Recognition: unknown
TSCG: Deterministic Tool-Schema Compilation for Agentic LLM Deployments
Pith reviewed 2026-05-08 17:35 UTC · model grok-4.3
The pith
Converting JSON tool schemas to structured text with eight deterministic operators restores high tool-use accuracy for small LLMs on large catalogs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
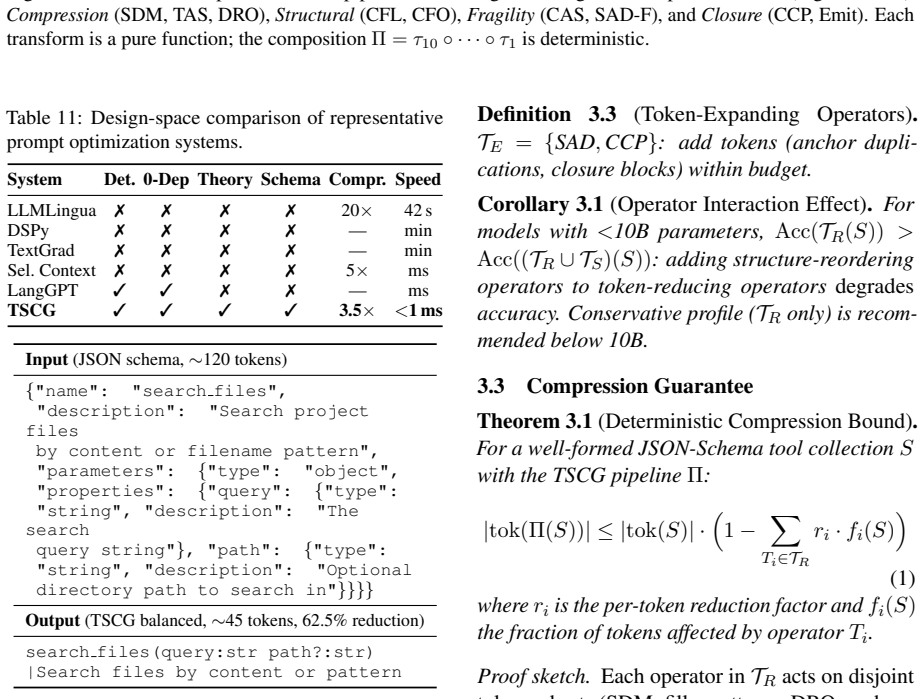
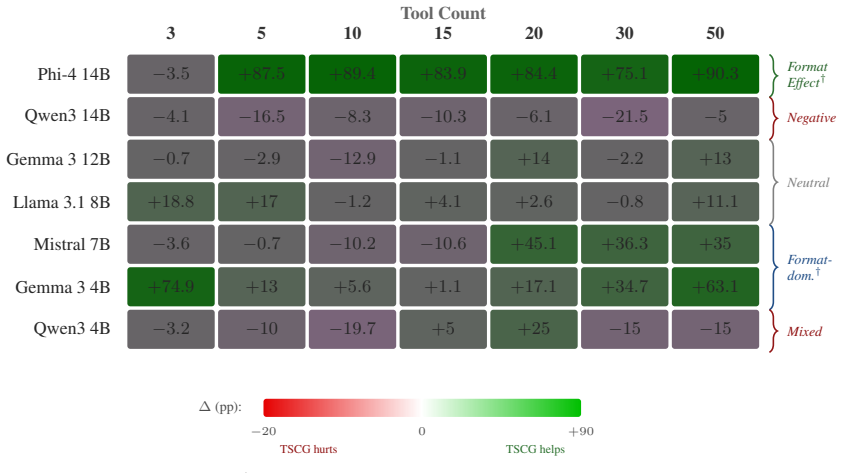
TSCG is a deterministic compiler that turns JSON tool schemas into structured text using eight composable operators and a formal compression bound of at least 51 percent. This change at the schema level resolves the dominant failure mode for small models in agentic tool use, as confirmed by per-operator isolation and format-versus-compression tests on thousands of calls across 12 models and 5 scenarios. The resulting accuracy and token-efficiency advantages hold on both synthetic and production MCP schemas.
What carries the argument
The eight composable operators that rewrite JSON schemas into structured text, supplying both the accuracy lift and the compression bound.
If this is right
- Small models achieve usable accuracy on production-scale tool sets of 20-50 tools.
- Token savings of 52-57 percent remain consistent even on heavy real-world schemas.
- Different models show distinct sensitivities to individual operators, enabling per-model compilation choices.
- Accuracy results on synthetic catalogs generalize to actual MCP schemas within 0.1 points.
- The method requires no per-model adjustments or runtime search.
Where Pith is reading between the lines
- Interface-level compilation could reduce reliance on larger models for agent workloads.
- The operator profiles suggest building lightweight schema adapters tailored to model families.
- Similar deterministic rewrites might improve LLM performance on other structured inputs such as API responses or configuration files.
- Longer-term deployment pipelines could treat schema format as a tunable parameter separate from model weights.
Load-bearing premise
The structured text created by the operators will be interpreted more reliably by LLMs than the original JSON across arbitrary models and schemas without introducing new parsing errors.
What would settle it
Testing TSCG output against the original JSON on an untested model or schema and finding no accuracy gain or an outright drop would falsify the claim that format change is the primary reliable mechanism.
Figures



read the original abstract
Production agent frameworks (OpenAI Function Calling, Anthropic Tool Use, MCP) transmit tool schemas as JSON, a format designed for machine parsing, not for interpretation by language models. For small models (4B-14B), this protocol mismatch accounts for the majority of tool-use failure at production catalog sizes. We present TSCG, a deterministic tool-schema compiler that resolves this mismatch at the API boundary, converting JSON schemas into token-efficient structured text without model access, fine-tuning, or runtime search. TSCG combines eight composable operators with a formal compression bound (>=51% on well-formed schemas). On TSCG-Agentic-Bench (about 19,000 calls, 12 models, 5 scenarios), TSCG restores Phi-4 14B from 0% to 84.4% accuracy at 20 tools (90.3% at 50 tools) and achieves 108-181% accuracy-retained ratio across three models on BFCL. Format-versus-compression decomposition (R^2=0.88 -> 0.03) establishes representation change as the dominant mechanism. Per-operator isolation across three frontier models reveals three distinct operator-response profiles: operator-hungry (Opus 4.7), operator-sensitive (GPT-5.2), and operator-robust (Sonnet 4), providing per-model deployment guidance. Scaling experiments show accuracy advantages persisting on heavy production MCP schemas (+5.0 pp at about 10,500 input tokens) despite saturation on light synthetic catalogs, with 52-57% token savings throughout. The synthetic benchmark generalizes to real MCP schemas within 0.1 accuracy points. TSCG ships as a 1,200-line zero-dependency TypeScript package.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSCG, a deterministic zero-dependency compiler that converts JSON tool schemas into structured text via eight composable operators, together with a formal compression bound of at least 51%. On TSCG-Agentic-Bench (~19k calls, 12 models) it reports restoring Phi-4 14B accuracy from 0% to 84.4% at 20 tools (90.3% at 50 tools), 108-181% accuracy-retained ratios on BFCL, and persistence of gains on heavy real MCP schemas; a format-versus-compression regression (R² 0.88 → 0.03) isolates representation change as the dominant mechanism, while per-operator profiles supply model-specific deployment guidance.
Significance. If the empirical results hold, the work supplies a practical, training-free intervention at the API boundary that directly addresses a documented failure mode for small-to-medium models in production agent frameworks. Notable strengths include the formal compression bound, the multi-model (12-model) validation, the explicit generalization test to real MCP schemas within 0.1 accuracy points, and the open 1,200-line TypeScript package that enables immediate reproducibility.
major comments (2)
- [§4.2] §4.2 (Benchmark Construction): the central accuracy claims (e.g., Phi-4 14B restoration to 84.4% at 20 tools) rest on ~19k calls across five scenarios; the manuscript must supply the precise accuracy metric definition, the full set of baseline controls (including any prompt or decoding variations), and statistical significance tests to confirm the lifts are not artifacts of benchmark construction.
- [§5.1] §5.1 (Format-versus-Compression Regression): the reported R² drop from 0.88 to 0.03 is used to establish representation change as dominant; confirm that the regression controls for token-length correlation and that the 52-57% token savings do not themselves explain the accuracy delta after the format variable is included.
minor comments (3)
- [Table 3] Table 3 (Per-operator profiles): label the three response profiles (operator-hungry, operator-sensitive, operator-robust) with explicit model names and include error bars or confidence intervals for the accuracy deltas.
- [§3] §3 (Operator Definitions): provide a compact pseudocode or formal grammar for the eight operators and their composition rules so that the deterministic guarantee can be verified without reading the full TypeScript source.
- [Figure 4] Figure 4 (Scaling on MCP schemas): clarify the input-token range (~10,500 tokens) and whether the +5.0 pp gain is measured against the same JSON baseline or an already-optimized prompt.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The two major comments identify areas where additional transparency will strengthen the paper. We address each point below and will incorporate the requested details and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Benchmark Construction): the central accuracy claims (e.g., Phi-4 14B restoration to 84.4% at 20 tools) rest on ~19k calls across five scenarios; the manuscript must supply the precise accuracy metric definition, the full set of baseline controls (including any prompt or decoding variations), and statistical significance tests to confirm the lifts are not artifacts of benchmark construction.
Authors: We agree that explicit documentation of the accuracy metric, controls, and significance testing is required for full reproducibility and to rule out benchmark artifacts. Accuracy is defined as the exact-match rate on tool name, parameter values, and output format against ground-truth invocations. All baselines used identical prompt templates (provided in the appendix) and greedy decoding (temperature = 0) with no sampling variations. In the revision we will expand §4.2 with (i) the formal metric definition, (ii) the complete prompt and decoding specifications, and (iii) McNemar’s test results for paired accuracy differences (all reported lifts p < 0.01). These additions directly address the concern. revision: yes
-
Referee: [§5.1] §5.1 (Format-versus-Compression Regression): the reported R² drop from 0.88 to 0.03 is used to establish representation change as dominant; confirm that the regression controls for token-length correlation and that the 52-57% token savings do not themselves explain the accuracy delta after the format variable is included.
Authors: The regression is hierarchical: token length is entered first as a covariate, after which the binary format indicator (TSCG vs. JSON) is added. The reported R² drop therefore already reflects incremental explanatory power of format after length is controlled. The 52–57 % token reduction is a direct consequence of the TSCG representation rather than an independent variable. In the revision we will add the full coefficient table, standard errors, and variance-inflation-factor diagnostics (all VIF < 2) to make the control explicit and to confirm that format accounts for the accuracy delta independently of length. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on empirical benchmark results from TSCG-Agentic-Bench (approximately 19,000 calls across 12 models) and BFCL, demonstrating accuracy restoration via deterministic JSON-to-structured-text conversion using eight operators. No mathematical derivation chain, fitted parameters renamed as predictions, or self-referential definitions appear; the format-versus-compression regression (R^2 drop from 0.88 to 0.03) and per-operator profiles are direct measurements on held-out data, independent of the compiler's definition. The formal compression bound and zero-dependency implementation provide separate support without reducing claims to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Input tool schemas are valid and well-formed JSON that can be parsed deterministically
Reference graph
Works this paper leans on
-
[1]
Anthropic . 2024. Introducing the Model Context Protocol . https://www.anthropic.com/news/model-context-protocol. Open standard for connecting AI assistants to data sources. Accessed: 2026-04-28
2024
-
[2]
Anthropic . 2025. Code execution with MCP: Building more efficient AI agents . https://www.anthropic.com/engineering/code-execution-with-mcp. Engineering blog post. Accessed: 2026-04-28
2025
-
[3]
Md Adnan Arefeen, Biplob Debnath, and Srimat Chakradhar. 2024. https://doi.org/10.1016/j.nlp.2024.100065 LeanContext : Cost-efficient domain-specific question answering using LLM s . Natural Language Processing Journal, 7:100065. ArXiv:2309.00841
-
[4]
Atlassian Labs . 2026. mcp-compressor: An MCP server wrapper for reducing tokens consumed by MCP tools . https://github.com/atlassian-labs/mcp-compressor. Open-source MCP proxy. Accessed: 2026-04-28
2026
-
[5]
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.232 Adapting language models to compress contexts . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3829--3846. Association for Computational Linguistics. ArXiv:2305.14788
-
[6]
Joong Ho Choi, Jiayang Zhao, Jeel Shah, Ritvika Sonawane, Mihir Sonawane, Navya Singh, Avani Appalla, Will Flanagan, and Filipe Condessa. 2025. https://arxiv.org/abs/2510.18043 CompactPrompt : A unified pipeline for prompt and data compression in LLM workflows . In 2nd Workshop on LLMs and Generative AI for Finance, ACM ICAIF '25, Singapore. ArXiv:2510.18...
-
[7]
Cloudflare . 2026. Code Mode: Bringing programmatic tool access to AI agents . https://blog.cloudflare.com/code-mode-mcp/. Engineering blog post. Accessed: 2026-04-28
2026
- [8]
-
[9]
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. 2024. https://openreview.net/forum?id=ZG3RaNIsO8 EvoPrompt : Connecting large language models with evolutionary algorithms yields powerful prompt optimizers . In The Twelfth International Conference on Learning Representations (ICLR). ArXiv:2309.08532
-
[10]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.825 LLMLingua : Compressing prompts for accelerated inference of large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358--13376. Association for Computational Linguist...
-
[11]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. https://aclanthology.org/2024.acl-long.91/ LongLLMLingua : Accelerating and enhancing LLM s in long context scenarios via prompt compression . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
-
[12]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. https://arxiv.org/abs/2310.03714 DSPy : Compiling declarative language model calls into self-improving pipelines . arXiv preprint arXiv:2310.03714
work page internal anchor Pith review arXiv 2023
-
[13]
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023. Compressing context to enhance inference efficiency of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6342--6353. Association for Computational Linguistics. ArXiv:2310.06201
-
[14]
Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Collier. 2025. https://doi.org/10.18653/v1/2025.naacl-long.368 Prompt compression for large language models: A survey . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7182...
-
[15]
Jesse Mu, Xiang Lisa Li, and Noah Goodman. 2023. https://papers.nips.cc/paper_files/paper/2023/hash/3d77c6dcc7f143aa2154e7f4d5e22d68-Abstract-Conference.html Learning to compress prompts with gist tokens . In Advances in Neural Information Processing Systems, volume 36. ArXiv:2304.08467
-
[16]
In: Findings of the Association for Computational Linguistics: ACL 2024 (Aug 2024)
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor R \"u hle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.57 LLMLingua-2 : Data distillation for efficient and faithful task-agnostic prompt compression . In Findings of the Associatio...
-
[17]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. https://proceedings.mlr.press/v267/patil25a.html The Berkeley Function Calling Leaderboard (BFCL) : From tool use to agentic evaluation of large language models . In Proceedings of the 42nd International Conference on Machine Learning ...
2025
-
[18]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/e4c61f578ff07830f5c37378dd3ecb0d-Abstract-Conference.html Gorilla: Large language model connected with massive API s . In Advances in Neural Information Processing Systems, volume 37. ArXiv:2305.15334
work page internal anchor Pith review arXiv 2024
-
[19]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.494 Automatic prompt optimization with ``gradient descent'' and beam search . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957--7968. Association for Computational Linguistic...
-
[20]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ToolLLM : Facilitating large language models to master 16000+ real-world API s. In The Twelfth International Conference on...
work page internal anchor Pith review arXiv 2024
-
[21]
Tobias Schnabel and Jennifer Neville. 2024. https://aclanthology.org/2024.findings-emnlp.37/ Symbolic prompt program search: A structure-aware approach to efficient compile-time prompt optimization . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 670--686, Miami, Florida. Association for Computational Linguistics. SAMMO fr...
-
[22]
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. https://doi.org/10.18653/v1/P16-1162 Neural machine translation of rare words with subword units . In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715--1725. Association for Computational Linguistics
-
[23]
toon-format . 2025. TOON: Token-Oriented Object Notation Specification . https://github.com/toon-format/toon. GitHub: toon-format/toon. Accessed: 2026-04-28
2025
-
[24]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. https://papers.nips.cc/paper/7181-attention-is-all-you-need Attention is all you need . In Advances in Neural Information Processing Systems, volume 30, pages 5998--6008. ArXiv:1706.03762
work page internal anchor Pith review arXiv 2017
-
[25]
Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan \"O . Ar k, and Tomas Pfister. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.461 Universal self-adaptive prompting . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7437--7462. Association for Computational Linguistic...
-
[26]
Ming Wang, Yuanzhong Liu, Xiaoyu Liang, Songlian Li, Yijie Huang, Xiaoming Zhang, Sijia Shen, Chaofeng Guan, Daling Wang, Shi Feng, Huaiwen Zhang, Yifei Zhang, Minghui Zheng, and Chi Zhang. 2024 a . https://arxiv.org/abs/2402.16929 LangGPT : Rethinking structured reusable prompt design framework for large language models from the programming language pers...
-
[27]
Xinyuan Wang, Chenxi Li, Zhen Wang, Fan Bai, Haotian Luo, Jiayou Zhang, Nebojsa Jojic, Eric P. Xing, and Zhiting Hu. 2024 b . https://openreview.net/forum?id=22pyNMuIoa PromptAgent : Strategic planning with language models enables expert-level prompt optimization . In The Twelfth International Conference on Learning Representations (ICLR). ArXiv:2310.16427
-
[28]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. https://openreview.net/forum?id=NG7sS51zVF Efficient streaming language models with attention sinks . In The Twelfth International Conference on Learning Representations (ICLR). ArXiv:2309.17453
work page internal anchor Pith review arXiv 2024
-
[29]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2024. https://openreview.net/forum?id=Bb4VGOWELI Large language models as optimizers . In The Twelfth International Conference on Learning Representations (ICLR). ArXiv:2309.03409
-
[30]
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. 2025. https://www.nature.com/articles/s41586-025-08661-4 Optimizing generative AI by backpropagating language model feedback . Nature, 639:609--616. Preprint available as arXiv:2406.07496 ``TextGrad: Automatic Differentiation via Text''
work page internal anchor Pith review arXiv 2025
-
[31]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. https://openreview.net/forum?id=92gvk82DE- Large language models are human-level prompt engineers . In The Eleventh International Conference on Learning Representations (ICLR). ArXiv:2211.01910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.