Recognition: 2 theorem links
· Lean TheoremStructured 3D Latents Are Surprisingly Powerful: Unleashing Generalizable Style with 2D Diffusion
Pith reviewed 2026-05-08 17:41 UTC · model grok-4.3
The pith
Structured 3D latents can be steered by 2D diffusion guidance to produce diverse styles far outside their training distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
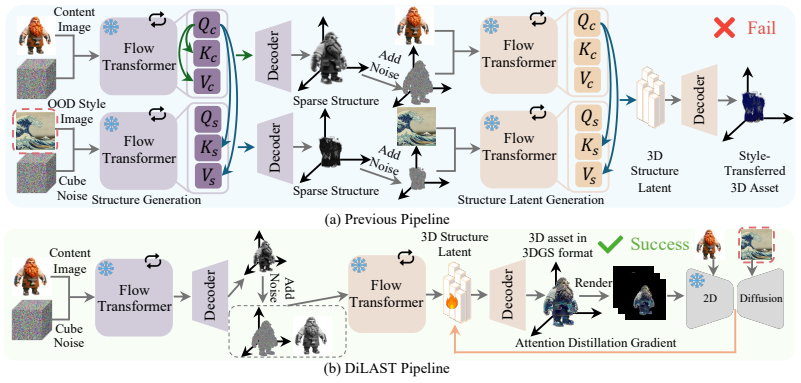
The authors demonstrate that structured 3D latent representations, despite training on comparatively limited data, remain sufficiently expressive for generalizable style transfer. By employing a pretrained 2D diffusion model to guide the alignment of rendered views with a target style, the method optimizes the underlying 3D latents and steers their denoising toward the desired direction, enabling diverse out-of-distribution styles while preserving geometric consistency.
What carries the argument
Optimization of structured 3D latent representations by aligning multiple rendered 2D views with target style through guidance from a pretrained 2D diffusion model.
If this is right
- Existing 3D generation models can produce styles never seen during their original training.
- The same 3D backbone supports multiple styles through latent steering alone.
- Style transfer becomes a plug-and-play addition to various 3D generation pipelines.
- Diverse appearance changes occur while 3D structure remains intact.
- Limited-data 3D models still encode rich style information that diffusion guidance can unlock.
Where Pith is reading between the lines
- Hybrid 2D-3D pipelines may become a practical route for expanding the stylistic range of 3D assets.
- Further gains could come from designing 3D latents that are even more directly compatible with 2D diffusion signals.
- The same guidance principle might extend to controlling other properties such as material or lighting in 3D scenes.
- Testing the approach on dynamic or scene-level 3D generation would reveal whether latent awakening scales beyond single objects.
Load-bearing premise
Guidance from 2D diffusion on rendered views will successfully update the 3D latents for the target style without creating geometric inconsistencies or artifacts across viewpoints.
What would settle it
Running the method on an extreme out-of-distribution style and observing either visible shape distortions or viewpoint-inconsistent geometry in the resulting 3D model.
Figures













read the original abstract
3D asset generation plays a pivotal role in fields such as gaming and virtual reality, enabling the rapid synthesis of high-fidelity 3D objects from a single or multiple images. Building on this capability, enabling style-controllable generation naturally emerges as an important and desirable direction. However, existing approaches typically rely on style images that lie within or are similar to the training distribution of 3D generation models. When presented with out-of-distribution (OOD) styles, their performance degrades significantly or even fails. To address this limitation, we introduce \textbf{DiLAST}: 2D Diffusion-based Latent Awakening for 3D Style Transfer. Specifically, we leverage a pretrained 2D diffusion model as a teacher to provide rich and generalizable style priors. By aligning rendered views with the target style under diffusion-based guidance, our method optimizes the structured 3D latent representations for stylization. We observe that this limitation stems not from insufficient model capacity, but from the underutilization of structured 3D latents, which are inherently expressive. Despite being trained on comparatively limited data, 3D generation models can leverage 2D diffusion guidance to steer denoising toward specific directions in latent space, thereby producing diverse, OOD styles. Extensive experiments across diverse data and multiple 3D generation backbones demonstrate the effectiveness and plug-and-play nature of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiLAST (2D Diffusion-based Latent Awakening for 3D Style Transfer), which uses guidance from a pretrained 2D diffusion model to optimize structured 3D latent representations in existing 3D generation models. Rendered 2D views are aligned to target out-of-distribution styles via diffusion-based guidance, allowing the 3D latents to produce diverse stylizations. The central claim is that limitations on OOD styles arise from underutilization of these latents rather than insufficient model capacity, with the method being plug-and-play across backbones and supported by extensive experiments on diverse data.
Significance. If the empirical claims hold, the work would demonstrate a practical route to generalizable style control in 3D assets by repurposing 2D diffusion priors, without retraining 3D models trained on limited data. This could meaningfully advance controllable generation for applications in gaming and VR, while underscoring the expressive capacity of structured latents when properly guided.
major comments (2)
- [DiLAST optimization procedure] DiLAST optimization procedure: the method applies diffusion guidance independently to rendered 2D views and back-propagates into the 3D latent, but no explicit multi-view consistency regularizer or cross-view loss term is described. This is load-bearing for the claim that geometry and 3D consistency are preserved under OOD stylization, as view-dependent solutions could satisfy the per-view guidance without generalizing to unseen angles.
- [Experiments] Experiments section: the abstract asserts that 'extensive experiments across diverse data and multiple 3D generation backbones demonstrate the effectiveness,' yet the provided description contains no quantitative metrics, baseline comparisons, ablation studies on the alignment procedure, or error analysis for OOD styles and consistency. This prevents verification that the data actually supports the central observation about latent power and generalization.
minor comments (1)
- The acronym DiLAST and its full expansion should be introduced with a brief parenthetical in the abstract for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [DiLAST optimization procedure] DiLAST optimization procedure: the method applies diffusion guidance independently to rendered 2D views and back-propagates into the 3D latent, but no explicit multi-view consistency regularizer or cross-view loss term is described. This is load-bearing for the claim that geometry and 3D consistency are preserved under OOD stylization, as view-dependent solutions could satisfy the per-view guidance without generalizing to unseen angles.
Authors: We agree that the absence of an explicit multi-view consistency term warrants further discussion in the manuscript. The current procedure optimizes a single shared 3D latent representation using guidance signals aggregated across multiple rendered views; the structured nature of the latent (inherited from the pretrained 3D backbone) and the joint back-propagation inherently discourage view-dependent solutions. Nevertheless, to make this mechanism fully transparent and to directly address the concern, we will revise the method section to include a dedicated paragraph explaining the implicit consistency, add a simple multi-view consistency metric in the experiments, and provide an ablation varying the number of optimization views. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts that 'extensive experiments across diverse data and multiple 3D generation backbones demonstrate the effectiveness,' yet the provided description contains no quantitative metrics, baseline comparisons, ablation studies on the alignment procedure, or error analysis for OOD styles and consistency. This prevents verification that the data actually supports the central observation about latent power and generalization.
Authors: We acknowledge that the experiments section in the submitted version emphasizes qualitative results and visual demonstrations. To enable quantitative verification of our claims regarding latent expressiveness and generalization, we will expand the experiments with: (i) quantitative metrics such as CLIP-based style similarity scores and multi-view consistency error (e.g., LPIPS across novel views), (ii) comparisons against baselines including naive latent optimization without diffusion guidance and existing 3D style transfer methods, (iii) ablations on guidance strength, number of views, and optimization steps, and (iv) error analysis highlighting failure cases for particularly challenging OOD styles. These additions will be presented in revised tables and figures. revision: yes
Circularity Check
No circularity: method relies on external pretrained 2D diffusion prior and optimization without self-referential derivations
full rationale
The paper introduces DiLAST as a plug-and-play optimization technique that aligns rendered 2D views of structured 3D latents with style priors from a pretrained external 2D diffusion model. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains are present in the provided abstract or method description. The central claim—that 3D latents can be steered toward OOD styles via 2D guidance—rests on the independent capacity of the external diffusion model and differentiable rendering, not on any reduction to the paper's own inputs or prior self-citations. This is a standard empirical method paper whose validity is testable via experiments rather than tautological by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained 2D diffusion models encode rich and generalizable style priors that can be transferred via rendered views.
invented entities (1)
-
DiLAST optimization procedure
no independent evidence
Lean theorems connected to this paper
-
Foundation/AlphaCoordinateFixation.lean (parameter-free α=1 fixation)alpha_pin_under_high_calibration unclearwe set the loss weights to λ1 = 0.2, λ2 = 20, and λ3 = 10. The number of sampling steps for the flow transformer is set to 500 ... and the guidance strength η is set to 5.
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[2]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review arXiv 2010
-
[3]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[4]
arXiv preprint arXiv:2401.17807 (2024)
Xiaoyu Li, Qi Zhang, Di Kang, Weihao Cheng, Yiming Gao, Jingbo Zhang, Zhihao Liang, Jing Liao, Yan-Pei Cao, and Ying Shan. Advances in 3d generation: A survey.arXiv preprint arXiv:2401.17807, 2024
-
[5]
Combo- verse: Compositional 3d assets creation using spatially-aware diffusion guidance
Yongwei Chen, Tengfei Wang, Tong Wu, Xingang Pan, Kui Jia, and Ziwei Liu. Combo- verse: Compositional 3d assets creation using spatially-aware diffusion guidance. InEuropean Conference on Computer Vision, pages 128–146. Springer, 2024
2024
-
[6]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review arXiv 2022
-
[7]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023
2023
-
[8]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21469–21480, 2025
2025
-
[9]
Guanjun Wu, Jiemin Fang, Chen Yang, Sikuang Li, Taoran Yi, Jia Lu, Zanwei Zhou, Jiazhong Cen, Lingxi Xie, Xiaopeng Zhang, et al. Unilat3d: Geometry-appearance unified latents for single-stage 3d generation.arXiv preprint arXiv:2509.25079, 2025
-
[10]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025
work page Pith review arXiv 2025
-
[11]
Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer
Jiwoo Chung, Sangeek Hyun, and Jae-Pil Heo. Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8795–8805, 2024
2024
-
[12]
Z*: Zero-shot style transfer via attention reweighting
Yingying Deng, Xiangyu He, Fan Tang, and Weiming Dong. Z*: Zero-shot style transfer via attention reweighting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6934–6944, 2024
2024
-
[13]
Unziplora: Separating content and style from a single image
Chang Liu, Viraj Shah, Aiyu Cui, and Svetlana Lazebnik. Unziplora: Separating content and style from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16776–16785, 2025
2025
-
[14]
Stylediffusion: Controllable disentangled style transfer via diffusion models
Zhizhong Wang, Lei Zhao, and Wei Xing. Stylediffusion: Controllable disentangled style transfer via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 7677–7689, 2023
2023
-
[15]
Stylessp: Sampling start- point enhancement for training-free diffusion-based method for style transfer
Ruojun Xu, Weijie Xi, XiaoDi Wang, Yongbo Mao, and Zach Cheng. Stylessp: Sampling start- point enhancement for training-free diffusion-based method for style transfer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18260–18269, 2025
2025
-
[16]
Attention distillation: A unified approach to visual characteristics transfer
Yang Zhou, Xu Gao, Zichong Chen, and Hui Huang. Attention distillation: A unified approach to visual characteristics transfer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18270–18280, 2025. 10
2025
-
[17]
Stylesculptor: Zero-shot style-controllable 3d asset generation with texture-geometry dual guidance
Zefan Qu, Zhenwei Wang, Haoyuan Wang, Ke Xu, Gerhard Petrus Hancke, and Rynson WH Lau. Stylesculptor: Zero-shot style-controllable 3d asset generation with texture-geometry dual guidance. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
2025
-
[18]
Xiaokun Sun, Zeyu Cai, Hao Tang, Ying Tai, Jian Yang, and Zhenyu Zhang. Morphany3d: Unleashing the power of structured latent in 3d morphing.arXiv preprint arXiv:2601.00204, 2026
-
[19]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[20]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[21]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[22]
Analyzing and improving the image quality of stylegan
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020
2020
-
[23]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review arXiv 2011
-
[24]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[25]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review arXiv 2022
-
[27]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review arXiv 2022
-
[28]
Efficient geometry- aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry- aware 3d generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16123–16133, 2022
2022
-
[29]
Gram: Generative radiance manifolds for 3d-aware image generation
Yu Deng, Jiaolong Yang, Jianfeng Xiang, and Xin Tong. Gram: Generative radiance manifolds for 3d-aware image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10673–10683, 2022
2022
-
[30]
Get3d: A generative model of high quality 3d textured shapes learned from images.Advances in neural information processing systems, 35:31841–31854, 2022
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d textured shapes learned from images.Advances in neural information processing systems, 35:31841–31854, 2022
2022
-
[31]
Sdf-stylegan: implicit sdf-based stylegan for 3d shape generation
Xinyang Zheng, Yang Liu, Pengshuai Wang, and Xin Tong. Sdf-stylegan: implicit sdf-based stylegan for 3d shape generation. InComputer Graphics Forum, volume 41, pages 52–63. Wiley Online Library, 2022
2022
-
[32]
Lucid- dreamer: Towards high-fidelity text-to-3d generation via interval score matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, and Yingcong Chen. Lucid- dreamer: Towards high-fidelity text-to-3d generation via interval score matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6517–6526, 2024. 11
2024
-
[33]
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation.arXiv preprint arXiv:2309.16653, 2023
-
[34]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 300–309, 2023
2023
-
[35]
Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. InProceedings of the IEEE/CVF international conference on computer vision, pages 22819–22829, 2023
2023
-
[36]
Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems, 36:8406–8441, 2023
2023
-
[37]
arXiv preprint arXiv:2311.06214 , year=
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model.arXiv preprint arXiv:2311.06214, 2023
-
[38]
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10072–10083, 2024
2024
-
[39]
Wonder3d: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9970–9980, 2024
2024
-
[40]
MVDream: Multi-view diffusion for 3d gen- eration.arXiv preprint arXiv:2308.16512, 2023
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi- view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
-
[41]
arXiv preprint arXiv:2311.04400 , year=
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400, 2023
-
[42]
Autodecoding latent 3d diffusion models.Advances in Neural Information Processing Systems, 36:67021–67047, 2023
Evangelos Ntavelis, Aliaksandr Siarohin, Kyle Olszewski, Chaoyang Wang, Luc V Gool, and Sergey Tulyakov. Autodecoding latent 3d diffusion models.Advances in Neural Information Processing Systems, 36:67021–67047, 2023
2023
-
[43]
3dtopia-xl: Scaling high-quality 3d asset generation via primitive diffusion
Zhaoxi Chen, Jiaxiang Tang, Yuhao Dong, Ziang Cao, Fangzhou Hong, Yushi Lan, Tengfei Wang, Haozhe Xie, Tong Wu, Shunsuke Saito, et al. 3dtopia-xl: Scaling high-quality 3d asset generation via primitive diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26576–26586, 2025
2025
-
[44]
Ln3diff++: Scalable latent neural fields diffusion for speedy 3d generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yushi Lan, Fangzhou Hong, Shangchen Zhou, Shuai Yang, Xuyi Meng, Yongwei Chen, Zhaoyang Lyu, Bo Dai, Xingang Pan, and Chen Change Loy. Ln3diff++: Scalable latent neural fields diffusion for speedy 3d generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[45]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review arXiv 2023
-
[46]
Deadiff: An efficient stylization diffusion model with disentangled representations
Tianhao Qi, Shancheng Fang, Yanze Wu, Hongtao Xie, Jiawei Liu, Lang Chen, Qian He, and Yongdong Zhang. Deadiff: An efficient stylization diffusion model with disentangled representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8693–8702, 2024
2024
-
[47]
Styletokenizer: Defining image style by a single instance for controlling diffusion models
Wen Li, Muyuan Fang, Cheng Zou, Biao Gong, Ruobing Zheng, Meng Wang, Jingdong Chen, and Ming Yang. Styletokenizer: Defining image style by a single instance for controlling diffusion models. InEuropean Conference on Computer Vision, pages 110–126. Springer, 2024. 12
2024
-
[48]
Stylestudio: Text-driven style transfer with selective control of style elements
Mingkun Lei, Xue Song, Beier Zhu, Hao Wang, and Chi Zhang. Stylestudio: Text-driven style transfer with selective control of style elements. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23443–23452, 2025
2025
-
[49]
Customizing text-to-image models with a single image pair
Maxwell Jones, Sheng-Yu Wang, Nupur Kumari, David Bau, and Jun-Yan Zhu. Customizing text-to-image models with a single image pair. InSIGGRAPH Asia 2024 Conference Papers, pages 1–13, 2024
2024
-
[50]
Sigstyle: Signature style transfer via personalized text-to-image models
Ye Wang, Tongyuan Bai, Xuping Xie, Zili Yi, Yilin Wang, and Rui Ma. Sigstyle: Signature style transfer via personalized text-to-image models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8051–8059, 2025
2025
-
[51]
Omnistyle: Filtering high quality style transfer data at scale
Ye Wang, Ruiqi Liu, Jiang Lin, Fei Liu, Zili Yi, Yilin Wang, and Rui Ma. Omnistyle: Filtering high quality style transfer data at scale. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7847–7856, 2025
2025
-
[52]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review arXiv 2022
-
[53]
Inversion-based style transfer with diffusion models
Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based style transfer with diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10146–10156, 2023
2023
-
[54]
Ziplora: Any subject in any style by effectively merging loras
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svetlana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras. InEuropean Conference on Computer Vision, pages 422–438. Springer, 2024
2024
-
[55]
Implicit style-content separation using b-lora
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen-Or. Implicit style-content separation using b-lora. InEuropean Conference on Computer Vision, pages 181–198. Springer, 2024
2024
-
[56]
Qr-lora: Efficient and disentangled fine-tuning via qr decomposition for customized generation
Jiahui Yang, Yongjia Ma, Donglin Di, Jianxun Cui, Hao Li, Wei Chen, Yan Xie, Xun Yang, and Wangmeng Zuo. Qr-lora: Efficient and disentangled fine-tuning via qr decomposition for customized generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17587–17597, 2025
2025
-
[57]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[58]
Stylerf: Zero-shot 3d style transfer of neural radiance fields
Kunhao Liu, Fangneng Zhan, Yiwen Chen, Jiahui Zhang, Yingchen Yu, Abdulmotaleb El Saddik, Shijian Lu, and Eric P Xing. Stylerf: Zero-shot 3d style transfer of neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8338–8348, 2023
2023
-
[59]
Unified implicit neural stylization
Zhiwen Fan, Yifan Jiang, Peihao Wang, Xinyu Gong, Dejia Xu, and Zhangyang Wang. Unified implicit neural stylization. InEuropean conference on computer vision, pages 636–654. Springer, 2022
2022
-
[60]
Stylegaussian: Instant 3d style transfer with gaussian splatting
Kunhao Liu, Fangneng Zhan, Muyu Xu, Christian Theobalt, Ling Shao, and Shijian Lu. Stylegaussian: Instant 3d style transfer with gaussian splatting. InSIGGRAPH Asia 2024 Technical Communications, pages 1–4. 2024
2024
-
[61]
Stylesplat: 3d object style transfer with gaussian splatting.arXiv preprint arXiv:2407.09473, 2024
Sahil Jain, Avik Kuthiala, Prabhdeep Singh Sethi, and Prakanshul Saxena. Stylesplat: 3d object style transfer with gaussian splatting.arXiv preprint arXiv:2407.09473, 2024
-
[62]
Styletex: Style image-guided texture generation for 3d models.ACM Transactions on Graphics (TOG), 43(6):1–14, 2024
Zhiyu Xie, Yuqing Zhang, Xiangjun Tang, Yiqian Wu, Dehan Chen, Gongsheng Li, and Xiaogang Jin. Styletex: Style image-guided texture generation for 3d models.ACM Transactions on Graphics (TOG), 43(6):1–14, 2024
2024
-
[63]
Texture: Text- guided texturing of 3d shapes
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text- guided texturing of 3d shapes. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023. 13
2023
-
[64]
Fix false transparency by noise guided splatting.arXiv preprint arXiv:2510.15736, 2025
Aly El Hakie, Yiren Lu, Yu Yin, Michael Jenkins, and Yehe Liu. Fix false transparency by noise guided splatting.arXiv preprint arXiv:2510.15736, 2025
-
[65]
Marcel Rogge and Didier Stricker. Object-centric 2d gaussian splatting: Background removal and occlusion-aware pruning for compact object models.arXiv preprint arXiv:2501.08174, 2025
-
[66]
Plenoxels: Radiance fields without neural networks
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5501–5510, 2022
2022
-
[67]
InstantStyle-Plus: Style transfer with content-preserving in text-to-image generation
Haofan Wang, Peng Xing, Renyuan Huang, Hao Ai, Qixun Wang, and Xu Bai. Instantstyle- plus: Style transfer with content-preserving in text-to-image generation.arXiv preprint arXiv:2407.00788, 2024
-
[68]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
2025
-
[69]
Chatgpt-5.5.https://chatgpt.com/, 2026
OpenAI. Chatgpt-5.5.https://chatgpt.com/, 2026. Large language model
2026
-
[70]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 14 Appendix A Additional Metric Details Table 2: Style images and corresponding style names. Style Image Style Name Neon cyberpunk glow style Soft atmospheric ...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.