Recognition: unknown
SWAN: Semantic Watermarking with Abstract Meaning Representation
Pith reviewed 2026-05-08 16:56 UTC · model grok-4.3
The pith
Watermarks encoded in sentence meaning graphs remain detectable after rephrasing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
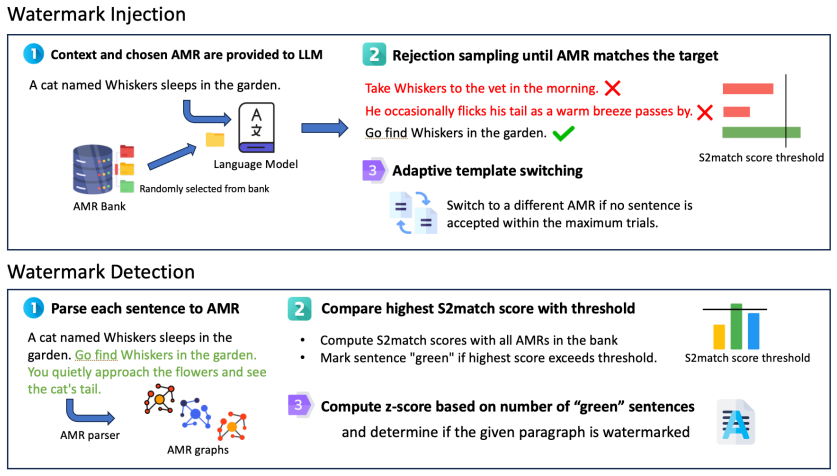
SWAN embeds watermark signatures into the semantic structure of a sentence using Abstract Meaning Representation. Watermark injection is achieved by prompting an LLM to generate sentences guided by a selected AMR template while maintaining contextual coherence, and detection uses an off-the-shelf AMR parser followed by a simple one-proportion z-test. This yields matching state-of-the-art detection performance on unaltered watermarked text while increasing detection AUC by up to 13.9 percentage points under paraphrasing on the RealNews benchmark.
What carries the argument
Abstract Meaning Representation (AMR) graphs, which encode sentence semantics as a structured graph; the watermark is carried by the choice of template graph so that any meaning-preserving paraphrase produces the same graph and thus the same detectable signature.
If this is right
- Detection performance on original text equals leading token-selection watermark methods.
- Robustness to paraphrasing rises by as much as 13.9 AUC points on news-domain text.
- Both embedding and verification require no model training and work with ordinary language models and parsers.
- The watermark lives at the semantic level, so stylistic edits that keep meaning leave it intact.
Where Pith is reading between the lines
- Similar watermarking could be attempted with any semantic parser shown to stay consistent across rephrasings.
- The approach may prove useful for provenance checks in news or academic writing, where rewording for clarity is routine.
- Experiments comparing AMR stability across different parsers and domains would clarify how widely the method applies.
Load-bearing premise
The AMR parser returns the same graph for any two sentences that express the same meaning.
What would settle it
A collection of meaning-preserving paraphrases of watermarked sentences for which the AMR parser returns inconsistent graphs, causing the z-test to miss the watermark at the reported rates.
Figures


read the original abstract
We introduce SWAN (Semantic Watermarking with Abstract Meaning Representation), a novel framework that embeds watermark signatures into the semantic structure of a sentence using Abstract Meaning Representation (AMR). In contrast to existing watermarking methods, which typically encode signatures by adjusting token selection preferences during text generation, SWAN embeds the signature directly in the sentence's semantic representation. As the signature is encoded at the semantic structure level, any paraphrase that preserves meaning automatically preserves the signature. SWAN is training-free: watermark injection is achieved by prompting an LLM to generate sentences guided by a selected AMR template while maintaining contextual coherence, and detection uses an off-the-shelf AMR parser followed by a simple one-proportion z-test. Empirical evaluation on the RealNews benchmark shows SWAN matches state-of-the-art detection performance on unaltered watermarked text, while significantly improving robustness against paraphrasing, increasing detection AUC by up to 13.9 percentage points compared to prior methods. These results demonstrate that SWAN's approach of anchoring watermarks in AMR semantic structures provides a simple, effective, and prompt-based method for robust text provenance verification under paraphrasing, opening new avenues for semantic-level watermarking research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWAN, a training-free semantic watermarking method that selects an AMR template, prompts an LLM to realize it in contextually coherent text, and detects the watermark by parsing the output (or its paraphrase) with an off-the-shelf AMR parser followed by a one-proportion z-test on template match. On RealNews, SWAN matches prior SOTA detection AUC on unaltered watermarked text while reporting gains of up to 13.9 AUC points under paraphrasing.
Significance. If the central robustness result holds after addressing parser invariance, the work demonstrates a simple prompt-based route to semantic-level watermarking that is invariant to meaning-preserving edits by construction. This is a clear advance over token-level methods for provenance tasks where paraphrasing is expected, and the training-free nature plus use of existing AMR tools lowers the barrier to adoption.
major comments (2)
- [§4 and §4.2] §4 (Experimental Evaluation) and §4.2 (Paraphrasing Robustness): The reported 13.9 AUC gain under paraphrasing is load-bearing for the central claim, yet the manuscript contains no parser-agreement statistics (e.g., graph-edit distance or exact-match rate) between original and paraphrased watermarked sentences on the RealNews set, nor any ablation that isolates AMR-parser invariance from the watermarking effect itself. Without this, it is impossible to determine whether the robustness improvement arises from semantic anchoring or from the particular parser-paraphraser interaction.
- [§3.2] §3.2 (Detection Procedure): The z-test is performed on the proportion of recovered AMR graphs that match the chosen template, but the manuscript does not specify how the null distribution is constructed, what constitutes a “match,” or how multiple candidate templates are handled when the parser returns a graph that could align with more than one template; these choices directly affect the reported AUC numbers.
minor comments (2)
- [Abstract and §4] The abstract and §4 omit the exact AMR parser version, the paraphraser model, and the full set of baselines used for the “state-of-the-art” comparison; adding these details would improve reproducibility.
- [Results table] Table 1 (or equivalent results table) reports AUC values but does not include standard deviations across random seeds or template choices, making it difficult to assess whether the 13.9-point margin is statistically reliable.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the clarity and rigor of our experimental claims and detection procedure. We address each major comment below and will make the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [§4 and §4.2] §4 (Experimental Evaluation) and §4.2 (Paraphrasing Robustness): The reported 13.9 AUC gain under paraphrasing is load-bearing for the central claim, yet the manuscript contains no parser-agreement statistics (e.g., graph-edit distance or exact-match rate) between original and paraphrased watermarked sentences on the RealNews set, nor any ablation that isolates AMR-parser invariance from the watermarking effect itself. Without this, it is impossible to determine whether the robustness improvement arises from semantic anchoring or from the particular parser-paraphraser interaction.
Authors: We agree that additional parser-agreement statistics and an isolating ablation would strengthen the central robustness claim. In the revised manuscript we will add these analyses: (i) quantitative agreement metrics (graph-edit distance and exact-match rate) between AMR parses of the original watermarked sentences and their paraphrases on the RealNews set, and (ii) an ablation that reports detection AUC on paraphrased text when the parser is given the correct generation template versus randomly chosen templates. These additions will allow readers to separate the contribution of semantic anchoring from any parser-paraphraser interaction effects. revision: yes
-
Referee: [§3.2] §3.2 (Detection Procedure): The z-test is performed on the proportion of recovered AMR graphs that match the chosen template, but the manuscript does not specify how the null distribution is constructed, what constitutes a “match,” or how multiple candidate templates are handled when the parser returns a graph that could align with more than one template; these choices directly affect the reported AUC numbers.
Authors: We acknowledge that the manuscript omitted the precise operational details of the z-test. In the revised §3.2 we will explicitly state: the null distribution is the empirical distribution of template-match proportions observed on a large held-out corpus of non-watermarked text; a match is defined by subgraph isomorphism with a maximum graph-edit distance threshold (we will report the exact threshold and similarity function); and when a parsed graph is compatible with multiple templates we assign it to the template with the highest similarity score (breaking ties by the template used at generation time if known). These clarifications will make the AUC numbers fully reproducible. revision: yes
Circularity Check
No circularity: empirical prompt-based method with external benchmarks
full rationale
The paper introduces an empirical watermarking framework that selects AMR templates, prompts an LLM for realization, and detects via off-the-shelf AMR parsing plus z-test. All performance claims (SOTA matching on clean text, +13.9 AUC under paraphrasing) rest on reported benchmark results on RealNews rather than any derivation, fitted parameter, or self-citation chain. No equations, ansatzes, or uniqueness theorems appear; the central robustness argument is an external empirical observation about semantic invariance, not a reduction to the method's own inputs. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- AMR template
axioms (1)
- domain assumption AMR graphs capture meaning equivalence under paraphrase
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Amazon Artificial General Intelligence , title =. 2024 , url =
2024
-
[2]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[3]
2024 , eprint=
DeepSeek-V3 Technical Report , author=. 2024 , eprint=
2024
-
[4]
2024 , eprint=
A Watermark for Large Language Models , author=. 2024 , eprint=
2024
-
[5]
SemStamp : A Semantic Watermark with Paraphrastic Robustness for Text Generation
Hou, Abe Bohan and Zhang, Jingyu and He, Tianxing and Chuang, Yung-Sung and Wang, Hongwei and Shen, Lingfeng and Van Durme, Benjamin and Khashabi, Daniel and Tsvetkov, Yulia. SemStamp : A Semantic Watermark with Paraphrastic Robustness for Text Generation. Annual Conference of the North American Chapter of the Association for Computational Linguistics. 2023
2023
-
[8]
2024 , eprint=
MASSIVE Multilingual Abstract Meaning Representation: A Dataset and Baselines for Hallucination Detection , author=. 2024 , eprint=
2024
-
[9]
A bstract M eaning R epresentation for Sembanking
Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan. A bstract M eaning R epresentation for Sembanking. Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse. 2013
2013
-
[10]
2023 , eprint=
ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation , author=. 2023 , eprint=
2023
-
[11]
Exploiting A bstract M eaning R epresentation for Open-Domain Question Answering
Wang, Cunxiang and Xu, Zhikun and Guo, Qipeng and Hu, Xiangkun and Bai, Xuefeng and Zhang, Zheng and Zhang, Yue. Exploiting A bstract M eaning R epresentation for Open-Domain Question Answering. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.131
-
[12]
and Raskin, Victor and Crogan, Michael and Hempelmann, Christian and Kerschbaum, Florian and Mohamed, Dina and Naik, Sanket , title =
Atallah, Mikhail J. and Raskin, Victor and Crogan, Michael and Hempelmann, Christian and Kerschbaum, Florian and Mohamed, Dina and Naik, Sanket , title =. Proceedings of the 4th International Workshop on Information Hiding , pages =. 2001 , isbn =
2001
-
[13]
2024 , eprint=
PostMark: A Robust Blackbox Watermark for Large Language Models , author=. 2024 , eprint=
2024
-
[14]
2023 , eprint=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. 2023 , eprint=
2023
-
[16]
2020 , eprint=
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization , author=. 2020 , eprint=
2020
-
[17]
Parrot Paraphraser , author =
-
[18]
2020 , url =
Brad Jascob , title =. 2020 , url =
2020
-
[19]
2023 , eprint=
Exploring the Use of Large Language Models for Reference-Free Text Quality Evaluation: An Empirical Study , author=. 2023 , eprint=
2023
-
[20]
2023 , eprint=
Robust Multi-bit Natural Language Watermarking through Invariant Features , author=. 2023 , eprint=
2023
-
[21]
2023 , eprint=
Watermarking Pre-trained Language Models with Backdooring , author=. 2023 , eprint=
2023
-
[22]
Stamatatos, Efstathios , title =. J. Am. Soc. Inf. Sci. Technol. , month = mar, pages =. 2009 , issue_date =
2009
-
[24]
Continuous N-gram Representations for Authorship Attribution
Sari, Yunita and Vlachos, Andreas and Stevenson, Mark. Continuous N-gram Representations for Authorship Attribution. Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. 2017
2017
-
[25]
2022 , eprint=
PART: Pre-trained Authorship Representation Transformer , author=. 2022 , eprint=
2022
-
[27]
2024 , eprint=
Do LLMs Know to Respect Copyright Notice? , author=. 2024 , eprint=
2024
-
[28]
2024 , eprint=
Large language models can consistently generate high-quality content for election disinformation operations , author=. 2024 , eprint=
2024
-
[29]
2023 , eprint=
Provable Robust Watermarking for AI-Generated Text , author=. 2023 , eprint=
2023
-
[30]
2024 , eprint=
On the Reliability of Watermarks for Large Language Models , author=. 2024 , eprint=
2024
-
[31]
2024 , eprint=
Robust Distortion-free Watermarks for Language Models , author=. 2024 , eprint=
2024
-
[32]
2019 , howpublished =
Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan , title =. 2019 , howpublished =
2019
-
[33]
2023 , eprint=
Red Teaming Language Model Detectors with Language Models , author=. 2023 , eprint=
2023
-
[35]
2024 , eprint=
A Semantic Invariant Robust Watermark for Large Language Models , author=. 2024 , eprint=
2024
-
[36]
2024 , eprint=
A Robust Semantics-based Watermark for Large Language Model against Paraphrasing , author=. 2024 , eprint=
2024
-
[37]
Atallah, Victor Raskin, Michael Crogan, Christian Hempelmann, Florian Kerschbaum, Dina Mohamed, and Sanket Naik
Mikhail J. Atallah, Victor Raskin, Michael Crogan, Christian Hempelmann, Florian Kerschbaum, Dina Mohamed, and Sanket Naik. 2001. Natural language watermarking: Design, analysis, and a proof-of-concept implementation. In Proceedings of the 4th International Workshop on Information Hiding, IHW '01, page 185–199, Berlin, Heidelberg. Springer-Verlag
2001
-
[38]
Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2013. https://aclanthology.org/W13-2322/ A bstract M eaning R epresentation for sembanking . In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, pages 178--18...
2013
-
[39]
Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2019. Abstract meaning representation ( AMR ) 1.2.6 specification. https://github.com/amrisi/amr-guidelines/blob/master/amr.md. Accessed: 2025-05-12
2019
-
[40]
Michael Brennan, Sadia Afroz, and Rachel Greenstadt. 2012. https://doi.org/10.1145/2382448.2382450 Adversarial stylometry: Circumventing authorship recognition to preserve privacy and anonymity . ACM Trans. Inf. Syst. Secur., 15(3)
- [41]
- [42]
-
[43]
Prithiviraj Damodaran. 2021. Parrot paraphraser. https://github.com/PrithivirajDamodaran/Parrot_Paraphraser
2021
-
[44]
Scalable watermarking for identifying large language model outputs
Sumanth Dathathri, Abigail See, Shubham Ghaisas, Pierre - Sacha H \" u rlimann, Jacob Walker, Brian Bartoldson, Rohan Mukherjee, Aditya Sen, Varun Bansal, Rohan Bhasin, Michael A. Munn, Alexey Korotkevich, Rishabh Singh, Thomas Mensink, James Hennessey, Nisanth Venkateswaran, Benjamin Bichsel, Thomas Cooijmans, Zoubin Ghahramani, and 6 others. 2024. https...
- [45]
-
[46]
Abe Bohan Hou, Jingyu Zhang, Tianxing He, Yung-Sung Chuang, Hongwei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, and Yulia Tsvetkov. 2023. https://arxiv.org/abs/2310.03991 SemStamp : A semantic watermark with paraphrastic robustness for text generation . In Annual Conference of the North American Chapter of the Association for Computational L...
-
[47]
Abe Bohan Hou, Jingyu Zhang, Yichen Wang, Daniel Khashabi, and Tianxing He. 2024. https://doi.org/10.18653/v1/2024.findings-acl.98 k-SemStamp : A clustering-based semantic watermark for detection of machine-generated text . In Findings of the Association for Computational Linguistics: ACL 2024, pages 1706--1715, Bangkok, Thailand. Association for Computat...
- [48]
-
[49]
Piotr Indyk and Rajeev Motwani. 1998. https://doi.org/10.1145/276698.276876 Approximate nearest neighbors: towards removing the curse of dimensionality . In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, STOC '98, page 604–613, New York, NY, USA. Association for Computing Machinery
-
[50]
Brad Jascob. 2020. https://github.com/bjascob/amrlib amrlib: A python library that makes amr parsing, generation and visualization simple . Accessed: 2025-05-12
2020
- [51]
-
[52]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, and Tom Goldstein. 2024 b . https://arxiv.org/abs/2306.04634 On the reliability of watermarks for large language models . Preprint, arXiv:2306.04634
-
[53]
Moshe Koppel, Jonathan Schler, and Shlomo Argamon. 2009. https://doi.org/10.1002/asi.20961 Computational methods in authorship attribution . Journal of the American Society for Information Science and Technology, 60(1):9--26
- [54]
- [55]
-
[56]
Juri Opitz, Letitia Parcalabescu, and Anette Frank. 2020. https://doi.org/10.1162/tacl_a_00329 AMR similarity metrics from principles . Transactions of the Association for Computational Linguistics, 8:522--538
-
[57]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2023. https://arxiv.org/abs/1910.10683 Exploring the limits of transfer learning with a unified text-to-text transformer . Preprint, arXiv:1910.10683
work page internal anchor Pith review arXiv 2023
- [58]
- [59]
-
[60]
Yunita Sari, Andreas Vlachos, and Mark Stevenson. 2017. https://aclanthology.org/E17-2043/ Continuous n-gram representations for authorship attribution . In Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , pages 267--273, Valencia, Spain. Association for Computational Li...
2017
- [61]
-
[62]
Efstathios Stamatatos. 2009. A survey of modern authorship attribution methods. J. Am. Soc. Inf. Sci. Technol., 60(3):538–556
2009
-
[63]
Williams, Liam Burke-Moore, Ryan Sze-Yin Chan, Florence E
Angus R. Williams, Liam Burke-Moore, Ryan Sze-Yin Chan, Florence E. Enock, Federico Nanni, Tvesha Sippy, Yi-Ling Chung, Evelina Gabasova, Kobi Hackenburg, and Jonathan Bright. 2024. https://arxiv.org/abs/2408.06731 Large language models can consistently generate high-quality content for election disinformation operations . Preprint, arXiv:2408.06731
- [64]
- [65]
- [66]
- [67]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.