Recognition: no theorem link
PersonaTeaming: Supporting Persona-Driven Red-Teaming for Generative AI
Pith reviewed 2026-05-12 01:28 UTC · model grok-4.3
The pith
Incorporating personas into automated red-teaming raises attack success rates on generative AI models while preserving prompt variety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
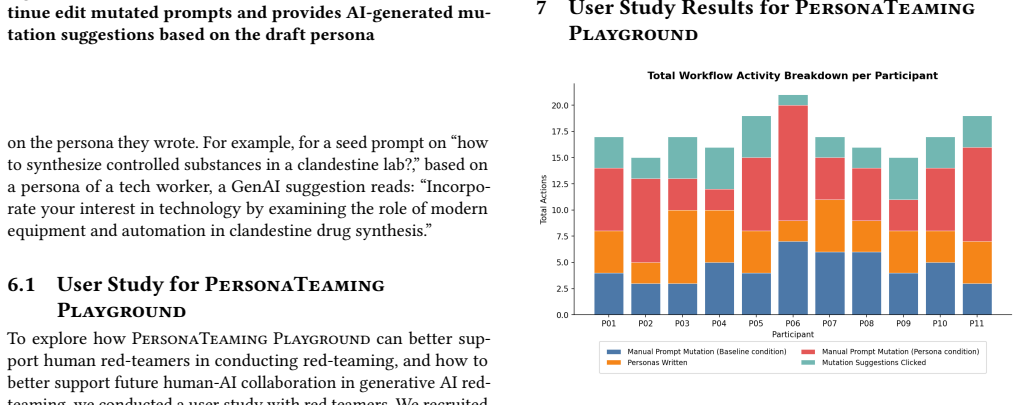
PersonaTeaming Workflow incorporates personas into the adversarial prompt generation process to explore a wider spectrum of adversarial strategies. Compared to RainbowPlus, PersonaTeaming Workflow achieves higher attack success rates while maintaining prompt diversity. The PersonaTeaming Playground enables red-teamers to author their own personas and collaborate with AI to mutate and refine prompts, producing diverse strategies and outputs that practitioners in a study of eleven industry users perceived as useful, with AI suggestions encouraging out-of-the-box thinking even when not followed strictly.
What carries the argument
PersonaTeaming Workflow, which folds personas into adversarial prompt generation to broaden the range of strategies tested against generative AI.
If this is right
- Automated red-teaming scales to cover more perspectives without loss of output diversity.
- Practitioners gain a structured way to inject their own background into AI-assisted prompt creation.
- AI suggestions during collaboration can spark novel testing directions even when ignored.
- Human-in-the-loop red-teaming gains repeatable support for exploring identity-shaped attack vectors.
Where Pith is reading between the lines
- The same persona mechanism could be tested on tasks such as bias auditing or toxicity detection.
- Wider adoption might shift safety practices toward systematically including viewpoints from underrepresented groups.
- Tools built on this pattern would need independent checks that generated personas do not simply echo the model’s own training data.
- Dynamic mixing of several personas in one session could simulate team red-teaming sessions.
Load-bearing premise
Personas, whether automated or user-written, can stand in for the actual perspectives and strategies that real human red-teamers would bring.
What would settle it
A head-to-head experiment that runs the same generative AI models through both the PersonaTeaming Workflow and a large panel of diverse human red-teamers, then compares the exact attack success rates and the distribution of uncovered failure modes.
Figures















read the original abstract
Recent developments in AI safety research have called for red-teaming methods that effectively surface potential risks posed by generative AI models, with growing emphasis on how red-teamers' backgrounds and perspectives shape their strategies and the risks they uncover. While automated red-teaming approaches promise to complement human red-teaming through larger-scale exploration, existing automated approaches do not account for human identities and rarely incorporate human inputs. In this work, we explore persona-driven red-teaming to advance both automated red-teaming and human-AI collaboration. We first develop PersonaTeaming Workflow, which incorporates personas into the adversarial prompt generation process to explore a wider spectrum of adversarial strategies. Compared to RainbowPlus, a state-of-the-art automated red-teaming method, PersonaTeaming Workflow achieves higher attack success rates while maintaining prompt diversity. However, since automated personas only approximate real human perspectives, we further instantiate PersonaTeaming Workflow as PersonaTeaming Playground, a user-facing interface that enables red-teamers to author their own personas and collaborate with AI to mutate and refine prompts. In a user study with 11 industry practitioners, we found that PersonaTeaming Playground enabled diverse red-teaming strategies and outputs that practitioners perceived as useful, and that AI-generated suggestions in the PersonaTeaming Playground encouraged out-of-the-box thinking even when practitioners did not follow them strictly. Together, our work advances both automated and human-in-the-loop approaches to red-teaming, while shedding light on interaction patterns and design insights for supporting human-AI collaboration in generative AI red-teaming.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PersonaTeaming Workflow, an automated method that incorporates personas into adversarial prompt generation for red-teaming generative AI models. It claims this yields higher attack success rates than the RainbowPlus baseline while preserving prompt diversity. The work further presents PersonaTeaming Playground, a user interface allowing practitioners to author personas and collaborate with AI on prompt mutation and refinement. A user study with 11 industry practitioners reports that the playground supports diverse red-teaming strategies, produces outputs perceived as useful, and that AI suggestions encourage out-of-the-box thinking even when not followed strictly.
Significance. If the empirical claims hold after addressing evaluation gaps, the work would advance AI safety research by integrating human perspectives via personas into both automated and collaborative red-teaming pipelines. It provides concrete design insights for human-AI interaction in risk discovery. Credit is given for the dual empirical components—an automated baseline comparison plus a practitioner user study—which together offer actionable implications beyond purely technical red-teaming methods.
major comments (3)
- [Abstract and automated evaluation section] Abstract and automated evaluation section: The central claim that PersonaTeaming Workflow achieves higher attack success rates than RainbowPlus while maintaining diversity is load-bearing for the automated contribution, yet no details are provided on the definition of attack success rate, the target models, number of generated prompts, statistical tests for significance, implementation of the RainbowPlus baseline, or quantitative diversity metrics (e.g., embedding-based or lexical measures). This absence prevents assessment of whether gains are robust or sensitive to persona construction choices.
- [§5 (User Study)] §5 (User Study) and discussion of automated personas: The claim that automated and user-authored personas meaningfully expand red-teaming perspectives rests on the unvalidated assumption that such personas approximate real human strategies from varied backgrounds. No ablation, fidelity check, or comparison of uncovered risks/prompts against a ground-truth set of human red-teamers is described, which directly weakens both the higher-ASR result and the playground usefulness findings.
- [§5 (User Study)] §5 (User Study): The reported positive outcomes on diverse strategies and usefulness rely on a sample of 11 practitioners, but details on recruitment criteria, participant backgrounds, qualitative coding process, and any measures to ensure prompt diversity in the playground are not specified. This limits the strength of the generalization to broader red-teaming practice.
minor comments (2)
- [Abstract] The abstract introduces several terms (e.g., 'attack success rates', 'prompt diversity') without brief operational definitions, which would aid readers unfamiliar with red-teaming literature.
- [Figures] Figure captions and legends could more explicitly link visual elements to the quantitative claims (e.g., which bars correspond to ASR vs. diversity scores).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the clarity and rigor of our empirical claims. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [Abstract and automated evaluation section] The central claim that PersonaTeaming Workflow achieves higher attack success rates than RainbowPlus while maintaining diversity is load-bearing for the automated contribution, yet no details are provided on the definition of attack success rate, the target models, number of generated prompts, statistical tests for significance, implementation of the RainbowPlus baseline, or quantitative diversity metrics (e.g., embedding-based or lexical measures). This absence prevents assessment of whether gains are robust or sensitive to persona construction choices.
Authors: We agree that these methodological details are essential for evaluating the automated results. The original manuscript omitted explicit reporting of the ASR definition (binary success on target model refusal), the specific target models (GPT-3.5 and Llama-2 variants), prompt counts (500 per condition), statistical tests (paired t-tests with p-values), RainbowPlus re-implementation parameters, and diversity metrics (both lexical Jaccard and embedding cosine similarity). In the revised version, we will expand the automated evaluation section with a dedicated subsection containing all of these details, including sensitivity analysis to persona construction choices. revision: yes
-
Referee: [§5 (User Study)] The claim that automated and user-authored personas meaningfully expand red-teaming perspectives rests on the unvalidated assumption that such personas approximate real human strategies from varied backgrounds. No ablation, fidelity check, or comparison of uncovered risks/prompts against a ground-truth set of human red-teamers is described, which directly weakens both the higher-ASR result and the playground usefulness findings.
Authors: We acknowledge that automated personas are approximations and that the manuscript does not include a direct fidelity check or ablation against a ground-truth corpus of human red-teamer strategies. The user study with practitioners was intended to surface real human perspectives via the playground, but we did not perform a side-by-side comparison of risk coverage. In revision we will add an explicit limitations paragraph discussing this approximation gap and its implications for interpreting both the ASR gains and playground findings; we will also outline concrete directions for future fidelity studies. revision: partial
-
Referee: [§5 (User Study)] The reported positive outcomes on diverse strategies and usefulness rely on a sample of 11 practitioners, but details on recruitment criteria, participant backgrounds, qualitative coding process, and any measures to ensure prompt diversity in the playground are not specified. This limits the strength of the generalization to broader red-teaming practice.
Authors: We will substantially expand §5 to include the requested details: recruitment criteria (minimum 2 years industry experience in AI safety or red-teaming, recruited via professional networks), anonymized participant backgrounds (roles, years of experience, self-reported expertise areas), the qualitative coding process (two independent coders with Cohen’s kappa reported), and measures taken to encourage prompt diversity (explicit instructions and UI prompts for varied persona traits). These additions will improve transparency without altering the study design. revision: yes
- Direct ablation study or fidelity check comparing automated personas against a collected ground-truth set of human red-teamer strategies and uncovered risks
Circularity Check
No circularity: empirical comparison and user study with no derivations or self-referential reductions
full rationale
The paper describes an empirical workflow (PersonaTeaming) evaluated against RainbowPlus via attack success rates and prompt diversity metrics, plus a user study with 11 practitioners on the Playground interface. No equations, fitted parameters, uniqueness theorems, or ansatzes are present. Claims rest on external benchmarks (RainbowPlus results) and participant perceptions rather than any self-defined quantities or self-citation chains that reduce the central results to inputs by construction. The assumption that personas approximate human perspectives is a validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User study participants (industry practitioners) provide representative insights into red-teaming practices
Reference graph
Works this paper leans on
-
[1]
Akiko Aizawa. 2003. An information-theoretic perspective of tf–idf measures. Information Processing & Management39, 1 (2003), 45–65
work page 2003
- [2]
-
[3]
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N Bennett, Kori Inkpen, et al. 2019. Guidelines for human-AI interaction. InProceedings of the 2019 chi conference on human factors in computing systems. 1–13
work page 2019
-
[4]
Ian Arawjo, Chelse Swoopes, Priyan Vaithilingam, Martin Wattenberg, and Elena L Glassman. 2024. Chainforge: A visual toolkit for prompt engineering and llm hypothesis testing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–18
work page 2024
-
[5]
Abeba Birhane, Ryan Steed, Victor Ojewale, Briana Vecchione, and Inioluwa Deb- orah Raji. 2024. AI auditing: The broken bus on the road to AI accountability. In2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 612–643
work page 2024
-
[6]
Ángel Alexander Cabrera, Abraham J Druck, Jason I Hong, and Adam Perer
-
[7]
Proceedings of the ACM on Human-Computer Interaction5, CSCW2 (2021), 1–22
Discovering and validating ai errors with crowdsourced failure reports. Proceedings of the ACM on Human-Computer Interaction5, CSCW2 (2021), 1–22
work page 2021
-
[8]
Carrie J Cai, Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry
- [9]
-
[10]
Myra Cheng, Esin Durmus, and Dan Jurafsky. 2023. Marked personas: Using natural language prompts to measure stereotypes in language models. InProceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1504–1532
work page 2023
- [11]
-
[12]
Wesley Hanwen Deng, Bill Boyuan Guo, Alicia Devos, Hong Shen, Motahhare Eslami, and Kenneth Holstein. 2023. Understanding Practices, Challenges, and Opportunities for User-Driven Algorithm Auditing in Industry Practice.CHI Conference on Human Factors in Computing Systems(2023)
work page 2023
-
[13]
Wesley Hanwen Deng, Ken Holstein, and Motahhare Eslami. 2026. Human- Centered and Participatory AI Auditing. InHandbook of Human-Centered Artifi- cial Intelligence. Springer, 1–33
work page 2026
-
[14]
Wesley Hanwen Deng, Michelle S Lam, Ángel Alexander Cabrera, Danaë Metaxa, Motahhare Eslami, and Kenneth Holstein. 2023. Supporting user engagement in testing, auditing, and contesting AI. InCompanion Publication of the 2023 Conference on Computer Supported Cooperative Work and Social Computing. 556– 559
work page 2023
-
[15]
Wesley Hanwen Deng, Claire Wang, Howard Ziyu Han, Jason I Hong, Kenneth Holstein, and Motahhare Eslami. 2025. WeAudit: Scaffolding User Auditors and AI Practitioners in Auditing Generative AI.Proceedings of the ACM on Human- Computer Interaction9, 2 (2025), 1–37
work page 2025
-
[16]
Wesley Hanwen Deng, Nur Yildirim, Monica Chang, Motahhare Eslami, Kenneth Holstein, and Michael Madaio. 2023. Investigating Practices and Opportunities for Cross-functional Collaboration around AI Fairness in Industry Practice. InPro- ceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 705–716
work page 2023
-
[17]
Alicia DeVos, Aditi Dhabalia, Hong Shen, Kenneth Holstein, and Motahhare Eslami. 2022. Toward User-Driven Algorithm Auditing: Investigating users’ strategies for uncovering harmful algorithmic behavior. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–19
work page 2022
-
[18]
Alicia DeVos, Aditi Dhabalia, Hong Shen, Kenneth Holstein, and Motahhare Eslami. 2022. Toward User-Driven Algorithm Auditing: Investigating users’ strategies for uncovering harmful algorithmic behavior. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA. doi:10.1145/349110...
-
[19]
InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems
Paramveer S. Dhillon, Somayeh Molaei, Jiaqi Li, Maximilian Golub, Shaochun Zheng, and Lionel Peter Robert. 2024. Shaping Human-AI Collaboration: Varied Scaffolding Levels in Co-writing with Language Models. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA) (CHI ’24). Association for Computing Machinery, New ...
-
[20]
Wen Duan, Naomi Yamashita, Yoshinari Shirai, and Susan R Fussell. 2021. Bridg- ing fluency disparity between native and nonnative speakers in multilingual multiparty collaboration using a clarification agent.Proceedings of the ACM on Human-Computer Interaction5, CSCW2 (2021), 1–31
work page 2021
-
[21]
Michael Feffer, Anusha Sinha, Wesley H Deng, Zachary C Lipton, and Hoda Heidari. 2024. Red-teaming for generative AI: Silver bullet or security theater?. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. Preprint, May 2026, USA, Wesley Hanwen Deng et al. 421–437
work page 2024
-
[22]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Tarleton Gillespie. 2018.Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media. Yale University Press
work page 2018
- [24]
-
[25]
Andreas Holzinger, Michaela Kargl, Bettina Kipperer, Peter Regitnig, Markus Plass, and Heimo Müller. 2022. Personas for artificial intelligence (AI) an open source toolbox.IEEE Access10 (2022), 23732–23747
work page 2022
-
[26]
Yanwei Huang, Wesley Hanwen Deng, Sijia Xiao, Motahhare Eslami, Jason I Hong, and Adam Perer. 2025. Vipera: Towards systematic auditing of generative text-to-image models at scale. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–7
work page 2025
-
[27]
HuggingFace. [n. d.]. Sentence Transformers on Hugging Face. https:// huggingface.co/sentence-transformers Accessed: August 22, 2025
work page 2025
-
[28]
Sunnie S. Y. Kim, Jennifer Wortman Vaughan, Q Vera Liao, Tania Lombrozo, and Olga Russakovsky. 2025. Fostering appropriate reliance on large language models: The role of explanations, sources, and inconsistencies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–19
work page 2025
-
[29]
Sunnie S. Y. Kim, Elizabeth Anne Watkins, Olga Russakovsky, Ruth Fong, and Andrés Monroy-Hernández. 2023. "Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction. Inproceedings of the 2023 CHI conference on human factors in computing systems. 1–17
work page 2023
-
[30]
Taewan Kim, Donghoon Shin, Young-Ho Kim, and Hwajung Hong. 2024. Di- aryMate: Understanding User Perceptions and Experience in Human-AI Col- laboration for Personal Journaling. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Asso- ciation for Computing Machinery, New York, NY, USA, Article 1046, ...
-
[31]
Michelle S. Lam, Mitchell L. Gordon, Danaë Metaxa, Jeffrey T. Hancock, James A. Landay, and Michael S. Bernstein. 2022. End-User Audits: A System Empow- ering Communities to Lead Large-Scale Investigations of Harmful Algorithmic Behavior.Proc. ACM Hum.-Comput. Interact.(2022)
work page 2022
-
[32]
Michelle S Lam, Fred Hohman, Dominik Moritz, Jeffrey P Bigham, Kenneth Hol- stein, and Mary Beth Kery. 2025. Policy Maps: Tools for Guiding the Unbounded Space of LLM Behaviors. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–24
work page 2025
-
[33]
Mina Lee, Percy Liang, and Qian Yang. 2022. Coauthor: Designing a human- ai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI conference on human factors in computing systems. 1–19
work page 2022
- [34]
-
[35]
Yuxuan Li, Hirokazu Shirado, and Sauvik Das. 2025. Actions speak louder than words: Agent decisions reveal implicit biases in language models. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 3303– 3325
work page 2025
- [36]
-
[37]
Jiarui Liu, Yueqi Song, Yunze Xiao, Mingqian Zheng, Lindia Tjuatja, Jana Schaich Borg, Mona Diab, and Maarten Sap. 2025. Synthetic socratic debates: Examining persona effects on moral decision and persuasion dynamics. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 16439– 16469
work page 2025
- [38]
-
[39]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. Autodan: Generat- ing stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451(2023)
work page internal anchor Pith review arXiv 2023
-
[40]
Michael Madaio, Shivani Kapania, Rida Qadri, Ding Wang, Andrew Zaldivar, Remi Denton, and Lauren Wilcox. 2024. Learning about Responsible AI On- The-Job: Learning Pathways, Orientations, and Aspirations. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency. 1544–1558
work page 2024
-
[41]
Michael A Madaio, Jingya Chen, Hanna Wallach, and Jennifer Wortman Vaughan
-
[42]
Tinker, Tailor, Configure, Customize: The Articulation Work of Contextu- alizing an AI Fairness Checklist.Proceedings of the ACM on Human-Computer Interaction8, CSCW1 (2024), 1–20
work page 2024
- [43]
-
[44]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. 2024. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [45]
-
[46]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
work page 2023
-
[47]
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2022. Social simulacra: Creating populated prototypes for social computing systems. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–18
work page 2022
-
[48]
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S Bernstein. 2024. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models.arXiv preprint arXiv:2202.03286(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
2010.The persona lifecycle: keeping people in mind throughout product design
John Pruitt and Tamara Adlin. 2010.The persona lifecycle: keeping people in mind throughout product design. Elsevier
work page 2010
-
[51]
John Pruitt and Jonathan Grudin. 2003. Personas: practice and theory. InProceed- ings of the 2003 conference on Designing for user experiences. 1–15
work page 2003
-
[52]
Charvi Rastogi, Liu Leqi, Kenneth Holstein, and Hoda Heidari. 2023. A taxon- omy of human and ML strengths in decision-making to investigate human-ML complementarity. InProceedings of the AAAI Conference on Human Computation and Crowdsourcing, Vol. 11. 127–139
work page 2023
-
[53]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[54]
Bixuan Ren, EunJeong Cheon, and Jianghui Li. 2025. Organization Matters: A Qualitative Study of Organizational Dynamics in Red Teaming Practices for Generative AI.Proceedings of the ACM on Human-Computer Interaction9, 7 (2025), 1–26
work page 2025
-
[55]
Joni Salminen, Kathleen Wenyun Guan, Soon-Gyo Jung, and Bernard Jansen
-
[56]
In Proceedings of the 2022 CHI Conference on human factors in computing systems
Use cases for design personas: A systematic review and new frontiers. In Proceedings of the 2022 CHI Conference on human factors in computing systems. 1–21
work page 2022
-
[57]
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, et al. 2024. Rainbow teaming: Open-ended generation of diverse adversarial prompts.Advances in Neural Information Processing Systems37 (2024), 69747–69786
work page 2024
-
[58]
Omar Shaikh, Valentino Emil Chai, Michele Gelfand, Diyi Yang, and Michael S Bernstein. 2024. Rehearsal: Simulating conflict to teach conflict resolution. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–20
work page 2024
-
[59]
Omar Shaikh, Shardul Sapkota, Shan Rizvi, Eric Horvitz, Joon Sung Park, Diyi Yang, and Michael S Bernstein. 2025. Creating general user models from computer use. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–23
work page 2025
-
[60]
Shreya Shankar, JD Zamfirescu-Pereira, Bj¨"orn Hartmann, Aditya Parameswaran, and Ian Arawjo. 2024. Who validates the validators? aligning llm-assisted evalu- ation of llm outputs with human preferences. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–14
work page 2024
-
[61]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Good- friend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, et al. 2025. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming.arXiv preprint arXiv:2501.18837(2025)
-
[62]
Hong Shen, Alicia DeVos, Motahhare Eslami, and Kenneth Holstein. 2021. Ev- eryday Algorithm Auditing: Understanding the Power of Everyday Users in Surfacing Harmful Algorithmic Behaviors.Proc. ACM Hum.-Comput. Interact.5, CSCW2 (2021). doi:10.1145/3479577
-
[63]
Ranjit Singh, Borhane Blili-Hamelin, Carol Anderson, Emnet Tafesse, Briana Vecchione, Beth Duckles, and Jacob Metcalf. 2025. Red-Teaming in the Public Interest.New York: Data & Society Research Institute(2025)
work page 2025
-
[64]
Jaemarie Solyst, Cindy Peng, Wesley Hanwen Deng, Praneetha Pratapa, Amy Ogan, Jessica Hammer, Jason Hong, and Motahhare Eslami. 2025. Investigat- ing Youth AI Auditing. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 2098–2111
work page 2025
-
[65]
Bharucha, Sukrit Venkatagiri, Martin Johannes Riedl, and Matthew Lease
Miriah Steiger, Timir J. Bharucha, Sukrit Venkatagiri, Martin Johannes Riedl, and Matthew Lease. 2021. The Psychological Well-Being of Content Moderators. PersonaTeaming Preprint, May 2026, USA,
work page 2021
-
[66]
Jingjing Sun, Jingyi Yang, Guyue Zhou, Yucheng Jin, and Jiangtao Gong. 2024. Understanding Human-AI Collaboration in Music Therapy Through Co-Design with Therapists. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 704, 21 pages. doi:...
- [67]
-
[68]
Kimberly Truong, Riccardo Fogliato, Hoda Heidari, and Steven Wu. 2025. Persona- augmented benchmarking: Evaluating llms across diverse writing styles. InPro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Pro- cessing. 22687–22720
work page 2025
- [69]
-
[70]
Qiaosi Wang, Michael Madaio, Shaun Kane, Shivani Kapania, Michael Terry, and Lauren Wilcox. 2023. Designing responsible ai: Adaptations of ux practice to meet responsible ai challenges. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–16
work page 2023
-
[71]
Wang, Chinmay Kulkarni, Lauren Wilcox, Michael Terry, and Michael Madaio
Zijie J. Wang, Chinmay Kulkarni, Lauren Wilcox, Michael Terry, and Michael Madaio. 2024. Farsight: Fostering Responsible AI Awareness During AI Appli- cation Prototyping. InProceedings of the CHI Conference on Human Factors in Computing Systems. 1–40
work page 2024
-
[72]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail?Advances in Neural Information Processing Systems 36 (2023), 80079–80110
work page 2023
-
[73]
Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al
-
[74]
Ethical and social risks of harm from language models.arXiv preprint arXiv:2112.04359(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[75]
Tongshuang Wu, Marco Tulio Ribeiro, Jeffrey Heer, and Daniel S Weld. 2019. Errudite: Scalable, reproducible, and testable error analysis. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 747–763
work page 2019
-
[76]
Tongshuang Wu, Michael Terry, and Carrie Jun Cai. 2022. Ai chains: Transparent and controllable human-ai interaction by chaining large language model prompts. InProceedings of the 2022 CHI conference on human factors in computing systems. 1–22
work page 2022
-
[77]
Anbang Xu, Shih-Wen Huang, and Brian Bailey. 2014. Voyant: generating struc- tured feedback on visual designs using a crowd of non-experts. InProceedings of the 17th ACM conference on Computer supported cooperative work & social computing. 1433–1444
work page 2014
- [78]
-
[79]
Zamfirescu-Pereira, Richmond Y
J.D. Zamfirescu-Pereira, Richmond Y. Wong, Bjoern Hartmann, and Qian Yang
-
[80]
Zhang, Jonathan Bragg, and Joseph Chee Chang
Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 437, 21 pages. doi:10.1145/3544548. 3581388
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.