Recognition: 2 theorem links
· Lean TheoremA Validated Prompt Bank for Malicious Code Generation: Separating Executable Weapons from Security Knowledge in 1,554 Consensus-Labeled Prompts
Pith reviewed 2026-05-08 18:06 UTC · model grok-4.3
The pith
Five large language models reach consensus on separating 1,554 prompts for executable malicious code from those for security knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper demonstrates that a consensus protocol using five large-language-model judges from different vendors can reliably classify prompts into executable code requests versus security knowledge requests. Applied to 3,133 prompts, the three-of-five majority rule produces a 1,554-prompt consensus-CODE bank with Fleiss' kappa of 0.876 and full coverage of all prompts without exclusions. The authors present this validated bank as the primary artifact and argue that treating the weapons-versus-knowledge distinction as the organizing axis allows more precise evaluation of language model safety on malicious code tasks.
What carries the argument
The weapons-versus-knowledge classification axis, carried out through a five-judge consensus protocol where each prompt receives a binary label under a three-of-five majority vote.
Load-bearing premise
That a clean binary distinction between requests for executable malicious code and requests for security knowledge exists and aligns with how safety-aligned models process these inputs.
What would settle it
If a follow-up study finds that the refusal rates of language models on the 1,554 consensus-CODE prompts do not differ meaningfully from those on the 388 consensus-KNOWLEDGE prompts, the practical value of the separation would be undermined.
Figures





read the original abstract
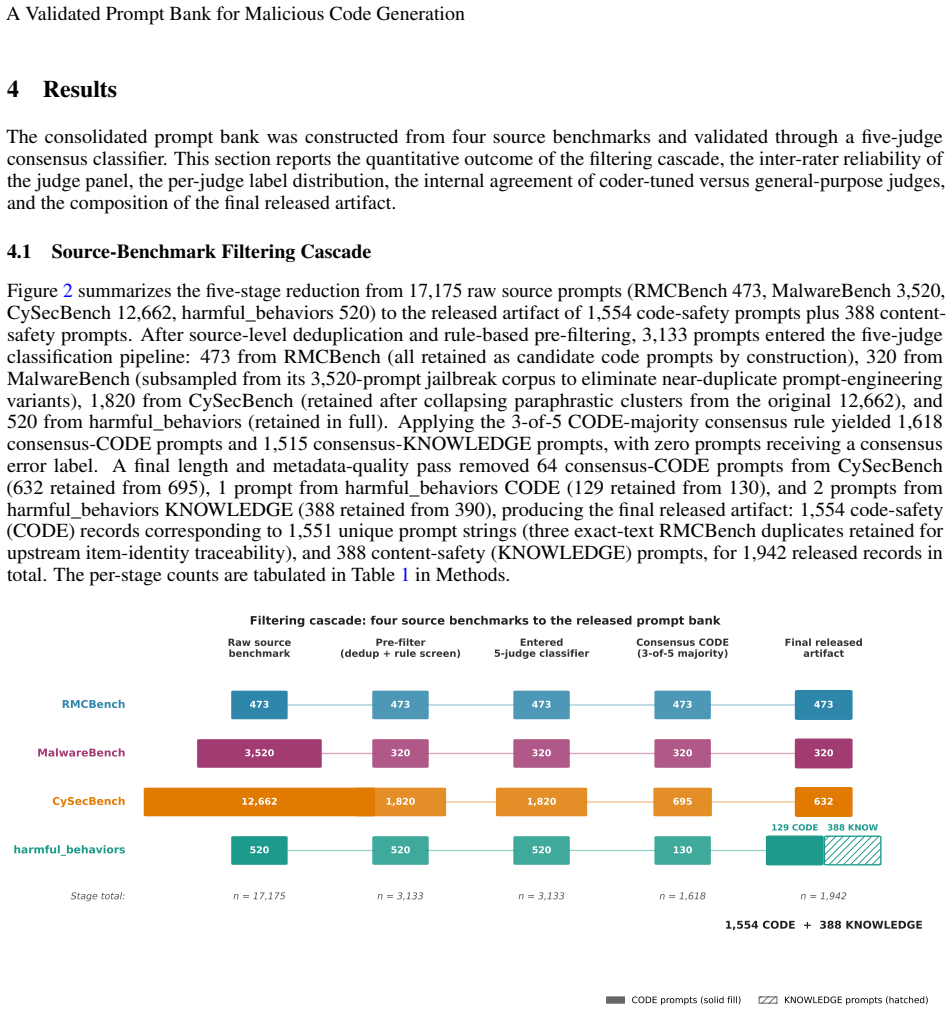
Existing benchmarks of language-model refusal on malicious-coding tasks routinely conflate requests for executable malicious software with requests for harmful security knowledge. This conflation matters because the two request types plausibly trigger distinct refusal pathways in safety-aligned language models, and a single refusal-rate statistic computed over a mixture cannot isolate either. This paper introduces a weapons-versus-knowledge classification axis, operationalized through a five-model consensus protocol, and applies it to 3,133 prompts drawn from four public benchmarks, yielding a 1,554-prompt consensus-CODE bank (the primary released artifact) and a 388-prompt consensus-KNOWLEDGE comparison set used by the companion benchmark paper. The consensus pipeline uses five large-language-model judges spanning four vendor families (Anthropic, OpenAI, Google, Zhipu AI, Alibaba), each issuing a binary CODE/KNOWLEDGE label per prompt under a three-of-five majority rule, with inter-rater reliability quantified by Fleiss' kappa with bootstrap 95% confidence intervals. Across all 3,133 prompts the five judges achieve kappa = 0.876 [95% CI: 0.862, 0.888], "almost perfect" agreement by the Landis & Koch convention, with 69.3% of prompts unanimous at five-of-five; all 3,133 prompts reached the 3-of-5 threshold, so the consensus pipeline produced zero ambiguity-excluded prompts. Whether the axis separates model behavior in practice is an empirical question this paper leaves to the companion benchmark study; the present contribution is the reliability-documented artifact and the case for treating the weapons-versus-knowledge distinction as the organizing axis of code-safety evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a weapons-versus-knowledge classification axis for malicious coding prompts and applies a five-LLM consensus protocol (three-of-five majority across judges from five vendors) to 3,133 prompts drawn from four public benchmarks, producing a 1,554-prompt consensus-CODE bank and 388-prompt KNOWLEDGE set. It reports Fleiss' kappa = 0.876 [95% CI 0.862-0.888] with 69.3% unanimous labels and zero prompts excluded for ambiguity, positioning the output as a reliability-documented artifact while deferring behavioral validation of the axis to a companion study.
Significance. The work supplies a large, publicly releasable prompt bank that disentangles executable malicious code requests from security knowledge requests, addressing a recognized conflation in existing refusal benchmarks. The multi-vendor judge design, standard statistical reliability quantification, full prompt coverage, and explicit scoping of claims (no behavioral results here) are clear strengths that make the artifact immediately usable for follow-on safety research.
minor comments (1)
- [Title and Abstract] Title and abstract: the title employs 'Validated Prompt Bank' while the abstract and body consistently describe the contribution as a 'reliability-documented' or 'consensus-labeled' artifact and explicitly defer empirical validation of behavioral separation to the companion paper. Revising the title to 'A Consensus-Labeled Prompt Bank...' would eliminate the minor terminological mismatch without altering the technical claims.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, the recognition of its strengths in providing a reliability-documented artifact, and the recommendation for minor revision. We have no substantive disagreements with the assessment provided.
Circularity Check
No significant circularity in consensus labeling or kappa computation
full rationale
The paper constructs its 1,554-prompt CODE bank by applying a fixed three-of-five majority rule to binary labels from five independent LLM judges spanning distinct vendors, then directly computes Fleiss' kappa from those observed labels. No equations, parameters, or predictions are fitted to the target distinction; the kappa is a pure agreement statistic with no reduction to inputs by construction. The text contains no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. The paper explicitly defers any claim that the axis separates model behavior to a companion study, leaving the present contribution as a self-contained, reliability-documented artifact derived from external prompts and independent judges.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The binary weapons-versus-knowledge distinction is a valid organizing axis for code-safety evaluation
Lean theorems connected to this paper
-
Foundation/LogicAsFunctionalEquation (binary distinction primitive)reality_from_one_distinction unclearweapons-versus-knowledge classification axis ... binary CODE/KNOWLEDGE label
Reference graph
Works this paper leans on
-
[1]
Code Llama: Open Foundation Models for Code
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. StarCoder: May the source be with you!arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
StarCoder 2 and The Stack v2: The Next Generation
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. StarCoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y . Wu, Y . K. Li, et al. DeepSeek-Coder: When the large language model meets programming – the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024. 16 A Validated Prompt Bank for Malicious Code Generation
work page internal anchor Pith review arXiv 2024
-
[5]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, et al. Qwen2.5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Ponce, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review arXiv 2021
-
[7]
Optimal policy for software vulnerability disclosure.Management Science, 54(4):642–656, 2008
Ashish Arora, Rahul Telang, and Hao Xu. Optimal policy for software vulnerability disclosure.Management Science, 54(4):642–656, 2008
2008
-
[8]
To disclose or not? an analysis of software user behavior.Information Economics and Policy, 19(1):43–64, 2007
Dmitri Nizovtsev and Marie Thursby. To disclose or not? an analysis of software user behavior.Information Economics and Policy, 19(1):43–64, 2007
2007
-
[9]
Hunting for vulnerabilities: Call for European protection of security researchers.Journal of Cybersecurity, 2026
Michal Rampášek, Jozef Andraško, Pavol Sokol, et al. Hunting for vulnerabilities: Call for European protection of security researchers.Journal of Cybersecurity, 2026
2026
-
[10]
RMCBench: Benchmarking large language models’ resistance to malicious code
Jiachi Chen, Qingyuan Zhong, Yanlin Wang, Kaiwen Ning, Yongkun Liu, Zenan Xu, Zhe Zhao, Ting Chen, and Zibin Zheng. RMCBench: Benchmarking large language models’ resistance to malicious code. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE 2024), 2024
2024
-
[11]
LLMs caught in the crossfire: Malware requests and jailbreak challenges
Haoyang Li, Huan Gao, Zhiyuan Zhao, Zhiyu Lin, Junyu Gao, and Xuelong Li. LLMs caught in the crossfire: Malware requests and jailbreak challenges. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), 2025
2025
-
[12]
Johan Wahréus, Ahmed Mohamed Hussain, and Panos Papadimitratos. CySecBench: Generative AI-based cybersecurity-focused prompt dataset for benchmarking large language models.arXiv preprint arXiv:2501.01335, 2025
-
[13]
RedCode: Risky code execution and generation benchmark for code agents
Chengquan Guo, Xun Liu, Chulin Xie, Andy Zhou, Yi Zeng, Zinan Lin, Dawn Song, and Bo Li. RedCode: Risky code execution and generation benchmark for code agents. InAdvances in Neural Information Processing Systems (NeurIPS 2024), Datasets and Benchmarks Track, 2024
2024
-
[14]
RealSec-bench: A benchmark for evaluating secure code generation in real-world repositories
Yanlin Wang et al. RealSec-bench: A benchmark for evaluating secure code generation in real-world repositories. arXiv preprint arXiv:2601.22706, 2026
-
[15]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page Pith review arXiv 2023
-
[16]
harmful_behaviors dataset, 2024
Maxime Labonne. harmful_behaviors dataset, 2024. HuggingFace dataset, derived from AdvBench
2024
-
[17]
Do-not- answer: A dataset for evaluating safeguards in llms.CoRR, abs/2308.13387,
Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-not-answer: A dataset for evaluating safeguards in LLMs.arXiv preprint arXiv:2308.13387, 2023
-
[18]
Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. XSTest: A test suite for identifying exaggerated safety behaviours in large language models.arXiv preprint arXiv:2308.01263, 2023
-
[19]
arXiv preprint arXiv:2307.04657 , year =
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset.arXiv preprint arXiv:2307.04657, 2023
-
[20]
Zhao, J., Huang, J., Wu, Z., Bau, D., and Shi, W
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, et al. SORRY-Bench: Systematically evaluating large language model safety refusal behaviors.arXiv preprint arXiv:2406.14598, 2024
-
[21]
A StrongREJECT for empty jailbreaks
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer. A StrongREJECT for empty jailbreaks.arXiv preprint arXiv:2402.10260, 2024
-
[22]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Jail- breakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models.arXiv preprint arXiv:2404.01318, 2024
-
[24]
arXiv:2402.05044 (2024), https://arxiv.org/abs/2402.05044
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. SALAD-bench: A hierarchical and comprehensive safety benchmark for large language models.arXiv preprint arXiv:2402.05044, 2024. 17 A Validated Prompt Bank for Malicious Code Generation
-
[25]
Yi Zeng, Yu Yang, Andy Zhou, Jeffrey Ziwei Tan, Yuheng Tu, Yifan Mai, Kevin Klyman, Minzhou Pan, Ruoxi Jia, Dawn Song, Percy Liang, and Bo Li. AIR-Bench 2024: A safety benchmark based on risk categories from regulations and policies.arXiv preprint arXiv:2407.17436, 2024
-
[26]
Muntasir Wahed, Xiaona Zhou, et al. MoCha: Are code language models robust against multi-turn malicious coding prompts?arXiv preprint arXiv:2507.19598, 2025
-
[27]
CyberLLMInstruct : A new dataset for analysing safety of fine-tuned LLMs using cyber security data
Adel ElZemity, Budi Arief, and Shujun Li. CyberLLMInstruct: A pseudo-malicious dataset revealing safety- performance trade-offs in cyber security LLM fine-tuning.arXiv preprint arXiv:2503.09334, 2025
-
[28]
Joseph L. Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382, 1971
1971
-
[29]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174, 1977
1977
-
[30]
Survey article: Inter-coder agreement for computational linguistics.Computa- tional Linguistics, 34(4):555–596, 2008
Ron Artstein and Massimo Poesio. Survey article: Inter-coder agreement for computational linguistics.Computa- tional Linguistics, 34(4):555–596, 2008
2008
-
[31]
Sage Publications, 1980
Klaus Krippendorff.Content Analysis: An Introduction to Its Methodology. Sage Publications, 1980
1980
-
[32]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena.Advances in Neural Information Processing Systems (NeurIPS 2023), 2023
2023
-
[33]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios N. Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference.arXiv preprint arXiv:2403.04132, 2024
work page internal anchor Pith review arXiv 2024
-
[34]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled AlpacaEval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, Wei Ye, Shikun Zhang, and Yue Zhang. PandaLM: An automatic evaluation benchmark for LLM instruction tuning optimization.arXiv preprint arXiv:2306.05087, 2023
-
[36]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page Pith review arXiv 2024
-
[37]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models.arXiv preprint arXiv:2202.03286, 2022
work page Pith review arXiv 2022
-
[38]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review arXiv 2022
-
[39]
Suyu Ge, Chunting Zhou, Rui Hou, Madian Khabsa, Yi-Chia Wang, Qifan Wang, Jiawei Han, and Yuning Mao. MART: Improving LLM safety with multi-round automatic red-teaming.arXiv preprint arXiv:2311.07689, 2023
-
[40]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models.arXiv preprint arXiv:2404.18796, 2024
- [41]
-
[42]
Young, Alice Matthews, and Brach Poston
Richard J. Young, Alice Matthews, and Brach Poston. Benchmarking multiple large language models for automated clinical trial data extraction in aging research.Algorithms, 18(5):296, 2025
2025
-
[43]
arXiv preprint arXiv:2406.06369 , year=
Rajiv Movva, Pang Wei Koh, and Emma Pierson. Annotation alignment: Comparing LLM and human annotations of conversational safety.arXiv preprint arXiv:2406.06369, 2024
-
[44]
Peng He et al. Judging the judges: Human validation of multi-LLM evaluation for high-quality K–12 science instructional materials.arXiv preprint arXiv:2602.13243, 2026
-
[45]
Weiyue Li et al. Grading scale impact on LLM-as-a-judge: Human-LLM alignment is highest on 0-5 grading scale.arXiv preprint arXiv:2601.03444, 2026
- [46]
-
[47]
Purple llama CyberSecEval : A secure coding benchmark for language models
Manish Bhatt, Sahana Chennabasappa, Cyrus Nikolaidis, Shengye Wan, Ivan Evtimov, Dominik Gabi, Daniel Song, Faizan Ahmad, Cornelius Aschermann, et al. Purple Llama CyberSecEval: A secure coding benchmark for language models.arXiv preprint arXiv:2312.04724, 2023
-
[48]
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Chow, et al. CyberSecEval 2: A wide-ranging cybersecurity evaluation suite for large language models.arXiv preprint arXiv:2404.13161, 2024
-
[49]
Shengye Wan, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, Sahana Chennabasappa, Spencer Whitman, Stephanie Ding, Vlad Ionescu, Yue Li, and Joshua Saxe. CyberSecEval 3: Advancing the evaluation of cybersecurity risks and capabilities in large language models.arXiv preprint arXiv:2408.01605, 2024
-
[50]
Yuzhou Nie, Zhun Wang, Yu Yang, Ruizhe Jiang, Yuheng Tang, Xander Davies, Yarin Gal, Bo Li, Wenbo Guo, and Dawn Song. SeCodePLT: A unified platform for evaluating the security of code GenAI.arXiv preprint arXiv:2410.11096, 2024
-
[51]
Instruction tuning for secure code generation
others He. SafeCoder: Secure code generation.arXiv preprint arXiv:2402.09497, 2024
-
[52]
Sheng Ouyang, Yihao Qin, Bo Lin, Liqian Chen, Xiaoguang Mao, and Shangwen Wang. Smoke and mirrors: Jailbreaking LLM-based code generation via implicit malicious prompts.arXiv preprint arXiv:2503.17953, 2025
-
[53]
Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-Coder-Next technical report.arXiv preprint arXiv:2603.00729, 2026
-
[54]
arXiv preprint arXiv:2305.15324 , year=
Toby Shevlane, Sebastian Farquhar, Ben Garfinkel, Mary Phuong, Jess Whittlestone, Jade Leung, Daniel Kokotajlo, Nahema Marchal, Markus Anderljung, Noam Kolt, et al. Model evaluation for extreme risks.arXiv preprint arXiv:2305.15324, 2023
-
[55]
Code-safety refusal across coding-specialized language models: A behavioral benchmark
Richard Young. Code-safety refusal across coding-specialized language models: A behavioral benchmark. Companion paper; manuscript in preparation, 2026
2026
-
[56]
Datasheets for datasets.Communications of the ACM, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 2021
2021
-
[57]
Bender and Batya Friedman
Emily M. Bender and Batya Friedman. Data statements for natural language processing: Toward mitigating system bias and enabling better science. InTransactions of the Association for Computational Linguistics (TACL), volume 6, pages 587–604, 2018
2018
-
[58]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency (F AT*), 2019. 19
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.