vocabulary generalization beyond standard benchmarks.
major comments (1)
- The central claim of an 8% mIoU improvement and zero-shot transfer rests on the cross-attention successfully retrieving geometrically relevant patterns from the independently pretrained, frozen VQVAE latent space. Because the VQVAE and MLLM are trained separately, the paper must supply evidence (e.g., feature-space alignment metrics, t-SNE visualizations, or an ablation removing the VQVAE injection) that the affordance-semantic queries can linearly access affordance-discriminative geometry; without this, the gains could be driven by the base MLLM rather than the proposed voxel-token fusion. This issue is load-bearing for the method's novelty and is not addressed by the current description of the compatibility gate.
minor comments (2)
- Abstract: the phrase 'approximately an 8% improvement in mIoU' should specify the exact baseline method and dataset split for immediate context.
- Notation: ensure the compatibility gate is consistently denoted (e.g., as a scalar or vector) and its training objective is stated explicitly in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We agree that the central claim requires stronger empirical support for the cross-attention mechanism's ability to align affordance-semantic queries with geometrically relevant patterns from the frozen VQVAE. We will revise the manuscript accordingly to address this load-bearing issue.
read point-by-point responses
-
Referee: The central claim of an 8% mIoU improvement and zero-shot transfer rests on the cross-attention successfully retrieving geometrically relevant patterns from the independently pretrained, frozen VQVAE latent space. Because the VQVAE and MLLM are trained separately, the paper must supply evidence (e.g., feature-space alignment metrics, t-SNE visualizations, or an ablation removing the VQVAE injection) that the affordance-semantic queries can linearly access affordance-discriminative geometry; without this, the gains could be driven by the base MLLM rather than the proposed voxel-token fusion. This issue is load-bearing for the method's novelty and is not addressed by the current description of the compatibility gate.
Authors: We acknowledge the validity of this concern and agree that the current manuscript does not provide sufficient direct evidence of feature-space alignment or the specific contribution of the voxel injection. The compatibility gate modulates injection strength but does not itself demonstrate that the queries retrieve affordance-discriminative geometry. In the revised manuscript we will add: (1) a dedicated ablation that removes the entire VQVAE cross-attention injection (replacing it with a simple learned bias or no injection), showing a substantial mIoU drop relative to the full model and thereby isolating the fusion's contribution beyond the base MLLM; (2) t-SNE visualizations of the MLLM output token queries alongside the multi-scale VQVAE features, with affordance labels overlaid to illustrate semantic-geometric clustering; and (3) quantitative alignment metrics (e.g., mean cosine similarity between matched query-voxel pairs for positive vs. negative affordance cases, plus retrieval precision at k). These additions will directly substantiate that the cross-attention accesses relevant geometric patterns and that the reported gains and zero-shot transfer are attributable to the proposed mechanism rather than the underlying MLLM alone. We will also expand the method section to clarify the role of the compatibility gate in this alignment process. revision: yes
Circularity Check
No circularity; derivation relies on independent pre-trained components and standard attention
full rationale
The paper describes a fusion method using cross-attention between autoregressive MLLM tokens and multi-scale features from a frozen, independently pre-trained 3D VQVAE, with a learned compatibility gate and semantic-conditioned attention for mask generation. No equation or step reduces by construction to a fitted parameter renamed as prediction, nor does any load-bearing claim rest on self-citation chains or ansatzes smuggled from prior author work. The central performance claims are empirical (mIoU gains and robot transfer) evaluated against external benchmarks, with the architecture drawing on standard, externally validated components rather than tautological redefinitions of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- compatibility gate
axioms (1)
- domain assumption A frozen pre-trained 3D VQVAE encoder supplies useful multi-scale geometric patterns relevant to affordance localization.
Reference graph
Works this paper leans on
-
[1]
K. Rana, J. Abou-Chakra, S. Garg, R. Lee, I. Reid, and N. Suender- hauf, “Learning from 10 demos: Generalisable and sample-efficient policy learning with oriented affordance frames,”arXiv preprint arXiv:2410.12124, 2024
-
[2]
Afforddp: Generalizable diffusion policy with transferable affordance,
S. Wu, Y . Zhu, Y . Huang, K. Zhu, J. Gu, J. Yu, Y . Shi, and J. Wang, “Afforddp: Generalizable diffusion policy with transferable affordance,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6971–6980
2025
-
[3]
A0: An affordance-aware hier- archical model for general robotic manipulation,
R. Xu, J. Zhang, M. Guo, Y . Wen, H. Yang, M. Lin, J. Huang, Z. Li, K. Zhang, L. Wang,et al., “A0: An affordance-aware hier- archical model for general robotic manipulation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 13 491–13 501
2025
-
[4]
Video-to-image affordance grounding via visual conceptual learning,
Z. Fan and K. Liang, “Video-to-image affordance grounding via visual conceptual learning,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3972–3980
2025
-
[5]
Uad: Unsupervised affordance distillation for generaliza- tion in robotic manipulation,
Y . Tang, W. Huang, Y . Wang, C. Li, R. Yuan, R. Zhang, J. Wu, and L. Fei-Fei, “Uad: Unsupervised affordance distillation for generaliza- tion in robotic manipulation,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 3822–3831
2025
-
[6]
Affor- dancellm: Grounding affordance from vision language models,
S. Qian, W. Chen, M. Bai, X. Zhou, Z. Tu, and L. E. Li, “Affor- dancellm: Grounding affordance from vision language models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7587–7597
2024
-
[7]
3daffordsplat: Efficient affordance reasoning with 3d gaussians,
Z. Wei, J. Lin, Y . Liu, W. Chen, J. Luo, G. Li, and L. Lin, “3daffordsplat: Efficient affordance reasoning with 3d gaussians,” in Proceedings of the 33rd ACM International Conference on Multime- dia, 2025, pp. 2821–2830
2025
-
[8]
3d affordancenet: A benchmark for visual object affordance understanding,
S. Deng, X. Xu, C. Wu, K. Chen, and K. Jia, “3d affordancenet: A benchmark for visual object affordance understanding,” inproceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, 2021, pp. 1778–1787
2021
-
[9]
O2o-afford: Annotation-free large-scale object-object affordance learning,
K. Mo, Y . Qin, F. Xiang, H. Su, and L. Guibas, “O2o-afford: Annotation-free large-scale object-object affordance learning,” inCon- ference on robot learning. PMLR, 2022, pp. 1666–1677
2022
-
[10]
Grounding 3d object affordance with language instructions, visual observations and interactions,
H. Zhu, Q. Kong, K. Xu, X. Xia, B. Deng, J. Ye, R. Xiong, and Y . Wang, “Grounding 3d object affordance with language instructions, visual observations and interactions,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 337–17 346
2025
-
[11]
Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models,
H. Wang, S. Wang, Y . Zhong, Z. Yang, J. Wang, Z. Cui, J. Yuan, Y . Han, M. Liu, and Y . Ma, “Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models,” inProceedings of the AAAI Conference on Artificial Intelli- gence, vol. 40, no. 12, 2026, pp. 9738–9746
2026
-
[12]
Task-aware 3d affordance segmentation via 2d guidance and geometric refinement,
L. He, M. Liu, Q. Ye, Y . Zhou, X. Deng, and G. Ding, “Task-aware 3d affordance segmentation via 2d guidance and geometric refinement,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 6, 2026, pp. 4654–4662
2026
-
[13]
Open-vocabulary affordance detection using knowledge distillation and text-point correlation,
T. Van V o, M. N. Vu, B. Huang, T. Nguyen, N. Le, T. V o, and A. Nguyen, “Open-vocabulary affordance detection using knowledge distillation and text-point correlation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 13 968–13 975
2024
-
[14]
Open-vocabulary 3d affordance understanding via functional text enhancement and multilevel repre- sentation alignment,
L. Wu, W. Wei, P. Yu, and J. Lan, “Open-vocabulary 3d affordance understanding via functional text enhancement and multilevel repre- sentation alignment,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 7988–7997
2025
-
[15]
Seqafford: Sequential 3d affordance reasoning via multimodal large language model,
C. Yu, H. Wang, Y . Shi, H. Luo, S. Yang, J. Yu, and J. Wang, “Seqafford: Sequential 3d affordance reasoning via multimodal large language model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 1691–1701
2025
-
[16]
H. Chu, X. Deng, Q. Lv, X. Chen, Y . Li, J. Hao, and L. Nie, “3d- affordancellm: Harnessing large language models for open-vocabulary affordance detection in 3d worlds,”arXiv preprint arXiv:2502.20041, 2025
-
[17]
Openhoi: Open-world hand-object interaction synthesis with multimodal large language model,
Z. Zhang, Y . Shi, L. Yang, S. Ni, Q. Ye, and J. Wang, “Openhoi: Open-world hand-object interaction synthesis with multimodal large language model,”arXiv preprint arXiv:2505.18947, 2025
-
[18]
Recon3d: High quality 3d reconstruction from a single image using generated back-view explicit priors,
R. Chen, M. Yin, J. Shen, and W. Ma, “Recon3d: High quality 3d reconstruction from a single image using generated back-view explicit priors,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 2802–2811
2024
-
[19]
Uni3d: Ex- ploring unified 3d representation at scale,
J. Zhou, J. Wang, B. Ma, Y .-S. Liu, T. Huang, and X. Wang, “Uni3d: Exploring unified 3d representation at scale,”arXiv preprint arXiv:2310.06773, 2023
-
[20]
Multi-model ap- proach based on 3d functional features for tool affordance learning in robotics,
T. Mar, V . Tikhanoff, G. Metta, and L. Natale, “Multi-model ap- proach based on 3d functional features for tool affordance learning in robotics,” in2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids). IEEE, 2015, pp. 482–489
2015
-
[21]
Positional prompt tuning for efficient 3d representation learning,
S. Zhang, Z. Qi, R. Dong, X. Bai, and X. Wei, “Positional prompt tuning for efficient 3d representation learning,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 1171– 1180
2025
-
[22]
Reason3d: Searching and reasoning 3d segmentation via large language model,
K.-C. Huang, X. Li, L. Qi, S. Yan, and M.-H. Yang, “Reason3d: Searching and reasoning 3d segmentation via large language model,” in2025 International Conference on 3D Vision (3DV). IEEE, 2025, pp. 1177–1186
2025
-
[23]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia, “Lisa: Reasoning segmentation via large language model,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9579–9589
2024
-
[24]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
J. Yu, Y . Xu, J. Y . Koh, T. Luong, G. Baid, Z. Wang, V . Vasude- van, A. Ku, Y . Yang, B. K. Ayan,et al., “Scaling autoregressive models for content-rich text-to-image generation,”arXiv preprint arXiv:2206.10789, vol. 2, no. 3, p. 5, 2022
work page internal anchor Pith review arXiv 2022
-
[25]
Cogview: Mastering text-to- image generation via transformers,
M. Ding, Z. Yang, W. Hong, W. Zheng, C. Zhou, D. Yin, J. Lin, X. Zou, Z. Shao, H. Yang,et al., “Cogview: Mastering text-to- image generation via transformers,”Advances in neural information processing systems, vol. 34, pp. 19 822–19 835, 2021
2021
-
[26]
Make-a-scene: Scene-based text-to-image generation with hu- man priors,
O. Gafni, A. Polyak, O. Ashual, S. Sheynin, D. Parikh, and Y . Taig- man, “Make-a-scene: Scene-based text-to-image generation with hu- man priors,” inEuropean conference on computer vision. Springer, 2022, pp. 89–106
2022
-
[27]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883
2021
-
[28]
Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae,
Y . Chen, Y . Lan, S. Zhou, T. Wang, and X. Pan, “Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 28 371–28 382
2025
-
[29]
Shapellm: Universal 3d object understanding for embodied interaction,
Z. Qi, R. Dong, S. Zhang, H. Geng, C. Han, Z. Ge, L. Yi, and K. Ma, “Shapellm: Universal 3d object understanding for embodied interaction,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 214–238
2024
-
[30]
J. Ye, Z. Wang, R. Zhao, S. Xie, and J. Zhu, “Shapellm-omni: A native multimodal llm for 3d generation and understanding,”arXiv preprint arXiv:2506.01853, 2025
-
[31]
The senses considered as perceptual systems
J. J. Gibson, “The senses considered as perceptual systems.” 1966
1966
-
[32]
Affordgrasp: In-context affordance reasoning for open-vocabulary task-oriented grasping in clutter,
Y . Tang, S. Zhang, X. Hao, P. Wang, J. Wu, Z. Wang, and S. Zhang, “Affordgrasp: In-context affordance reasoning for open-vocabulary task-oriented grasping in clutter,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 9433–9439
2025
-
[33]
arXiv preprint arXiv:2503.03556 , year=
X. Zhu, Y . Li, L. Cui, P. Li, H.-a. Gao, Y . Zhu, and H. Zhao, “Afford-x: Generalizable and slim affordance reasoning for task- oriented manipulation,”arXiv preprint arXiv:2503.03556, 2025
-
[34]
Affordancenet: An end-to-end deep learning approach for object affordance detection,
T.-T. Do, A. Nguyen, and I. Reid, “Affordancenet: An end-to-end deep learning approach for object affordance detection,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 5882–5889
2018
-
[35]
Where2act: From pixels to actions for articulated 3d objects,
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, and S. Tulsiani, “Where2act: From pixels to actions for articulated 3d objects,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6813–6823
2021
-
[36]
Vat-mart: Learning visual action trajectory proposals for manipulating 3d articulated objects,
R. Wu, Y . Zhao, K. Mo, Z. Guo, Y . Wang, T. Wu, Q. Fan, X. Chen, L. Guibas, and H. Dong, “Vat-mart: Learning visual action trajectory proposals for manipulating 3d articulated objects,”arXiv preprint arXiv:2106.14440, 2021
-
[37]
Grounding 3d object affordance from 2d interactions in images,
Y . Yang, W. Zhai, H. Luo, Y . Cao, J. Luo, and Z.-J. Zha, “Grounding 3d object affordance from 2d interactions in images,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 905–10 915
2023
-
[38]
Laso: Language-guided affordance segmentation on 3d object,
Y . Li, N. Zhao, J. Xiao, C. Feng, X. Wang, and T.-s. Chua, “Laso: Language-guided affordance segmentation on 3d object,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 251–14 260
2024
-
[39]
Openscene: 3d scene understanding with open vocabularies,
S. Peng, K. Genova, C. Jiang, A. Tagliasacchi, M. Pollefeys, T. Funkhouser,et al., “Openscene: 3d scene understanding with open vocabularies,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 815–824
2023
-
[40]
Great: Geometry-intention collaborative inference for open-vocabulary 3d object affordance grounding,
Y . Shao, W. Zhai, Y . Yang, H. Luo, Y . Cao, and Z.-J. Zha, “Great: Geometry-intention collaborative inference for open-vocabulary 3d object affordance grounding,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 326–17 336
2025
-
[41]
3d-llm: Injecting the 3d world into large language models,
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan, “3d-llm: Injecting the 3d world into large language models,”Advances in Neural Information Processing Systems, vol. 36, pp. 20 482–20 494, 2023
2023
-
[42]
Pointllm: Empowering large language models to understand point clouds,
R. Xu, X. Wang, T. Wang, Y . Chen, J. Pang, and D. Lin, “Pointllm: Empowering large language models to understand point clouds,” in European Conference on Computer Vision. Springer, 2024, pp. 131– 147
2024
-
[43]
Ll3da: Visual interactive instruction tuning for omni- 3d understanding reasoning and planning,
S. Chen, X. Chen, C. Zhang, M. Li, G. Yu, H. Fei, H. Zhu, J. Fan, and T. Chen, “Ll3da: Visual interactive instruction tuning for omni- 3d understanding reasoning and planning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 26 428–26 438
2024
-
[44]
Grounded 3d-llm with referent tokens.arXiv preprint arXiv:2405.10370, 2024
Y . Chen, S. Yang, H. Huang, T. Wang, R. Xu, R. Lyu, D. Lin, and J. Pang, “Grounded 3d-llm with referent tokens,”arXiv preprint arXiv:2405.10370, 2024
-
[45]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[46]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892–34 916, 2023
2023
-
[47]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: En- hancing vision-language understanding with advanced large language models,”arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review arXiv 2023
-
[48]
Qwen-vl: A versatile vision-language model for under- standing, localization,
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for under- standing, localization,”Text Reading, and Beyond, vol. 2, no. 1, p. 1, 2023
2023
-
[49]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[50]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling,
X. Yu, L. Tang, Y . Rao, T. Huang, J. Zhou, and J. Lu, “Point-bert: Pre-training 3d point cloud transformers with masked point modeling,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 19 313–19 322
2022
-
[51]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3836–3847
2023
-
[52]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo,et al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[53]
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding,
K. Mo, S. Zhu, A. X. Chang, L. Yi, S. Tripathi, L. J. Guibas, and H. Su, “Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 909– 918
2019
-
[54]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen,et al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[55]
Zero-shot learning of 3d point cloud objects,
A. Cheraghian, S. Rahman, and L. Petersson, “Zero-shot learning of 3d point cloud objects,” in2019 16th International Conference on Machine Vision Applications (MVA). IEEE, 2019, pp. 1–6
2019
-
[56]
Transduc- tive zero-shot learning for 3d point cloud classification,
A. Cheraghian, S. Rahman, D. Campbell, and L. Petersson, “Transduc- tive zero-shot learning for 3d point cloud classification,” inProceed- ings of the IEEE/CVF winter conference on applications of computer vision, 2020, pp. 923–933
2020
-
[57]
Generative zero-shot learning for semantic segmentation of 3d point clouds,
B. Michele, A. Boulch, G. Puy, M. Bucher, and R. Marlet, “Generative zero-shot learning for semantic segmentation of 3d point clouds,” in 2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 992–1002
2021
-
[58]
Open-vocabulary affordance detection in 3d point clouds,
T. Nguyen, M. N. Vu, A. Vuong, D. Nguyen, T. V o, N. Le, and A. Nguyen, “Open-vocabulary affordance detection in 3d point clouds,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 5692–5698
2023
-
[59]
M. Abdin, J. Aneja, H. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann,et al., “Phi-4 technical report,”arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[60]
Ulip-2: Towards scalable multimodal pre-training for 3d understanding,
L. Xue, N. Yu, S. Zhang, A. Panagopoulou, J. Li, R. Mart ´ın-Mart´ın, J. Wu, C. Xiong, R. Xu, J. C. Niebles,et al., “Ulip-2: Towards scalable multimodal pre-training for 3d understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 091–27 101
2024
-
[61]
3d shapenets: A deep representation for volumetric shapes,
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao, “3d shapenets: A deep representation for volumetric shapes,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1912–1920
2015
-
[62]
Point transformer,
H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V . Koltun, “Point transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16 259–16 268
2021
-
[63]
Affordpose: A large- scale dataset of hand-object interactions with affordance-driven hand pose,
J. Jian, X. Liu, M. Li, R. Hu, and J. Liu, “Affordpose: A large- scale dataset of hand-object interactions with affordance-driven hand pose,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 14 713–14 724
2023
-
[64]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.