Recognition: unknown
Balanced Aggregation: Understanding and Fixing Aggregation Bias in GRPO
Pith reviewed 2026-05-10 14:49 UTC · model grok-4.3
The pith
Balanced Aggregation fixes GRPO bias by averaging token gradients separately in positive and negative groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
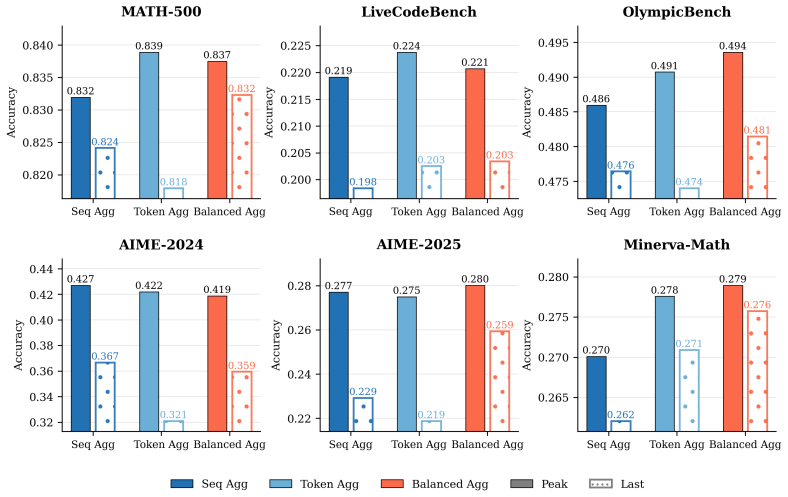
Token aggregation introduces sign-length coupling while sequence aggregation implicitly downweights longer responses through sequence-level equal weighting; Balanced Aggregation removes both effects by computing token-level means separately within the positive and negative subsets and then combining them with sequence-count-based weights.
What carries the argument
Balanced Aggregation (BA), which computes token-level means separately within the positive and negative subsets and combines them with sequence-count-based weights.
If this is right
- Training stability improves across runs that differ in response-length distribution.
- Final performance rises on reasoning and coding benchmarks relative to both token and sequence aggregation baselines.
- The relative advantage of token versus sequence aggregation is governed by the amount of response-length variation and the length gap between positive and negative examples.
- Aggregation rule becomes an explicit, tunable design dimension in GRPO-style RLVR.
Where Pith is reading between the lines
- The same separation principle could be tested in other group-relative RL algorithms that currently use uniform aggregation.
- Controlling or stratifying training data by positive-negative length gap would let practitioners predict when BA yields the largest lift.
- Future RLVR papers should report length statistics for positive and negative groups to make aggregation effects comparable across studies.
Load-bearing premise
The observed performance gains are caused by removal of the identified aggregation biases rather than by incidental changes in gradient scale or effective learning rate.
What would settle it
An experiment that equalizes gradient norms between Balanced Aggregation and the two standard rules while preserving the positive-negative separation would show no remaining advantage if bias removal is not the operative mechanism.
Figures


read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a central paradigm for improving reasoning and code generation in large language models, and GRPO-style training is widely adopted for its simplicity and effectiveness. However, an important design choice remains underexplored: how token-level policy gradient terms are aggregated within each sampled group. Standard GRPO uses sequence aggregation, while recent work has advocated token aggregation as a better alternative. We show that these two rules induce different optimization biases: token aggregation introduces sign-length coupling, while sequence aggregation implicitly downweights longer responses through sequence-level equal weighting. To address this tension, we propose \textbf{Balanced Aggregation (BA)}, a simple drop-in replacement that computes token-level means separately within the positive and negative subsets and then combines them with sequence-count-based weights. Experiments with Qwen2.5-Math-7B and Qwen3-1.7B on DAPO-17k and Polaris, evaluated on six reasoning and coding benchmarks, show that BA consistently improves training stability and final performance over standard token and sequence aggregation. Our analysis further shows that the relative effectiveness of token and sequence aggregation is largely governed by response-length variation and the positive-negative length gap, highlighting aggregation as a critical design dimension in GRPO-style RLVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies aggregation biases in GRPO-style RLVR: token aggregation induces sign-length coupling while sequence aggregation downweights longer responses via equal weighting. It proposes Balanced Aggregation (BA) as a drop-in fix that computes separate token-level means over positive and negative subsets then reweights by sequence counts. Experiments on Qwen2.5-Math-7B and Qwen3-1.7B trained on DAPO-17k and Polaris, evaluated across six reasoning and coding benchmarks, report that BA yields improved training stability and final performance relative to standard token and sequence aggregation.
Significance. If the gains can be attributed specifically to bias removal, the work would usefully spotlight an under-examined design choice in policy-gradient aggregation for verifiable-reward RL. The proposal is simple and the evaluation spans two model scales and two datasets, which strengthens the practical case. The analysis tying relative effectiveness to response-length statistics is a constructive contribution. However, without controls that isolate mechanism from scale, the significance remains provisional.
major comments (2)
- [Experiments] Experiments section: the direct comparisons of BA against token and sequence aggregation do not include gradient-norm matching, learning-rate rescaling, or scale-controlled ablations. Different aggregation operators alter the magnitude of the summed policy gradient, so the reported stability and benchmark gains cannot be confidently attributed to removal of sign-length coupling or length downweighting rather than incidental changes in effective update scale.
- [Results] Results: no error bars, statistical significance tests, or quantitative effect sizes are reported for the claimed consistent improvements in stability and performance. This weakens the ability to assess reliability of the central empirical claim.
minor comments (1)
- [Abstract] Abstract: the statement that BA 'consistently improves' would be more informative if accompanied by concrete metrics or relative gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the attribution of our empirical results. We address each major comment below and have revised the manuscript to incorporate additional controls and statistical reporting.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the direct comparisons of BA against token and sequence aggregation do not include gradient-norm matching, learning-rate rescaling, or scale-controlled ablations. Different aggregation operators alter the magnitude of the summed policy gradient, so the reported stability and benchmark gains cannot be confidently attributed to removal of sign-length coupling or length downweighting rather than incidental changes in effective update scale.
Authors: We agree that isolating the effect of bias removal from incidental changes in gradient magnitude is important for causal attribution. In the revised manuscript, we have added scale-controlled ablations: we normalize the summed policy gradient norms to match across the three aggregation methods and rescale the learning rate to preserve comparable update magnitudes. These experiments, now included in the Experiments section, show that Balanced Aggregation retains its advantages in training stability and final benchmark performance. We have also added a brief analysis of per-method gradient norms to the paper. revision: yes
-
Referee: [Results] Results: no error bars, statistical significance tests, or quantitative effect sizes are reported for the claimed consistent improvements in stability and performance. This weakens the ability to assess reliability of the central empirical claim.
Authors: We acknowledge that the lack of variability measures and formal statistical tests limits the strength of the empirical claims. We have rerun the main experiments across multiple random seeds, added standard-deviation error bars to all benchmark tables and training curves, and included paired t-test p-values together with Cohen's d effect sizes for the reported improvements. These additions appear in the revised Results section and the associated figures. revision: yes
Circularity Check
No circularity: derivation and proposal are self-contained algorithmic definitions
full rationale
The paper derives the two identified biases directly from the explicit definitions of token aggregation (sign-length coupling via per-token means) and sequence aggregation (length downweighting via equal sequence weighting). BA is introduced as an independent operator that splits positive/negative subsets and reweights by sequence counts; this is not equivalent to either baseline by construction. No equations reduce a 'prediction' to a fitted parameter, no uniqueness theorem is imported, and no self-citation chain carries the central claim. Experiments provide external empirical validation on held-out benchmarks rather than internal consistency checks. The derivation chain therefore remains non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sign of the advantage for a token is independent of response length in the desired optimum.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Polaris: A post-training recipe for scaling reinforcement learning on advanced reasoning models, 2025
HKU NLP Group, ByteDance Seed, and Fudan University. Polaris: A post-training recipe for scaling reinforcement learning on advanced reasoning models, 2025. URL https://hkunlp. github.io/blog/2025/Polaris/
2025
-
[3]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[4]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InAnnual Meeting of the Association for Computational Linguistics, 2024
2024
-
[5]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida I. Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024. URL https://arxiv.org/abs/ 2403.07974
work page internal anchor Pith review arXiv 2024
-
[6]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S. Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling re- inforcement learning compute for llms, 2025. URL https://arxiv.org/abs/2510.13786
-
[7]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Venkatesh Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models, 2022. URLhttps://arxiv.org/abs/2206.14858
work page internal anchor Pith review arXiv 2022
-
[8]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review arXiv 2023
-
[9]
When speed kills stability: Demystifying RL collapse from the training-inference mismatch, sep 2025
Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Yu Shen. When speed kills stability: Demystifying RL collapse from the training-inference mismatch, sep 2025. URL https://richardli.xyz/rl-collapse
2025
-
[10]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective, 2025. URL https: //arxiv.org/abs/2503.20783
work page internal anchor Pith review arXiv 2025
-
[11]
Part i: Tricks or traps? a deep dive into rl for llm reasoning, 2025
Zihe Liu, Jiashun Liu, Yancheng He, Weixun Wang, Jiaheng Liu, Ling Pan, Xinyu Hu, Shaopan Xiong, Ju Huang, Jian Hu, Shengyi Huang, Johan Obando-Ceron, Siran Yang, Jiamang Wang, Wenbo Su, and Bo Zheng. Part i: Tricks or traps? a deep dive into rl for llm reasoning, 2025. URLhttps://arxiv.org/abs/2508.08221
-
[12]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. Stabilizing moe reinforcement learning by aligning training and inference routers, 2025. URL https://arxiv.org/abs/2510.11370
-
[13]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
MiniMax, :, Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chunhao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, Haimo Zhang, Han Ding, Haohai Sun, Haoyu Feng, Huaiguang 12 Cai, Haicha...
work page internal anchor Pith review arXiv 2025
-
[14]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondri...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Yiping Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, Daya Guo, Dejian Yang, Dejian Yang, and Ruoyu Zhang. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/ abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Opencompass: A universal evaluation platform for foundation models,
OpenCompass Team. Opencompass: A universal evaluation platform for foundation models,
- [18]
-
[19]
arXiv preprint arXiv:2510.06062 , year=
Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, and Kun Gai. Aspo: Asymmetric importance sampling policy optimization, 2025. URL https://arxiv.org/abs/2510.06062
-
[20]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024. URLhttps://arxiv.org/abs/2409.12122
work page internal anchor Pith review arXiv 2024
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Your efficient rl framework secretly brings you off-policy rl training, aug 2025
Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao. Your efficient rl framework secretly brings you off-policy rl training, aug 2025. URLhttps: //fengyao.notion.site/off-policy-rl
2025
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Scaling of search and learning: A roadmap to reproduce o1 from reinforcement learning perspective, 2024
Zhiyuan Zeng, Qinyuan Cheng, Zhangyue Yin, Bo Wang, Shimin Li, Yunhua Zhou, Qipeng Guo, Xuanjing Huang, and Xipeng Qiu. Scaling of search and learning: A roadmap to reproduce o1 from reinforcement learning perspective, 2024. URL https://arxiv.org/abs/2412. 14135
2024
-
[25]
Geometric-mean policy optimization,
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, Fang Wan, and Furu Wei. Geometric-mean policy optimization,
- [26]
-
[27]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. URLhttps://arxiv.org/abs/2507.18071
work page internal anchor Pith review arXiv 2025
-
[28]
Rloop: An self-improving framework for reinforcement learning with iterative policy initialization,
Zeng Zhiyuan, Jiashuo Liu, Zhangyue Yin, Ge Zhang, Wenhao Huang, and Xipeng Qiu. Rloop: An self-improving framework for reinforcement learning with iterative policy initialization,
-
[29]
URLhttps://arxiv.org/abs/2511.04285. 14 Appendix A: Why Use Sequence-Count Weights in BA? Here we briefly justify the choice of weights k/G and (G−k)/G in BA. Recall that under the binary-reward GRPO setting, the normalized advantages are ˆAi = r G−k k fori∈S +, ˆAi =− r k G−k fori∈S −.(24) Substituting these values into the BA objective gives JBA = k G r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.