Recognition: unknown
Divide and Conquer: Decoupled Representation Alignment for Multimodal World Models
Pith reviewed 2026-05-10 15:47 UTC · model grok-4.3
The pith
Decoupling modality features in a diffusion model allows each to align with a separate foundation model expert for improved multi-modal video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that decoupling modality-specific features from the diffusion model's intermediate representations and aligning each decoupled feature to its corresponding expert foundation model via a multi-modal representation alignment loss together with a modality-specific decoupling regularization enables joint optimization that fully exploits the distinct domain-specific priors from multiple foundation models.
What carries the argument
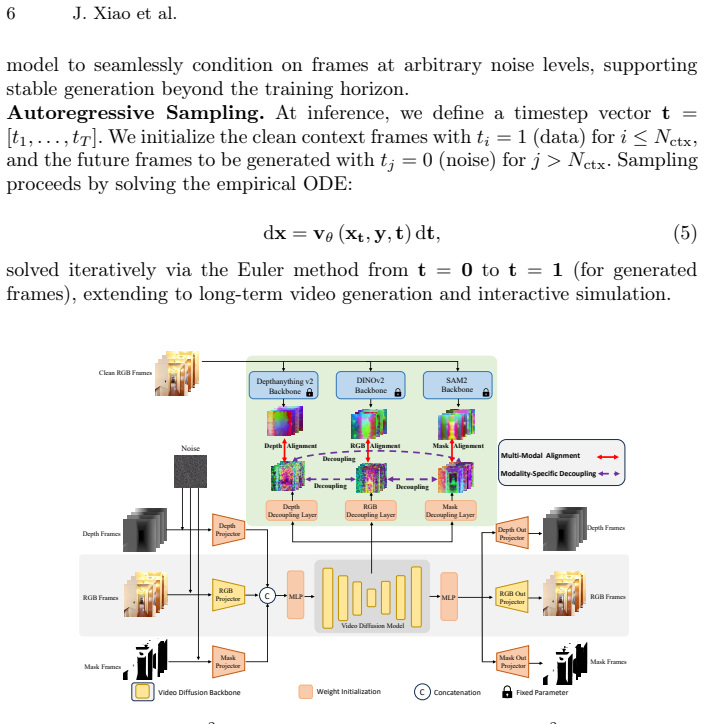
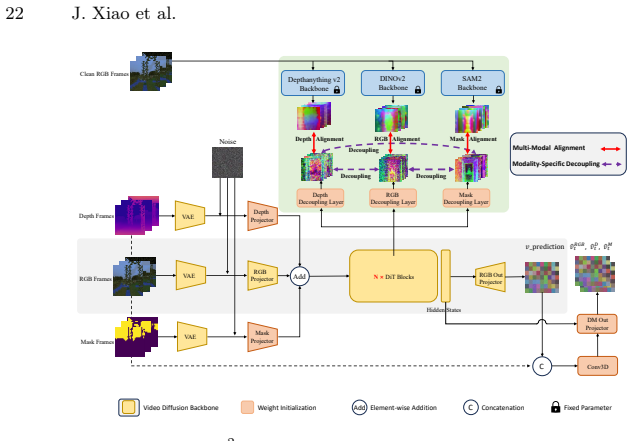
The M2-REPA method, which decouples modality-specific features from diffusion representations and aligns them individually to expert foundation models using alignment and regularization losses.
If this is right
- Multi-modal videos achieve higher visual quality by drawing on specialized priors from individual foundation models.
- Long-term consistency improves because complementary expert knowledge is preserved across frames.
- Joint training of the diffusion model becomes feasible while retaining the benefits of modality-specific pre-training.
- The approach outperforms standard baselines across metrics for quality and temporal coherence in experiments.
Where Pith is reading between the lines
- The same separation-and-align strategy could apply to other multi-modal generation tasks such as audio-video or text-image synthesis.
- It offers a route to combine many existing single-modality experts without retraining a single giant model from scratch.
- Adding further modalities might scale the quality gains without proportional increases in training cost.
Load-bearing premise
That foundation models for different modalities each carry distinct complementary information and that a decoupling step can isolate their features without erasing useful shared structure between modalities.
What would settle it
An ablation experiment that removes the decoupling regularization and measures whether performance on visual quality and long-term consistency drops compared to the full method, or whether aligning all modalities to a single mismatched expert still matches the reported gains.
Figures




read the original abstract
Emerging multi-modal world models attempt to jointly generate videos across diverse modalities (e.g., RGB, depth, and mask), yet they fail to fully exploit the rich priors of existing foundation models. We propose $M^2$-REPA, the first representation alignment method tailored for multi-modal video generation. Our key insight is that foundation models trained on different modality spaces naturally capture distinct domain-specific priors, acting as complementary "experts." Specifically, we first decouple modality-specific features from the diffusion model's intermediate representations, then align each with its corresponding expert foundation model. To this end, we design two synergistic objectives: a multi-modal representation alignment loss that enforces feature-to-expert matching, and a modality-specific decoupling regularization that encourages complementarity across different modalities. This design enables joint optimization, fully exploiting priors from multiple foundation models. Extensive experiments demonstrate that our method significantly outperforms baselines in visual quality and long-term consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes M²-REPA, a decoupled representation alignment method for multimodal world models in video generation. It decouples modality-specific features from the diffusion model's intermediate representations, then aligns each with its corresponding expert foundation model via a multi-modal representation alignment loss and a modality-specific decoupling regularization. The design is claimed to enable joint optimization that fully exploits complementary priors from multiple foundation models, with experiments showing significant gains in visual quality and long-term consistency over baselines.
Significance. If the central claims hold, this work could meaningfully advance multimodal video generation by offering a practical way to integrate diverse foundation-model priors without optimization conflicts. The decoupling regularization addresses a recognized challenge in joint multi-expert training and, if shown to preserve complementarity, would provide a reusable template for other multimodal synthesis tasks.
major comments (2)
- [Method] Method section (description of the two synergistic objectives): the modality-specific decoupling regularization is presented as encouraging complementarity across modalities, yet no analysis, bound, or ablation demonstrates that the term separates features rather than functioning as an orthogonality penalty that could discard cross-modal information or induce gradient conflicts during simultaneous expert optimization. This directly underpins the claim that joint optimization is enabled without new conflicts.
- [Experiments] Experiments section: performance improvements in visual quality and long-term consistency are reported, but the manuscript provides no controls comparing the full M²-REPA pipeline against independent per-modality alignments (i.e., the same alignment losses without the decoupling term). Without such isolation, it remains unclear whether the reported gains require the proposed decoupling or could be obtained by simpler joint training.
minor comments (2)
- [Abstract] The abstract states that foundation models 'naturally capture distinct domain-specific priors, acting as complementary experts,' but this assumption is not accompanied by a reference or preliminary measurement of prior complementarity on the target modalities.
- [Method] Notation for the two loss terms and the decoupling regularizer should be introduced with explicit equations early in the method section to allow readers to verify the claimed synergy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (description of the two synergistic objectives): the modality-specific decoupling regularization is presented as encouraging complementarity across modalities, yet no analysis, bound, or ablation demonstrates that the term separates features rather than functioning as an orthogonality penalty that could discard cross-modal information or induce gradient conflicts during simultaneous expert optimization. This directly underpins the claim that joint optimization is enabled without new conflicts.
Authors: We acknowledge that the original manuscript does not include a formal analysis, bound, or dedicated ablation isolating the decoupling regularizer's effect on feature separation versus potential information loss or gradient issues. To address this, we will revise the method section to add a short theoretical motivation: the regularizer is applied after explicit modality-specific feature extraction (via the decoupling process), encouraging orthogonality only within those subspaces while the alignment loss preserves any necessary cross-modal complementarity. We will also add an ablation study reporting inter-modality feature correlations and per-expert gradient statistics with/without the term, demonstrating that it reduces conflicts without discarding useful shared information. These changes will directly support the joint-optimization claim. revision: yes
-
Referee: [Experiments] Experiments section: performance improvements in visual quality and long-term consistency are reported, but the manuscript provides no controls comparing the full M²-REPA pipeline against independent per-modality alignments (i.e., the same alignment losses without the decoupling term). Without such isolation, it remains unclear whether the reported gains require the proposed decoupling or could be obtained by simpler joint training.
Authors: We agree that the current experiments do not isolate the decoupling term's contribution via a direct control against independent per-modality alignments. The reported baselines omit alignment entirely, leaving open whether simpler joint training suffices. In the revision we will add new results training separate per-modality models using only the alignment losses (no decoupling regularizer) and compare them quantitatively to the full joint M²-REPA model on the same metrics. These controls will show that independent alignments improve over non-aligned baselines but still underperform the joint model in long-term consistency and visual quality, thereby confirming that the decoupling term is necessary for effective multi-expert integration. revision: yes
Circularity Check
No circularity: method design is independent of its claimed outputs
full rationale
The provided manuscript text introduces M²-REPA via a new decoupling step on diffusion features followed by two explicitly designed losses (alignment + modality-specific regularization). No equations appear that equate any reported gain or complementarity to a fitted hyperparameter or prior result by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the central premise (joint optimization exploiting complementary priors) is not reduced to a renaming or ansatz smuggled from the authors' own prior work. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models trained on different modality spaces naturally capture distinct domain-specific priors that are complementary.
invented entities (1)
-
modality-specific decoupling regularization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 3rd International Workshop on Rich Media With Generative AI, ACM (2025) 1
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. Proceedings of the 3rd International Workshop on Rich Media With Generative AI, ACM (2025) 1
2025
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[3]
Advances in Neural Information Processing Systems37, 24081–24125 (2024) 4, 5
Chen, B., Martí Monsó, D., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Information Processing Systems37, 24081–24125 (2024) 4, 5
2024
-
[4]
arXiv preprint arXiv:2506.01103 (2025) 4
Chen, J., Zhu, H., He, X., Wang, Y., Zhou, J., Chang, W., Zhou, Y., Li, Z., Fu, Z., Pang, J., et al.: Deepverse: 4d autoregressive video generation as a world model. arXiv preprint arXiv:2506.01103 (2025) 4
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, S., Guo, H., Zhu, S., Zhang, F., Huang, Z., Feng, J., Kang, B.: Video depth anything: Consistent depth estimation for super-long videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22831–22840 (2025) 15
2025
-
[6]
4dnex: Feed-forward 4d generative modeling made easy.arXiv preprint arXiv:2508.13154, 2025
Chen, Z., Liu, T., Zhuo, L., Ren, J., Tao, Z., Zhu, H., Hong, F., Pan, L., Liu, Z.: 4dnex: Feed-forward 4d generative modeling made easy. arXiv preprint arXiv:2508.13154 (2025) 2, 4
-
[7]
Cherian,A.,Corcodel,R.,Jain,S.,Romeres,D.:Llmphy:Complexphysicalreason- ingusinglargelanguagemodelsandworldmodels.arXivpreprintarXiv:2411.08027 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
URL: https://oasis-model
Decart, E., McIntyre, Q., Campbell, S., Chen, X., Wachen, R.: Oasis: A universe in a transformer. URL: https://oasis-model. github. io (2024) 4 Decoupled Representation Alignment for Multimodal World Models 17
2024
-
[9]
Everingham,M.,VanGool,L.,Williams,C.K.,Winn,J.,Zisserman,A.:Thepascal visualobjectclasses(voc)challenge.Internationaljournalofcomputervision88(2), 303–338 (2010) 11
2010
-
[10]
Advances in Neural Information Processing Systems37, 91560–91596 (2024) 1
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y., Geiger, A., Zhang, J., Li, H.: Vista: A generalizable driving world model with high fidelity and versatile controllability. Advances in Neural Information Processing Systems37, 91560–91596 (2024) 1
2024
-
[11]
Ha, D., Schmidhuber, J.: World models. arXiv preprint arXiv:1803.101222(3) (2018) 1
work page internal anchor Pith review arXiv 2018
-
[12]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
He, X., Peng, C., Liu, Z., Wang, B., Zhang, Y., Cui, Q., Kang, F., Jiang, B., An, M., Ren, Y., et al.: Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009 (2025) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Advances in neural information processing systems33, 6840–6851 (2020) 1
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 1
2020
-
[14]
In: International Conference on Machine Learning
Hoogeboom, E., Heek, J., Salimans, T.: simple diffusion: End-to-end diffusion for high resolution images. In: International Conference on Machine Learning. pp. 13213–13232. PMLR (2023) 8, 11, 15
2023
-
[15]
GAIA-1: A Generative World Model for Autonomous Driving
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023) 1
work page internal anchor Pith review arXiv 2023
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, W., Gao, X., Li, X., Zhao, S., Cun, X., Zhang, Y., Quan, L., Shan, Y.: Depthcrafter: Generating consistent long depth sequences for open-world videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2005–2015 (2025) 11
2005
-
[17]
ACM Transactions on Graphics (TOG)44(6), 1–15 (2025) 2, 4
Huang, T., Zheng, W., Wang, T., Liu, Y., Wang, Z., Wu, J., Jiang, J., Li, H., Lau, R., Zuo, W., et al.: Voyager: Long-range and world-consistent video diffusion for explorable 3d scene generation. ACM Transactions on Graphics (TOG)44(6), 1–15 (2025) 2, 4
2025
-
[18]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[19]
arXiv preprint arXiv:2506.09229 (2025) 2, 4, 7, 8
Hwang, S., Jang, H., Kim, K., Park, M., Choo, J.: Cross-frame representation alignment for fine-tuning video diffusion models. arXiv preprint arXiv:2506.09229 (2025) 2, 4, 7, 8
-
[20]
arXiv preprint arXiv:2412.11673 (2024) 4
Karypidis, E., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Dino-foresight: Look- ing into the future with dino. arXiv preprint arXiv:2412.11673 (2024) 4
-
[21]
Advances in Neural Information Processing Systems37, 89834–89868 (2024) 4
Kim, J., Kang, J., Choi, J., Han, B.: Fifo-diffusion: Generating infinite videos from text without training. Advances in Neural Information Processing Systems37, 89834–89868 (2024) 4
2024
-
[22]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
In: International conference on machine learning
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.: Similarity of neural network rep- resentations revisited. In: International conference on machine learning. pp. 3519–
-
[24]
PMlR (2019) 3, 6, 9, 14, 25
2019
-
[25]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
arXiv preprint arXiv:2508.15720 (2025) 2, 4 18 J
Liu, Z., Deng, X., Chen, S., Wang, A., Guo, Q., Han, M., Xue, Z., Chen, M., Luo, P., Yang, L.: Worldweaver: Generating long-horizon video worlds via rich perception. arXiv preprint arXiv:2508.15720 (2025) 2, 4 18 J. Xiao et al
-
[28]
arXiv preprint arXiv:2510.03104 (2025) 2, 4
Mei,Z.,Shorinwa,O.,Majumdar,A.:Geometrymeetsvision:Revisitingpretrained semantics in distilled fields. arXiv preprint arXiv:2510.03104 (2025) 2, 4
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 2, 3, 4, 6, 7, 9, 10, 11, 12, 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
URL: https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/ (2025) 1, 4
Parker-Holder, J., Fruchter, S., et al.: Genie 3: A new frontier for world mod- els. URL: https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/ (2025) 1, 4
2025
-
[31]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 11, 13, 21
2023
-
[32]
Qian, Z., Chi, X., Li, Y., Wang, S., Qin, Z., Ju, X., Han, S., Zhang, S.: Wrist- world: Generating wrist-views via 4d world models for robotic manipulation. arXiv preprint arXiv:2510.07313 (2025) 2, 4
-
[33]
Worldsimbench: T owards video generation models as world simulators, 2024
Qin, Y., Shi, Z., Yu, J., Wang, X., Zhou, E., Li, L., Yin, Z., Liu, X., Sheng, L., Shao, J., et al.: Worldsimbench: Towards video generation models as world simulators. arXiv preprint arXiv:2410.18072 (2024) 1
-
[34]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 2, 4, 6
2021
-
[35]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024) 2, 4, 7, 9, 10, 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 11, 21
2022
-
[37]
Russell, L., Hu, A., Bertoni, L., Fedoseev, G., Shotton, J., Arani, E., Corrado, G.: Gaia-2: A controllable multi-view generative world model for autonomous driving. arXiv preprint arXiv:2503.20523 (2025) 1
-
[38]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
arXiv preprint arXiv:2502.06764 (2025)
Song, K., Chen, B., Simchowitz, M., Du, Y., Tedrake, R., Sitzmann, V.: History- guided video diffusion. arXiv preprint arXiv:2502.06764 (2025) 4, 7, 10, 12, 21
-
[40]
U-repa: Aligning diffu- sion u-nets to vits.arXiv preprint arXiv:2503.18414, 2025
Tian, Y., Chen, H., Zheng, M., Liang, Y., Xu, C., Wang, Y.: U-repa: Aligning diffusion u-nets to vits. arXiv preprint arXiv:2503.18414 (2025) 2, 7, 15
-
[41]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018) 11
work page internal anchor Pith review arXiv 2018
-
[42]
Diffusion models are real- time game engines.arXiv preprint arXiv:2408.14837, 2024
Valevski, D., Leviathan, Y., Arar, M., Fruchter, S.: Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837 (2024) 1, 4
-
[43]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676,
Wang, J., Yuan, Y., Zheng, R., Lin, Y., Gao, J., Chen, L.Z., Bao, Y., Zhang, Y., Zeng, C., Zhou, Y., et al.: Spatialvid: A large-scale video dataset with spatial annotations. arXiv preprint arXiv:2509.09676 (2025) 4 Decoupled Representation Alignment for Multimodal World Models 19
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 2, 4, 6
2025
-
[46]
IEEE transactions on image processing 13(4), 600–612 (2004) 11
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004) 11
2004
-
[47]
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Wu, H., Wu, D., He, T., Guo, J., Ye, Y., Duan, Y., Bian, J.: Geometry forcing: Mar- rying video diffusion and 3d representation for consistent world modeling. arXiv preprint arXiv:2507.07982 (2025) 2, 4, 6, 7, 10, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
arXiv preprint arXiv:2504.12369 (2025)
Xiao, Z., Lan, Y., Zhou, Y., Ouyang, W., Yang, S., Zeng, Y., Pan, X.: Worldmem: Long-term consistent world simulation with memory. arXiv preprint arXiv:2504.12369 (2025) 4
-
[49]
Xu, G., Lin, H., Luo, H., Wang, X., Yao, J., Zhu, L., Pu, Y., Chi, C., Sun, H., Wang, B., et al.: Pixel-perfect depth with semantics-prompted diffusion transform- ers. arXiv preprint arXiv:2510.07316 (2025) 4, 6, 7
-
[50]
In: International Conference on Machine Learning
Yan, W., Hafner, D., James, S., Abbeel, P.: Temporally consistent transformers for video generation. In: International Conference on Machine Learning. pp. 39062– 39098. PMLR (2023) 11, 13, 21
2023
-
[51]
Advances in Neural Information Processing Systems37, 21875–21911 (2024) 2, 3, 4, 7, 9, 10, 11, 12, 15
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024) 2, 3, 4, 7, 9, 10, 11, 12, 15
2024
-
[52]
Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023
Yang, M., Du, Y., Ghasemipour, K., Tompson, J., Schuurmans, D., Abbeel, P.: Learning interactive real-world simulators. arXiv preprint arXiv:2310.061141(2), 6 (2023) 1
-
[53]
Video as the new language for real-world decision making.arXiv preprint arXiv:2402.17139, 2024
Yang, S., Walker, J., Parker-Holder, J., Du, Y., Bruce, J., Barreto, A., Abbeel, P., Schuurmans, D.: Video as the new language for real-world decision making. arXiv preprint arXiv:2402.17139 (2024) 1
-
[54]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024) 1
work page internal anchor Pith review arXiv 2024
-
[55]
In: RSS 2025 Workshop: Mobile Manipulation: Emerging Opportunities{\&}Con- temporary Challenges (2025) 4
Yin, T., Mei, Z., Sun, T., Zha, L., Zhou, E., Bao, J., Yamane, M., Sho, O., Majum- dar, A.: Womap: World models for embodied open-vocabulary object localization. In: RSS 2025 Workshop: Mobile Manipulation: Emerging Opportunities{\&}Con- temporary Challenges (2025) 4
2025
-
[56]
In: CVPR (2025) 4
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast autoregressive video diffusion models. In: CVPR (2025) 4
2025
-
[57]
arXiv preprint arXiv:2509.07979 (2025) 4
Yoon, H., Jung, J., Kim, J., Choi, H., Shin, H., Lim, S., An, H., Kim, C., Han, J., Kim, D., et al.: Visual representation alignment for multimodal large language models. arXiv preprint arXiv:2509.07979 (2025) 2, 4
-
[58]
Yu, J., Qin, Y., Wang, X., Wan, P., Zhang, D., Liu, X.: Gamefactory: Creating new games with generative interactive videos. arXiv preprint arXiv:2501.08325 (2025) 1
-
[59]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940 (2024) 2, 4, 6, 7, 15, 21, 23
work page internal anchor Pith review arXiv 2024
-
[60]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 11 20 J. Xiao et al
2018
-
[61]
arXiv preprint arXiv:2505.23656 (2025) 2, 4, 6, 7, 8
Zhang, X., Liao, J., Zhang, S., Meng, F., Wan, X., Yan, J., Cheng, Y.: Videorepa: Learning physics for video generation through relational alignment with foundation models. arXiv preprint arXiv:2505.23656 (2025) 2, 4, 6, 7, 8
-
[62]
Tesseract: Learning 4d embodied world models, 2025
Zhen, H., Sun, Q., Zhang, H., Li, J., Zhou, S., Du, Y., Gan, C.: Tesseract: learning 4d embodied world models. arXiv preprint arXiv:2504.20995 (2025) 1, 2, 4, 21
-
[63]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018) 4, 10, 11, 12
work page internal anchor Pith review arXiv 2018
-
[64]
Zhou, Y., Wang, Y., Zhou, J., Chang, W., Guo, H., Li, Z., Ma, K., Li, X., Wang, Y., Zhu, H., et al.: Omniworld: A multi-domain and multi-modal dataset for 4d world modeling. arXiv preprint arXiv:2509.12201 (2025) 4
-
[65]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, H., Wang, Y., Zhou, J., Chang, W., Zhou, Y., Li, Z., Chen, J., Shen, C., Pang, J., He, T.: Aether: Geometric-aware unified world modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8535–8546 (2025) 2, 4
2025
-
[66]
Zhu, Z., Wang, X., Zhao, W., Min, C., Deng, N., Dou, M., Wang, Y., Shi, B., Wang, K., Zhang, C., et al.: Is sora a world simulator? a comprehensive survey on general world models and beyond. arXiv preprint arXiv:2405.03520 (2024) 1 Decoupled Representation Alignment for Multimodal World Models 21 Supplementary Material A Latent-Space DiT Architecture Deta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.