Recognition: 2 theorem links
Is It Novel and Why? Fine-Grained Patent Novelty Prediction Based on Passage Retrieval
Pith reviewed 2026-05-08 18:37 UTC · model grok-4.3
The pith
Decomposing patent claims into features and retrieving matching prior art passages yields more accurate novelty predictions than binary claim-level classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
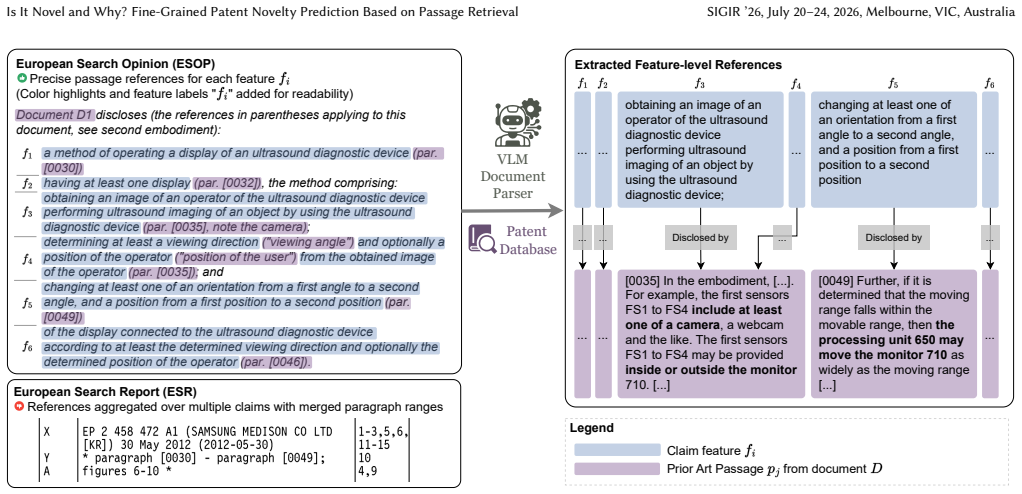
By releasing the FiNE-Patents dataset of first claims annotated at the feature level from European Search Opinion documents, the authors show that LLM workflows performing claim decomposition, passage retrieval from prior art, and identification of novel features outperform embedding-based baselines on retrieval and novelty tasks while remaining robust to spurious correlations that degrade claim-level classifiers.
What carries the argument
The LLM workflow that decomposes a patent claim into features, retrieves specific passages from a prior art document for each feature, and identifies which features establish novelty.
If this is right
- Passage retrieval accuracy increases when models analyze claims feature by feature rather than as a whole.
- Novel feature identification becomes more precise with the retrieval-plus-reasoning workflow.
- Claim-level novelty decisions gain robustness because they are derived from explicit feature-level evidence rather than end-to-end classification.
- The resulting explanations are granular, showing exactly which parts of an invention are already disclosed.
Where Pith is reading between the lines
- The same decomposition and retrieval steps could be tested on patent corpora from other jurisdictions to check cross-office consistency.
- Automated tools following this pattern might reduce examiner workload by surfacing candidate passages and flagging non-novel features.
- The approach may transfer to other legal comparison tasks that require matching specific elements across long documents.
Load-bearing premise
The feature-level annotations extracted from European Search Opinion documents serve as reliable and consistent ground truth for both passage retrieval and novelty judgments.
What would settle it
A new collection of patent claims where the LLM workflows show no improvement over embedding baselines on passage retrieval or lose robustness to spurious correlations would falsify the main claims.
Figures




read the original abstract
Novelty assessment is a critical yet complex task in the examination process for patent acceptance, requiring examiners to determine whether an invention is disclosed in a prior art document. The process involves intricate matching between specific features of a patent claim and passages in the prior art. While prior work has approached novelty prediction primarily as a binary classification task at the claim level, we argue that this formulation is susceptible to spurious correlations and lacks the granularity required for practical application. In this work, we introduce FiNE-Patents (Fine-grained Novelty Examination of Patents), a novel dataset comprising 3,658 first patent claims annotated with fine-grained, feature-level prior art references extracted from European Search Opinion (ESOP) documents. We propose shifting the evaluation paradigm from simple binary classification to a joint retrieval and abstract reasoning task at the feature level, requiring models to identify specific passages from a prior art document that disclose individual claim features, and to identify which features of a claim make it novel. We implement and evaluate LLM-based workflows that decompose claims into features, analyze each feature against prior art, and finally derive a claim-level novelty prediction. Our experiments demonstrate that these workflows outperform embedding-based baselines on passage retrieval and novel feature identification. Furthermore, we show that unlike trained classifiers, LLMs are robust against spurious correlations present in the claim-level novelty classification task. We release the dataset and code to foster further research into transparent and granular patent analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the FiNE-Patents dataset consisting of 3,658 first patent claims with feature-level prior-art passage annotations extracted from European Search Opinion (ESOP) documents. It reframes novelty assessment as a joint passage-retrieval and abstract-reasoning task at the feature level rather than binary claim-level classification, and evaluates LLM-based workflows that decompose claims, retrieve disclosing passages, identify novel features, and aggregate to a claim-level prediction. The central claims are that these workflows outperform embedding-based baselines on retrieval and novel-feature identification, and that LLMs exhibit greater robustness to spurious correlations than trained classifiers.
Significance. If the ESOP-derived annotations prove reliable and the workflows generalize, the shift to fine-grained, passage-level evaluation could meaningfully improve transparency and accuracy in patent novelty analysis. The public release of the dataset and code is a clear strength that supports reproducibility and follow-on work. The robustness result is potentially important because it suggests LLMs may avoid certain annotation artifacts that affect supervised models. However, the overall significance is tempered by the dependence on a single source of ground truth whose completeness and consistency are not independently validated in the manuscript.
major comments (1)
- [§3 and §4] §3 (Dataset Construction) and §4 (Experiments): The feature-level annotations extracted from ESOP documents are treated as exhaustive ground truth for both passage retrieval (which prior-art passages disclose each feature) and novel-feature identification. The manuscript does not report inter-annotator agreement, coverage statistics against full prior-art searches, or an analysis of omitted passages; because ESOPs are examiner opinions rather than exhaustive searches and involve subjective claim decomposition, any incompleteness or inconsistency directly affects the reported gains over embedding baselines and the robustness comparison in §5.3.
minor comments (1)
- [Abstract and §1] The abstract and §1 would benefit from an explicit statement of the primary evaluation metrics (e.g., precision@K, MAP, or F1 for retrieval and novelty identification) and the exact number of prior-art documents per claim.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address the major comment on dataset annotations point by point below and outline planned revisions.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Dataset Construction) and §4 (Experiments): The feature-level annotations extracted from ESOP documents are treated as exhaustive ground truth for both passage retrieval (which prior-art passages disclose each feature) and novel-feature identification. The manuscript does not report inter-annotator agreement, coverage statistics against full prior-art searches, or an analysis of omitted passages; because ESOPs are examiner opinions rather than exhaustive searches and involve subjective claim decomposition, any incompleteness or inconsistency directly affects the reported gains over embedding baselines and the robustness comparison in §5.3.
Authors: We appreciate the referee's observation that ESOP-derived annotations, while enabling fine-grained feature-level evaluation, are not exhaustive ground truth. ESOPs reflect examiner opinions on relevant prior art and claim feature decomposition rather than complete searches, which can lead to omitted passages or subjective judgments. In the revised manuscript, we will add a dedicated limitations subsection to §3 discussing the provenance and potential incompleteness of these annotations. We will also report additional coverage statistics already derivable from the dataset, such as the average number of annotated passages per feature, the distribution of prior-art documents per claim, and the proportion of features with single vs. multiple disclosing passages. Regarding inter-annotator agreement, the annotations are extracted directly from official ESOP documents and were not produced via independent multi-annotator labeling in our study; we will explicitly note this as a limitation and suggest future multi-examiner validation. For the experimental impact, we agree that absolute performance figures could be influenced by any annotation gaps, but relative comparisons between LLM workflows and embedding baselines remain informative because all methods are evaluated against identical annotations. We will add a short discussion in §5.3 acknowledging how potential ESOP artifacts might affect the spurious-correlation robustness results and will moderate our claims accordingly. These changes will improve transparency without altering the core contribution of shifting to feature-level retrieval and reasoning. revision: partial
Circularity Check
No circularity: empirical evaluation on newly introduced dataset with external baselines
full rationale
The paper introduces FiNE-Patents, a new dataset derived from ESOP documents, and evaluates LLM workflows for feature-level passage retrieval and novelty identification against embedding baselines. No mathematical derivations, fitted parameters, or predictions are present that reduce to self-defined quantities. The central claims rest on empirical comparisons (outperformance on retrieval/novelty metrics and robustness to spurious correlations) that are externally falsifiable via the released dataset and code. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing premises. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Patent claims can be decomposed into discrete, independently matchable features without substantial loss of meaning.
- domain assumption Annotations extracted from European Search Opinion documents accurately capture the specific prior-art passages that disclose individual claim features.
Reference graph
Works this paper leans on
-
[1]
Lin Ai, Ziwei Gong, Harshsaiprasad Deshpande, Alexander Johnson, Emmy Phung, Ahmad Emami, and Julia Hirschberg. 2025. NovAScore: A New Au- tomated Metric for Evaluating Document Level Novelty. InProceedings of the 31st International Conference on Computational Linguistics, Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, ...
2025
-
[2]
Amna Ali, Ali Tufail, Liyanage Chandratilak De Silva, and Pg Emeroylariffion Abas. 2024. Innovating Patent Retrieval: A Comprehensive Review of Techniques, Trends, and Challenges in Prior Art Searches.Applied System Innovation7, 5 (2024). doi:10.3390/asi7050091
-
[3]
Linda Andersson, Mihai Lupu, João Palotti, Allan Hanbury, and Andreas Rauber
-
[4]
InProceedings of the 25th ACM International on Conference on Information and Knowledge Management
When is the time ripe for natural language processing for patent pas- sage retrieval?. InProceedings of the 25th ACM International on Conference on Information and Knowledge Management. 1453–1462
-
[5]
Linda Andersson, Parvaz Mahdabi, Allan Hanbury, and Andreas Rauber. 2012. Report on the CLEF-IP 2012 Experiments: Exploring Passage Retrieval with the PIPExtractor. InConference and Labs of the Evaluation Forum. https://api. semanticscholar.org/CorpusID:5914491
2012
-
[6]
Linda Andersson, Parvaz Mahdabi, Allan Hanbury, and Andreas Rauber. 2013. Exploring patent passage retrieval using nouns phrases. InEuropean Conference on Information Retrieval. Springer, 676–679
2013
- [7]
-
[8]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page Pith review arXiv 2025
-
[9]
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondrej Dusek. 2024. Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed- Source LLMs. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Yvette Graham and Matthew Purver (Eds.). Association ...
-
[10]
Roger E Beaty and Dan R Johnson. 2021. Automating creativity assessment with SemDis: An open platform for computing semantic distance.Behavior research methods53, 2 (2021), 757–780
2021
-
[11]
Matthias Blume, Ghobad Heidari, and Christoph Hewel. 2024. Comparing Com- plex Concepts with Transformers: Matching Patent Claims Against Natural Language Text. InProceedings of the 5th Workshop on Patent Text Mining and Semantic Technologies (PatentSemTech@SIGIR)
2024
-
[12]
Zhenhai Chi, Wuquan Lin, Zhanhao Xiao, Huihui Li, Weiqi Chen, and Xiaoyong Liu. 2026. A review of patent analysis based on machine learning.Applied Soft Computing186 (2026), 114063. doi:10.1016/j.asoc.2025.114063
-
[13]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and psychological measurement20, 1 (1960), 37–46
1960
-
[14]
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan
-
[15]
Investigating Data Contamination in Modern Benchmarks for Large Lan- guage Models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Linguistics, Mexico Ci...
-
[16]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186. Is It Novel...
2019
- [17]
-
[18]
Pasi Fränti and Radu Mariescu-Istodor. 2023. Soft precision and recall.Pattern Recognition Letters167 (2023), 115–121
2023
-
[19]
Atsushi Fujii and Tetsuya Ishikawa. 2005. Document Structure Analysis for the NTCIR-5 Patent Retrieval Task.. InNTCIR
2005
-
[20]
Atsushi Fujii, Makoto Iwayama, and Noriko Kando. 2005. Overview of Patent Retrieval Task at NTCIR-5. InNTCIR Conference on Evaluation of Information Access Technologies. https://api.semanticscholar.org/CorpusID:267804819
2005
-
[21]
Atsushi Fujii, Makoto Iwayama, and Noriko Kando. 2006. Test Collections for Patent Retrieval and Patent Classification in the Fifth NTCIR Workshop.. InLREC. 671–674
2006
-
[22]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. Shortcut learn- ing in deep neural networks.Nature Machine Intelligence2, 11 (2020), 665–673
2020
-
[23]
Tirthankar Ghosal. 2022. Studies in aspects of peer review: novelty, scope, research lineage, review significance, and peer review outcome.SIGIR Forum55, 2, Article 26 (March 2022), 2 pages. doi:10.1145/3527546.3527577
-
[24]
Shohei Hido, Shoko Suzuki, Risa Nishiyama, Takashi Imamichi, Rikiya Takahashi, Tetsuya Nasukawa, Tsuyoshi Idé, Yusuke Kanehira, Rinju Yohda, Takeshi Ueno, Akira Tajima, and Toshiya Watanabe. 2012. Modeling Patent Quality: A System for Large-scale Patentability Analysis using Text Mining.Inf. Media Technol.7, 3 (2012), 1180–1191. doi:10.11185/IMT.7.1180
- [25]
-
[26]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated gain-based evaluation of IR techniques.ACM Trans. Inf. Syst.20, 4 (2002), 422–446
2002
-
[27]
Lekang Jiang and Stephan M Goetz. 2025. Natural language processing in the patent domain: a survey.Artificial Intelligence Review58, 7 (2025), 214
2025
-
[28]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
-
[29]
InThe Twelfth International Conference on Learning Representations
DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=sY5N0zY5Od
-
[30]
Valentin Knappich, Annemarie Friedrich, Anna Hätty, and Simon Razniewski
-
[31]
InProceedings of the 6th Workshop on Patent Text Mining and Semantic Technologies (PatentSemTech@SIGIR)
PEDANTIC: A Dataset for the Automatic Examination of Definiteness in Patent Claims. InProceedings of the 6th Workshop on Patent Text Mining and Semantic Technologies (PatentSemTech@SIGIR)
-
[32]
Valentin Knappich, Anna Hätty, Simon Razniewski, and Annemarie Friedrich
-
[33]
PAP2PAT: Benchmarking Outline-Guided Long-Text Patent Generation with Patent-Paper Pairs. InFindings of the Association for Computational Linguis- tics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 9524–9554. doi:10.18653/v1/2025.findings-acl.496
-
[34]
Nancy Kong, Uwe Dulleck, Adam B Jaffe, Shupeng Sun, and Sowmya Vajjala
-
[35]
Linguistic metrics for patent disclosure: Evidence from university versus corporate patents.Research policy52, 2 (2023), 104670
2023
-
[36]
Ralf Krestel, Renukswamy Chikkamath, Christoph Hewel, and Julian Risch. 2021. A survey on deep learning for patent analysis.World Patent Information65 (2021), 102035
2021
-
[37]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Mem- ory Management for Large Language Model Serving with PagedAttention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[38]
Ronan Le Bras, Swabha Swayamdipta, Chandra Bhagavatula, Rowan Zellers, Matthew Peters, Ashish Sabharwal, and Yejin Choi. 2020. Adversarial filters of dataset biases. InInternational Conference on Machine Learning. Pmlr, 1078–1088
2020
- [39]
-
[40]
Vladimir I Levenshtein et al. 1966. Binary codes capable of correcting deletions, insertions, and reversals. InSoviet physics doklady, Vol. 10. Soviet Union, 707–710
1966
-
[41]
Yucheng Li, Yunhao Guo, Frank Guerin, and Chenghua Lin. 2024. An Open- Source Data Contamination Report for Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 528–541. doi:10.18653/v1/2024.f...
-
[42]
Hyunseung Lim, Sooyohn Nam, Sungmin Na, Ji Yong Cho, June Yong Yang, Hyungyu Shin, Yoonjoo Lee, Juho Kim, Moontae Lee, and Hwajung Hong
-
[43]
InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track
PANORAMA: A Dataset and Benchmarks Capturing Decision Trails and Rationales in Patent Examination. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=JWewCpdjjq
-
[44]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
-
[45]
Ethan Lin, Zhiyuan Peng, and Yi Fang. 2025. Evaluating and Enhancing Large Lan- guage Models for Novelty Assessment in Scholarly Publications. InProceedings of the 1st Workshop on AI and Scientific Discovery: Directions and Opportunities, Peter Jansen, Bhavana Dalvi Mishra, Harsh Trivedi, Bodhisattwa Prasad Ma- jumder, Tom Hope, Tushar Khot, Doug Downey, ...
-
[46]
Jiacheng Liu, Sewon Min, Luke Zettlemoyer, Yejin Choi, and Hannaneh Hajishirzi
-
[47]
InFirst Conference on Language Modeling
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens. InFirst Conference on Language Modeling. https://openreview.net/forum? id=u2vAyMeLMm
-
[48]
Hao-Cheng Lo and Jung-Mei Chu. 2021. Pre-trained Transformer-based Clas- sification for Automated Patentability Examination. In2021 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE). IEEE, 1–5
2021
-
[49]
Mihai Lupu, Atsushi Fujii, Douglas W Oard, Makoto Iwayama, and Noriko Kando
-
[50]
InCurrent challenges in patent information retrieval
Patent-related tasks at ntcir. InCurrent challenges in patent information retrieval. Springer, 77–111
- [51]
-
[52]
Peter Organisciak, Selcuk Acar, Denis Dumas, and Kelly Berthiaume. 2023. Be- yond semantic distance: Automated scoring of divergent thinking greatly im- proves with large language models.Thinking Skills and Creativity49 (2023), 101356
2023
-
[53]
Arav Parikh and Shiri Dori-Hacohen. 2024. ClaimCompare: A Data Pipeline for Evaluation of Novelty Destroying Patent Pairs. InProceedings of the 5th Workshop on Patent Text Mining and Semantic Technologies (PatentSemTech@SIGIR)
2024
-
[54]
Florina Piroi and Allan Hanbury. 2017. Evaluating information retrieval systems on European patent data: The clef-ip campaign. InCurrent Challenges in Patent Information Retrieval. Springer, 113–142
2017
-
[55]
Florina Piroi, Mihai Lupu, and Allan Hanbury. 2013. Overview of CLEF-IP 2013 Lab: Information Retrieval in the Patent Domain. InInternational Conference of the Cross-Language Evaluation Forum for European Languages. Springer, 232–249
2013
-
[56]
Julian Risch, Nicolas Alder, Christoph Hewel, and Ralf Krestel. 2021. PatentMatch: A Dataset for Matching Patent Claims & Prior Art. InProceedings of the 2nd Work- shop on Patent Text Mining and Semantic Technologies (PatentSemTech@SIGIR)
2021
-
[57]
Janika Saretzki and Mathias Benedek. 2026. Investigating the Validity Evidence of Automated Scoring Methods for Divergent Thinking Assessments.Creativity Research Journal(2026), 1–17
2026
-
[58]
Jinzhi Shan, Qi Zhang, Chongyang Shi, Mengting Gui, Shoujin Wang, and Usman Naseem. 2024. Structural Representation Learning and Disentanglement for Evidential Chinese Patent Approval Prediction. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2014–2023
2024
-
[59]
Yongluo Shen and Zexi Lin. 2024. PatentGrapher: A PLM-GNNs Hybrid Model for Comprehensive Patent Plagiarism Detection Across Full Claim Texts.IEEE Access 12 (2024), 182717–182725. https://api.semanticscholar.org/CorpusID:274416597
2024
-
[60]
Ravi, and Sourav Medya
Homaira Huda Shomee, Zhu Wang, Sathya N. Ravi, and Sourav Medya. 2025. A Survey on Patent Analysis: From NLP to Multimodal AI. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational L...
2025
-
[61]
doi:10.18653/v1/2025.acl-long.419
-
[62]
Smith, and Hannaneh Hajishirzi
Evan Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Ak- shita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Allyson Ettinger, Michal Guerquin, David Heineman, Hamish Ivison, Pang Wei Koh, Jiache...
2025
- [63]
- [64]
-
[65]
Wenqing Wu, Chengzhi Zhang, Tong Bao, and Yi Zhao. 2025. SC4ANM: Identify- ing optimal section combinations for automated novelty prediction in academic papers.Expert Syst. Appl.273 (2025), 126778. https://api.semanticscholar.org/ CorpusID:276296422
2025
-
[66]
Long Xia, Jun Xu, Yanyan Lan, Jiafeng Guo, and Xueqi Cheng. 2016. Modeling Document Novelty with Neural Tensor Network for Search Result Diversification. InProceedings of the 39th International ACM SIGIR Conference on Research and SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Knappich et al. Development in Information Retrieval(Pisa, Italy)(SIGIR...
-
[67]
Qiushi Xiong, Zhipeng Xu, Zhenghao Liu, Mengjia Wang, Zulong Chen, Yue Sun, Yu Gu, Xiaohua Li, and Ge Yu. 2025. Enhancing the Patent Matching Capability of Large Language Models via the Memory Graph. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for C...
-
[68]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review arXiv 2025
- [69]
-
[70]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[71]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review arXiv 2025
-
[72]
Yi Zhao and Chengzhi Zhang. 2025. A review on the novelty measurements of academic papers.Scientometrics130, 2 (2025), 727–753
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.