Recognition: unknown
UnAC: Adaptive Visual Prompting with Abstraction and Stepwise Checking for Complex Multimodal Reasoning
Pith reviewed 2026-05-07 17:29 UTC · model grok-4.3
The pith
UnAC improves complex multimodal reasoning in LMMs by combining adaptive visual prompting, image abstraction, and gradual self-checking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
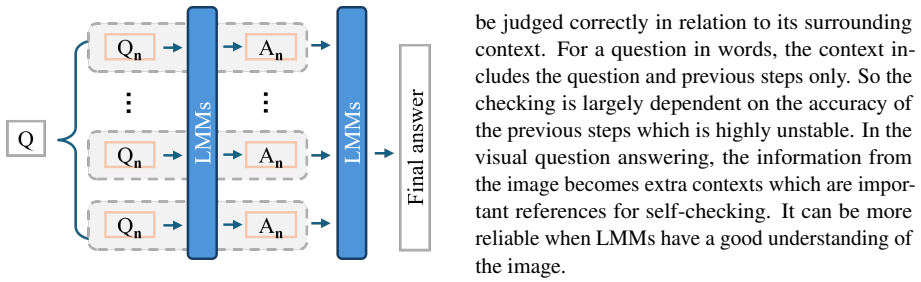
UnAC strengthens reasoning for complex multimodal tasks in LMMs through an adaptive visual prompting strategy that focuses on salient regions, an image-abstraction prompt that extracts key information, and a gradual self-checking scheme that verifies each decomposed subquestion and its answer.
What carries the argument
The UnAC prompting pipeline with its three components: adaptive visual prompting to highlight salient regions, image-abstraction prompts to capture essential details, and gradual self-checking to verify subquestions step by step.
Load-bearing premise
The gains come from the new prompting components causally strengthening reasoning rather than simply drawing out capabilities the models already possess on these benchmarks.
What would settle it
Ablation experiments on the same benchmarks that remove one UnAC component at a time and find no statistically significant drop in accuracy would show the components are not responsible for the reported improvements.
Figures


read the original abstract
Although recent LMMs have become much stronger at visual perception, they remain unreliable on problems that require multi-step reasoning over visual evidence. In this paper, we present UnAC (Understanding, Abstracting, and Checking), a multimodal prompting method that strengthens reasoning for complex multimodal tasks in LMMs (e.g., GPT-4o, Gemini 1.5, and GPT-4V). To improve image understanding and capture fine details, we propose an adaptive visual prompting strategy that enables LMMs to focus on salient regions. We further design an image-abstraction prompt to effectively extract key information from images. In addition, we introduce a gradual self-checking scheme that improves reasoning by verifying each decomposed subquestion and its answer. Extensive experiments on three public benchmarks-MathVista, MM-Vet, and MMMU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UnAC (Understanding, Abstracting, and Checking), a multimodal prompting framework for large multimodal models (LMMs) such as GPT-4o, Gemini 1.5, and GPT-4V. It consists of three components: an adaptive visual prompting strategy to focus on salient image regions for better understanding, an image-abstraction prompt to extract key information, and a gradual self-checking scheme to verify each decomposed subquestion and answer. The central claim is that these prompting heuristics strengthen reasoning on complex multimodal tasks, supported by experiments on the MathVista, MM-Vet, and MMMU benchmarks.
Significance. If the empirical results demonstrate consistent, attributable gains over strong baselines, UnAC would represent a practical, training-free contribution to prompt engineering for visual reasoning in LMMs. The structured decomposition and verification steps address a known weakness in current models on multi-step visual problems, and the approach is general enough to apply across multiple frontier LMMs.
major comments (2)
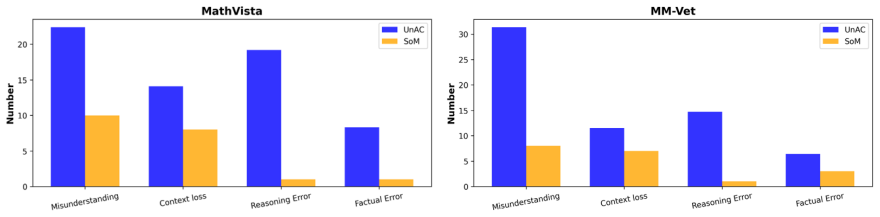
- [Abstract] Abstract: The text states that 'extensive experiments' were conducted on MathVista, MM-Vet, and MMMU yet reports no quantitative results, baseline comparisons, ablation studies, error bars, or statistical significance. Because the central claim is that the three prompting components causally improve reasoning, the absence of these data is load-bearing and prevents verification of the claim.
- [Abstract] The manuscript positions the gains as arising from the specific design of adaptive visual prompting, image abstraction, and gradual self-checking rather than generic prompt lengthening or structuring. Without controls that isolate these components (e.g., a generic chain-of-thought or longer-prompt baseline), it is impossible to rule out that any observed improvement is merely elicitation from already-capable models.
minor comments (1)
- [Abstract] The final sentence of the abstract is truncated ('Extensive experiments on three public benchmarks-MathVista, MM-Vet, and MMMU.') and should be completed with a concise statement of the observed outcomes.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the emphasis on making the abstract self-contained and on isolating the contributions of our proposed components. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The text states that 'extensive experiments' were conducted on MathVista, MM-Vet, and MMMU yet reports no quantitative results, baseline comparisons, ablation studies, error bars, or statistical significance. Because the central claim is that the three prompting components causally improve reasoning, the absence of these data is load-bearing and prevents verification of the claim.
Authors: We agree that the abstract should summarize the key quantitative outcomes to support the central claims. The full manuscript reports results on MathVista, MM-Vet, and MMMU with baseline comparisons and component-wise ablations. We will revise the abstract to include representative accuracy improvements, mention of the baselines used, and a brief reference to the ablation findings. We will also ensure that variance or statistical details from the main experiments are referenced or added to the abstract where space permits. revision: yes
-
Referee: [Abstract] The manuscript positions the gains as arising from the specific design of adaptive visual prompting, image abstraction, and gradual self-checking rather than generic prompt lengthening or structuring. Without controls that isolate these components (e.g., a generic chain-of-thought or longer-prompt baseline), it is impossible to rule out that any observed improvement is merely elicitation from already-capable models.
Authors: The three components target distinct failure modes (region focus, information condensation, and incremental verification) that generic lengthening does not address. The manuscript already contains ablation studies that remove each component individually and measure the resulting drops. To further isolate effects from generic prompting, we will add explicit comparisons against a standard chain-of-thought baseline and a length-matched generic prompt in the revised version. revision: yes
Circularity Check
No significant circularity; empirical prompting heuristics
full rationale
The paper describes UnAC as a set of prompting heuristics (adaptive visual prompting, image-abstraction prompts, gradual self-checking) for LMMs, evaluated empirically on external benchmarks (MathVista, MM-Vet, MMMU). No equations, fitted parameters, derivations, or first-principles claims are present. Claims rest on experimental gains rather than any internal reduction to inputs by construction. No self-definitional, fitted-prediction, or self-citation load-bearing patterns apply. This is the expected non-finding for a prompting-methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LMMs possess latent reasoning ability that can be elicited by structured prompting
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[8]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[9]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[10]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[11]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of artificial general intelligence: Early experiments with gpt-4 , author=. arXiv preprint arXiv:2303.12712 , year=
work page internal anchor Pith review arXiv
-
[12]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[13]
Palm 2 technical report , author=. arXiv preprint arXiv:2305.10403 , year=
work page internal anchor Pith review arXiv
-
[14]
Advances in Neural Information Processing Systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Focalclick: Towards practical interactive image segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
Semantic-sam: Segment and recognize anything at any granularity
Semantic-sam: Segment and recognize anything at any granularity , author=. arXiv preprint arXiv:2307.04767 , year=
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
What does clip know about a red circle? visual prompt engineering for vlms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
The dawn of lmms: Preliminary explorations with gpt-4v (ision)
The dawn of lmms: Preliminary explorations with gpt-4v (ision) , author=. arXiv preprint arXiv:2309.17421 , volume=
-
[19]
Take a step back: evoking reasoning via abstraction in large language models
Take a step back: Evoking reasoning via abstraction in large language models , author=. arXiv preprint arXiv:2310.06117 , year=
-
[20]
Selfcheck: Using llms to zero-shot check their own step-by-step reasoning , author=. arXiv preprint arXiv:2308.00436 , year=
-
[21]
arXiv preprint arXiv:2304.03284 , year=
Seggpt: Segmenting everything in context , author=. arXiv preprint arXiv:2304.03284 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Segment everything everywhere all at once , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
arXiv preprint arXiv:2311.17076 , year=
Compositional chain-of-thought prompting for large multimodal models , author=. arXiv preprint arXiv:2311.17076 , year=
-
[25]
A Survey on In-context Learning
A survey on in-context learning , author=. arXiv preprint arXiv:2301.00234 , year=
work page internal anchor Pith review arXiv
-
[26]
Advances in Neural Information Processing Systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v , author=. arXiv preprint arXiv:2310.11441 , year=
work page internal anchor Pith review arXiv
-
[28]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[29]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review arXiv
-
[30]
Advances in Neural Information Processing Systems , volume=
Deductive verification of chain-of-thought reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. arXiv preprint arXiv:2308.02490 , year=
work page internal anchor Pith review arXiv
-
[32]
Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. arXiv preprint arXiv:2311.16502 , year=
-
[33]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. arXiv preprint arXiv:2310.02255 , year=
work page internal anchor Pith review arXiv
-
[34]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Visual chatgpt: Talking, drawing and editing with visual foundation models , author=. arXiv preprint arXiv:2303.04671 , year=
work page internal anchor Pith review arXiv
-
[35]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Llama-adapter: Efficient fine-tuning of language models with zero-init attention , author=. arXiv preprint arXiv:2303.16199 , year=
-
[36]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review arXiv
-
[37]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[38]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review arXiv
-
[39]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review arXiv
-
[40]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review arXiv
-
[41]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review arXiv
-
[42]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review arXiv
-
[43]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[44]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models, 2024
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models , author=. arXiv preprint arXiv:2406.09403 , year=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Compositional chain-of-thought prompting for large multimodal models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.