Recognition: unknown
PREFER: Personalized Review Summarization with Online Preference Learning
Pith reviewed 2026-05-08 11:04 UTC · model grok-4.3
The pith
An online learning framework generates personalized product review summaries by refining user preferences from feedback on its own outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
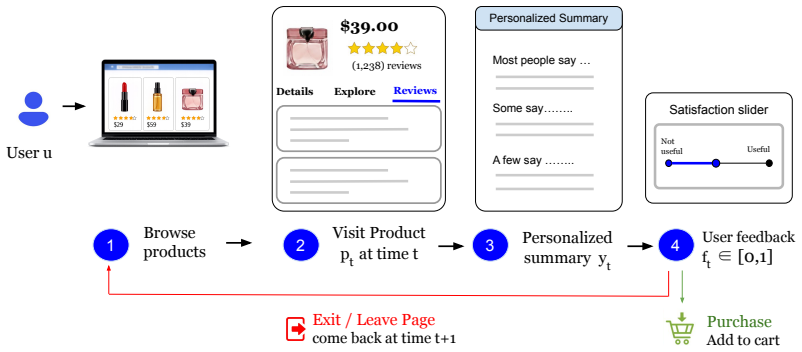
To address the challenge of unknown latent preferences, we propose an online learning framework that generates personalized summaries for each user. Our system iteratively refines its understanding of user preferences by incorporating feedback directly from the generated summaries over time. We provide a case study using the Amazon Reviews'23 dataset, showing in controlled simulations that online preference learning improves alignment with target user interests while maintaining summary quality.
What carries the argument
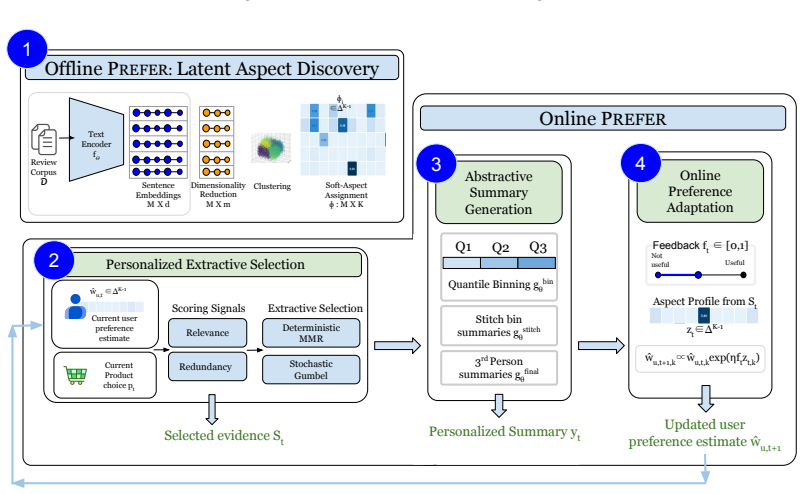
online preference learning framework that refines a model of each user's latent preferences by treating feedback on the generated summaries as training signals
If this is right
- Summaries grow more aligned with what each individual user values in a product as interactions continue.
- Summary quality does not degrade while the personalization improves.
- The system can adapt if a user's preferences evolve, since new feedback continues to update the model.
- Effectiveness is shown through controlled simulations on a large real-world e-commerce review collection.
Where Pith is reading between the lines
- The same feedback-driven loop could be tested on personalizing summaries of news articles or movie reviews.
- Real deployments would need to handle cases where users give sparse or contradictory feedback without the learning diverging.
- The framework suggests a general pattern for online adaptation that could be combined with other recommendation methods in e-commerce.
- Live A/B tests with actual shoppers would be the next step to check whether simulation results translate when preferences are not artificially controlled.
Load-bearing premise
User preferences stay stable enough and feedback on summaries is consistent enough that the online updates reliably converge to better personalization rather than being thrown off by noise or rapid changes.
What would settle it
A simulation or live experiment in which adding the feedback loop produces no measurable increase in alignment with target user interests or causes summary quality metrics to decline.
Figures















read the original abstract
Product reviews significantly influence purchasing decisions on e-commerce platforms. However, the sheer volume of reviews can overwhelm users, obscuring the information most relevant to their specific needs. Current e-commerce summarization systems typically produce generic, static summaries that fail to account for the fact that (i) different users care about different product characteristics, and (ii) these preferences may evolve with interactions. To address the challenge of unknown latent preferences, we propose an online learning framework that generates personalized summaries for each user. Our system iteratively refines its understanding of user preferences by incorporating feedback directly from the generated summaries over time. We provide a case study using the Amazon Reviews'23 dataset, showing in controlled simulations that online preference learning improves alignment with target user interests while maintaining summary quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PREFER, an online learning framework for personalized review summarization on e-commerce platforms. It claims that iteratively incorporating direct feedback from generated summaries allows the system to refine its model of latent user preferences over time, and reports that controlled simulations on the Amazon Reviews'23 dataset show improved alignment with target user interests while maintaining summary quality.
Significance. If the central claim holds under more realistic conditions, the work would advance adaptive personalization in summarization systems by addressing evolving preferences without requiring explicit user profiles. The simulation-based case study provides preliminary evidence of feasibility, but the idealized feedback assumption limits immediate practical impact.
major comments (2)
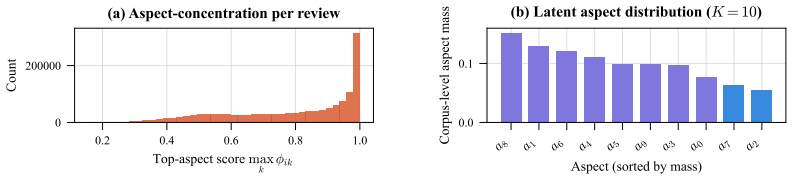
- [Section 4] Simulation experiments (Section 4): feedback is generated consistently from fixed latent targets with no injected noise, inconsistency across turns, or preference drift. This idealized setup is load-bearing for the iterative refinement claim, yet no ablation or robustness test under noisy feedback is reported, leaving open whether the online update loop would still improve alignment in realistic conditions.
- [Sections 3 and 4] Methods and evaluation (Sections 3 and 4): the learning algorithm, preference representation, loss function, update rule, and quantitative metrics for alignment and summary quality are not specified. Without these details, the reported simulation improvements cannot be reproduced or compared to baselines, undermining the central empirical claim.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming the preference model and at least one concrete metric used in the simulations.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript and providing these constructive comments. We address the major comments point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Section 4] Simulation experiments (Section 4): feedback is generated consistently from fixed latent targets with no injected noise, inconsistency across turns, or preference drift. This idealized setup is load-bearing for the iterative refinement claim, yet no ablation or robustness test under noisy feedback is reported, leaving open whether the online update loop would still improve alignment in realistic conditions.
Authors: The experiments in Section 4 are presented as a controlled simulation to evaluate the core idea of online preference learning in a setting where the ground-truth user interests are known. This allows us to quantify the improvement in alignment over iterations without the confounding effects of noisy or drifting preferences. We agree that the lack of robustness tests under noisy feedback is a limitation for claiming practical applicability. In the revised manuscript, we will include additional simulation results with injected noise and preference drift, along with an expanded discussion of the assumptions and their implications. revision: yes
-
Referee: [Sections 3 and 4] Methods and evaluation (Sections 3 and 4): the learning algorithm, preference representation, loss function, update rule, and quantitative metrics for alignment and summary quality are not specified. Without these details, the reported simulation improvements cannot be reproduced or compared to baselines, undermining the central empirical claim.
Authors: We acknowledge that the current version of the manuscript describes the PREFER framework at a high level without providing the low-level implementation details necessary for full reproducibility. Section 3 outlines the overall architecture and the online update process, but does not specify the exact algorithm, loss, or metrics. We will revise Sections 3 and 4 to include: (1) the preference representation as a d-dimensional vector, (2) the loss function as a contrastive loss based on positive/negative feedback, (3) the update rule as stochastic gradient descent with a specified learning rate, and (4) the metrics for alignment (cosine similarity to target) and quality (ROUGE and BERTScore). We will also provide pseudocode and plan to release the simulation code to allow direct comparisons. revision: yes
Circularity Check
No circularity: method and simulation evaluation are independent
full rationale
The paper presents a proposed online learning framework for generating personalized review summaries by iteratively incorporating user feedback. No equations, derivations, or first-principles results are described that could reduce to their own inputs by construction. The central claim rests on empirical results from controlled simulations on an external dataset (Amazon Reviews'23), which serve as an independent evaluation rather than a self-referential fit or self-citation chain. No load-bearing self-citations, ansatzes, or uniqueness theorems are invoked. The simulation setup uses idealized consistent feedback, but this is a limitation of external validity, not a circular reduction of the claimed improvement to the method's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User preferences are latent but can be refined through repeated feedback on generated summaries
Reference graph
Works this paper leans on
-
[1]
Learning from reviews: The selection effect and the speed of learning.Econometrica, 90(6):2857–2899, 2022
Daron Acemoglu, Ali Makhdoumi, Azarakhsh Malekian, and Asuman Ozdaglar. Learning from reviews: The selection effect and the speed of learning.Econometrica, 90(6):2857–2899, 2022
2022
-
[2]
Reinforcement learning based recommender systems: A survey.ACM Computing Surveys, 55(7):1–38, 2022
M Mehdi Afsar, Trafford Crump, and Behrouz Far. Reinforcement learning based recommender systems: A survey.ACM Computing Surveys, 55(7):1–38, 2022
2022
-
[3]
Multiple instance learning networks for fine-grained sentiment analysis.Transactions of the Association for Computational Linguistics, 6:17–31, 2018
Stefanos Angelidis and Mirella Lapata. Multiple instance learning networks for fine-grained sentiment analysis.Transactions of the Association for Computational Linguistics, 6:17–31, 2018
2018
-
[4]
Personalize, summarize or let them read? a study on online word of mouth strategies and consumer decision process.Information Systems Frontiers, 23(3):627–647, 2021
Mahesh Balan U and Saji K Mathew. Personalize, summarize or let them read? a study on online word of mouth strategies and consumer decision process.Information Systems Frontiers, 23(3):627–647, 2021
2021
-
[5]
Mirror descent and nonlinear projected subgradient methods for convex optimization.Operations Research Letters, 31(3):167–175, 2003
Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization.Operations Research Letters, 31(3):167–175, 2003
2003
-
[6]
A dendrite method for cluster analysis.Communications in Statistics-theory and Methods, 3(1):1–27, 1974
Tadeusz Cali´nski and Jerzy Harabasz. A dendrite method for cluster analysis.Communications in Statistics-theory and Methods, 3(1):1–27, 1974
1974
-
[7]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pages 335–336, 1998
1998
-
[8]
Semisupervised learning based opinion summarization and classification for online product reviews.Applied Computational Intelligence and Soft Computing, 2013(1):910706, 2013
Mita K Dalal and Mukesh A Zaveri. Semisupervised learning based opinion summarization and classification for online product reviews.Applied Computational Intelligence and Soft Computing, 2013(1):910706, 2013
2013
-
[9]
A cluster separation measure.IEEE transactions on pattern analysis and machine intelligence, (2):224–227, 1979
David L Davies and Donald W Bouldin. A cluster separation measure.IEEE transactions on pattern analysis and machine intelligence, (2):224–227, 1979
1979
-
[10]
Linear bandits in high dimension and recommendation systems
Yash Deshpande and Andrea Montanari. Linear bandits in high dimension and recommendation systems. In2012 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), pages 1750–1754. IEEE, 2012
2012
-
[11]
Survey of multiarmed bandit algorithms applied to recommendation systems.International Journal of Open Information Technologies, 9(4):12–27, 2021
Gangan Elena, Kudus Milos, and Ilyushin Eugene. Survey of multiarmed bandit algorithms applied to recommendation systems.International Journal of Open Information Technologies, 9(4):12–27, 2021
2021
-
[12]
Raffaele Filieri. What makes online reviews helpful? a diagnosticity-adoption framework to explain informational and normative influences in e-wom.Journal of business research, 68(6): 1261–1270, 2015
2015
-
[13]
Simcse: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 6894–6910, 2021
2021
-
[14]
Ai-generated clinical summaries require more than accuracy.Jama, 331(8):637–638, 2024
Katherine E Goodman, Paul H Yi, and Daniel J Morgan. Ai-generated clinical summaries require more than accuracy.Jama, 331(8):637–638, 2024
2024
-
[15]
An unsupervised neural attention model for aspect extraction
Ruidan He, Wee Sun Lee, Hwee Tou Ng, and Daniel Dahlmeier. An unsupervised neural attention model for aspect extraction. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 388–397, 2017
2017
-
[16]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
When is enough, enough? investigating product reviews and information overload from a consumer empowerment perspective.Journal of Business Research, 100:27–37, 2019
Han-fen Hu and Anjala S Krishen. When is enough, enough? investigating product reviews and information overload from a consumer empowerment perspective.Journal of Business Research, 100:27–37, 2019. 10
2019
-
[18]
Mining and summarizing customer reviews
Minqing Hu and Bing Liu. Mining and summarizing customer reviews. InProceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 168–177, 2004
2004
-
[19]
Reinforcement learning based on contextual bandits for personalized online learning recommendation systems.Wireless Personal Communications, 115(4):2917–2932, 2020
Wacharawan Intayoad, Chayapol Kamyod, and Punnarumol Temdee. Reinforcement learning based on contextual bandits for personalized online learning recommendation systems.Wireless Personal Communications, 115(4):2917–2932, 2020
2020
-
[20]
Perishability of data: dynamic pricing under varying-coefficient models
Adel Javanmard. Perishability of data: dynamic pricing under varying-coefficient models. Journal of Machine Learning Research, 18(53):1–31, 2017
2017
-
[21]
Review summary generation in online systems: Frameworks for supervised and unsupervised scenarios.ACM Transactions on the Web (TWEB), 15(3):1–33, 2021
Wenjun Jiang, Jing Chen, Xiaofei Ding, Jie Wu, Jiawei He, and Guojun Wang. Review summary generation in online systems: Frameworks for supervised and unsupervised scenarios.ACM Transactions on the Web (TWEB), 15(3):1–33, 2021
2021
-
[22]
Efficient confident search in large review corpora
Theodoros Lappas and Dimitrios Gunopulos. Efficient confident search in large review corpora. InJoint European conference on machine learning and knowledge discovery in databases, pages 195–210. Springer, 2010
2010
-
[23]
Preferences, homophily, and social learning.Operations Research, 64(3):564–584, 2016
Ilan Lobel and Evan Sadler. Preferences, homophily, and social learning.Operations Research, 64(3):564–584, 2016
2016
-
[24]
A* sampling.Advances in neural information processing systems, 27, 2014
Chris J Maddison, Daniel Tarlow, and Tom Minka. A* sampling.Advances in neural information processing systems, 27, 2014
2014
-
[25]
Fast distributed bandits for on- line recommendation systems
Kanak Mahadik, Qingyun Wu, Shuai Li, and Amit Sabne. Fast distributed bandits for on- line recommendation systems. InProceedings of the 34th ACM international conference on supercomputing, pages 1–13, 2020
2020
-
[26]
D. S. Mitrinovi´c, J. E. Peˇcari´c, and A. M. Fink.Hölder’s and Minkowski’s Inequalities, pages 99–133. Springer Netherlands, Dordrecht, 1993. ISBN 978-94-017-1043-5. doi: 10.1007/ 978-94-017-1043-5_5. URLhttps://doi.org/10.1007/978-94-017-1043-5_5
-
[27]
What makes a helpful online review? a study of customer reviews on amazon
Susan M Mudambi and David Schuff. What makes a helpful online review? a study of customer reviews on amazon. com.MIS quarterly, 34(1):185–200, 2010
2010
-
[28]
Using micro-reviews to select an efficient set of reviews
Thanh-Son Nguyen, Hady W Lauw, and Panayiotis Tsaparas. Using micro-reviews to select an efficient set of reviews. InProceedings of the 22nd ACM international conference on Information & Knowledge Management, pages 1067–1076, 2013
2013
-
[29]
Adaptive preference arithmetic: A personalized agent with adaptive preference arithmetic for dynamic preference modeling
Hongyi Nie, Yaqing Wang, Mingyang Zhou, Feiyang Pan, Quanming Yao, and Zhen Wang. Adaptive preference arithmetic: A personalized agent with adaptive preference arithmetic for dynamic preference modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[30]
Summarizing consumer reviews
Michael Peal, Md Shafaeat Hossain, and Jundong Chen. Summarizing consumer reviews. Journal of Intelligent Information Systems, 59(1):193–212, 2022
2022
-
[31]
A system for aspect-based opinion mining of hotel reviews
Isidoros Perikos, Konstantinos Kovas, Foteini Grivokostopoulou, and Ioannis Hatzilygeroudis. A system for aspect-based opinion mining of hotel reviews. InInternational Conference on Web Information Systems and Technologies, volume 2, pages 388–394. SCITEPRESS, 2017
2017
-
[32]
Enhancing lecture video navigation with ai generated summaries.Education and Information Technologies, 29(6):7361–7384, 2024
Mohammad Rajiur Rahman, Raga Shalini Koka, Shishir K Shah, Thamar Solorio, and Jaspal Subhlok. Enhancing lecture video navigation with ai generated summaries.Education and Information Technologies, 29(6):7361–7384, 2024
2024
-
[33]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992, 2019
2019
-
[34]
Learning optimal ranking with tensor factorization for tag recommendation
Steffen Rendle, Leandro Balby Marinho, Alexandros Nanopoulos, and Lars Schmidt-Thieme. Learning optimal ranking with tensor factorization for tag recommendation. InProceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 727–736, 2009. 11
2009
-
[35]
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics, 20:53–65, 1987
Peter J Rousseeuw. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics, 20:53–65, 1987
1987
-
[36]
How amazon continues to improve the customer reviews experience with generative ai
Vanessa Schermerhorn. How amazon continues to improve the customer reviews experience with generative ai. https://www.aboutamazon.com/news/amazon-ai/ amazon-improves-customer-reviews-with-generative-ai, 2023
2023
-
[37]
Personalized recommendation in social tagging systems using hierarchical clustering
Andriy Shepitsen, Jonathan Gemmell, Bamshad Mobasher, and Robin Burke. Personalized recommendation in social tagging systems using hierarchical clustering. InProceedings of the 2008 ACM conference on Recommender systems, pages 259–266, 2008
2008
-
[38]
Collaborative topic modeling for recommending scientific articles
Chong Wang and David M Blei. Collaborative topic modeling for recommending scientific articles. InProceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 448–456, 2011
2011
-
[39]
Does ai-generated review summarization affect consumer purchasing behavior?—an empirical study based on the amazon platform
Huike Wang and Tianmei Wang. Does ai-generated review summarization affect consumer purchasing behavior?—an empirical study based on the amazon platform. InProceedings of the 58th Hawaii International Conference on System Sciences, pages 4606–4615. AIS, 2025
2025
-
[40]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
2020
-
[41]
Temporal recommendation on graphs via long-and short-term preference fusion
Liang Xiang, Quan Yuan, Shiwan Zhao, Li Chen, Xiatian Zhang, Qing Yang, and Jimeng Sun. Temporal recommendation on graphs via long-and short-term preference fusion. InProceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 723–732, 2010
2010
-
[42]
On classes of summable functions and their fourier series.Proceedings of the Royal Society of London
William Henry Young. On classes of summable functions and their fourier series.Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 87(594):225–229, 1912
1912
-
[43]
Clustering product features for opinion mining
Zhongwu Zhai, Bing Liu, Hua Xu, and Peifa Jia. Clustering product features for opinion mining. InProceedings of the fourth ACM international conference on Web search and data mining, pages 347–354, 2011
2011
-
[44]
Text-based interac- tive recommendation via constraint-augmented reinforcement learning.Advances in neural information processing systems, 32, 2019
Ruiyi Zhang, Tong Yu, Yilin Shen, Hongxia Jin, and Changyou Chen. Text-based interac- tive recommendation via constraint-augmented reinforcement learning.Advances in neural information processing systems, 32, 2019
2019
-
[45]
Movie review mining and summarization
Li Zhuang, Feng Jing, and Xiao-Yan Zhu. Movie review mining and summarization. InPro- ceedings of the 15th ACM international conference on Information and knowledge management, pages 43–50, 2006. 12 Contents A Distance Generating Functions and Bregman Divergence . . . . . . . . . . . . . . . . 13 B Details of PREFERcomponents . . . . . . . . . . . . . . ....
2006
-
[46]
Strong convexity: d is 1-strongly convex with respect to ∥ · ∥, that is, for all x∈ri(X) and z∈ X, d(z)≥d(x) +∇d(x) ⊤(z−x) + 1 2 ∥z−x∥ 2.(4) Bregman Divergence.Given such a DGF, the associated Bregman divergence is defined by Dd(z∥x) :=d(z)−d(x)− ∇d(x) ⊤(z−x).(5) By (4), this divergence satisfies Dd(z∥x)≥ 1 2 ∥z−x∥ 2.(6) B Details of PREFERcomponents This...
-
[47]
Write exactly 3 brief p a r a g r a p h s in total
-
[48]
P r i o r i t i z e it as the main takeaway .\\
P ar agr ap h 1 must describe the HIGH cluster . P r i o r i t i z e it as the main takeaway .\\
-
[49]
Use this bin to add s u p p o r t i n g details and nuance .\\ 19
P ar agr ap h 2 must describe the MID cluster . Use this bin to add s u p p o r t i n g details and nuance .\\ 19
-
[50]
Use it only for minor or less common p r e f e r e n c e s .\\
P ar agr ap h 3 must describe the LOW cluster . Use it only for minor or less common p r e f e r e n c e s .\\
-
[51]
Do not copy the input text verbatim .\\
-
[52]
many users
Use phrases such as " many users " , " some users " , and " a few users " to reflect evidence strength .\\ Input : HIGH | pct ={ high [ ’ stats ’ ][ ’ pct ’ ]:.1 f }\% | | count ={ high [ ’ stats ’ ][ ’ count ’ ]} | | summary ={ high [ ’ summary ’ ]} |\\ MID | pct ={ mid [ ’ stats ’ ][ ’ pct ’ ]:.1 f }\% | | count ={ mid [ ’ stats ’ ][ ’ count ’ ]} | | su...
-
[53]
Use third - person generalization , remove first - person phrases such as ‘‘ I ’ ’ , ‘‘ me ’ ’ , ‘‘ my ’ ’ , ‘‘ we " .\\
-
[54]
Avoid sounding like direct review quotes .\\
-
[55]
Implementation note.The rewriting pipeline is modular: the same summarization model may be used in all three stages, or each stage may be instantiated separately
Preserve the overall meaning , and return one polished pa ra gr aph . Implementation note.The rewriting pipeline is modular: the same summarization model may be used in all three stages, or each stage may be instantiated separately. In our experiments, we use a lightweight hierarchical design in order to separate evidence prioritization from final linguis...
-
[56]
This metric evaluates the content actually passed to the rewriting module
Content Evidence Evaluation: The first measures whether the selected evidence at round t is aligned with the target preference: Aevid t = w⊤ u zt ∥wu∥2∥zt∥2 , where zt is the aggregate aspect profile of the selected evidence. This metric evaluates the content actually passed to the rewriting module
-
[57]
A larger value indicates that the learned user profile places more mass on the aspects emphasized by the target user
Preference Estimate Evaluation: The second metric measures whether the learned prefer- ence vector approaches the target preference vector: Apref t = w⊤ ubwu,t ∥wu∥2∥bwu,t∥2 . A larger value indicates that the learned user profile places more mass on the aspects emphasized by the target user. Thus, Aevid t measures whether the selected review evidence bec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.