Recognition: unknown
Storage Is Not Memory: A Retrieval-Centered Architecture for Agent Recall
Pith reviewed 2026-05-08 16:41 UTC · model grok-4.3
The pith
Agent memory succeeds when raw events are kept verbatim and recovered through a dedicated multi-stage retrieval pipeline rather than summarized at storage time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Storage is not memory. The correct primitive for agent recall is a retrieval-centered architecture that stores events verbatim and applies a multi-stage pipeline to surface the exact context required by any later query, rather than attempting to anticipate needs by extracting and discarding information at ingestion.
What carries the argument
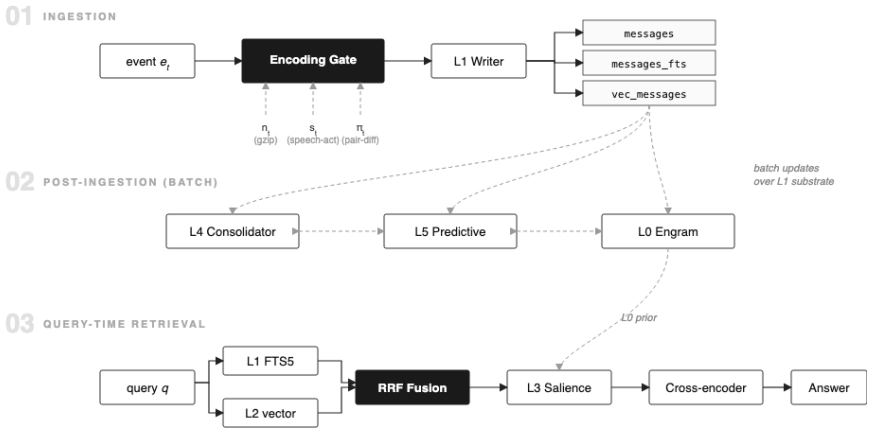
The six-layer True Memory architecture, which operates a multi-stage retrieval pipeline directly over preserved verbatim events inside a single SQLite file.
If this is right
- Verbatim event preservation prevents the irreversible loss that occurs when summaries are created before queries are known.
- Multi-stage retrieval can adapt to any query because it works over the full original record rather than a fixed extracted view.
- The entire memory system runs as a single file on ordinary hardware without vector stores, graphs, or GPUs.
- Performance differences appear across conversation, long-context, and million-token benchmarks when retrieval replaces extraction as the core mechanism.
- Ablation results indicate that the advantage is stable across small variations in the top-performing configuration family.
Where Pith is reading between the lines
- The same separation of storage from retrieval could apply to any long-lived record where future questions cannot be predicted at write time.
- Systems built this way would naturally support incremental updates and re-querying without re-ingestion or re-extraction steps.
- Real-world agents with evolving goals might show larger gains because retrieval can be tuned per query without touching the stored events.
- Testing on open-ended agent trajectories rather than fixed benchmarks would reveal whether the staged pipeline scales when queries arrive continuously.
Load-bearing premise
All information required by future unknown queries remains present and recoverable in the raw event stream through staged retrieval, without any permanent loss from the absence of early extraction.
What would settle it
A set of queries on long multi-session records where the decisive facts are scattered across many events in forms that no retrieval pipeline can reassemble without having performed summary extraction at ingestion time.
Figures



read the original abstract
Extraction at ingestion is the wrong primitive for agent memory: content discarded before the query is known cannot be recovered at retrieval time. We propose True Memory, a six-layer architecture that shifts the center of the system from a storage schema to a multi-stage retrieval pipeline operating over events preserved verbatim. The full system runs as a single SQLite file on commodity CPU with no external database, vector index, graph store, or GPU. On LoCoMo (1,540 questions across 10 multi-session conversations), True Memory Pro reaches 93.0% accuracy (3-run mean) against 61.4% for Mem0, 65.4% for Supermemory, approximately 71% for Zep, and 94.5% for EverMemOS under a matched gpt-4.1-mini answer model. On LongMemEval (500 questions), True Memory Pro reaches 87.8% (3-run mean). On BEAM-1M (700 questions at the 1-million-token scale), True Memory Pro reaches 76.6% (3-run mean), above the prior published result of 73.9% for Hindsight. A 56-configuration ablation shows a 1.3-percentage-point spread within the top-performing configuration family.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that extraction at ingestion time is the wrong primitive for agent memory systems because it irreversibly discards information before any query is known. It proposes True Memory, a six-layer retrieval-centered architecture that preserves events verbatim in a single SQLite file and defers all processing to a multi-stage query-time pipeline. The system is evaluated on LoCoMo (93.0% accuracy), LongMemEval (87.8%), and BEAM-1M (76.6%), outperforming baselines such as Mem0, Supermemory, Zep, and Hindsight under a matched gpt-4.1-mini answer model, with supporting results from a 56-configuration ablation study.
Significance. If the performance gains can be attributed to the retrieval-centered design rather than unstated implementation choices, the work would be significant for shifting agent memory paradigms away from storage schemas toward query-time pipelines. The single-file CPU-only implementation and the ablation analysis are concrete strengths that could influence practical long-context agent systems.
major comments (2)
- [§3] §3 (Architecture): The six-layer retrieval pipeline is presented as the central innovation, yet the manuscript provides no concrete description of the similarity functions, ranking logic, or context-assembly rules operating over the verbatim event store. This omission is load-bearing because the core claim—that verbatim storage plus deferred retrieval avoids irreversible loss—cannot be evaluated without knowing how the stages locate and combine spans at 1M-token scale.
- [§5.1, Tables 1–3] §5.1 and Tables 1–3: All benchmark results are reported only as 3-run means (e.g., 93.0% on LoCoMo, 76.6% on BEAM-1M) with no standard deviations, error bars, or statistical significance tests against baselines. Given the modest margins over some comparators and the 1.3-point spread in the ablation, the absence of variance measures weakens the empirical support for the architecture’s superiority.
minor comments (2)
- [Abstract] Abstract: The phrase “approximately 71% for Zep” is imprecise; the exact reported value and the source of the comparison should be stated consistently with the other baselines.
- [§4.2] §4.2: The ablation study mentions a “top-performing configuration family” but does not enumerate the 56 configurations or identify which hyper-parameters were varied, limiting reproducibility of the sensitivity analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and agree that the suggested additions will strengthen the presentation of the retrieval-centered architecture and the empirical claims. We will incorporate these changes in the revised version.
read point-by-point responses
-
Referee: [§3] §3 (Architecture): The six-layer retrieval pipeline is presented as the central innovation, yet the manuscript provides no concrete description of the similarity functions, ranking logic, or context-assembly rules operating over the verbatim event store. This omission is load-bearing because the core claim—that verbatim storage plus deferred retrieval avoids irreversible loss—cannot be evaluated without knowing how the stages locate and combine spans at 1M-token scale.
Authors: We acknowledge that §3 currently emphasizes the high-level design rationale and the six-layer structure without providing the low-level operational details of the retrieval pipeline. The manuscript does not specify the exact similarity functions (e.g., how lexical and semantic scores are combined), the ranking logic across the multi-stage process, or the context-assembly rules for selecting and combining verbatim event spans at 1M-token scale. This is a genuine gap that limits evaluation of the core claim. In the revision we will expand §3 with a new subsection containing these concrete descriptions, including the hybrid scoring formula, stage-wise ranking procedure, and assembly heuristics, supported by pseudocode where helpful. revision: yes
-
Referee: [§5.1, Tables 1–3] §5.1 and Tables 1–3: All benchmark results are reported only as 3-run means (e.g., 93.0% on LoCoMo, 76.6% on BEAM-1M) with no standard deviations, error bars, or statistical significance tests against baselines. Given the modest margins over some comparators and the 1.3-point spread in the ablation, the absence of variance measures weakens the empirical support for the architecture’s superiority.
Authors: We agree that reporting only 3-run means without variance measures or statistical tests is insufficient, particularly given the modest margins over certain baselines and the 1.3-point spread observed in the ablation study. The current manuscript does not include standard deviations, error bars, or significance testing. In the revised version we will update §5.1 and Tables 1–3 to report standard deviations for all means, include error bars in the tables and any associated figures, and add results from statistical significance tests (e.g., paired t-tests) against the baselines to better substantiate the performance claims. revision: yes
Circularity Check
No circularity: empirical performance claims on public benchmarks
full rationale
The paper proposes a retrieval-centered architecture and supports its claims exclusively with empirical accuracy numbers on public benchmarks (LoCoMo 93.0%, LongMemEval 87.8%, BEAM-1M 76.6%). No equations, first-principles derivations, or mathematical predictions appear in the provided text. The architecture description does not reduce any result to a fitted parameter, self-citation, or definitional equivalence. Ablation results are likewise direct measurements rather than constructed outputs. The central claims remain independent of any internal loop and rest on external benchmark evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Verbatim events contain all information needed for future arbitrary queries.
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taran- jeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long- term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review arXiv
-
[2]
Accessed 2026-04-15. D. Richard Hipp and contributors. SQLite and the FTS5 full-text-search module.https:// www.sqlite.org/fts5.html,
2026
-
[3]
SQLite released in 2000; the FTS5 module was added in
2000
-
[4]
Accessed 2026-04-15. C. Hu, X. Gao, Z. Zhou, D. Xu, Y. Bai, X. Li, H. Zhang, T. Li, C. Zhang, L. Bing, and Y. Deng. EverMemOS: A self-organizing memory oper- ating system for structured long-horizon reason- ing,
2026
-
[5]
Chris Latimer, Nicol ´o Boschi, Andrew Neeser, Chris Bartholomew, Gaurav Srivastava, Xuan Wang, and Naren Ramakrishnan. Hindsight is 20/20: Building agent memory that re- tains, recalls, and reflects.arXiv preprint arXiv:2512.12818,
-
[6]
Yuqing Li, Jiangnan Li, Mo Yu, Guoxuan Ding, Zheng Lin, Weiping Wang, and Jie Zhou. Query-focused and memory-aware reranker for long context processing.arXiv preprint arXiv:2602.12192,
-
[7]
arXiv:2402.17753. Yu. A. Malkov and D. A. Yashunin. Effi- cient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(4):824–836,
work page internal anchor Pith review arXiv
-
[8]
arXiv:1603.09320. James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. Why there are comple- mentary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory.Psychological Review, 102(3):419– 457,
-
[9]
Rodrigo Nogueira and Kyunghyun Cho. Pas- sage re-ranking with BERT.arXiv preprint arXiv:1901.04085,
work page internal anchor Pith review arXiv 1901
-
[10]
MemGPT: Towards LLMs as Operating Systems
15 Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operat- ing systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review arXiv
-
[11]
Qwen Team
Representative commercial and open- source vector database products; product doc- umentation athttps://www.pinecone.io, https://www.trychroma.com,https:// weaviate.io, andhttps://qdrant.tech, accessed 2026-04-15. Qwen Team. Qwen3-Embedding: Advanced text embedding and reranking through foundation models,
2026
- [12]
-
[13]
Documentation athttps: //docs.supermemory.ai
Commercial agent- memory service. Documentation athttps: //docs.supermemory.ai. Accessed 2026-04-
2026
-
[14]
arXiv:2510.27246. St´ephan Tulkens and Thomas van Dongen. Model2vec: Fast static embeddings from sen- tence transformers.https://github.com/ MinishLab/model2vec,
-
[15]
Endel Tulving
Accessed 2026-04-15. Endel Tulving. Episodic and semantic memory. In Endel Tulving and Wayne Donaldson, editors, Organization of Memory, pages 381–403. Aca- demic Press,
2026
-
[16]
arXiv:2410.10813. Zep AI. Graphiti: A temporal knowledge graph framework for ai agents.https:// github.com/getzep/graphiti,
work page internal anchor Pith review arXiv
-
[17]
16 A Complete 56-configuration ablation data Table 7 lists every cell of the 7 embedder×8 reranker grid referenced in§7, sorted by LoCoMo accuracy
Ac- cessed 2026-04-15. 16 A Complete 56-configuration ablation data Table 7 lists every cell of the 7 embedder×8 reranker grid referenced in§7, sorted by LoCoMo accuracy. The aggregate statistics in Table 6 and the heatmap in Figure 4 are computed directly from these 56 rows. Table 7: Per-configuration results across the 56-cell LoCoMo grid. ★ Wilson 95% ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.