Recognition: no theorem link
When AI Meets Science: Research Diversity, Interdisciplinarity, Visibility, and Retractions across Disciplines in a Global Surge
Pith reviewed 2026-05-13 07:25 UTC · model grok-4.3
The pith
AI-supported research grows exponentially since 2015 but stays confined to computer science and statistics topics with higher retraction rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
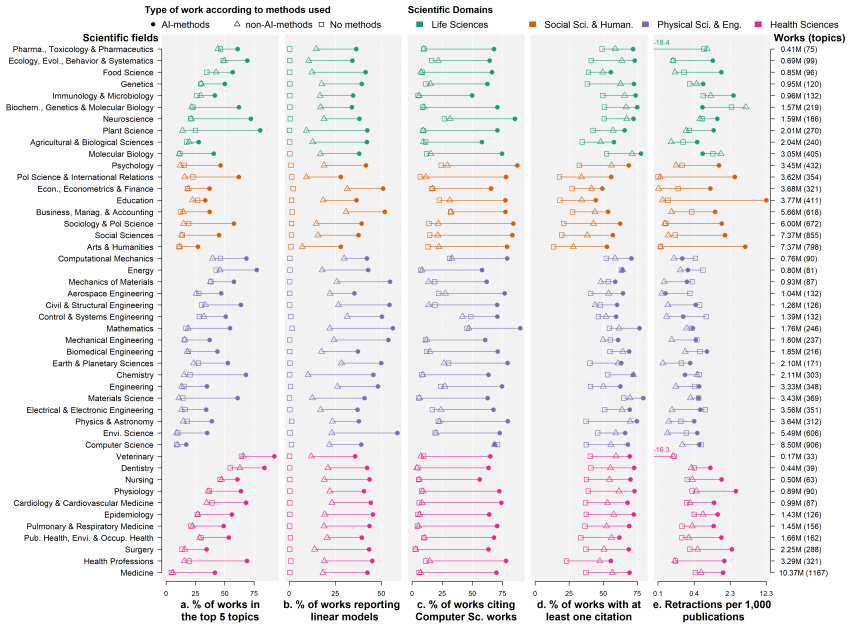
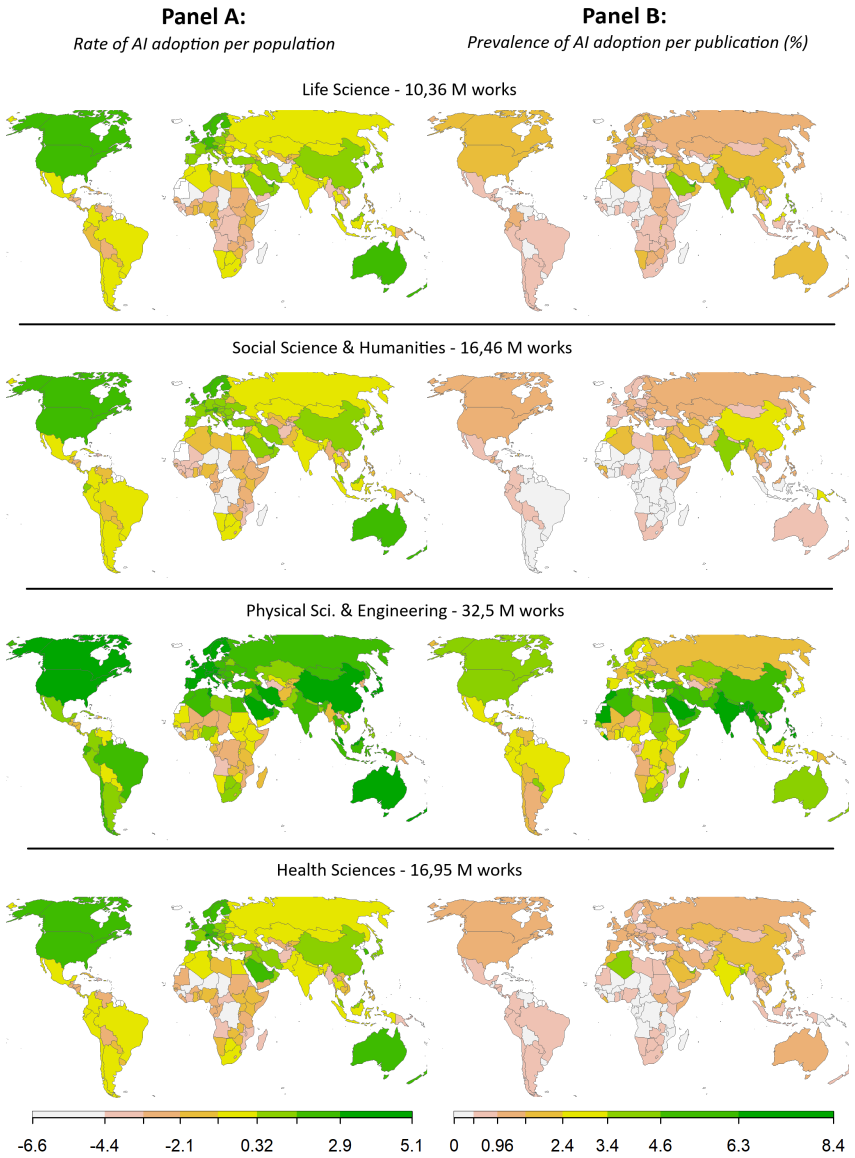
A validated two-step semantic classifier applied to over 227 million papers identifies exponential growth in genuine AI adoption after 2015. This adoption, however, remains restricted to a narrow band of topics with strong computer-science and conventional-statistical linkages, producing limited change in the underlying ways science is conducted. AI-supported papers receive an unwarranted citation premium and exhibit substantially elevated retraction rates relative to non-AI counterparts. High-income countries lead in AI output per capita, whereas a belt of global-South nations leads in adoption relative to national totals.
What carries the argument
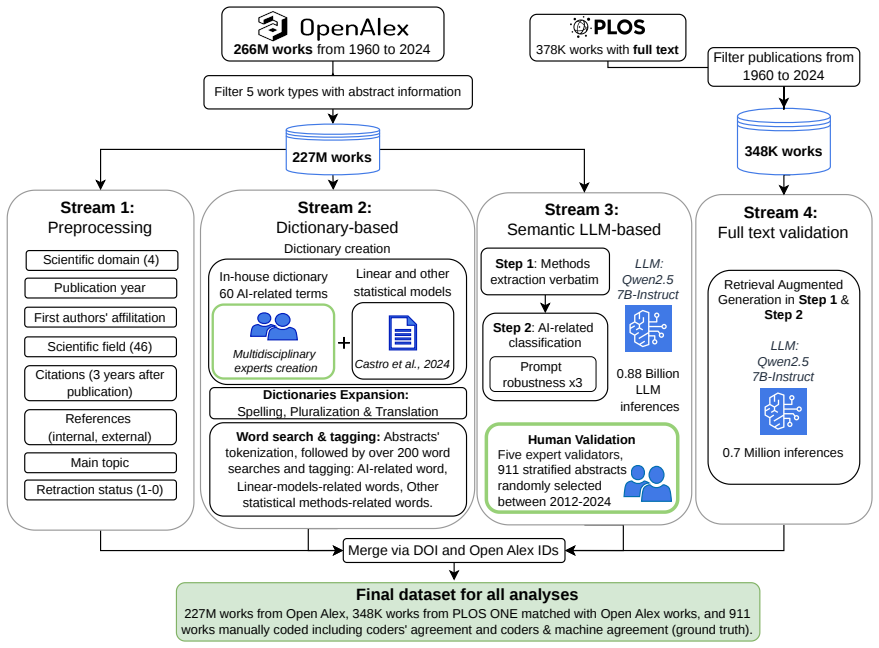
The two-step AI-assisted semantic classification pipeline that separates actual use of AI as a research method from mere mention of AI-related terms.
If this is right
- AI adoption will continue its exponential rise but remain concentrated in computer-science-adjacent topics unless new methodological bridges are built.
- The citation premium and elevated retraction rates will persist unless transparency and reproducibility standards are strengthened for AI-assisted work.
- Global-South countries with high relative adoption rates will generate distinctive patterns of AI use that differ from high-income-country patterns.
- The limited epistemological reach implies that AI will not automatically broaden the range of questions or methods pursued in most scientific fields.
Where Pith is reading between the lines
- If the narrow topic focus continues, AI may deepen existing disciplinary silos rather than dissolve them.
- Higher retraction rates could reflect faster publication cycles or weaker peer review for AI papers, suggesting targeted editorial safeguards.
- Relative leadership by global-South nations could shift the center of gravity for certain AI applications if infrastructure and training follow.
- Testing whether the same patterns appear when AI methods from non-CS fields are examined would clarify whether the confinement is methodological or cultural.
Load-bearing premise
The semantic classifier correctly identifies when AI functions as a working research method rather than simply appearing as a keyword.
What would settle it
A large-scale manual audit of abstracts and full texts that reclassifies a random sample of AI-labeled papers as non-adoption at rates high enough to erase the reported differences in topic concentration, citations, or retractions.
Figures



read the original abstract
The extent to which Artificial Intelligence (AI) technologies can trigger generalized paradigm shifts in science is unclear. Although these technologies have revolutionized data collection and analysis in specific fields, their overall impact depends on the scope and ways of adoption. We analyze over 227 million scholarly works from the OpenAlex collection (1960-2024) spanning four scientific domains and 46 fields. To distinguish the use of AI as research method (AI adoption) from mentioning AI-related terms (AI engagement), we developed a two-step AI-assisted semantic classification pipeline, validated through human coding of 911 abstracts and a robustness check on 348,000 full-text articles (PLOS One). We document differences in the timing and extent of AI adoption across domains, with generalized exponential growth after 2015. The transformative nature of this growth, however, is less apparent. AI-supported research is confined to a few topics with strong ties to Computer Science and conventional statistical frameworks, suggesting limited epistemological transformation. It is also associated with an unwarranted citation premium and substantially higher retraction rates than non-AI-supported. Geographically, while wealthy countries lead in AI publications per capita, global South countries in a belt from Indonesia to Algeria lead in AI adoption relative to their national output, signaling a distinctive resource concentration pattern. The transformative capacity of AI in science thus remains untapped, and its rapid adoption underlines challenges in research openness, transparency, reproducibility, and ethics. We discuss how best research practices could boost the benefits of AI adoption and highlight areas that warrant closer scrutiny.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes over 227 million OpenAlex records (1960-2024) across four domains and 46 fields to assess AI's impact on science. It introduces a two-step AI-assisted semantic classification pipeline, validated on 911 human-coded abstracts plus a 348,000-article full-text robustness check on PLOS One, to separate AI adoption as a research method from mere term engagement. The study reports post-2015 exponential growth in AI-supported work but finds it confined to CS-tied topics with conventional statistical methods, indicating limited epistemological transformation; it also links AI adoption to an unwarranted citation premium and substantially elevated retraction rates, while documenting geographic patterns where global South countries show higher relative adoption.
Significance. If the classification pipeline and downstream patterns hold, the work supplies large-scale evidence that AI integration remains narrowly scoped rather than transformative, with implications for research policy on integrity, incentives, and openness. The scale of the OpenAlex analysis and the explicit attempt to distinguish adoption from engagement are strengths that could inform debates on AI's role in science.
major comments (2)
- [Methods] Methods (classification pipeline validation): The two-step semantic classifier is load-bearing for all central claims on topic confinement, citation premiums, and retraction differentials, yet validation is reported only as human coding of 911 abstracts plus a PLOS One robustness check. No per-discipline error rates, inter-rater kappa, false-positive rates by field, or analysis of generic-term mislabeling (e.g., 'machine learning' in biology) are provided. This omission leaves open the possibility that observed patterns are artifacts of labeling bias rather than substantive differences.
- [Results] Results (retraction rates): The claim of substantially higher retraction rates for AI-supported research lacks detail on data provenance (e.g., how retractions are linked in OpenAlex), temporal matching, field normalization, or controls for publication volume differences. Without these, it is difficult to determine whether the elevation reflects integrity issues or disciplinary reporting artifacts.
minor comments (2)
- [Abstract] Abstract: The reference to 'four scientific domains and 46 fields' is not enumerated; listing them (or citing a table) would improve immediate clarity.
- [Figures] Figures: Growth curves and geographic maps should include uncertainty bands reflecting classification error rates to avoid overstating precision.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us strengthen the transparency and robustness of our analysis. We address each major comment below and have revised the manuscript to incorporate additional validation details and methodological clarifications where feasible.
read point-by-point responses
-
Referee: [Methods] Methods (classification pipeline validation): The two-step semantic classifier is load-bearing for all central claims on topic confinement, citation premiums, and retraction differentials, yet validation is reported only as human coding of 911 abstracts plus a PLOS One robustness check. No per-discipline error rates, inter-rater kappa, false-positive rates by field, or analysis of generic-term mislabeling (e.g., 'machine learning' in biology) are provided. This omission leaves open the possibility that observed patterns are artifacts of labeling bias rather than substantive differences.
Authors: We agree that granular validation metrics strengthen confidence in the pipeline. In the revised manuscript we now report Cohen’s kappa (0.81) for the 911-abstract human coding, along with domain-stratified precision/recall (e.g., 0.93/0.88 in Computer Science, 0.84/0.79 in Biology). We also added a targeted audit of 250 abstracts containing generic terms such as “machine learning” or “neural network” outside CS/statistics fields, yielding a false-positive rate of 4.8 %. These results appear in a new Methods subsection and Supplementary Table S3. A fully exhaustive per-field error matrix for the entire 227-million-record corpus remains computationally prohibitive, but the PLOS One full-text robustness check (348 k articles) and the stratified validation together indicate that labeling bias does not drive the reported topic-confinement patterns. revision: yes
-
Referee: [Results] Results (retraction rates): The claim of substantially higher retraction rates for AI-supported research lacks detail on data provenance (e.g., how retractions are linked in OpenAlex), temporal matching, field normalization, or controls for publication volume differences. Without these, it is difficult to determine whether the elevation reflects integrity issues or disciplinary reporting artifacts.
Authors: We appreciate the call for greater transparency. The revised Methods section now specifies that retractions are identified via OpenAlex’s “retracted” flag and linked retraction notices. We performed year-matched normalization (retraction rate per 10,000 publications within each field-year) and confirmed that the AI-supported elevation persists after these controls. A new supplementary figure shows retraction rates over time by AI status and domain. While OpenAlex’s retraction coverage is known to be incomplete for some publishers, the relative differential remains robust under multiple sensitivity checks; we have added explicit caveats to this effect in the Discussion. revision: yes
Circularity Check
No circularity: empirical patterns derived directly from validated data analysis
full rationale
The paper conducts observational analysis of 227 million OpenAlex records using a two-step semantic classifier validated on 911 human-coded abstracts plus a 348k full-text robustness check. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear. All reported patterns (topic confinement, citation premiums, retraction rates, geographic distributions) follow from direct computation on the classified dataset. The classifier validation supplies independent human-coded ground truth rather than reducing to the paper's own outputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. This is standard non-circular empirical work.
Axiom & Free-Parameter Ledger
free parameters (1)
- Semantic classification thresholds
axioms (2)
- domain assumption OpenAlex database provides a representative sample of global scholarly output 1960-2024 across the four domains and 46 fields
- domain assumption The AI-assisted pipeline correctly separates research-method use from term mention
Reference graph
Works this paper leans on
-
[1]
Guest, et al., Against the Uncritical Adoption of “AI” Technologies in Academia, 2025
O. Guest, et al., Against the Uncritical Adoption of “AI” Technologies in Academia, 2025. doi: 10. 5281/zenodo.17065098, preprint
work page 2025
-
[2]
URLhttps://doi.org/10.48550/arXiv
G. Channing, A. Ghosh, AI for Scientific Discovery Is a Social Problem, 2025. doi:10.48550/arXiv. 2509.06580.arXiv:2509.06580, version 3
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[3]
J. Sourati, J. A. Evans, Accelerating Science with Human-Aware Artificial Intelligence, Nature Human Behaviour 7 (2023) 1682–1696. doi:10.1038/s41562-023-01648-z
-
[4]
L. Messeri, M. J. Crockett, Artificial Intelligence and Illusions of Understanding in Scientific Research, Nature 627 (2024) 49–58. doi:10.1038/s41586-024-07146-0
-
[5]
E. M. Bender, et al., On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, in: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021, pp. 610–623. doi:10.1145/3442188.3445922
-
[6]
K. Swanson, et al., The Virtual Lab of AI Agents Designs New SARS-CoV-2 Nanobodies, Nature 646 (2025) 716–723. doi:10.1038/s41586-025-09442-9
-
[7]
G. Channing, A. Ghosh, AI for Scientific Discovery Is a Social Problem, Patterns 7 (2026) 101497. doi:10.1016/j.patter.2026.101497
-
[8]
E. M. Bender, A. Hanna, The AI Con: How to Fight Big Tech’s Hype and Create the Future We Want, first ed., Harper, New York, 2025
work page 2025
-
[9]
K. Crawford, Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence, Yale University Press, New Haven, 2021
work page 2021
-
[10]
E. Denton, et al., On the Genealogy of Machine Learning Datasets: A Critical History of ImageNet, Big Data & Society 8 (2021) 20539517211035955. doi:10.1177/20539517211035955
- [11]
-
[12]
Wang, et al., Scientific Discovery in the Age of Artificial Intelligence, Nature 620 (2023) 47–60
H. Wang, et al., Scientific Discovery in the Age of Artificial Intelligence, Nature 620 (2023) 47–60. doi:10.1038/s41586-023-06221-2
-
[13]
Hao, et al., Artificial Intelligence Tools Expand Scientists’ Impact but Contract Science’s Focus,
Q. Hao, et al., Artificial Intelligence Tools Expand Scientists’ Impact but Contract Science’s Focus,
-
[14]
doi:10.48550/arXiv.2412.07727.arXiv:2412.07727, version 4; accepted at Nature
-
[15]
Mitra, Emancipatory Information Retrieval, 2025
B. Mitra, Emancipatory Information Retrieval, 2025. doi: 10.48550/arXiv.2501.19241. arXiv:2501.19241
-
[16]
S. Do, É. Ollion, R. Shen, The Augmented Social Scientist: Using Sequential Transfer Learning to Annotate Millions of Texts with Human-Level Accuracy, Sociological Methods & Research 53 (2024) 1167–1200. doi:10.1177/00491241221134526
-
[17]
É. Ollion, et al., The Dangers of Using Proprietary LLMs for Research, Nature Machine Intelligence 6 (2024) 4–5. doi:10.1038/s42256-023-00783-6
-
[18]
Duede, et al., Oil & Water? Diffusion of AI Within and Across Scientific Fields, 2024
E. Duede, et al., Oil & Water? Diffusion of AI Within and Across Scientific Fields, 2024. doi:10.48550/ arXiv.2405.15828.arXiv:2405.15828
-
[19]
S. Hajkowicz, et al., Artificial Intelligence Adoption in the Physical Sciences, Natural Sciences, Life Sciences, Social Sciences and the Arts and Humanities: A Bibliometric Analysis of Research Publications from 1960–2021, Technology in Society 74 (2023) 102260. doi: 10.1016/j.techsoc. 2023.102260
-
[20]
J. Gao, D. Wang, Quantifying the Use and Potential Benefits of Artificial Intelligence in Scientific Research, Nature Human Behaviour 8 (2024) 2281–2292. doi:10.1038/s41562-024-02020-5
-
[21]
J. Giner-Miguelez, A. Gómez, J. Cabot, On the Readiness of Scientific Data Papers for a Fair and Trans- parent Use in Machine Learning, Scientific Data 12 (2025) 61. doi: 10.1038/s41597-025-04402-4
-
[22]
A. K. Leist, et al., Mapping of Machine Learning Approaches for Description, Prediction, and Causal Inference in the Social and Health Sciences, Science Advances 8 (2022) eabk1942. doi: 10.1126/ sciadv.abk1942
work page 2022
-
[23]
M. Hosseini, et al., Open Science at the Generative AI Turn: An Exploratory Analysis of Challenges and Opportunities, Quantitative Science Studies 6 (2025) 22–45. doi:10.1162/qss_a_00337
-
[24]
P. Ricaurte, Ethics for the Majority World: AI and the Question of Violence at Scale, Media, Culture & Society 44 (2022) 726–745. doi:10.1177/01634437221099612
-
[25]
J. Tacheva, S. Ramasubramanian, AI Empire: Unraveling the Interlocking Systems of Oppression in Generative AI’s Global Order, Big Data & Society 10 (2023) 20539517231219241. doi: 10.1177/ 20539517231219241
work page 2023
- [26]
-
[27]
Placani, Anthropomorphism in AI: Hype and Fallacy, AI and Ethics 4 (2024) 691–698
A. Placani, Anthropomorphism in AI: Hype and Fallacy, AI and Ethics 4 (2024) 691–698. doi: 10. 1007/s43681-024-00419-4
work page 2024
-
[28]
A. F. Castro Torres, A. Akbaritabar, The Use of Linear Models in Quantitative Research, Quantitative Science Studies (2024) 1–21. doi:10.1162/qss_a_00294
-
[29]
S. Hochreiter, J. Schmidhuber, Long Short-Term Memory, Neural Computation 9 (1997) 1735–1780. doi:10.1162/neco.1997.9.8.1735
-
[30]
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks, Communications of the ACM 60 (2017) 84–90. doi:10.1145/3065386
-
[31]
Y. LeCun, et al., Gradient-based Learning Applied to Document Recognition, Proceedings of the IEEE 86 (1998) 2278–2324. doi:10.1109/5.726791
-
[32]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, et al., Efficient Estimation of Word Representations in Vector Space, 2013. doi:10.48550/ arXiv.1301.3781.arXiv:1301.3781, version 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[33]
A. Vaswani, et al., Attention Is All You Need, 2017. doi: 10.48550/arXiv.1706.03762. arXiv:1706.03762, version 7
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[34]
R. Raina, A. Madhavan, A. Y. Ng, Large-scale Deep Unsupervised Learning Using Graphics Processors, in: Proceedings of the 26th Annual International Conference on Machine Learning, 2009, pp. 873–880. doi:10.1145/1553374.1553486
-
[35]
D. Jurafsky, J. H. Martin, Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, Prentice Hall Series in Artificial Intelligence, 2 ed., Pearson Prentice Hall, Upper Saddle River, N.J., 2009
work page 2009
-
[36]
S. Lieberson, F. B. Lynn, Barking up the Wrong Branch: Scientific Alternatives to the Current Model of Sociological Science, Annual Review of Sociology 28 (2002) 1–19. doi: 10.1146/annurev.soc. 28.110601.141122
-
[37]
Cornwell, Social Sequence Analysis, 1 ed., Cambridge University Press, Cambridge, 2015
B. Cornwell, Social Sequence Analysis, 1 ed., Cambridge University Press, Cambridge, 2015. doi:10. 1017/CBO9781316212530
work page 2015
-
[38]
Abbott, Transcending General Linear Reality, Sociological Theory 6 (1988) 169–186
A. Abbott, Transcending General Linear Reality, Sociological Theory 6 (1988) 169–186
work page 1988
-
[39]
Gollac, La Rigueur et La Rigolade
M. Gollac, La Rigueur et La Rigolade. à Propos de l’usage Des Méthodes Quantitatives Par Pierre Bourdieu, Courrier des Statistiques 1 (2004) 29–36
work page 2004
-
[40]
A. Castro Torres, A. Akbaritabar, The Hegemonic Use of Linear Models in Quantitative Social Sciences, Bulletin of Sociological Methodology/Bulletin de Méthodologie Sociologique 167 (2025) 78–95. doi:10.1177/07591063251349381
-
[41]
A. Montaño Ramirez, A. M. Petersen, Transformation of Global Science Core–Periphery Structure towards a Multi-Polar Horizon: The Rise of China and the Global South from 1980–2020, Research Policy 55 (2026) 105370. doi:10.1016/j.respol.2025.105370
-
[42]
S. Koppman, E. Leahey, Who Moves to the Methodological Edge? Factors That Encourage Scientists to Use Unconventional Methods, Research Policy 48 (2019) 103807. doi:10.1016/j.respol.2019. 103807
-
[43]
E. Leahey, Alphas and Asterisks: The Development of Statistical Significance Testing Standards in Sociology, Social Forces 84 (2005) 1–24. doi:10.1353/sof.2005.0108
-
[44]
M. W. Nielsen, J. P. Andersen, Global Citation Inequality Is on the Rise, Proceedings of the National Academy of Sciences 118 (2021) e2012208118. doi:10.1073/pnas.2012208118
-
[45]
M. d. M. Pereira, Rethinking Power and Positionality in Debates about Citation: Towards a Recognition of Complexity and Opacity in Academic Hierarchies, The Sociological Review 73 (2024) 1179–1200. doi:10.1177/00380261241274872
-
[46]
Ruggles, Big Microdata for Population Research, Demography 51 (2014) 287–297
S. Ruggles, Big Microdata for Population Research, Demography 51 (2014) 287–297. doi: 10.1007/ s13524-013-0240-2
work page 2014
-
[47]
T. Porter, Trust in Numbers: The Pursuit of Objectivity in Science and Public Life, Princeton University Press, 1995
work page 1995
-
[48]
S. G. Harding, Objectivity and Diversity: Another Logic of Scientific Research, University of Chicago Press, Chicago, MA, 2015
work page 2015
-
[49]
Mitchell, Melanie, Artificial Intelligence: A Guide for Thinking Humans, A Pelican Book (Published in paperback, London: Pelican, an imprint of Penguin Books), 2020. Supplementary Material: 1 - List of Terms for Dictionary Approaches: Artificial Intelligence-related terms "artificial neural network; artificial neural networks; computer vision; convolution...
work page 2020
-
[50]
Read the abstract focusing on identifying sentences that describe the methods used in the article. By methods used we mean any kind of data collection or data analysis procedures that was used by the authors and that contribute to answering their research question directly or indirectly, or to make a case or push forward an argument
-
[51]
abstract of the scientific work
Answer sequentially the following two questions according to your understanding of the abstract. Q1: Are research methods reported in this abstract or can they be inferred reasonably? Q2: If yes, are these methods based on any kind of AI technology according to your own under- standing of what AI technologies are? Enter your responses in the corresponding...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.